Introduction#
NVIDIA NIM for NV-CLIP (NV-CLIP NIM) brings the power of state-of-the-art embedding model to enterprise applications, providing unmatched natural language and multimodal understanding capabilities.
NIM makes it easy for IT and DevOps teams to self-host NV-CLIP NIM in their own managed environments while still providing developers with industry-standard APIs that allow them to build powerful copilots, chatbots, and AI assistants that can transform their business. Leveraging NVIDIA’s cutting-edge GPU acceleration and scalable deployment, NIM offers the fastest path to inference with unparalleled performance.
NV-CLIP NIM brings the power of state-of-the-art text and image embedding models to your applications, offering unparalleled natural language processing and understanding capabilities. You can use NV-CLIP NIM for semantic search, Retrieval Augmented Generation (RAG), or any application that uses text and image embeddings. It is built on the NVIDIA software platform, incorporating CUDA, TensorRT, and Triton to offer out-of-the-box GPU acceleration.
Enterprise-Ready Features#
NIM abstracts away model inference internals such as execution engine and runtime operations. They are also the most performant option available, whether with TensorRT or ONNX. NIM offers the following high-performance features:
High Performance NV-CLIP NIM is optimized for high-performance deep learning inference with NVIDIA TensorRT ™ and NVIDIA Triton ™ Inference Server.
Scalable Deployment that is performant and can quickly and seamlessly scale from a few users to millions.
Flexible Integration to easily incorporate the microservice into existing workflows and applications. Developers are provided an OpenAI API-compatible programming model and custom NVIDIA extensions for additional functionality.
Enterprise-Grade Security emphasizes security by using safetensors, constantly monitoring and patching CVEs in our stack and conducting internal penetration tests.
Architecture#
NIMs are packaged as container images on a model/model family basis. Each NIM is its own Docker container with a model, such as “nvidia/nvclip-vit-h-14”. These containers include a runtime that runs on any NVIDIA GPU with sufficient GPU memory, but some model/GPU combinations are optimized. NIM automatically downloads the model from NGC, leveraging a local filesystem cache if available. Each NIM is built from a common base, so once an NIM has been downloaded, additional NIMs can be quickly downloaded.
For the NVIDIA GPUs listed in Support Matrix, NIM downloads the optimized TensorRT engine and runs an inference using the TensorRT library. NIM downloads a non-optimized model for all other NVIDIA GPUs.
NIMs are distributed as NGC container images through the NVIDIA NGC Catalog. A security scan report is available for each container within the NGC catalog, which provides a security rating of that image, a breakdown of CVE severity by package, and links to detailed information on CVEs.
Applications#
Multimodal Retrieval Augmented Generation#
In a Multimodal Retrieval Augmented Generation (RAG) application, we use the embedding model to encode the knowledge base of images and texts (offline) and user question (online) into contextual embeddings, so that the LLM can retrieve the most relevant context and provide the users with the correct answers. We need high quality embeddings model to ensure high relevancy of the retrieved context.
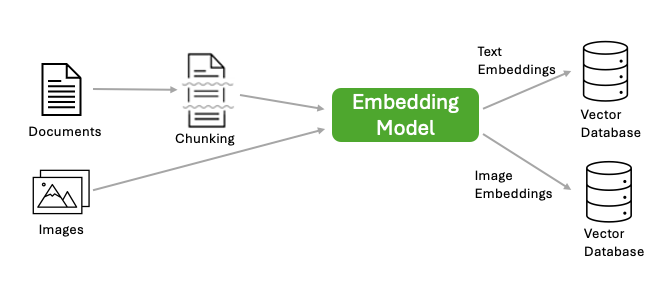
1. Encoding the knowledge base (offline): Given a knowledge base containing documents in text, PDF, HTML, or other formats, and images, we first split the knowledge base of documents into chunks, then encode each chunk into a dense vector representation, also called embedding, using an embedding model. We also encode each image into a embedding using an embedding model. The resulting embeddings, along with their corresponding documents and other metadata, are saved in a vector database. The diagram below illustrates the knowledge base encoding process.
2. Deployment (online): Once deployed, the RAG application can access the vector database and answer questions in real time. To answer a user question, the RAG application first finds relevant chunks from the vector database, then it uses the retrieved chunks as context to generate a response.
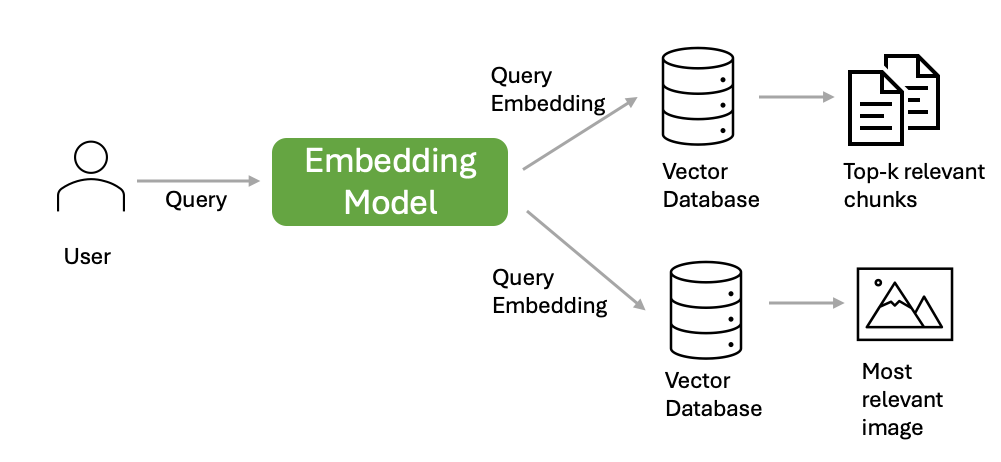
- Phase 1: Retrieval from the vector database based on the user’s query
The user’s query is first embedded as a dense vector using the embedding model. Then the query embedding is used to search the vector database for the most relevant document chunks and the most relevant image with respect to the user’s query. The following diagram illustrates the retrieval process.
- Phase 2: Use an LLM to generate a response leveraging the retrieved context
The most relevant chunks are joined to form the context for the user query. The LLM combines the context and the user query to generate a response. The diagram below illustrates the response generation process.

Image Classification and Retrieval#
Zero-Shot Image Classification: NV-CLIP NIM can classify images without specific training data by associating images with natural language descriptions.
Semantic Image Search: Users can input natural language queries to retrieve images that match the textual descriptions, improving search precision and relevance.
Text Classification and Clustering#
Text embeddings can be used for text classification tasks, such as sentiment analysis and topic categorization. They can also be used for clustering tasks, such as topic discovery and recommender systems. A high quality embedding model improves the performance of these tasks by capturing the contextual information in the dense vector representation.
Custom Applications#
The NV-CLIP NIM API is designed to be versatile. Developers can leverage the text and image embeddings for a variety of applications based on their specific use cases, experiment, and integrate the API seamlessly into their projects. Some of the example workflows can be found in the multimodal search section of our repository.