Components & Customization
To help understand more and potentially customize the microservice, here’s a deep dive of the components’ implementation and the data flow between them:
Library API
The microservice extensively uses the API from the Analytics Stream library. The microservice pipeline and the API usage are discussed in-depth in the subsequent sections.
When you build a new pipeline using this API (by modifying ours or creating one from scratch), the library dependencies will be fetched from our artifactory.
For more details, refer to the README.md in the metropolis-apps-standalone-deployment/modules/behavior-analytics/ directory.
Protobuf to Object
The protobuf message payload is sent over Kafka as ByteArray, that is a Kafka ProducerRecord has (topic, key, value), where topic=mdx-raw, key=sensor-id and value=protobuf-byte-array. Once the message is received by the Behavior Analytics microservice, it transform the byte array to Frame object. The Frame object maps to the video frame being processed by perception. It contains all the detected objects for a given frame and their corresponding bounding box in a single message. Each object may have additional attributes like embedding vector, pose etc.,
To read more about the schema, refer to the Protobuf Schema.
Usage
Reading metadata from Kafka, with respect to Apache Spark Structured streaming:
/**
* raw Dataset: read protobuf or JSON from kakfa
*/
val rawDataset = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", brokers)
.option("subscribe", appConfig.rawTopic)
.option("startingOffsets", "latest")
.option("failOnDataLoss", false)
.load()
.selectExpr("timestamp", "CAST(key AS STRING)", "value")
.select("timestamp", "key", "value")
.withWatermark("timestamp", watermarkI)
/**
* transform ByteArray to nv.schema.Frame
*/
val frameDataset = rawDataset
.select("value")
.map { row =>
val bytes = row.getAs[Array[Byte]](0)
if(appConfig.dataType.equals("json")) {
//input data format is json
val json = new String(bytes, java.nio.charset.StandardCharsets.UTF_8)
SchemaUtil.jsonToNvFrame(json)
} else {
//input data format is protobuf
Frame.parseFrom(bytes)
}
}
Definition
Frame Object definition:
/**
* @param version represents version of the schema
* @param id represents the video frame-id
* @param timestamp represents the camera timestamp
* @param sensorId Unique sensor-id
* @param objects List of objects, where each object is represented using nv.schema.Object
*
*
*/
case class Frame(
version: String,
id: String,
timestamp: Option[com.google.protobuf.timestamp.Timestamp],
sensorId: String,
objects: Seq[nv.schema.Object])
The raw frame object is translated to JSON before being stored in Elasticsearch, the JSON representation is as below.
{
"version": "4.0",
"id": "252",
"timestamp": "2022-02-09T10:45:10.170Z",
"sensorId": "xyz",
"objects": [
{
"id": "3",
"bbox": {
"leftX": 285.0,
"topY": 238.0,
"rightX": 622.0,
"bottomY": 687.0
},
"type": "Person",
"confidence": 0.9779,
"info": {
"gender": "male",
"age": 45,
"hair": "black",
"cap": "none",
"apparel": "formal"
},
"embedding": {
"vector": [
1.4162299633026123,
-0.28852298855781555,
1.1123499870300293,
-0.047587499022483826,
-2.293760061264038,
0.8388320207595825
]
}
}
]
}
Image to Global Coordinate Transformation
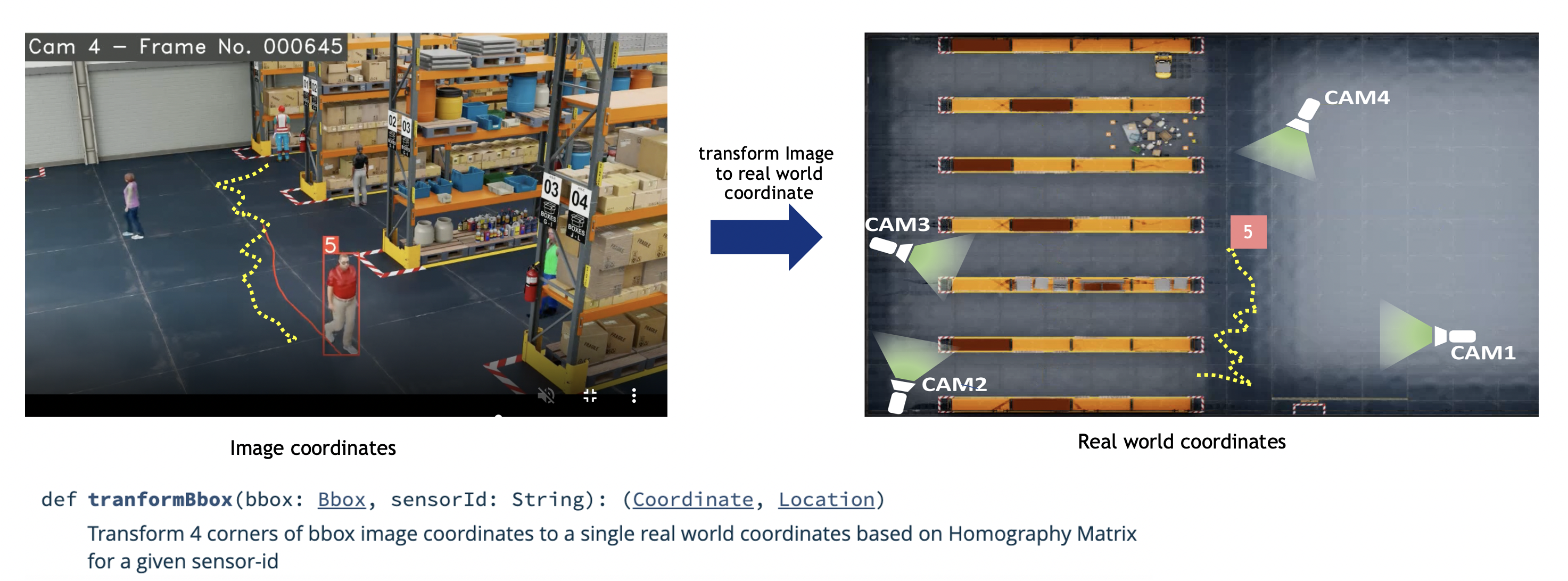
The Frame metadata contains information about object-id, bounding box in image/pixel coordinates, object-type and secondary attributes where applicable. In the above diagram, the yellow dots in the left image represent the movement of a Person in image coordinates. The image coordinates are obtained by taking the bottom-middle of the bounding box. The right side of the diagram shows the movement or behavior on floor plan map real world coordinates, i.e., geo coordinates (lat/lon WGS-84) or building map coordinates (in meters).
