Sizing Guide#
This sizing guide is intended to help customers implement fine-tuning of Large Language Models with NVIDIA RTX Virtual Workstation (vWS) at scale. To utilize the NVIDIA RTX vWS, a server of NVIDIA-Certified Systems equipped with NVIDIA Tensor Core GPUs is recommended. This server size is the minimum viable and can be expanded with additional servers.
Workload#
The benchmarks used within this sizing guide are not all-encompassing; they provide a representative workflow and serve as a starting point that can be used to build upon depending on your environment. This sizing specifically concentrates on a single-node deployment for the following workflow.
Large Language Models#
Llamafactory supports many LLMs and can be selected using the Model name drop-down menu. Llamafactory obtains these models through Hugging Face. Some models are ungated, while others, like llama3-8b-instruct, are gated. If a model is gated, you will need to request access to the model. Once access is granted, you can generate an Access Token that can be used with AI Workbench to download the model. The models you can support will depend on the parameter size of the model (7B, 8B, etc.) and the quantization you select (4-bit, 8-bit, etc.).
In most cases, a vGPU profile of 24Q can support up to an 8B parameter with 16-bit quantization. You can review Llamafactory’s guidance on what is supported here, but this is just general guidance as other factors such as batch size and sequence length will affect the amount of vGPU memory. In Llamafacotry these parameters are Batch size and Cuttoff length respectively. If you receive ‘out of memory’ errors, you must lower these parameters or increase the vGPU profile to 32Q.
For a list of all the supported Large Language Models, along with their supported model size and the template to use, reference this chart on the office Llamafactory GitHub repository.
Datasets#
Llamafactory also supports many datasets, each trained for a specific purpose. For example, the dataset we used, Codealpaca, was trained on coding and programming languages. You will want to select a dataset that most closely aligns with your project. You can select a dataset using the Dataset drop-down menu in the Llamafactory UI.
You may also use your custom dataset. For details on how to create and import this into your Llamafactory project, see this reference document.
Configuration#
Server Configuration#
2U NVIDIA-Certified System
Intel(R) Xeon(R) Gold 6354 CPU @ 3.00GHz HT On
39 MB Cache
20 TB iSCSI LUN
Broadcom NextXtreme E-Series Advanced Dual-port Ethernet OCP Adapter for 10GBASE-T
1x NVIDIA GPU: L40/S, L4, A10, T4
Hypervisor - VMware ESXi 8.0 U2
NVIDIA Host Driver - 550.127.05
VM Configuration#
OS Version - Ubuntu 22.04.5 LTS
32 vCPU
128 GB vRAM
NVIDIA Guest Driver - 550.127.05
Sizing#
Sizing recommendations for vGPU profiles based on model size and quantization. These are only estimates, and you should check with the model card for the specific model on Hugging Face.
vGPU Profile |
Reference Model Size |
Quantization |
|---|---|---|
16Q Profile |
8B - 12B |
4 bit |
24Q Profile |
8B - 12B |
8 bit |
48Q Profile |
8B - 12B |
16 bit |
Performance#
One way to measure performance across different GPUs and different vGPU profiles is relative throughput. Relative throughput measures how many training units, like samples or batches, the GPU can process over time relative to its peak performance. It measures how efficiently the GPU’s computational resources are being utilized.
Relative performance is important for faster training and optimizing resources. With a more powerful GPU, such as the L40S, training can be completed faster, often saving hours or days over previous-generation hardware, depending on the model size and dataset. Understanding throughput will help optimize the fine-tuning setup and maximize the use of available resources.
