NVIDIA Self-Hosted Server Overview#
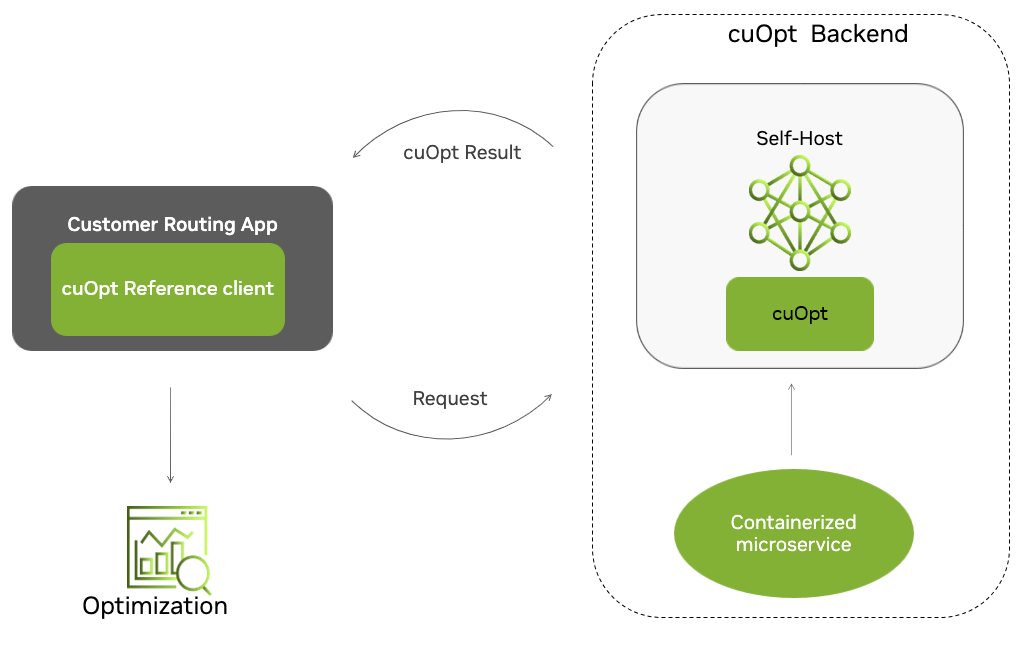
NVIDIA cuOpt is a containerized server and can be easily deployed locally and in CSPs.
The example server uses HTTP POST requests on port 5000 to accept optimization input data. cuOpt works on the given data with options/constraints provided, and returns optimized results in response.
Quickstart Guide#
Step 1: Get access to cuOpt#
GA (Routing only):#
Get a subscription for NVIDIA AI Enterprise (NVAIE) to get the cuOpt container to host in your cloud.
Once given access, users can find cuOpt container in the NGC catalog.
EA - Early Access to LP/MIP:#
Please contact
cuopt@nvidia.comand share your interest to use Routing/LP/MILP.Once given access, users can find EA cuOpt container in the NGC catalog.
Step 2: Access NGC#
Log into NGC using the invite and choose the appropriate NGC org.
Generate an NGC API key from settings. If you have not generated an API Key, you can generate it by going to the Setup option in your profile and choose Get API Key. Store this or generate a new one next time. More information can be found here.
Step 3: Pull a cuOpt Container#
Prerequisites for running the container:
Please visit system requirements for self-hosted for more information.
Go to the container section for cuOpt and copy the pull tag for the latest image.
Within the Select a tag dropdown, locate the container image release that you want to run.
Click the Copy Image Path button to copy the container image path.
Log into the nvcr.io container registry in your cluster setup, using the NGC API key as shown below.
docker login nvcr.io
Username: $oauthtoken
Password: <my-api-key>
Note
The username is $oauthtoken and the password is your API key.
Pull the cuOpt container.
The container for cuOpt can be found in the Containers tab in NGC. Please copy the tag from the cuOpt container page and use it as follows,
# Save the image tag in a variable for use below
export CUOPT_IMAGE="CONTAINER_TAG_COPIED_FROM_NGC"
docker pull $CUOPT_IMAGE
Step 4: Running cuOpt#
Note
The commands below run the cuOpt container in detached mode. To stop a detached container, use the docker stop command. To instead run the container in interactive mode, remove the -d option.
