Deployment Best Practices#
Run a Proof of Concept#
The most successful deployments balance user density (scalability) with quality user experience. This balance is achieved by using NVIDIA RTX vWS virtual machines in production while gathering objective measurements and subjective feedback from end users.
Objective Measurements |
Subjective Feedback |
|---|---|
Loading time of application |
Overall user experience |
Loading time of dataset |
Application performance |
Utilization (CPU, GPU, network) |
Zooming and panning experience |
Frames Per Second (FPS) |
Video streaming |
Leverage Management and Monitoring Tools#
As discussed in previous chapter, several NVIDIA specific and third-party industry tools can help validate your deployment and ensure it provides an acceptable end-user experience and optimal density. Failure to leverage these tools can result in unnecessary risk and poor end-user experience.
Understand Your Users#
Another benefit of performing a POC before deployment is that it enables a more accurate categorization of user behavior and GPU requirements for each virtual workstation. Customers often segment their end-users into user types for each application and bundle similar user types on a host. Light users can be supported on a smaller GPU and smaller profile size, while heavy users require more GPU resources, large profile size, and, may be best kept on an upgraded vGPU license like NVIDIA RTX Virtual Workstation (RTX vWS).
Use Benchmark Testing#
Benchmarks like nVector can be used to help size a deployment, but they have some limitations. The nVector benchmarks simulate peak workloads with the highest demand for GPU resources across all virtual machines. The benchmark does not account for the times when the system is not fully utilized. Hypervisors and the best effort scheduling policy can be leveraged to achieve higher user densities with consistent performance.
The graphic below demonstrates how workflows processed by end-users are typically interactive, which means there are multiple short idle breaks when users require less performance and resources from the hypervisor and NVIDIA vGPU. The degree to which higher scalability is achieved depends on your users’ typical day-to-day activities, such as the number of meetings and the length of lunch or breaks, multi-tasking, etc. It is recommended to test and validate your internal workloads to meet the needs of your users.
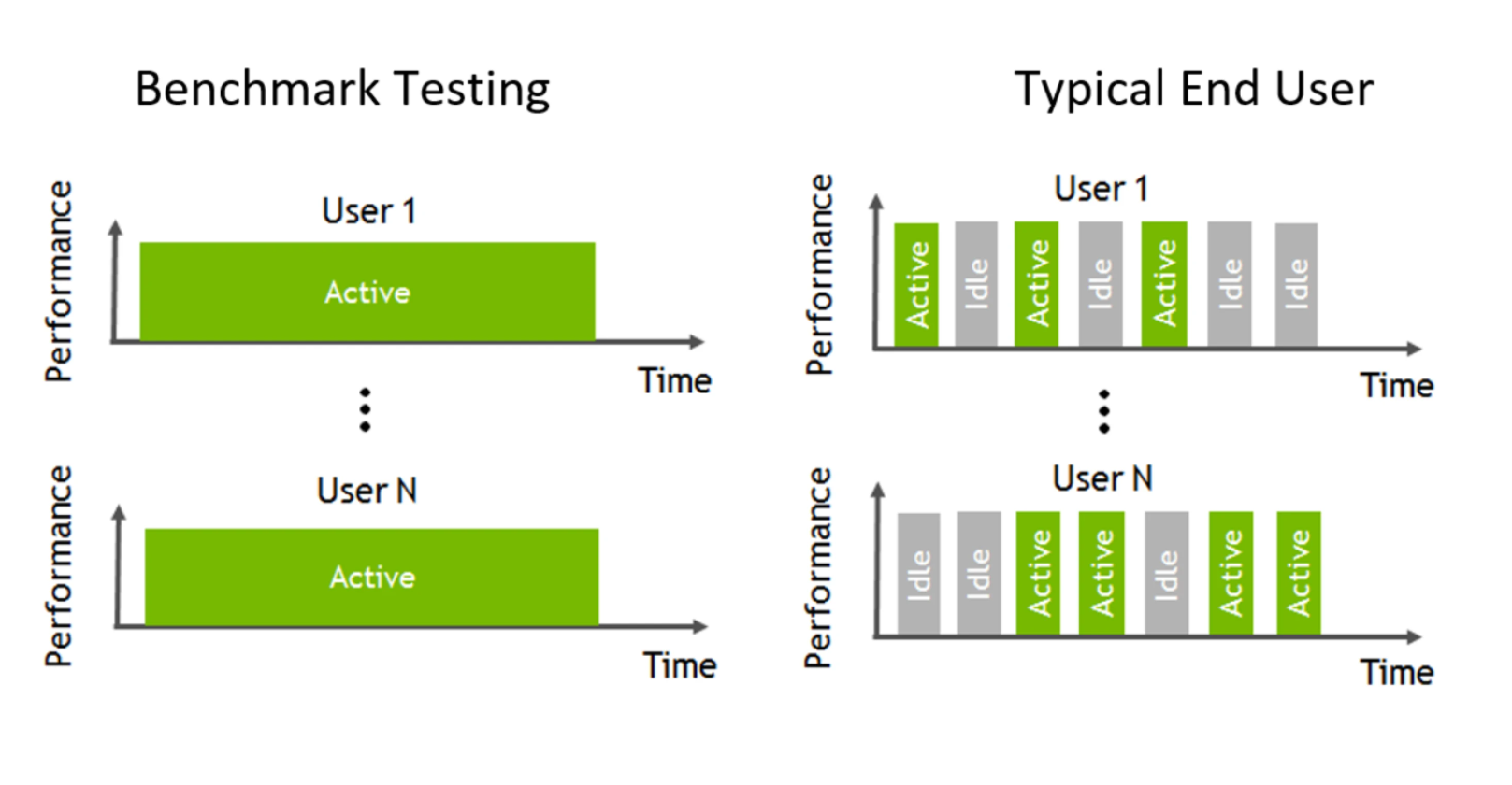
Figure 8 Benchmark Testing Typical End User#
NVIDIA used the nVector benchmarking engine to conduct vGPU testing at scale. This benchmarking engine automates the testing process from provisioning virtual machines, establishing remote connections, executing KW workflow, and analyzing the results across all virtual machines. Test results shown in this application guide are based on the nVector KW benchmarks run in parallel on all virtual machines with metrics averaged.