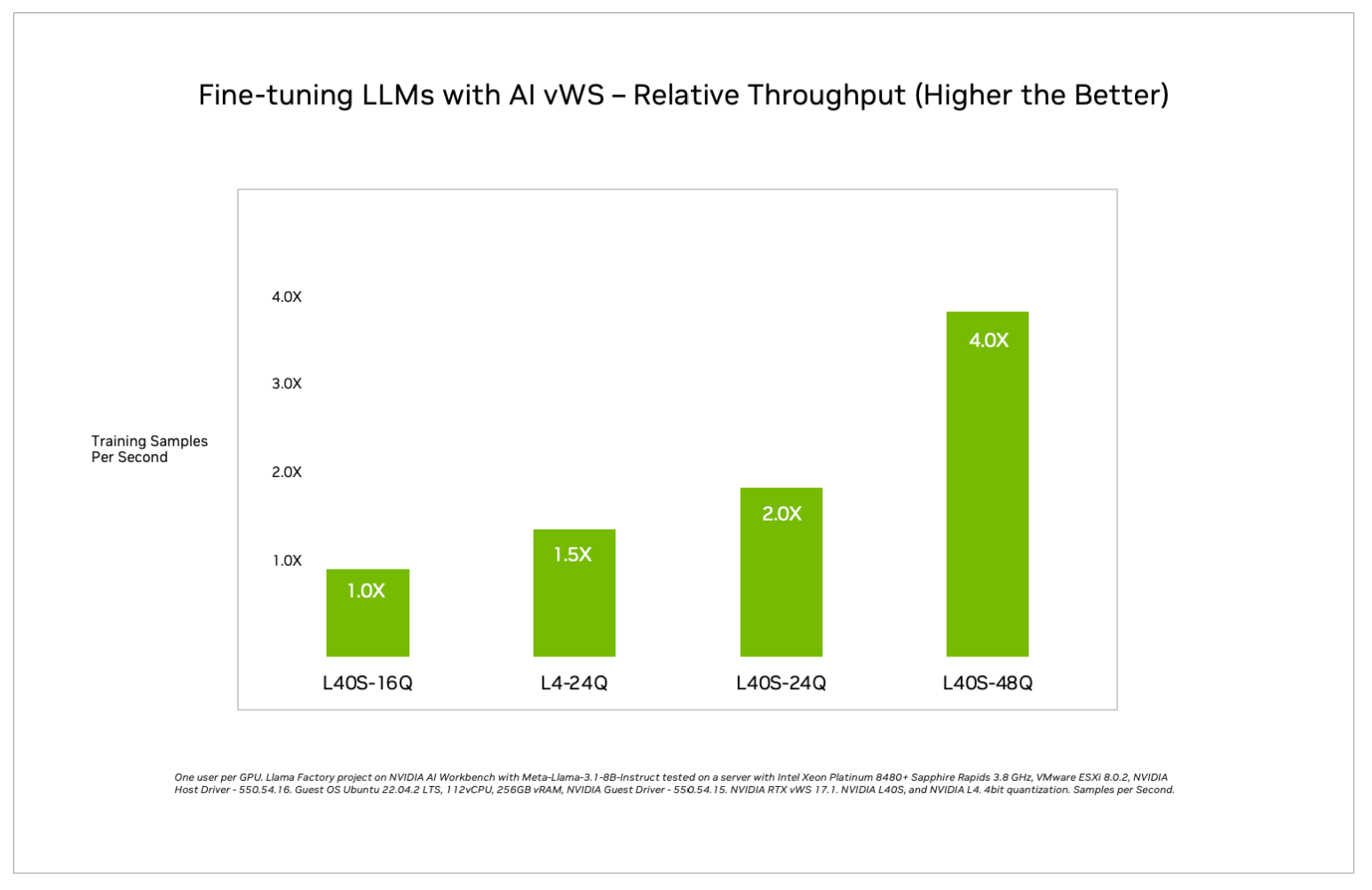
The NVIDIA L40S in a 48Q profile provides 4X throughput than L40S-16Q and more than 2.5X throughput than L4-24Q. In addition, with double the GPU memory of NVIDIA L4, the L40S can support a 48Q vGPU profile capable of fine-tuning larger LLMs and utilizing more accurate bit precision, like 8-bit and 16-bit. Because of this, it is recommended the L40S GPUs be used for this deployment to achieve optimal performance. With NVIDIA vGPU, IT organizations can adjust GPU resources as the required throughput grows.