

KVBM Integrations
KVBM Integrates with Inference frameworks (vLLM, TRTLLM, SGLang) via Connector APIs to influence KV caching behaviour, scheduling, and forward pass execution. There are two components of the interface, Scheduler and Worker. Scheduler(leader) is responsible for the orchestration of KV block offload/onboard, builds metadata specifying transfer data to the workers. It also maintains hooks for handling asynchronous transfer completion. Worker is responsible for reading metadata built by the scheduler(leader), does async onboarding/ offloading at the end of the forward pass.
Typical KVBM Integrations
The following figure shows the typical integration of KVBM with inference frameworks (vLLM used as an example)
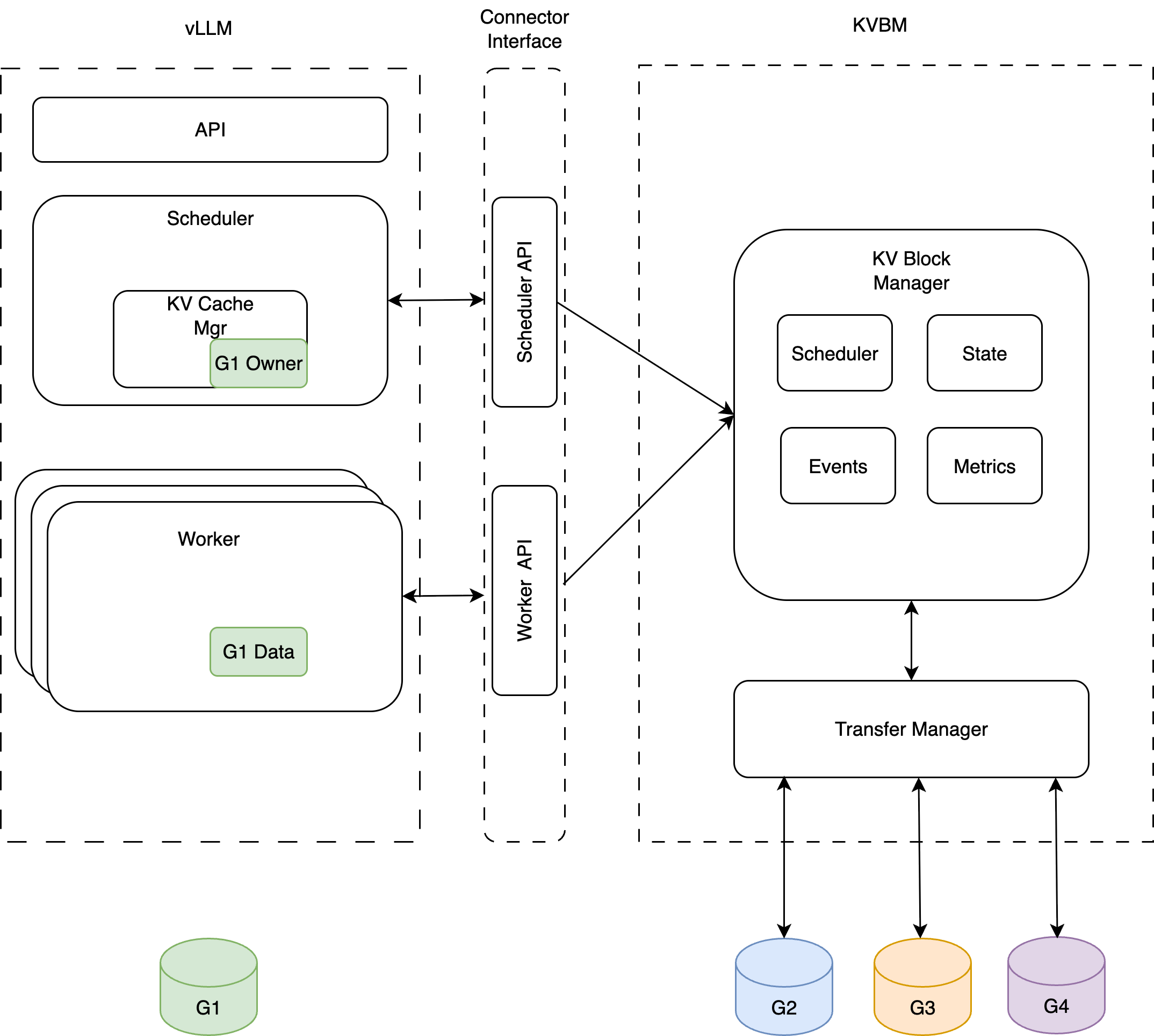 vLLM KVBM Integration
vLLM KVBM Integration
How to run KVBM with Frameworks
- Instructions to run KVBM in vLLM
- Instructions to run KVBM with TRTLLM
Onboarding
 Onboarding blocks from Host to Device
Onboarding blocks from Host to Device
 Onboarding blocks from Disk to Device
Onboarding blocks from Disk to Device
Offloading
 Offloading blocks from Device to Host&Disk
Offloading blocks from Device to Host&Disk