Components & Customization
To help understand more and potentially customize the microservice, here’s a deep dive of the components’ implementation and the data flow between them:
Library API
The microservice extensively uses the API from the Behavior Learning library. The microservice pipeline and the API usage are discussed in-depth in the subsequent sections.
Subsequently, the term ‘component’ refers to the parts of the Behavior Learning pipeline, while the term ‘module’ refers to a module of the Behavior Learning library.
When you build a new pipeline using this library (by modifying ours or creating one from scratch), the library dependencies will be fetched from our artifactory.
For more details, please refer to the README.md in the metropolis-apps-standalone-deployment/modules/behavior-learning/ directory.
Ingestion
The Ingestion component is primarily responsible for ingesting data that is used for training and is de-coupled from the Training component itself. This allows ingestion to be a continuous process, while training can be scheduled periodically.
The Ingestion component uses the functions provided by the Ingestion module of the Behavior Learning Library.
from mdx.behavior_learning.ingestion import Ingestion
ingestion = Ingestion(config)
The pipeline starts with fetching the schema of our data using the
get_schema()function.
- get_schema(self)
Returns schema of data. Schema is read from an internal JSON file.
- Returns
returns the schema of the behavior data.
- Return type
pyspark.sql.types.StructType
behavior_schema = ingestion.get_schema()
Next, the streaming data is filtered and formatted using the
format_data()function to enable partitioning in delta.
- format_data(self, df):
Formats the data to the requirements of dedup_and_upsert_to_delta. Adds column hourOfDay which is required for creating partitions in the delta table.
- Parameters
spark_df (pyspark.sql.DataFrame) – spark dataframe to format
- Returns
returns the formatted dataframe.
- Return type
pyspark.sql.Dataframe
formatted_df = ingestion.format_data()
3. Finally, the dedup_and_upsert_to_delta batch writer function is used to write to a delta table. The function de-duplicates data using the set of parameters - sensor id, object ID and start time.
The data is partitioned first on sensor id, and then on the hour of day during which the behavior was generated. If the delta table does not exist, then a delta table is created using the table location specified in the config file.
- dedup_and_upsert_to_delta(self, micro_batch_output_df, batch_id):
Batch writer to upsert data into the delta table. De-duplication of data is done within and across batches. If table is not present, it creates a new table.
- Parameters
micro_batch_output_df (pyspark.sql.DataFrame) – dataframe containing the output of the micro batch
batch_id (int) – id of the micro batch
- Returns
none
query = formatted_df.writeStream.foreachBatch(ingestion.dedup_and_upsert_to_delta)
Combining the pieces, the core pipeline that ingests behavior data using the ingestion module’s functions is given below:
# Import ingestion module from mdx package. from mdx.behavior_learning.ingestion import Ingestion ingestion = Ingestion(config) # Fetch schema of behavior data. json_schema = ingestion.get_schema() # Read data from Kafka. df = spark.readStream.format("kafka")\ .option("kafka.bootstrap.servers", str(config["kafka"]["brokers"]))\ .option("subscribe", str(config["kafka"]["topics"]["behaviorTopic"]))\ .option("failOnDataLoss","true")\ .load() df = df.selectExpr("CAST(key AS STRING)", "CAST(value AS STRING)") df = df.withColumn('value', F.from_json(F.col('value'), json_schema)).select("value.*") # Format data for storage. formatted_df = ingestion.format_data(df) # Write to delta table. query = formatted_df.writeStream\ .foreachBatch(ingestion.dedup_and_upsert_to_delta)\ .outputMode("update")\ .option("checkpointLocation", config["ingestion"]["checkpointLocation"])\ .trigger(processingTime='{}'.format(config["ingestion"]["ingestionTrigger"]))\ .start()Ingestion module also provides a
vacuum_delta()function to delete old data based on a configurable retention period.
- vacuum_delta(self):
Vacuums the delta table based on the data retention period set in config.
- Returns
None
ingestion.vacuum_delta()A separate thread is spawned to run the vacuum periodically.
Model Training
Model training is periodically scheduled to read the newly ingested behavior data and output deep learning models per sensor. Model training consists of four sub components - Data Transformation, Behavior Clustering, Behavior Learning, and Model Management. These are sequentially executed for each sensor.
Data Transformation (Extrapolation)
The sensorId partition column is used to read the Behavior data per sensor. Data is converted to a pandas data frame. Using the DataTransformer module’s extrapolate_locations function, each behavior’s coordinates are extrapolated to a fixed number of points.
- extrapolate_locations(self, location: dict):
Extrapolates the coordinates of a behavior to a configured fixed number of points. The start and end points of the behavior remain the same, intermediary points are redistributed.