The bounding box coordinates are transformed to real world coordinates using a homography matrix. This homography matrix is generated as part of the calibration process. The real world coordinates provide the exact location of object and are used subsequently for doing various spatial-temporal analytics.
Usage
import com.nvidia.mdx.core.transform.CalibrationE
//each message represent a object
val messageDataset =
frameDataset.map(
frame =>
SchemaUtil.nvFrameToMessages(frame) //single frame contains multiple objects
)
.flatMap(msgs => msgs)
.map { msg =>
CalibrationE.transform(msg, configbc.value)
}
Note
For geo coordinates, use Calibration.
API
/**
Checks if the given Location falls within the ROI for the given intersection.
**/
def pointInPolygon(loc: Location, sensorId: String, configbc: Map[String, String] = Map.empty): Boolean
/**
Transform 4 corners of bbox image coordinates to a single real world coordinates based
on Homography Matrix for a given sensor-id
Also transform real world coordinates (cartesian) to lat-lon, with respect
to a given origin. The transformation matrix and the origin are initialized
from an external configuration if transformation matrix is not present, it will return image coordinates
**/
def tranformBbox(bbox: Bbox, sensorId: String): (Coordinate, Location)
/**
internally invokes tranformBbox and Returns updated Message
**/
def transform(msg: Message, configuration: Map[String, String] = Map.empty): Message
Definition
Message represents a single object + contextual data:
case class Message(
messageid: String,
mdsversion: String,
timestamp: Option[Timestamp],
place: Option[Place],
sensor: Option[Sensor],
analyticsModule: Option[AnalyticsModule],
object: Option[Object],
event: Option[Event],
videoPath: String
)
Behavior State Management (BSM)
As the perception layer tracks a given object, the object-id remains the same during the time the object is seen by a single camera. This helps in forming a Behavior for a given object. Behavior defines the sequence of real world coordinates an object was detected at, its appearance, embeddings, pose etc., The span of the Behavior may be short lived based on how long it was seen with respect to a given camera. There are cases where the span of the Behavior can be very long. An example is a car stopped due to a red signal or a car parked on the roadside or a person standing in a queue.
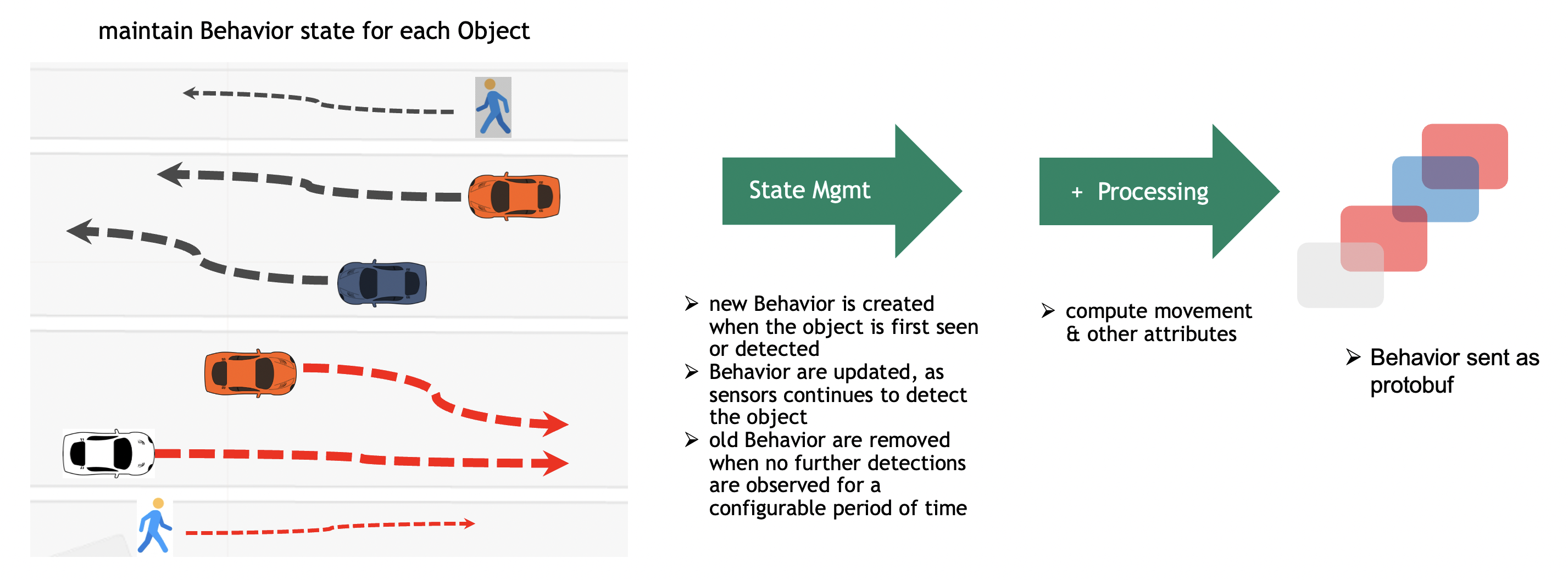
The above diagram, depicts a few tracks with respect to vehicle & people movement as seen by the camera. However, this can be any kind of object like a robot, a bicycle etc. The BSM maintains the Behavior state on live streaming data. As the objects are detected by the perception layer and Frame metadata sent over the network to the Kafka broker, the Behavior Analytics pipeline consumes all detections corresponding to an object and maintains the Behavior state in memory. The in-memory copy of the Behavior is backed up by a persistent store for reliability. The Behavior gets updated when the perception layer sends more detection metadata with respect to the same object. At some point of time, the object gets out of the Field of View of the camera and no more metadata is sent to the BSM, the BSM cleanup the Behavior corresponding to object which is not seen any more. The period of time before which BSM cleanup the state is configurable. To keep the memory footprint of behavior state low, only minimal information is stored during the life of the behavior, the state comprise of object-id, sensor-id, locations, start & end timestamps, object embeddings etc.,
