TAO Toolkit Overview
Welcome to the trial of TAO Toolkit on NVIDIA AI Launchpad
The NVIDIA TAO Toolkit, built on TensorFlow and PyTorch, simplifies and accelerates the model training process by abstracting away the complexity of AI models and the deep learning framework. You can use the power of transfer learning to fine-tune NVIDIA pretrained models with your own data and optimize the model for inference throughput — all without the need for AI expertise or large training datasets.
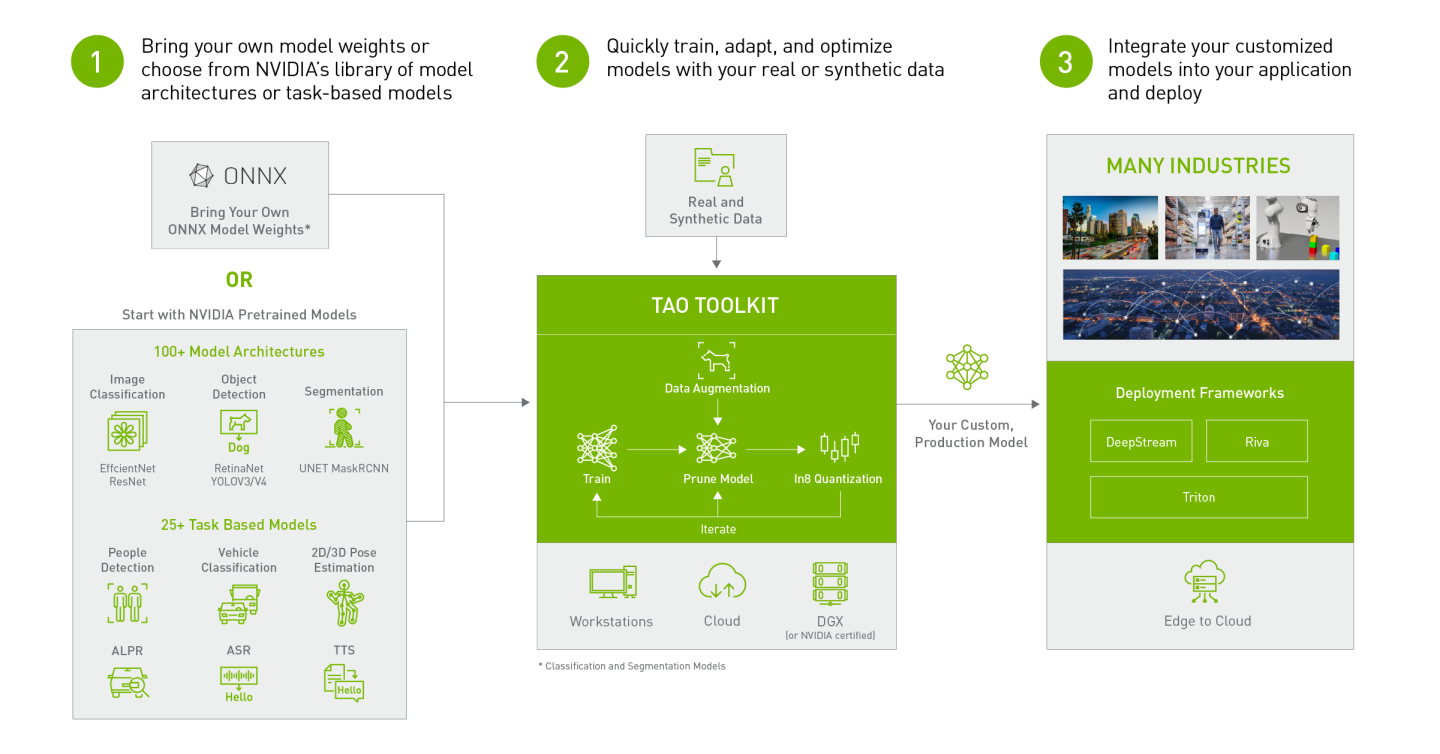
In this lab, you will fully understand how to use TAO Toolkit to finetune and optimize an Object detection model on a custom dataset without any code.