- Parameters
location (dict) – location dict/field in behavior data.
- Returns
new location dict with interpolated coordinates.
- Return type
python dict
from mdx.behavior_learning.data_transformer import DataTransformer data_transformer = DataTransformer(config) behavior_df["locations"].map(data_transformer.extrapolate_locations)
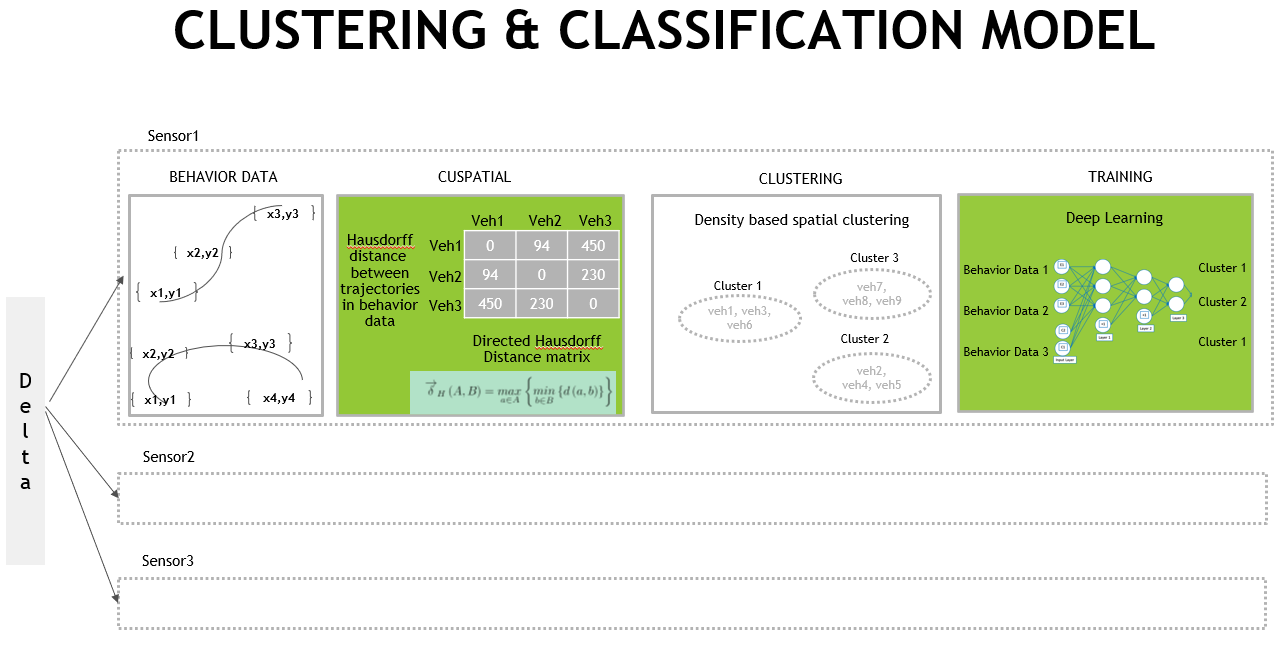
Behavior Clustering
Behavior Clustering is used to generate labelled data for deep learning. Behavior clustering is performed in two steps:
Calculating the directed hasudorff distance matrix and
Using hdbscan to generate cluster labels.
The Behavior Clustering module in the Library provides individual functions for both, but also provides a single wrapper function generate_labels(), that chains both the steps.
- generate_labels(self, behavior_df):
Generates clustering labels for the behavior data.
Calculates the cuSpatial directed hausdorff distance between trajectories contained in the behavior data and uses them as input to hdbscan to cluster behavior.
Makes calls to
directed_hausdorffandrun_hdbscan. Parameters for clustering are taken from the config file.- param pandas.Dataframe behavior_df
pandas data frame containing behavior data.
- return
Input dataframe with an additional column ‘labels’, that contains the cluster labels. Also returns number of clusters and noisy points.
- rtype
(pandas.DataFrame, int, int)
from mdx.behavior_learning.nn.behavior_clustering import BehaviorClustering
behavior_clustering = BehaviorClustering(config)
labelled_data, num_clusters, num_noise = behavior_clustering.generate_labels(behavior_data)
The generated labels are added to the behavior data and a labelled data frame is returned by the function.
In the pipeline, this data is passed to the Behavior Learning component for model training.
Optional - Clustering Internals
Internally, the computation of hausdorff distance is done using the RAPIDS cuSpatial library.
This allows the use of the GPU to efficiently compute the distance matrix.