Behavior State Management API
Usage
import com.nvidia.mdx.core.stream.StateMgmt
// init state management
val stateMgmt = new StateMgmt(config)
//usage for dataset of Message
messageDataset
.groupByKey(msg => msg.key)
.mapGroupsWithState(processingTimeTimeout())(stateMgmt.updateBehaviorE)
Definition
case class ObjectState(
id: String,
start: Timestamp,
end: Timestamp,
points: List[Coordinate],
sampling: Int = 1,
lastXPoints: List[Coordinate] = List.empty,
object: Object = null,
embeddings: Array[Embedding] = Array.empty) extends Product with Serializable
API
import com.nvidia.mdx.core.stream.StateMgmt
//internally named ObjectState, the ID is uniquely identified using sensorId + ObjectId
/**
Tracks and maintains state for a given object Euclidean space , internally named ObjectState, the ID is uniquely identified using sensorId + ObjectId
It does the following functions
- remove any ObjectState which is timed out
- create new ObjectState, if no similar objectId was seen before or existing ObjectId was last seen long time back
- update existing ObjectState if the new data event timestamp is within configurable time span
- prune ObjectState as needed, when the object is seen for long period of times, say parked car, the number of points are pruned to reduce the memory footprint
- generate List of embeddings representing different variantions in an object
- ObjectState state management saves/stores least amount of information to reduce the storage,
ObjectState comprise of
- sensorId + objectId
- start and end timestamp
- sequence of geo points
- List of embedddings representing a object, thousands of embeddings can get generated for an given object, which are clusered using com.nvidia.mdx.core.util.CRP
- other attributes like Pose, Gaze, Gesture
The internal state is translated to Object nv.schema.ext.Behavior before sending it to any sink for consumption
**/
//Tracks and maintains state for given Objects in real world coordinates,
def updateBehaviorE(objectId: String, inputs: Iterator[Message], groupState: GroupState[ObjectState]): Option[Behavior]
//Tracks and maintains state for given Objects in Cartesian coordinates, along with tracklet, which is part of the behavior to be used for generating trip events
def updateBehaviorEwithTripwire(objectId: String, inputs: Iterator[Message], oldState: GroupState[ObjectState]): Option[(Behavior, Behavior)]
//used for batch inference of behavior
def groupBySensorId( id: String, inputs: Iterator[Behavior])
Note
For each method in StateMgmt there is corresponding Sink writer, which processess the outputs like - Behavior, Behavior+tripEvents or BehaviorList. See Sink.
Embeddings Cluster
Behavior comprises of sequence of real world coordinates an object was detected at, its appearance, embeddings, pose etc., The embeddings or the feature vector represents the object appearance, these embeddings are generated continuously and may vary based on factors like lighting, camera angle and field of view. Embeddings cluster tries to summarize 100s of feature vectors into few salient ones that can be used to represent an object appearance. The cluster algorithm used is CRP, it is a non-parametric generative Bayesian model, the data is processed in a streaming mode, clustering is done in an incremental model. As the sequence of embeddings are processed by the pipeline, it simultaneously learns the number of clusters, the model of each cluster, and entity assignments into clusters. The state of the cluster model is maintained by computing the cluster centers across every micro batch.