If you have Docker 19.03 or later, a typical command to launch the container is:
docker run -it -d --gpus=1 --rm -p 5000:5000 $CUOPT_IMAGE
If you have Docker 19.02 or earlier, a typical command to launch the container is:
nvidia-docker run -it -d --gpus=1 --rm -p 5000:5000 $CUOPT_IMAGE
By default the container runs on port
5000, but this can be changed using environment variableCUOPT_SERVER_PORT,
docker run -it -d --gpus=1 -e CUOPT_SERVER_PORT=8080 --rm -p 8080:8080 $CUOPT_IMAGE
This command would launch the container and cuOpt API endpoints should be available for testing.
If you have multiple GPUs and would like to choose a particular GPU, please use
--gpus device=<GPU_ID>.GPU_IDcan be found using the commandnvidia-smi.Server can be configured for log levels and other options using environment variables, options are listed as follows:
CUOPT_SERVER_PORT : For server port (default 5000).
CUOPT_SERVER_IP : For server IP (default 0.0.0.0).
CUOPT_SERVER_LOG_LEVEL : Options are
critical,error,warning,info,debug(default is info).CUOPT_LP_TIME_LIMIT_SEC : For setting a maximum time limit for only LP/MILP solver run time; this would also act as the default time limit if not set. Otherwise, the default is None and the solver runs either until achieves an optimal solution (in the case of LP). For MILP time limit is mandatory.
CUOPT_LP_ITERATION_LIMIT : For setting a maximum iteration time limit for only LP/MILP solver; this would also act as the default value if not set. Otherwise, the default is None and the solver runs until it achieves a solution.
CUOPT_DATA_DIR : A shared mount path used to optionally pass cuOpt problem data files to the endpoint, instead of sending data over network (default is None).
CUOPT_RESULT_DIR : A shared mount path used to optionally pass cuOpt result files from the endpoint, instead of sending data over the network (default is None).
CUOPT_MAX_RESULT : Maximum size (kilobytes) of a result returned over http from the endpoint when
CUOPT_RESULT_DIRis set. Set to 0 to have all results written toCUOPT_RESULT_DIR(default is 250).CUOPT_GPU_COUNT : To configure each GPU to run a cuOpt solver process (Multi-GPU configuration), so that the cuOpt service may solve multiple problems simultaneously. Problems will be assigned to available idle solver processes. Default is 1. This value is capped at the number of available GPUs. Select which set of GPUs should be used, with
CUDA_VISIBLE_DEVICESas shown below, and then set the environment variableCUOPT_GPU_COUNTin the container to assign the number of GPUs to use. - A solver will use only one GPU, multiple GPUs can’t be pooled under a single process to expand memory or other capability. - IfCUOPT_GPU_COUNTis greater than available GPUs, cuOpt will configure to what it has access to.
docker run -it -d --gpus '"device=0,1"' -e CUDA_VISIBLE_DEVICES="0,1" -e CUOPT_SERVER_PORT=8080 -e CUOPT_GPU_COUNT=2 --rm -p 8080:8080 $CUOPT_IMAGE
CUOPT_SSL_CERTFILE : Filepath in container for SSL certificate, may need to mount a directory for this file with read and write access.
CUOPT_SSL_KEYFILE : Filepath in container for key file, may need to mount a directory for this file with read and write access.
You can generate a self-signed certificate easily as follows:
openssl genrsa -out ca.key 2048
openssl req -new -x509 -days 365 -key ca.key -subj "/C=CN/ST=GD/L=SZ/O=Acme, Inc./CN=Acme Root CA" -out ca.crt
openssl req -newkey rsa:2048 -nodes -keyout server.key -subj "/C=CN/ST=GD/L=SZ/O=Acme, Inc./CN=*.example.com" -out server.csr
openssl x509 -req -extfile <(printf "subjectAltName=DNS:example.com,DNS:www.example.com") -days 365 -in server.csr -CA ca.crt -CAkey ca.key -CAcreateserial -out server.crt
server.crt and server.key are meant for server, ca.crt is meant for client.
Input data can be shared and results can be accumulated using shared mount paths rather than sending over network using options
CUOPT_DATA_DIRandCUOPT_RESULT_DIRas follows:Create directories to share with the container and run the container.
