SOMATIC PIPELINE
Run a somatic variant pipeline workflow
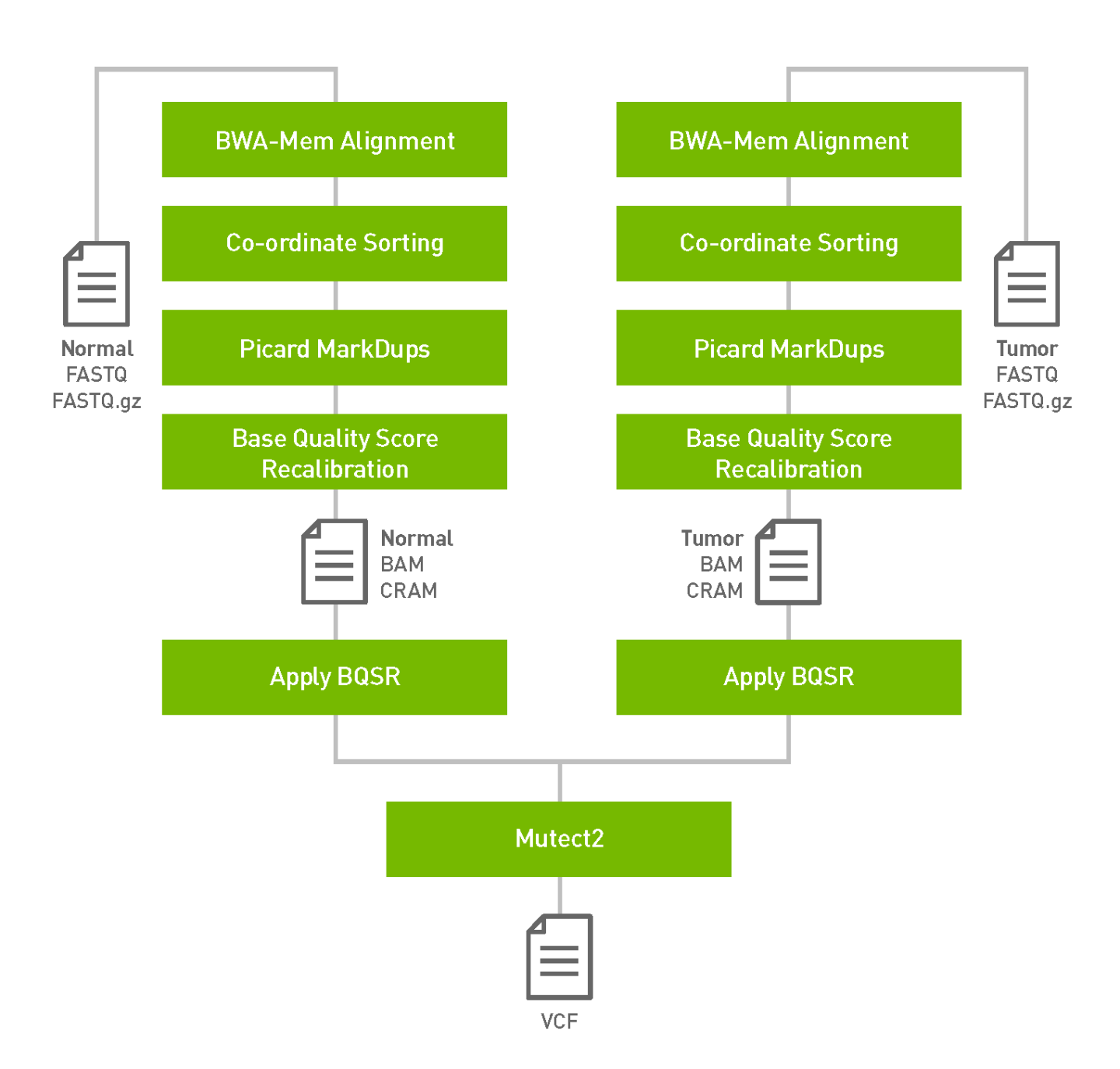
The somatic pipeline process the tumor fastq files and optionally normal fastq files and knownSites files and generates tumor or tumor/normal analysis. The output is in vcf format.
CLI
# The commandline below will run tumor-only analysis.
$ pbrun somatic --ref Ref/Homo_sapiens_assembly38.fasta \
--in-tumor-fq Data/sample_1.fq.gz Data/sample_2.fq.gz \
--out-vcf output.vcf \
--out-tumor-bam tumor.bam
# The commandline below will run tumor-normal analysis.
$ pbrun somatic --ref Ref/Homo_sapiens_assembly38.fasta \
--knownSites Ref/Homo_sapiens_assembly38.known_indels.vcf.gz \
--in-tumor-fq Data/sample_1.fq.gz Data/sample_2.fq.gz "@RG\tID:sm_tumor_rg1\tLB:lib1\tPL:bar\tSM:sm_tumor\tPU:sm_tumor_rg1" \
--out-vcf output.vcf \
--out-tumor-bam tumor.bam \
--out-tumor-recal-file recal.txt \
--in-normal-fq normal0.fq.gz normal1.fq.gz "@RG\tID:sm_normal_rg1\tLB:lib1\tPL:bar\tSM:sm_normal\tPU:sm_normal_rg1" \
--out-normal-bam normal.bam
- --ref
- --in-tumor-fq
- --in-se-tumor-fq
- --out-vcf
- --out-tumor-bam
- --out-tumor-recal-file
- --knownSites
- --in-normal-fq
- --in-se-normal-fq
- --out-normal-bam
- --tmp-dir
- --num-gpus
- --no-markdups
- --ploidy
- --interval-file
- --interval
- --interval-padding
- --tumor-read-group-sm
- --tumor-read-group-lb
- --tumor-read-group-pl
- --tumor-read-group-id-prefix
- --normal-read-group-sm
- --normal-read-group-lb
- --normal-read-group-pl
- --normal-read-group-id-prefix
- --bwa-options
- --gpu-devices
(required) The reference genome in fasta format. We assume that the indexing required to run bwa has been completed by the user.