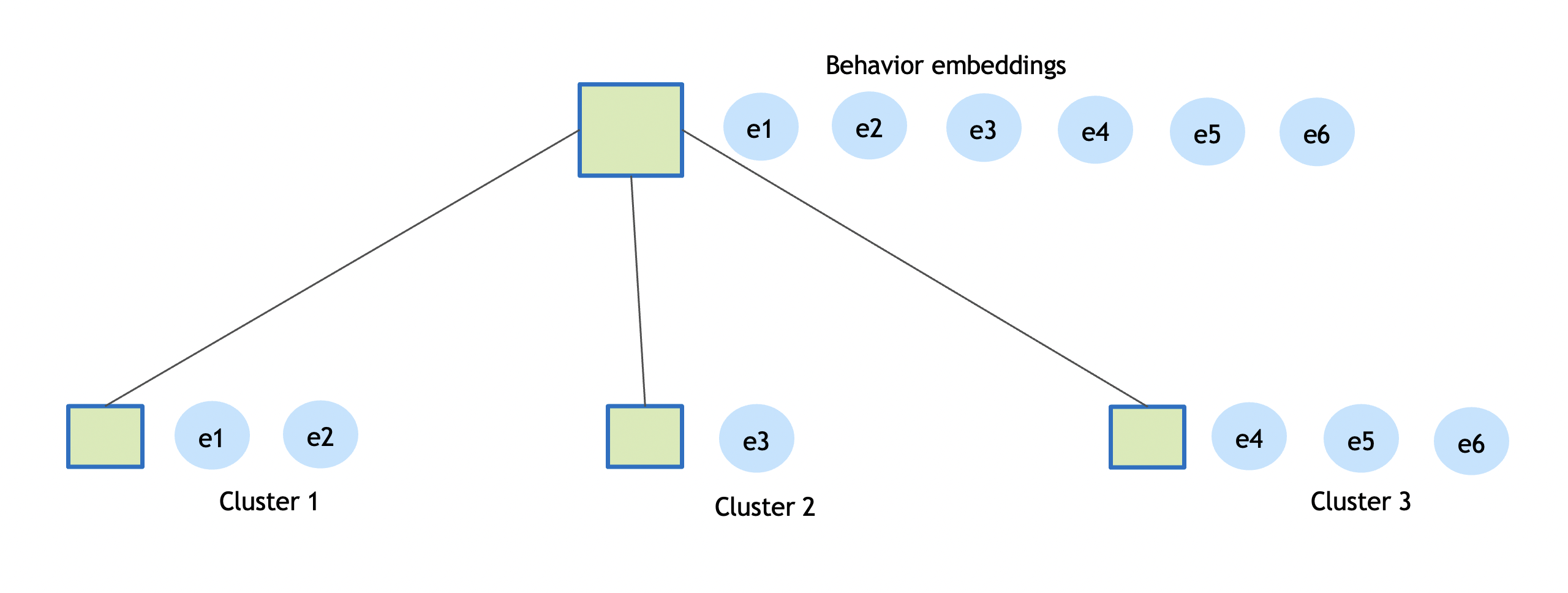
The diagram above shows only a few embeddings instead of 100s, idea is how to create few representative embeddings from all the detections for a given Object. The clustering distance used is cosine similarity and default threshold is 0.9. The clustering process completes when a object is no more detected by a sensor. At of end of each micro batch the cluster centers are computed and stored in the Milvus vector database for query. This allows any search with respect to a reference embedding. Example search all detection of an object across multiple sensor in a given time interval. This search mechanism is called Query by Example. More details can be found over here.
Usage
import com.nvidia.mdx.core.util.CRP
//Given a list of normalized vectors create the CRP cluster model.
//default pnew=0.9, threshold for creation of new cluster
//if given a new vector is not close enough to any of the existing cluster.
//takes two inputs, vecs = Array[Embedding], pnew = cosine similarity threshold
val model = CRP.cluster(vecs, 0.9)
Example
If a query is made with respect to a reference embedding, one can get the get the list of behavior which are nearest. Below provides an example. Note that behaviorId = sensorId + objectId.
Query = "Building_K_Cam1 #-# 7"
Result = ["Building_K_Cam5 #-# 44","Building_K_Cam7 #-# 5","Building_K_Cam6 #-# 88"]

The above pic only shows a frame / point of time for given behavior.
Behavior Processing
Behavior Attributes
The key attributes of the Behavior are based on object movement + Object appearance with highest confidence + Sensor + Place + Embeddings + Pose + Gesture + Gaze:
Name |
Description |
|---|---|
id |
unique id of the Behavior, default implementation used <b>sensor-id + object-id. The object-Id is generated by sensor-processing layer. The sensor-processing layer tracks a objects over time and assigns it a unique id. To make the Behavior id unique across all sensors, a combination of sensor-id and object-id is used. |
bearing |
given two end points of the Behavior represents the initial bearing/direction. Given a sequence of points representing Behavior, the start and end is used as the two endpoints. |
direction |
represents the direction in which object is moving, bearing is converted to direction like East, West, North or South |
distance |
in meters, approximate distance computed based on movement of object for each point in the Behavior |
linearDistance |
Euclidean distance between start and end of Behavior |
speed |
average speed in miles per hour (mph), computed based on distance traversed over time internal of the Behavior |
speedOverTime |
speed in miles per hour (mph), The speed computation over time is computed based smaller segments of the Behavior. default is every segment with a span of 1 seconds speed is computed |
start |
start timestamp in UTC of the Behavior |
timeInterval |
time span of the Behavior in seconds |
locations |
representing array of [lon,lat] or [x,y] |
smoothLocations |
representing smoothened array of [lon,lat] or [x,y] |
edges |
The edges represents the roadsegment of open street map (OSM). Each edge has unique id, road network edges, only applicable for geo coordinates |
place |
where object was detected |
sensor |
which detected the object |
object |
represents type of object and its appearance attributes |
event |
can be “moving”, “parked”, etc., |
videoPath |
URL of the video if stored |
embeddings |
array of embeddings |
pose |
array of pose estimations |
gesture |
array of gesture estimations |
gaze |
array of gaze estimations |
Movement Attributes
For geo coordinates i.e., Latitude, Longitude. Trajectory is used. For Cartesian coordinates, TrajectoryE is used:
import com.nvidia.mdx.core.schema.trajectory.Trajectory
val t = Trajectory(id, start, end, locations)
// compute movement behavior or attributes
t.bearing
t.direction
t.distance
t.timeInterval
t.speed
t.speedOverTime
t.smoothTrajectory
Note
For Cartesian coordinates use
TrajectoryEFor image coordinates use
TrajectoryI
Average Speed Computation
The distance computation is made with respect to two consecutive points in the smoothened trajectory. The trajectory distance is the sum of all the individual distances obtained between consecutive points.