Caution
When done well, benchmarking can improve an organization’s processes and overall performance. In the context of benchmarking, a channel refers to the specific path or method through which data or workloads are processed by the GPU. Understanding and defining channels is crucial as it directly impacts the performance outcomes measured in benchmark tests, making it a significant sizing factor for GPU deployments. However, there are a plethora of pitfalls to the use of benchmark testing, especially social benchmarking, as the results of an organization’s internal POC may yield different results than the social benchmark. This is due to a variety of reasons such as configuration differences, unreliable or incomplete data, lack of proper framework for standardized testing, etc. Conducting an internal POC with benchmark testing is valuable, but it can provide an incomplete picture when not paired with organizational strategy and goals.
Understanding the GPU Scheduler#
NVIDIA vPC provides three GPU scheduling options to accommodate a variety of QoS requirements of customers. Additional information regarding GPU scheduling can be found here.
Understanding GPU Channels#
GPU channels are dedicated communication pathways that allow applications and system processes to interact with the GPU for accelerated computing. Each vGPU instance is allocated a specific number of GPU channels, which are consumed as applications request GPU resources.
Channel allocation per vGPU is designed based on the maximum number of vGPU instances that can run concurrently on a physical GPU. Larger profiles typically have more GPU channels, which can help improve multitasking and application stability.
When all vGPU channels are consumed, applications may fail to launch or may crash, and system responsiveness degrades. The following errors are reported on the hypervisor host or in an NVIDIA bug report, when running vGPU 16.10, 17.6 and 18.1 and later releases:
Jun 26 08:01:25 srvxen06f vgpu-3[14276]: error: vmiop_log: (0x0): Guest attempted to allocate channel above its max channel limit 0xfb
Monitoring GPU Channel Usage During POC#
By monitoring GPU channel allocation, users can prevent channel exhaustion, optimize vGPU deployments, and ensure stable performance in virtualized environments.
The channel_usage_threshold_percentage plugin parameter helps detect when workloads approach GPU channel exhaustion for specific hypervisors.
Setting a threshold allows administrators to receive warnings when channel usage surpasses a defined percentage.
By default, channel usage warnings are disabled, but administrators can enable them by setting a threshold percentage. For KVM hypervisors, the plugin parameter can be configured as follows:
echo "channel_usage_threshold_percentage=<percentage>" >
/sys/bus/mdev/devices/<UUID>/nvidia/vgpu_params
For example, to set the GPU channel usage warning threshold to 80%, run the following command:
echo "channel_usage_threshold_percentage=80" >
/sys/bus/mdev/devices/<UUID>/nvidia/vgpu_params
Note
The above instructions are specific to KVM hypervisors. Path and configuration methods differ on other hypervisors. For more information, follow the the hypervisor-specific setup steps:
When running vGPU 16.10, 17.6 and 18.1 and later releases, once the usage surpasses the threshold, warning messages appear in the logs, indicating that channel utilization is approaching exhaustion. Example log output:
Sep 10 08:39:52 smc120-0003 nvidia-vgpu-mgr[313728]: notice: vmiop_log: Guest current channel usage 81% on engine 0x1 exceeds threshold channel usage 80%
This feature is particularly useful during Proof-of-Concept (PoC) deployments to observe and optimize resource allocation before production deployment. Through proactive monitoring, administrators can detect potential channel exhaustion early, preventing system crashes and performance degradation by identifying workloads that consume excessive GPU channels. This insight allows for timely adjustments before issues escalate.