Overview
Introduction
The Behavior Analytics microservice is based on Apache Spark Structured streaming and implementation language is Scala.
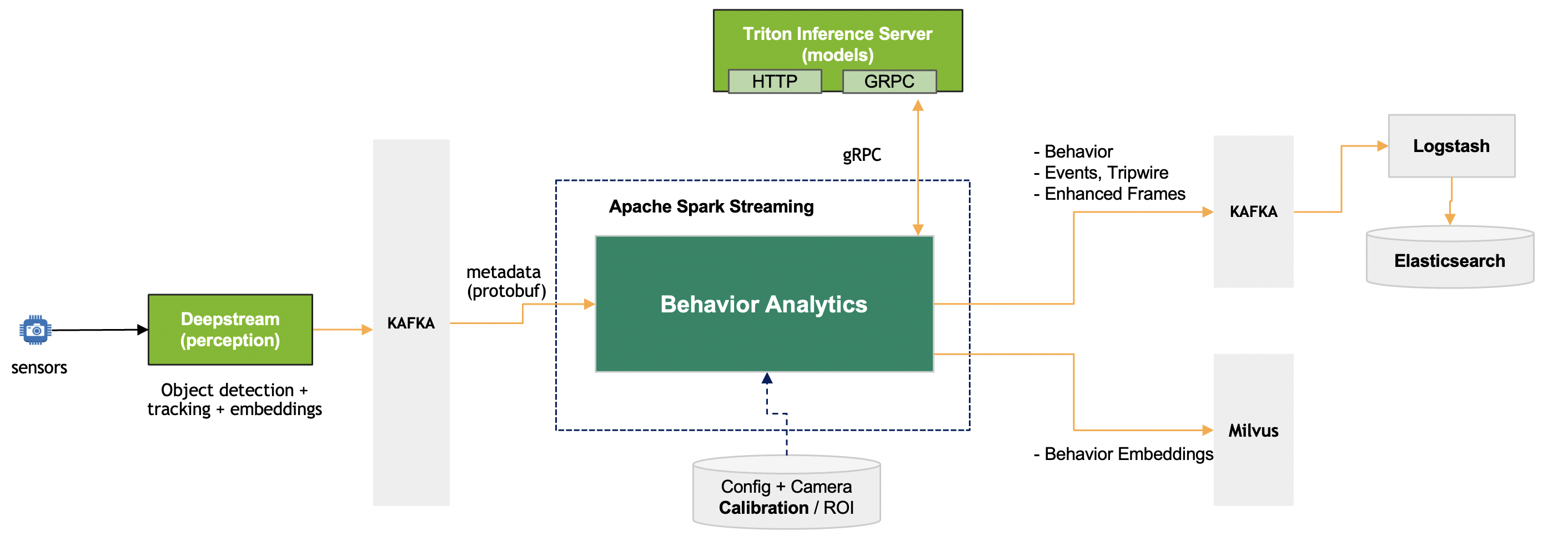
The perception layer read camera/video input streams, sequentially process the frames for object detection and tracking, generates object embeddings, sends protobuf message with frame metadata to the Kafka broker. The diagram above represents the Behavior Analytics pipeline input and output in context of the entire dataflow. The metadata generated by the perception layer represent a frame with details about object detection bbox + tracking ID + embedding vector + other attributes. The input is processed by the pipeline to generate Behavior. Behavior in short is object tracked over a period of time with it attributes. The key component of the pipeline are:
Protobuf Message to Frame: Takes protobuf message / byte array and translates into Frame object.
Image to Real world Coordinate: transform the Image coordinates to real world coordinates (latitude, longitude) or other coordinates system like cartesian. Also, if Region of Interest (ROI) is defined, it checks that the points fall within the defined ROI.
Behavior State Management: Manages state of each object Behavior with respect to single camera, objects across all camera sensors are processed simultaneously.
Behavior Processing: Derives key information like speed, direction and distance based on the movement, appearance, embeddings of the object.
Behavior Clustering: This helps discovering movement patterns over a period of time. The movement could be traffic on road or by people inside a building. The behavior objects are clustered using models deployed on Triton Inference Server. The service is used for assigning cluster index to an instance of object-behavior.
Event Detection: There are different kind of events which are generated by the pipeline. These events are Tripwire, Social distancing violation, ROI detections.
Sink: The Behavior and events generated by the Behavior Analytics pipeline is send to Kafka and Behavior embeddings are stored in Milvus vector database.
Input & Output
The various stages of the pipeline is shown below, with inputs and outputs for each sub-component.
