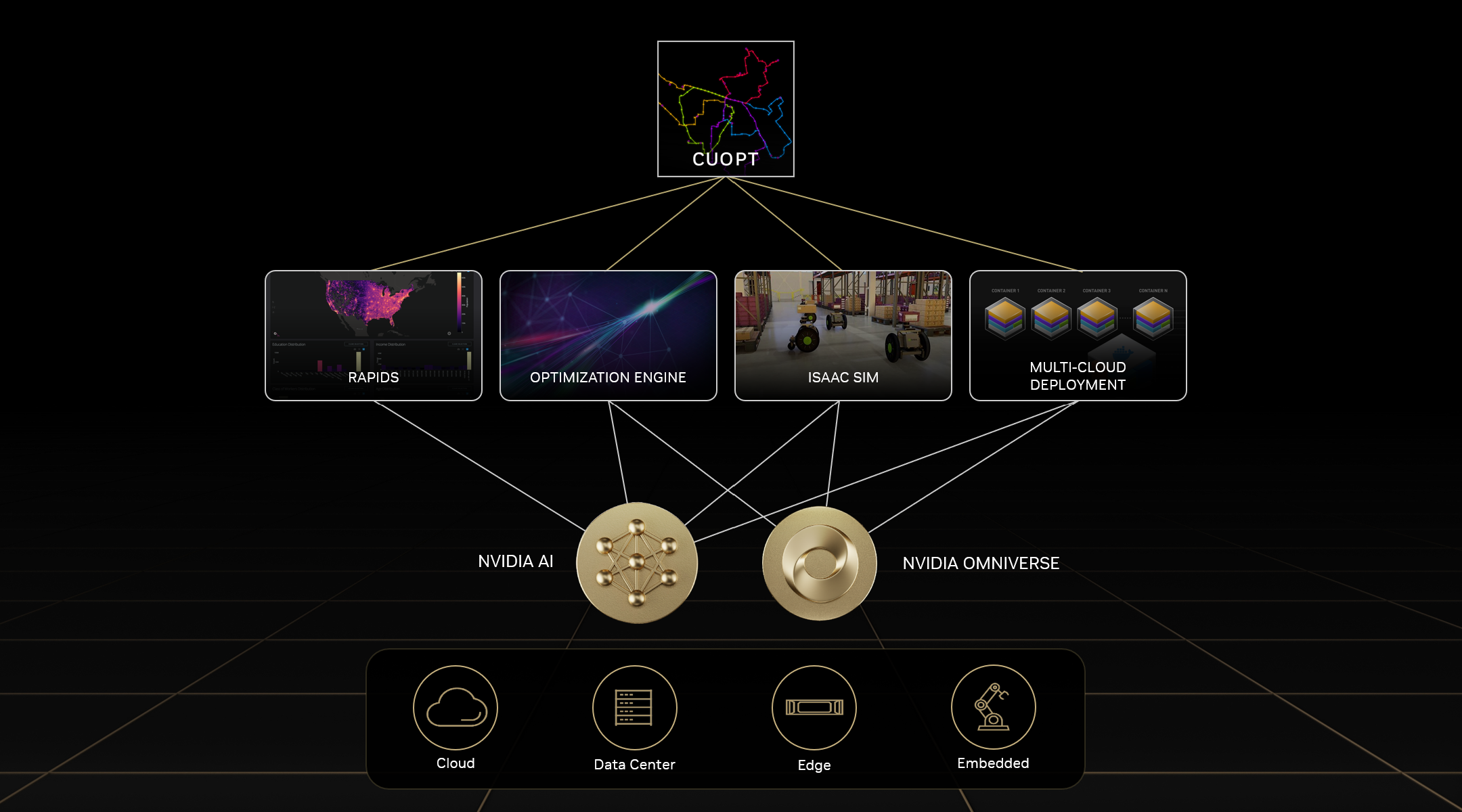
Overview¶
NVIDIA cuOpt is a GPU-accelerated combinatorial optimization engine for solving complex routing problems with multiple constraints while delivering new capabilities like dynamic rerouting and robotic simulation. Typical problem spaces such as the Traveling Salesperson Problem (TSP), Vehicle Routing Problem (VRP), and Pickup and Delivery Problem (PDP) that are common to the logistics and operations research industry have historically frustrated many in the ecosystem due to the inaccuracy and long wait times that are associated with CPU solvers. NVIDIA cuOpt accelerates these problem spaces through clever use of parallel heuristics and supports many variations of these base problems, such as adding constraints on vehicle capacities, delivery time windows, and vehicle drivers shifts and breaks during the work day. These operational research and logistics problems are incredibly compute-intensive with massive operational costs. Most problems common to this space are NP-hard, or in layman’s terms there exists no apparent or efficient algorithm to directly calculate a solution. NVIDIA GPUs bring the throughput capabilities needed to fuel the most ambitious heuristics (tabu search, guided local search, ant colony, etc.) while also supporting the most challenging constraints with accelerated runtime and better accuracy.
The cuOpt production-ready solver is offered as a RESTful API Service that is simple and easy to use with any browser. Using the NVIDIA cuOpt service, users do not need to worry about resource provisioning or environment setup; simply pip install the cuOpt Python thin client, enter your credentials, and solve your routing problems.