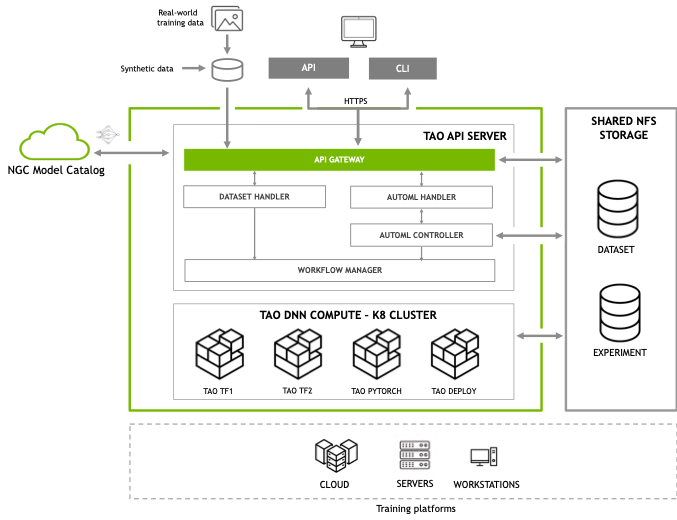
TAO Toolkit Architecture
There is more information available on the TAO Toolkit architecture at this link: TAO Toolkit Architecture
A typical computer vision workflow with TAO Toolkit can be seen at this link: TAO Computer Vision workflow
TAO Toolkit comes with a set of pre-trained computer vision models. There is a table of supported pre-trained models at this link: TAO Computer Vision Model Zoo
What is Object detection?
Object detection is a computer vision task for classifying and putting bounding boxes around images or frames of videos etc. Object detection can be used in many real world applications like self checkout in retail, self driving cars etc. In this lab, you will detect objects in a warehouse.
Challenges with Object detection:
Training a deep learning model for object detection from scratch requires a deep understanding of neural network architectures and clustering algorithms while carefully tuning hyperparameters. Also, training from scratch usually requires a huge amount of data for the model to start showing accurate results. A software engineer with no data science experience, who wants to integrate such a model into his application might find this to be a challenging task. NVIDIA has developed the TAO toolkit to solve these challenges.
Learn how to use TAO APIs to Train and fine-tune AI models
Learn how to optimize AI models for inference performance
Learn how to automatically tuning hyperparameters using AutoML in TAO
You will run three different Jupyter Notebooks as part of this lab
Train a custom object detection model using YOLOv4, this is done by running notebook lab1-yolo_training.ipynb
Data input & conversion
Model Training using YOLOv4 with default hyperparameters
Evaluate model accuracy
Optimize model with TAO - prune, quantize, TensorRT conversion, this is done by running notebook lab2-yolo_optimization.ipynb
Run TensorRT inference on unpruned model
Model optimization - prune, retrain, model evaluation
Run TensorRT inference on pruned, quantized model
Compare the performance gain between unpruned and pruned model
Use AutoML to find the optimal Hyperparameters, this is done by running notebook lab3-automl.ipynb
Train YOLOv4 model using AutoML to sweep hyperparameters
Evaluate the accuracy of each models
To start each Notebook, click on the Jupyter Notebook link in the left hand navigation pane. This will open a new tab where you can select and run each notebook in turn.
NVIDIA TAO toolkit TAO Toolkit
TAO CLI is part of NVIDIA toolkit and is simple Command Line Interface (CLI), which abstracts away AI framework complexity, enabling you to build production-quality AI models using just a spec file and one of the NVIDIA pre-trained models
TAO Toolkit API is a Kubernetes service that exposes TAO Toolkit functionality through APIs, the service also enables a client to build end-to-end workflows.
The first two steps of the lab will take several hours to complete. The final step, AutoML, will run for approximately 12-18 hours.
TAO Toolkit is part of NVIDIA AI Enterprise which allows AI Practitioners to run Deep Learning workflows in virtual machines with the same performance as a local workstation. AI Practitioners can quickly access Jupyter Notebooks, which leverage NVIDIA GPUs since IT Administrators have all the tools to create VMs with required NVIDIA AI Enterprise components to perform AI Training and deploy inferencing using Triton. This allows AI Practitioners to have instant access to valuable GPU resources within Enterprise data centers.