Note
The data and results directories mounted on the cuOpt container need to be readable and writable by the container user, and also have the execute permission set. If they are not, the container will print an error message and exit. Be careful to set permissions correctly on those directories before running the cuOpt server.
mkdir data mkdir result CID=$(docker run --rm --gpus=1 \ -v `pwd`/data:/cuopt_data \ -v `pwd`/results:/cuopt_results \ -e CUOPT_DATA_DIR=/cuopt_data \ -e CUOPT_RESULT_DIR=/cuopt_results \ -e CUOPT_MAX_RESULT=0 \ -e CUOPT_SERVER_PORT=8081 \ -p 8081:8081 \ -it -d $CUOPT_IMAGE)
check whether container up and running with following health check,
curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/health'
Create a data file in the data directory and send a POST request to cuOpt with name of the data file.
echo "{ \"cost_matrix_data\": {\"data\": {\"0\": [[0, 1], [1, 0]]}}, \"task_data\": {\"task_locations\": [1], \"demand\": [[1]], \"task_time_windows\": [[0, 10]], \"service_times\": [1]}, \"fleet_data\": {\"vehicle_locations\":[[0, 0]], \"capacities\": [[2]], \"vehicle_time_windows\":[[0, 20]] }, \"solver_config\": {\"time_limit\": 2} }" >> data/data.json curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/request' \ --header 'Content-Type: application/json' \ --header "CLIENT-VERSION: custom" \ --header "CUOPT-DATA-FILE: data.json" \ -d {}
The result would be available in the result directory as follows:
cat results/*
Note
Kill the running Docker container once you have completed testing.
docker kill $CID
Step 5: Testing Container#
curlandjqcan be used instead of the thin client to communicate with server. To make sure they are installed on Ubuntu:sudo apt install jq curl
Note
The examples use HTTP since SSL is not enabled, please refer to conatiner set-up on how to enable SSL and then you can use HTTPS.
Note
Don’t add any comments in curl command, it might consider it as input and error.
Health Check
Check whether container is up and running with following health check,
curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/health' | jq
Routing Example:
curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/request' \
--header 'Content-Type: application/json' \
--header "CLIENT-VERSION: custom" \
-d '{
"cost_matrix_data": {"data": {"0": [[0, 1], [1, 0]]}},
"task_data": {"task_locations": [1], "demand": [[1]], "task_time_windows": [[0, 10]], "service_times": [1]},
"fleet_data": {"vehicle_locations":[[0, 0]], "capacities": [[2]], "vehicle_time_windows":[[0, 20]] },
"solver_config": {"time_limit": 2}
}' | jq
This would get you a request-id in a successful scenario as {reqId:<REQUEST_ID>}. This is the id that user would use to track the status of the request.
Poll the server with this request-id to get response, response might be 201 where it is still pending or 200 with result. You can poll with following command,
curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/request/<REQUEST_ID>' --header 'Content-Type: application/json' --header "CLIENT-VERSION: custom" | jq
The response would be as follows, more details on the response can be found under responses schema in open-api spec or same can be found in redoc as well
{
"response": {
"solver_response": {
"status": 0,
"num_vehicles": 1,
"solution_cost": 2.0,
"objective_values": {
"cost": 2.0
},
"vehicle_data": {
"0": {
"task_id": [
"Depot",
"0",
"Depot"
],
"arrival_stamp": [
0.0,
1.0,
3.0
],
"type": [
"Depot",
"Delivery",
"Depot"
],
"route": [
0,
1,
0
]
}
},
"dropped_tasks": {
"task_id": [],
"task_index": []
}
}
},
"reqId": "0eabe835-a7e0-4d84-9410-1602eaa254c0"
}
LP Example:
Note
Linear Programming (LP) and Mixed Integer Linear Programming (MILP) are Early Access features and are currently open to only select customers.
curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/request' \
--header 'Content-Type: application/json' \
--header "CLIENT-VERSION: custom" \
-d '{
"csr_constraint_matrix": {
"offsets": [0, 2, 4],
"indices": [0, 1, 0, 1],
"values": [3.0, 4.0, 2.7, 10.1]
},
"constraint_bounds": {
"upper_bounds": [5.4, 4.9],
"lower_bounds": ["ninf", "ninf"]
},
"objective_data": {
"coefficients": [0.2, 0.1],
"scalability_factor": 1.0,
"offset": 0.0
},
"variable_bounds": {
"upper_bounds": ["inf", "inf"],
"lower_bounds": [0.0, 0.0]
},
"maximize": false,
"solver_config": {
"tolerances": {
"optimality": 0.0001
}}
}' | jq
This would get you a request-id in a successful scenario as {reqId:<REQUEST_ID>}. This is the id that user would use to track the status of the request.
