Overview
Introduction
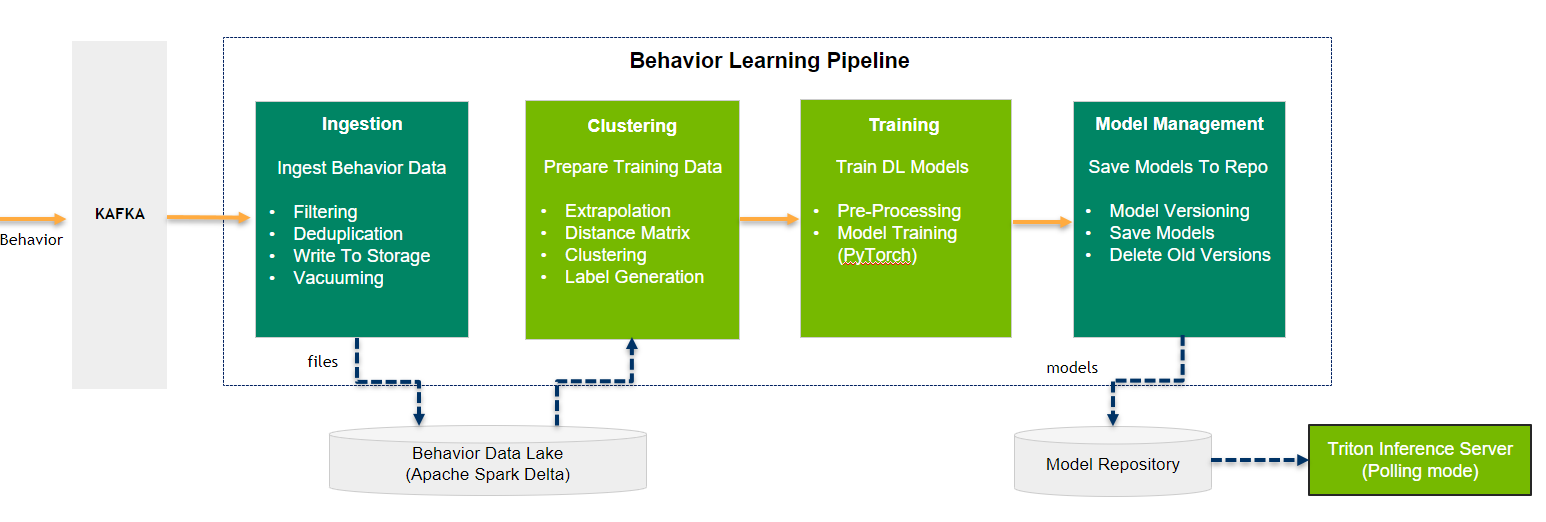
The Behavior Learning microservice consumes the behavior data from a Kafka topic, identifies the patterns in the behavior using clustering, and outputs models trained on the clustering results to an inference server.
The pipeline is made up of two components written in Python:
Ingestion - Consumes data from a Kafka topic using Spark Structured Streaming and writes to a Delta Lake.
Model Training - Loads data from the Delta Lake, clusters behavior data to generate labels, and trains a deep learning model that is uploaded to a Triton Inference Server.
Sample Clusters
Examples of two sample clusters are shown below, where behaviors have been clustered using the the models created by the Behavior Learning microservice.