(required) Full path to the pair ended fastq files (in gz or fastq format) followed by read group with quotes. (Example: "@RG\tID:foo\tLB:lib1\tPL:bar\tSM:20"). Files can be in fastq or fastq.gz format. This option can be repeated multiple times.
Path to the single ended fastq file followed by optional read group with quotes (Example: "@RG\tID:foo\tLB:lib1\tPL:bar\tSM:sample\tPU:foo"). File can be in fastq or fastq.gz format or a google cloud storage object. Either all sets of inputs have read group or none should have it and will be automatically added by the pipeline. This option can be repeated multiple times.
Example 1: --in-se-tumorfq sampleX_1.fastq.gz --in-se-tumor-fq sampleX_2.fastq.gz .
Example 2: --in-se-tumor-fq sampleX_1.fastq.gz "@RG\tID:foo\tLB:lib1\tPL:bar\tSM:tumor\tPU:unit1" --in-se-tumor-fq sampleX_2.fastq.gz "@RG\tID:foo2\tLB:lib1\tPL:bar\tSM:tumor\tPU:unit2" .
For same sample, Read Groups should have same sample name (SM) and different ID and PU (default: None)
(required) Path of VCF file after Variant Calling.
(required) Path of bam file for tumor reads.
Path of report file after Base Quality Score Recalibration for tumor sample.
Known indel files in .vcf.gz format. These should be compressed vcf files for known SNPs and indels. You can use this option multiple times. If you provide this option, then you must also provide an –out-recal-file (see below for details).
Full path to the pair ended fastq files (in gz or fastq format) followed by read group with quotes. (Example: "@RG\tID:foo\tLB:lib1\tPL:bar\tSM:20"). Files can be in fastq or fastq.gz format. This option can be repeated multiple times.
Path to the single ended fastq file followed by optional read group with quotes (Example: "@RG\tID:foo\tLB:lib1\tPL:bar\tSM:sample\tPU:foo").
File can be in fastq or fastq.gz format or a google cloud storage object. Either all sets of inputs have read group or none should have it and will be automatically added by the pipeline. This option can be repeated multiple times.
Example 1:
--in-se-normalfq sampleX_1.fastq.gz --in-se-normal-fq sampleX_2.fastq.gz .
Example 2:
--in-se-normal-fq sampleX_1.fastq.gz "@RG\tID:foo\tLB:lib1\tPL:bar\tSM:normal\tPU:unit1" \
--in-se-normal-fq sampleX_2.fastq.gz "@RG\tID:foo2\tLB:lib1\tPL:bar\tSM:normal\tPU:unit2" .
For same sample, Read Groups should have same sample name (SM) and different ID and PU (default: None)
Path of bam file for normal reads.
Defaults to ..
Full path to the directory where temporary files will be stored.
Defaults to 8.
The number of GPUs to be used for this analysis task.
Defaults to False.
Do not mark duplicates, generate bam after co-ordinate sorting.
Defaults to 2.
Ploidy assumed for the bam file. Currently only haploid (ploidy 1) and diploid (ploidy 2) are supported.
Path to an interval file for BQSR step with possible formats: Picard-style (.interval_list or .picard), GATK-style (.list or .intervals), or BED file (.bed). This option can be used multiple times (default: None)
(-L) Interval strings within which to call variants from the input reads. All intervals will have a padding of 100 to get read records and overlapping intervals will be combined. Interval files should be passed using the --interval-file option.
This option can be used multiple times. e.g. -L chr1 -L chr2:10000 -L chr3:20000+ -L chr4:10000-20000 (default: None)
(-ip) Padding size (in base pairs) to add to each interval you are including (default: None)
SM tag for read groups for tumor sample (default: None)
LB tag for read groups for tumor sample (default: None)
PL tag for read groups for tumor sample (default: None)
prefix for ID and PU tag for read groups for tumor sample. This prefix will be used for all pair of tumor fastq files in this run. The ID and PU tag will consist of this prefix and an identifier which will be unique for a pair of fastq files (default: None)
SM tag for read groups for normal sample (default: None)
LB tag for read groups for normal sample (default: None)
PL tag for read groups for normal sample (default: None)
prefix for ID and PU tag for read groups for normal sample. This prefix will be used for all pair of normal fastq files in this run. The ID and PU tag will consist of this prefix and an identifier which will be unique for a pair of fastq files (default: None)
Pass supported bwa mem options as one string. Current original bwa mem supported options, -M, -Y, -T.
Which GPU devices to use for a run. By default, all GPU devices will be used. To set specific GPU devices, enter a comma-separated list of GPU device numbers.