Distance computation uses the Haversine formula to calculate the great-circle distance between two points – that is, the shortest distance over the earth’s surface.
Compute distance d between two consecutive points:
val a = sin²(Δφ/2) + cos φ1 ⋅ cos φ2 ⋅ sin²(Δλ/2)
val c = 2 ⋅ atan2( √a, √(1−a) )
val d = R ⋅ c
// where φ is latitude, λ is longitude, R is earth’s radius (mean radius = 6,371km);
// note that angles need to be in radians to pass to trig functions!
val TrajectoryDistance = Σd
val averageSpeed = TrajectoryDistance / time-interval
Note
For Cartesian and image coordinates euclidean distance is used.
Speed Computation Over Time
Here is an example of Vehicle moving East with an average speed of 29.95 miles/hr, covered 212.87 meters in 15.90 seconds. However, the average speed may not exactly depict the vehicle speed, how it changes over time. If we consider the speed over time, it looks as below:
speedsOverTime = [35.37, 26.53, 28.63, 30.53, 27.51, 28.34, 29.4, 30.33, 28.79, 26.76, 25.54, 24.71, 23.98, 23.39, 24.32]
The speed computation over time is computed based on smaller segments of the trajectory. default is every segment with a span of 1 seconds speed is computed.
Direction
The Direction is computed based on the bearing of the Object.
The formula is for the initial bearing which if followed in a straight line along a great-circle arc will take you from the start point to the end point:
def bearing(from: Location, to: Location) = {
val p1 = from.copy(from.lat * DEGREES_TO_RADIANS, from.lon * DEGREES_TO_RADIANS)
val p2 = to.copy(to.lat * DEGREES_TO_RADIANS, to.lon * DEGREES_TO_RADIANS)
val dLon = p2.lon - p1.lon
val y = Math.sin(dLon) * Math.cos(p2.lat);
var x = Math.cos(p1.lat) * Math.sin(p2.lat) - Math.sin(p1.lat) * Math.cos(p2.lat) * Math.cos(dLon);
val brng = Math.atan2(y, x) * RADIANS_TO_DEGREES
brng
}
Note
For Cartesian and image coordinates the angle with the x axis is used.
The direction definition based on bearing is as follows:
def direction(bearing: Double) = {
val x = ((bearing / 90) + .5).toInt
val arr = List("N", "E", "S", "W")
arr(x % 4)
}
Note
For Cartesian and image coordinates left, right, up & down is used.
Behavior Clustering
Inference Service
Inference Service is based on Triton Inference Server: https://github.com/triton-inference-server/server.
Inference Model
The Model input is a batch of Behavior, each behavior is represented by tensor of shape [100,2], i.e., array of locations represented by [x,y] or [lng,lat]. The return value is cluster index to which behavior belongs.
name: "a-sensor-id"
platform: "pytorch_libtorch"
max_batch_size: 1000
input [
{
name: "input__0"
data_type: TYPE_FP64
dims: [-1, 100, 2]
}
]
output [
{
name: "output__0"
data_type: TYPE_INT32
dims: [-1, 1]
}
]
Inference API
Check Server
Interface to access triton inference server, using a gRPC client, example usage below:
TritonInferenceClient.config = Util.readConfig("config.json")
Check Channel Ready
TritonInferenceClient.channelReady(false)
//server API
TritonInferenceClient.serverLive()
TritonInferenceClient.serverReady()
TritonInferenceClient.serverMetadata()
Check Model
val model = "a-sensor-id" // models have same name as sensorId
//model API
TritonInferenceClient.modelReady(model)
TritonInferenceClient.modelMetadata(model)
TritonInferenceClient.modelConfig(model)
Use Inference API to Cluster
Linear Interpolate
val tensor = (1 to 40).map(x => Array(x.toDouble, 100 + x.toDouble)).toArray
val interpolate = TritonInferenceClient.linearInterpolate(tensor, 100)
//inference
val behaviorArray : Array[Behavior] = provide interpolated Behavior array
val (clusterArr, modelVersion) = TritonInferenceClient.inferWithJson(model,behaviorArrayArray, config)
The movement pattern based on clustering is shown below:

Tripwire Events
Tripwire definition is part of the camera/sensor calibration JSON. A sensor may have more one tripwires defined with respect to it. The wire is defined with respect to two points p1 and p2 as shown in the diagram below. Along with the wire definition a direction is defined. The convention followed while defining the direction is that p1 corresponds to IN while p2 corresponds to OUT.