Single Road
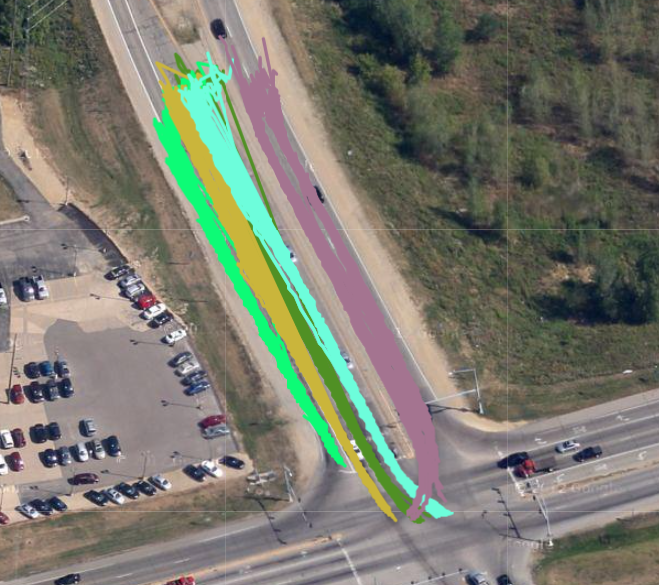
Intersection - 1
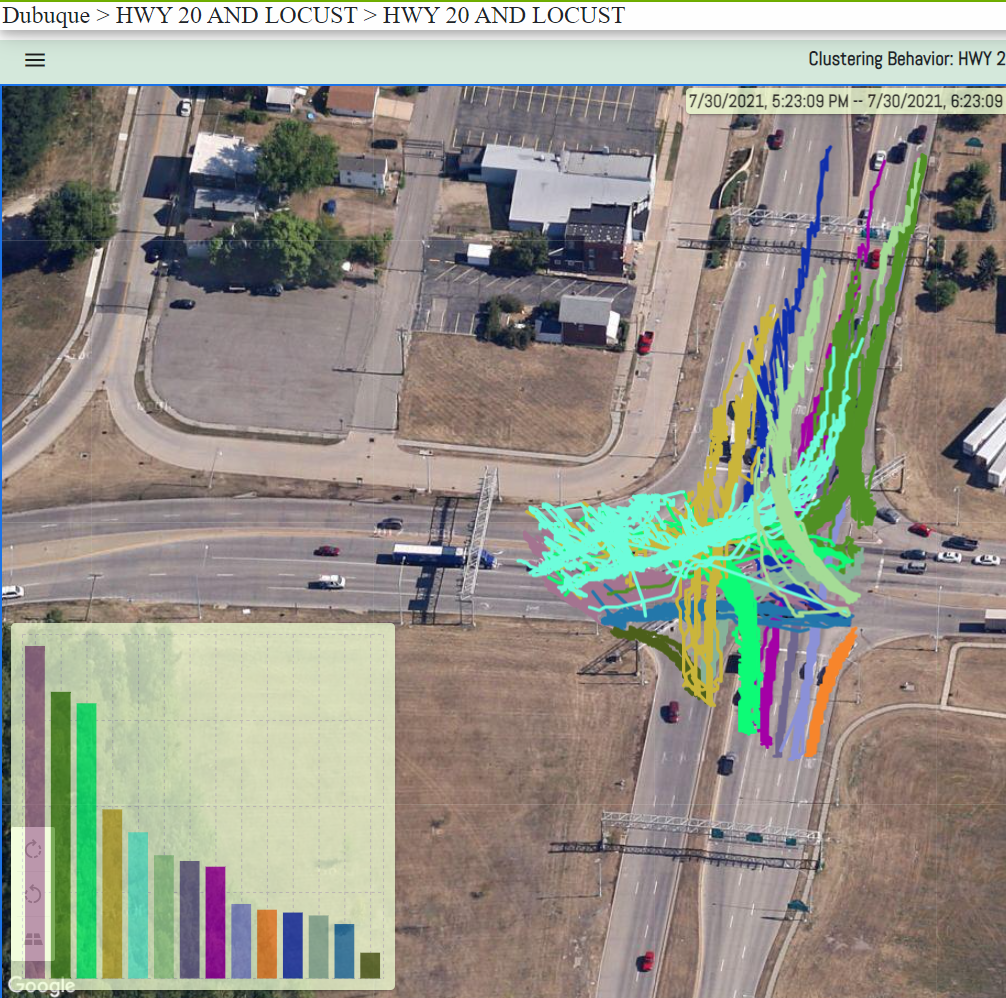
Intersection - 2

Note
Clustering labels are not consistent across different versions of models. Therefore when a new version of the model is loaded, only behavior data clustered using the new model is displayed on the UI.