Overview
Welcome to this LaunchPad hands-on lab, which will walk you through a few examples of how to accelerate operations in Apache Spark 3 using NVIDIA RAPIDS. In this lab, you will have access to an Apache Spark cluster, running on accelerated compute infrastructure, that has the RAPIDS Accelerator for Apache Spark integrated into it. This plugin leverages GPUs to accelerate processing via the RAPIDS libraries.
The RAPIDS Accelerator for Apache Spark intercepts and accelerates ETL pipelines by dramatically improving the performance of Spark SQL and DataFrame operations. Spark 3 provides columnar processing support in the Catalyst query optimizer which is what the RAPIDS Accelerator plugs into to accelerate SQL and DataFrame operators, with zero code changes necessary. When the query plan is executed, those operators can then be run on GPUs within the Spark cluster.
The RAPIDS Accelerator library also has a built-in accelerated shuffle based on UCX that can be configured to leverage GPU-to-GPU communication and RDMA capabilities (not demonstrated in this lab).
Rapids Accelerator for Apache Spark reaps the benefit of GPU performance while saving infrastructure costs.
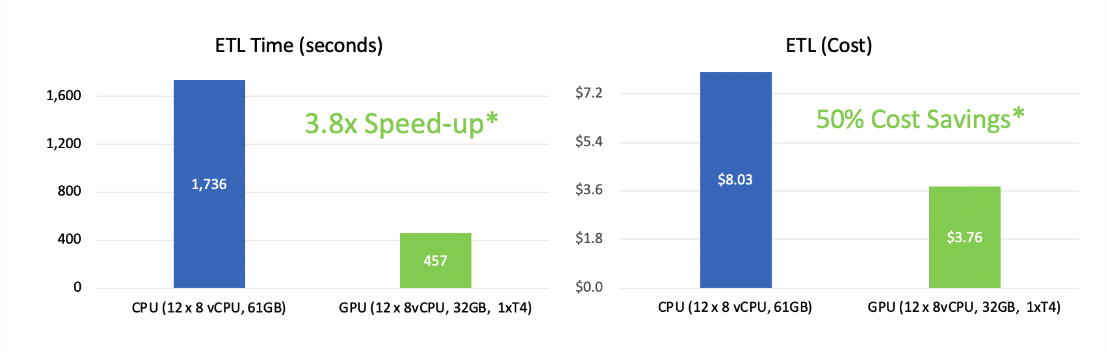
*ETL for FannieMae Mortgage Dataset (~200GB) as shown in our demo. Costs based on Cloud T4 GPU instance market price on Databricks Standard edition
Run your existing Apache Spark applications with no code change. Launch Spark with the RAPIDS Accelerator for Apache Spark plugin jar and enable a configuration setting:
spark.conf.set('spark.rapids.sql.enabled','true')
The following is an example of a physical plan with operators running on the GPU:
== Physical Plan ==
GpuColumnarToRow false
+- GpuProject [cast(c_customer_sk#0 as string) AS c_customer_sk#40]
+- GpuFileGpuScan parquet [c_customer_sk#0] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/customer], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<c_customer_sk:int>
Learn more on how to get started.
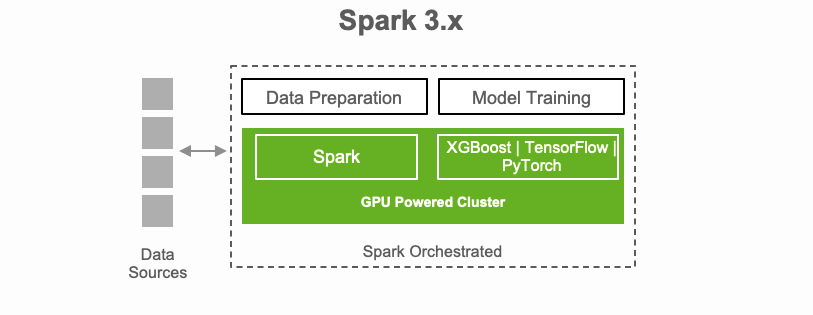
A single pipeline, from ingest to data preparation to model training