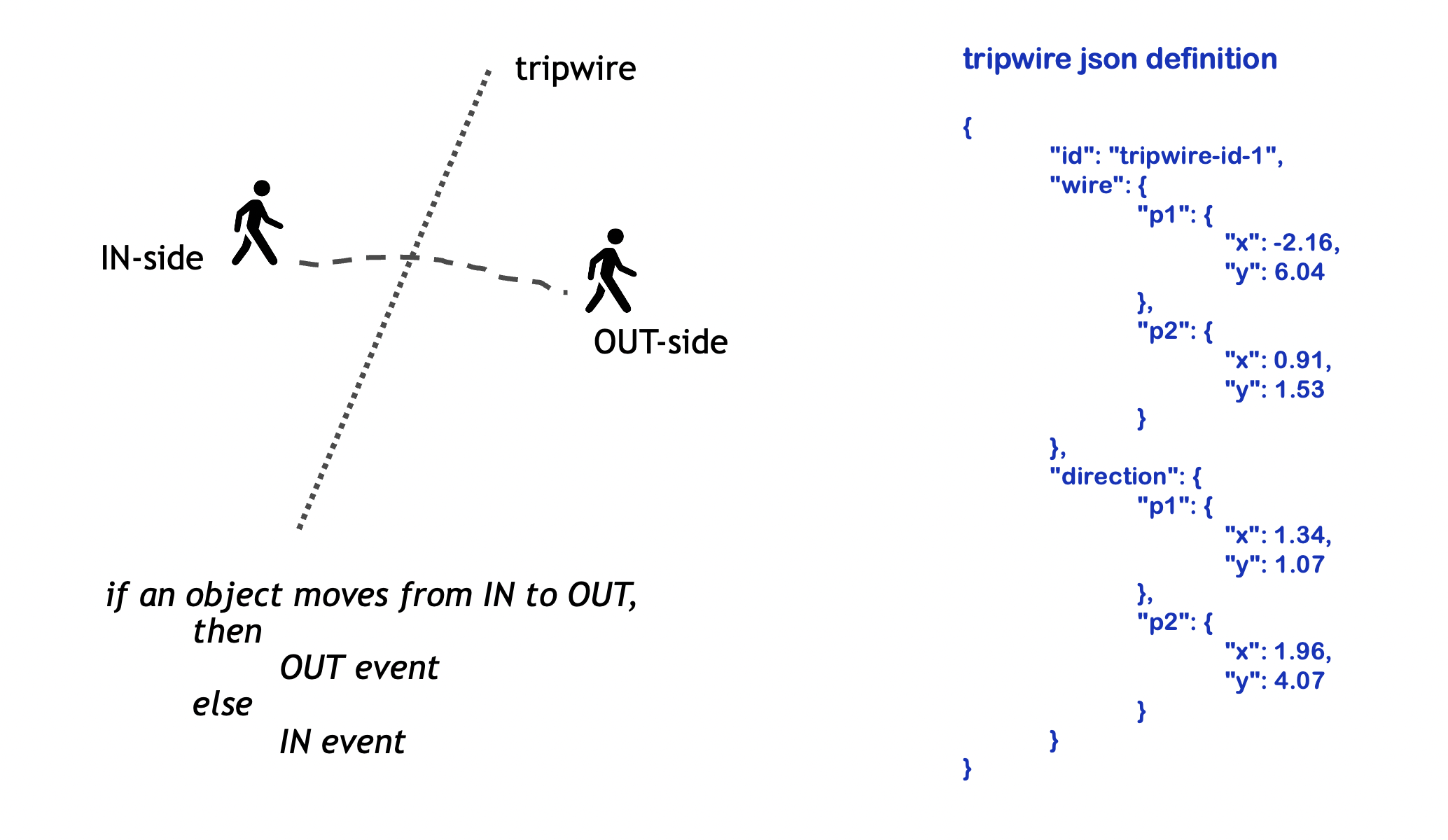
Tripwire API
Usage
import com.nvidia.mdx.core.transform.TripwiresE
//Generate tripevents based on list of locations in a Behavior object
//used for cartesian coordinates
val tripEvents = TripwiresE.tripEvents(behavior, config)
Definition:
The Behavior object contains the locations, start and end timestamp, from the trajectory based on the same object.
Takes the formed trajectory and split it into multiple tracklets, these tracklets are overlapping with a length of minTripLength. the minTripLength is defined based on the trip criteria, example tracklet will be considered tripping a wire if there are “x” number of points before and after the tripwire each tracklet is checked against the tripwire and the function return the list of which has tripped:
API
def tripEvents(tm: Behavior, configbc: Map[String, String] = Map.empty): List[Behavior]
Note
For image coordinates use TripwiresI.
