Sizing Guide#
This sizing guide is intended to help customers implement an RAG application with NVIDIA RTX Virtual Workstation (vWS) at scale. To utilize the NVIDIA RTX vWS, a server of NVIDIA-Certified Systems equipped with NVIDIA Tensor Core GPUs is recommended. This server size is the minimum viable and can be expanded with additional servers.
Workload#
The benchmarks used within this sizing guide are not all-encompassing; they provide a representative workflow and serve as a starting point that can be used to build upon depending on your environment. This sizing specifically concentrates on a single-node deployment for the following workflow:
Large Language Models#
- Ungated Models
These can be accessed, downloaded, and run locally inside the project with no additional configurations required:
- Gated Models
Some additional configurations in AI Workbench may be required, but these configurations are not added to the project by default. Namely, a Hugging Face API token is required to run gated models locally. See how to create a token here.
The following models are gated. Verify that you have been granted access to this model that appears on the model cards for any models you are interested in running locally:
Refer to the Github doc for details to set up a gated model.
Inference#
Select Local System as the inference mode for either ungated or gated models. For quantization, the recommended precision for your system will be pre-selected for you, but 32-bit (full), 8-bit, and 4-bit bits and bytes precision levels are currently supported.
Using RAG#
Upload documents to use as a vector database, and query your documents.
Configuration#
Server Configuration#
2U NVIDIA-Certified System
Intel Xeon Platinum 8480+ @3.8GHz Turbo (Sapphire Rapids) HT On
105 MB Cache
3.84 TB Solid State Drive (NVMe)
Intel Ethernet Controller X710 for 10GBASE-T
1x NVIDIA GPU: L40S, L4, A10, T4
Hypervisor - VMware ESXi 8.0.3
NVIDIA Host Driver - 550.54.15
VM Configuration#
OS Version - Ubuntu 22.04.2
112 vCPU
256GB vRAM
NVIDIA Guest Driver - 550.54.15
Sizing#
Sizing recommendations for vGPU profiles based on model size and quantization:
vGPU Profile |
Reference Model Size |
Quantization |
|---|---|---|
16Q Profile |
8B (default) |
4 bit |
24Q Profile |
8B (default) |
8 bit |
Performance#
To evaluate the performance across different GPU architectures of NVIDIA Tensor Cores, the following tests were conducted for comparative analysis based on tokens per second:
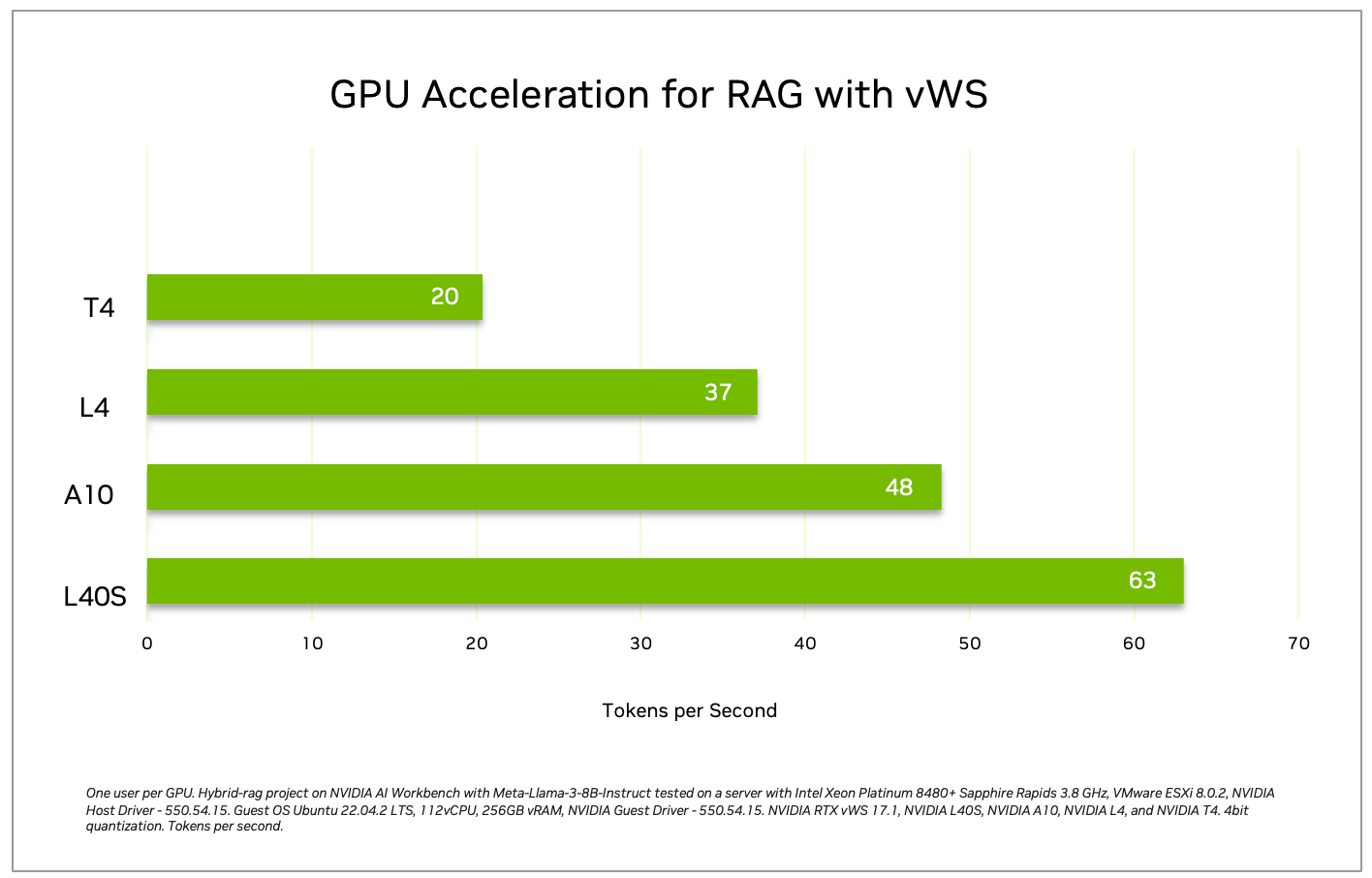
NVIDIA L40S generates 3X throughout compared to T4 and 1.7X compared to L4. We recommend utilizing the L40S GPUs for this deployment to achieve optimal performance.
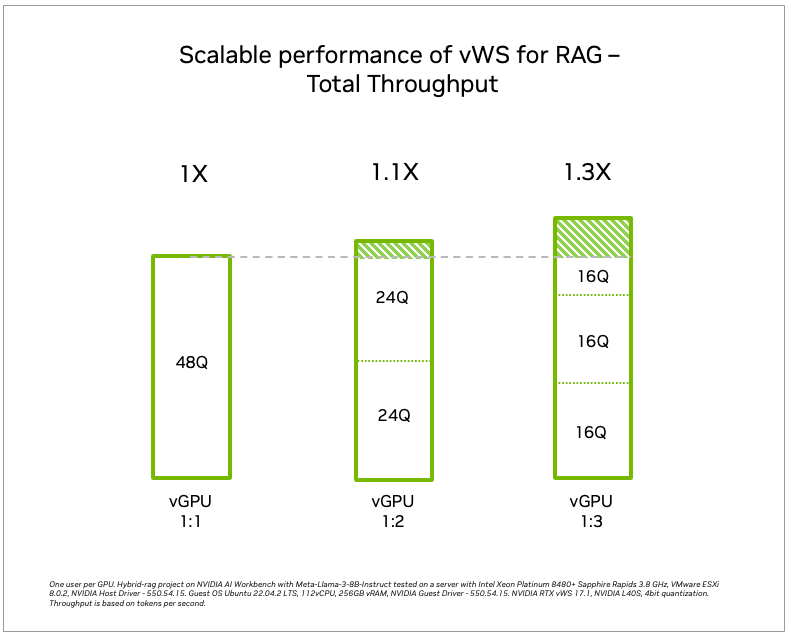
In analyzing vGPU scalability performance, the following test evaluated the impact of GPU sharing on overall throughput across various GPU partitioning options, ranging from a full GPU to half and one-third of an L40S GPU. Virtualized GPUs offer significantly higher total throughput because they can efficiently share resources among multiple virtual machines.