Poll the server with this request-id to get response, response might be 201 where it is still pending or 200 with result. You can poll with following command,
curl --location 'http://<SERVER_IP>:<SERVER:PORT>/cuopt/request/<REQUEST_ID>' --header 'Content-Type: application/json' --header "CLIENT-VERSION: custom" | jq
The response would be as follows, more details on the response can be found under responses schema in open-api spec or same can be found in redoc as well
{
"response": {
"solver_response": {
"status": 1,
"solution": {
"primal_solution": [
0.0,
0.0
],
"dual_solution": [
0.0,
0.0
],
"primal_objective": 0.0,
"dual_objective": 0.0,
"solver_time": 72.0,
"vars": {},
"lp_statistics": {
"primal_residual": 0.0,
"dual_residual": 0.0,
"gap": 0.0,
"reduced_cost": [
0.2,
0.1
]
}
}
}
},
"reqId": "3b16c9cb-fbe0-4f11-9d9f-c77f260a0745",
"notes": [
"Optimal"
]
}
Step 6: Installing Thin Client Using Pip Index#
Note
The self-hosted thin client requires Python 3.10.
The thin client enables users to test quickly, but users can design their own clients using this.
Whenever thin clients need to be updated or installed, you can directly install it using the NVIDIA pip index.
Requirements:
Please visit system requirements for thin client for self-hosted for more information.
pip install --upgrade --extra-index-url https://pypi.nvidia.com cuopt-sh-client
For more information navigate to Self-Hosted Thin Client.
Step 7: Installing cuOpt on Kubernetes Using a Helm Chart#
Please refer to system requirements for self-hosted container on kubernetes for information on Kubernetes cluster requirements and links to Kubernetes resources.
Create a namespace in Helm.
1kubectl create namespace <some name> 2export NAMESPACE="<some name>"
Test whether cluster has access to GPU or not using following example (if
kubectlis not available use the analagous command for your Kubernetes installation to run this pod)kubectl apply -f - <<EOF apiVersion: v1 kind: Pod metadata: name: cuda-vector-add spec: restartPolicy: OnFailure containers: - name: cuda-vector-add image: "k8s.gcr.io/cuda-vector-add:v0.1" resources: limits: nvidia.com/gpu: 1 EOF kubectl logs cuda-vector-add
Should be getting response as follows,
[Vector addition of 50000 elements] Copy input data from the host memory to the CUDA device CUDA kernel launch with 196 blocks of 256 threads Copy output data from the CUDA device to the host memory Test PASSED Done
Configure the NGC API Key as secret.
Refer to step 2 to acquire an NGC API key.
kubectl create secret docker-registry ngc-docker-reg-secret \ -n $NAMESPACE --docker-server=nvcr.io --docker-username='$oauthtoken' \ --docker-password=$NGC_CLI_API_KEY
Fetch the Helm Chart.
The Helm chart for cuOpt can be found in the
Helm Chartstab in NGC. Please copy the fetch tag from cuOpt Helm page and use it as follows:helm fetch <FETCH-TAG-COPIED-FROM-NGC> --username='$oauthtoken' --password=$NGC_CLI_API_KEY --untar
Run the cuOpt server.
For GA:
helm install --namespace $NAMESPACE nvidia-cuopt-chart cuopt --values cuopt/values.yaml
For EA:
helm install --namespace $NAMESPACE nvidia-cuopt-chart cuopt-ea --values cuopt-ea/values.yaml
It might take some time to download the container, which is shown in the status as PodInitializing; otherwise it would be Running. Use the following commands to verify:
kubectl -n $NAMESPACE get all
NAME READY STATUS RESTARTS AGE pod/cuopt-cuopt-deployment-595656b9d6-dbqcb 1/1 Running 0 21s NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE service/cuopt-cuopt-deployment-cuopt-service ClusterIP X.X.X.X <none> 5000/TCP,8888/TCP 21s NAME READY UP-TO-DATE AVAILABLE AGE deployment.apps/cuopt-cuopt-deployment 1/1 1 1 21s NAME DESIRED CURRENT READY AGE replicaset.apps/cuopt-cuopt-deployment-595656b9d6 1 1 1 21s
Test the deployment with examples listed under container testing
Uninstalling NVIDIA cuOpt Server:
helm uninstall -n $NAMESPACE nvidia-cuopt-chart