Proximity Detection
This component detects social distancing violations, based on configured “proximity-detection-threshold”. The object detected are clustered using dbscan and reports the cluster of points/object-ids involved in the violation:
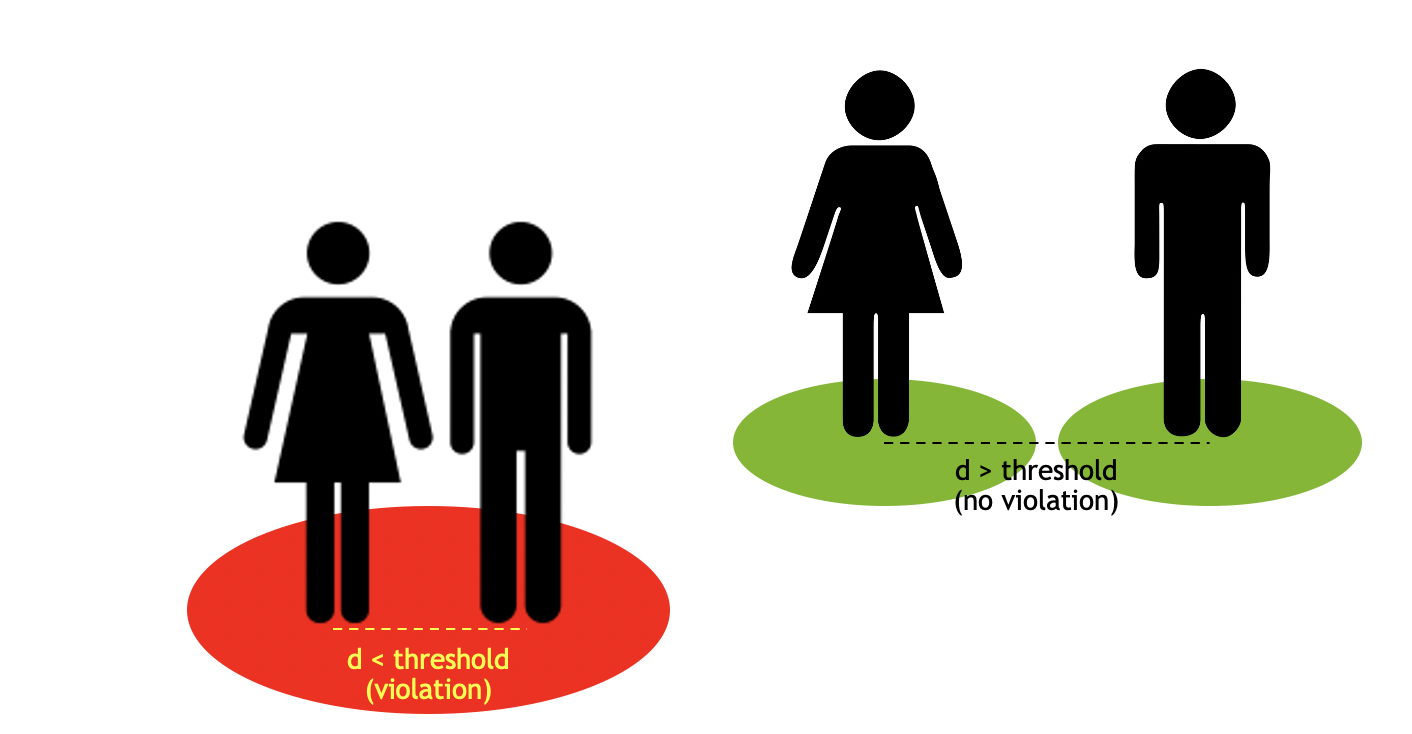
Usage
import com.nvidia.mdx.core.transform.CalibrationE
//dataset of frames:
frameDataset
.groupByKey(f => f.sensorId)
.mapGroups { case (id, frames) =>
frames.toList
}
.map { frames =>
CalibrationE.transformFList(frames, configbc.value)
}
API
Enhance frame message, with cluster of objects violating social distancing. detects social distancing violations, based on configured “proximity-detection-threshold” reports the cluster of points/object-ids involved in the violation:
//transform, enhance frames with ROI, FOV count, proximity detection
//also smoothen coordinates over a window of 5 points
def transformFList(frames: List[Frame], config: Map[String, String] = Map.empty): List[FrameMessage]
Field of View (FOV) and Region of Interest (ROI) Count
The above also generated the FOV and ROI Count, based on each object type, example JSON when FrameMessage is translated to JSON, note object details not shown below:
{
"version": "1.0",
"id": "285457",
"timestamp": "2020-06-11T04:00:00.022Z",
"sensorId": "Endeavor_Cafeteria",
"objects": [ ],
"fov": [
{
"type": "Person",
"count": 2
},
{
"type": "Vehicle",
"count": 3
}
],
"rois": [
{
"id": "roi-1",
"type": "Person",
"count": 2
},
{
"id": "roi-2",
"type": "Vehicle",
"count": 3
}
}
Sink
Sink is based on org.apache.spark.sql.ForeachWriter. There are two different of sink, Kafka & Milvus. Kafka sink is used to push all the Behavior, Event, Frames data to relevant Kafka topics. Milvus Sink used to persist embeddings to the vector database Milvus. One can add other data sink based on the use case.
Usage
import com.nvidia.mdx.core.stream.Sink
// init Sink
val sink = Sink(config)
//use the kafka sink writers
val behaviorQuery = dataset // dataset of Message
.groupByKey(msg => msg.key) //represents unique object-id
.mapGroupsWithState(processingTimeTimeout())(stateMgmt.updateBehaviorE)
.writeStream
.option("checkpointLocation", checkpoint_behavior) //checkpoint location
.foreach(sink.behaviorEWriter) //write behavior to kafka
Note
stateMgmt.updateBehaviorE produces an output, which is consumed by sink.behaviorEWriter. For more information, refer to the Behavior State Management API.
The Sink implementation consists of multiple ForeachWriter as shown below. You’ll have to choose the appropriate one for your use case.