The distance matrix outputted by hausdorff is then converted into a numpy array and given as input to hdbscan. Hdbscan uses the parameters minPtsForCluster and minSampleForCore in the config file and runs the clustering algorithm.
The parameters minPtsForCluster and minSampleForCore determine how conservative the clustering should be.
The number of clusters is automatically determined by hdbscan. Cluster labels start from 0 and are monotonically increasing.
Behaviors which are not part of a cluster are given the label -1.
Additional parameters such as encodeProperty, that enable clustering to take into account direction or flow, can be set in the config file to tune the clustering to a specific use case.
More details are provided in the configurations section.
Behavior Learning
The behavior learning component outputs PyTorch deep learning models that are trained on behavior data.
The behavior learning module in the Behavior Learning Library provides a single function call train_and_export_model() that takes behavior data as input and produces deep learning models trained on it.
- train_and_export_model(self, training_data):
Outputs a deep learning model trained on the behavior data. Behavior data’s location field is used for features.
Training parameters are taken from the config file.
Internally uses
BehaviorLearning.instantiate_modelandBehaviorLearning.train_model.
- Parameters
data (pandas.Dataframe) – Data to train on. Internally divided into training, testing and validation sets.
- Returns
trained model and training and validation stats as a python dict.
- Return type
(nn.Module, dict)
from mdx.behavior_learning.nn.behavior_learning import BehaviorLearning behavior_learning = BehaviorLearning(config) model, training_results = behavior_learning.train_and_export_model(labelled_df)
Optional - Deep Learning Internals
Internally, the behavior data is first passed to a pre-processing function which converts the behavior coordinates into features to be trained on.
A three layered fully connected neural network (FCNN) is used for training. The model is configured based on parameters specified in the config file.
Finally, the model is trained on the labelled behavior data using the GPU, and the trained model and the training stats are returned.
The function for each of the intermediary steps are also provided for more custom use cases.
The training pipeline uses the train_and_export_model function to produce trained models on the labelled data.
Model Management
The model management component saves the models created in the previous step. It uses the save_model() function provided by the ModelManagement module in the library.
- save_model(self, model, sensor):
Saves model, by packaging and writing model to
model_repository.
Model_repositoryvalue is set using the config file.Currently only supports pytorch models.
- Parameters
model (nn.Module) – model to be saved.
sensor (string) – sensor corresponding to the model.
- Returns
None
from mdx.behavior_learning.model_management import ModelManagement model_management = ModelManagement(config) model_management.save_model(model, sensor_name)
Model versioning is automatically maintained by the module.
Internally, the
save_model()function uses TorchScript for packaging and saving the model to a model repository folder.The ModelManagement module also provides additional functions to facilitate the saving, loading and unloading of models from Triton server.
Combining the pieces
The core workflow of the training component is given below.
# Import modules from mdx package.
from mdx.behavior_learning.nn.behavior_clustering import BehaviorClustering
from mdx.behavior_learning.nn.behavior_learning import BehaviorLearning
from mdx.behavior_learning.model_management import ModelManagement
from mdx.behavior_learning.data_transformer import DataTransformer
# Instantiate the modules.
data_transformer = DataTransformer(config)
behavior_clustering = BehaviorClustering(config)
behavior_learning = BehaviorLearning(config)
model_management = ModelManagement(config)
# Iterate over each sensor
for sensor in sensors:
partition = "sensorId='{}'".format(sensor)
# Read data from delta table
behavior_df = spark.read.format("delta")\
.load(self.delta_table_location)\
.select("id","locations","direction","distance","sensorId")\
.where(partition)\
.limit(config["modelTraining"]["models"]["sampleSourceSize"])\
.toPandas()
# Extrapolate behavior data.
behavior_df["locations"] = behavior_df["locations"].map(data_transformer.extrapolate_locations)
# Cluster behavior data.
labelled_df, num_clusters, num_noise = behavior_clustering.generate_labels(behavior_df)
# Train model for sensor.
model, trainingStats = behavior_learning.create_and_train_model(labelled_df)
# Save the model.
model_management.save_model(model, sensor)
Note
For the complete code of the ingestion and training components, take a look at main_ingestion.py and main_training.py in /behavior-learning folder in the behavior-learning docker container.
A visual representation of the steps involved are shown in the image below:
Triton Inference Server
The Triton Inference Server is used to serve the models from the model_repository folder. A server started in polling mode, will automatically detect changes made to the model repository and proceed with unloading the old version and loading the newly written version.
In case the triton server is started in some other mode, model management module provides load and unload functions for directly loading a model into triton. For details on how Triton is used for inference, see Inference Service which is part of Behavior Analytics Library.