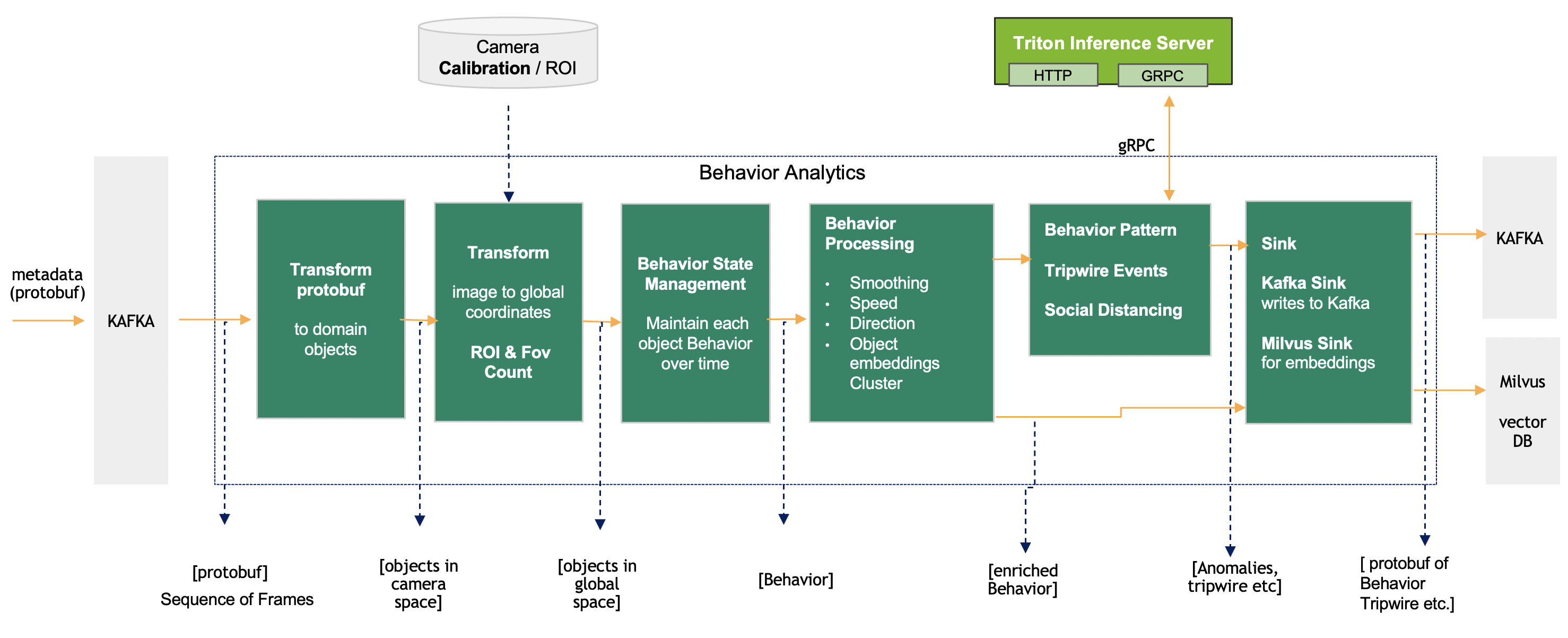
Each of the stages with inputs and outputs:
Transform |
Input (source) |
Output (sink) |
Description |
Protobuf to Frame Object |
Protobuf (Kafka) |
Dataset of Frame Object |
Converts JSON string to Dataset of frames |
Image to Geo Coordinates |
Dataset + Calibration |
Dataset with Geo Coordinates |
Perspective Transform using camera |
Calibration ROI Check |
Dataset + ROI |
Filtered Dataset |
Point in Polygon |
Behavior State Management |
Dataset |
Dataset of Behavior (backed up by persistence storage) |
Maintain state of Behavior for larger number of moving objects |
Behavior Processing |
Dataset of Behavior + Configuration |
Dataset of Behavior with enriched features |
Compute Length /Speed / Direction, Object embeddings cluster |
Sink: Kafka Sink + Milvus Sink |
Dataset of Frame or Behavior |
Protobuf (Kafka) + embeddings (Milvus) |
Puts the dataset to Kafka and embedding to Milvus |
Behavior Cluster Classification |
Dataset of Behavior + per-sensor DL models |
Dataset of Behavior With cluster info |
Based on unsupervised behavior learning , the DL model predicts Behavior cluster |
Tripwire Events |
Dataset of Behavior + tripwire definitions |
Tripwire Events |
Trip events are generated when a Person / Object walks over a tripwire |
ROI + FOI Count SocialDistancing |
Dataset of frames |
enhanced Frames |
ROI and FOV count based on object type detect social distancing violation based on proximity of objects |