API
//behavior writer for euclidean or cartesian coordinates
val behaviorEWriter: ForeachWriter[Option[Behavior]]
//behaviorE writer used for tripwire, take two inputs,
//the original behavior and tracklet to be used for tripwire event detection
val behaviorEWithTripwireWriter: ForeachWriter[Option[(Behavior, Behavior)]]
//behavior writer for Inference As a Service,
//inference is done using Triton Inference Server
//the current inference service is used find cluster index in which a trajectory belong
val behaviorInferenceWriter: ForeachWriter[(String, List[String])]
//frames writer used for enhanced frame, this is not part of stateMgmt,
//frames are transformed using CalibrationE
val framesWriter: ForeachWriter[FrameMessage]
Writing your own sink
Follow the example code below:
//example writer implementation
val behaviorWriter = new ForeachWriter[Option[Behavior]]{
log.info("init frame writer")
var producer: KProducer = _
override def open(partitionId: Long, version: Long) = {
producer = new KProducer(brokers)
true
}
override def process(value: Option[Behavior]) = {
//enrich Behavior object as needed
if(value.isDefined){
val b = value.get
val j = Util.jsonString(b)
producer.send(framesTopic, b.sensorId, j)
//check for anomaly etc, generate alerts
}
}
override def close(errorOrNull: Throwable) = {
producer.close
}
}
Dynamic Calibration
This feature is available for Euclidean or Cartesian coordinate based pipeline.
The service listen to Kafka mdx-notification topic for any calibration changes, specifically homography matrix change or tripwire definition change or ROI definition change the sensor definitions are updated based as the changes triggered by user.
The notification can be triggered by any client, One option is use Rest API to updated the calibration file. The web-API microservice then sends a Kafka message with necessary details or change.
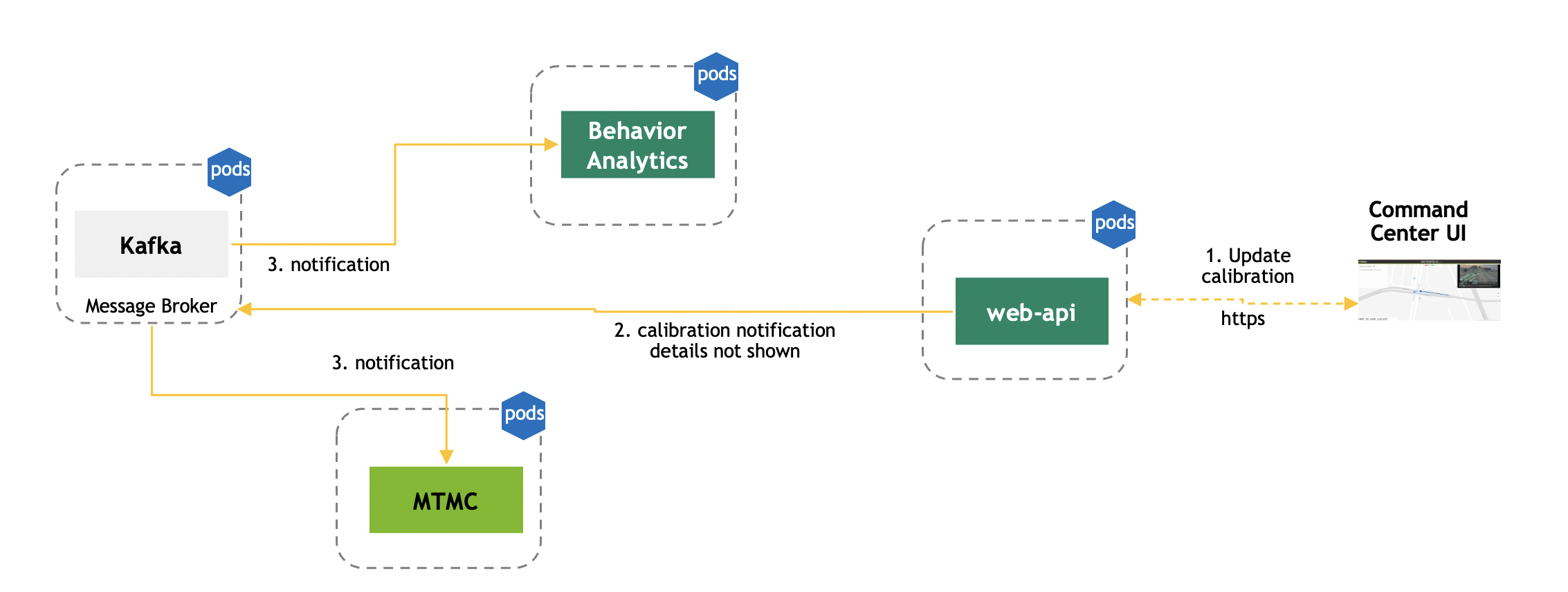
Example
Kafka Notification Message. Details of topic, key, value and headers for an example is shown below:
"topic": "mdx-notification"
"key": "cabibration"
"value": {
"version": "1.0",
"calibrationType": "cartesian",
"sensors": [
"...details not shown..."
]
}
"headers": {
"event.type": "upsert or upsert-all or delete",
"insertTimestamp": "2021-06-01T14:34:13.417Z"
}
Usage
You can also use the interface, to start the monitoring calibration change mdx-notification, while using CalibrationI.transform this is automatically invoked.
Note this runs on distributed system, with spark on multiple executor nodes where the in memory definitions of the sensor is updated based on the notification.
import com.nvidia.mdx.core.transform.CalibrationEListener
CalibrationEListener.start(config)
API
/**
Used to start the threads on executor,
1. This starts the Kafka notification listener, writes the new calibration change in a file
2. Watcher thread, checks new calibration file in a configured folder and update the in memory sensor values
3. Cleaner thread, cleans already processed calibration
4. Kafka producer, request the latest calibration after start, this is optional and works in conjuction with web-API
**/
def start(conf: Map[String, String] = Map.empty): Boolean