Command-Line Programs#
trtexec#
Included in the samples/trtexec directory in the GitHub repository is a command-line wrapper tool called trtexec. trtexec is a tool that can quickly utilize TensorRT without developing your application. The trtexec tool has three main purposes:
It is useful for benchmarking networks on random or user-provided input data.
It is useful for generating serialized engines from models.
It is useful for generating a serialized timing cache from the builder.
Benchmarking Network#
If you have a model saved as an ONNX file, you can use the trtexec tool to test the performance of running inference on your network using TensorRT. The trtexec tool has many options for specifying inputs and outputs, iterations for performance timing, precision allowed, and other options.
To maximize GPU utilization, trtexec enqueues the inferences one batch ahead of time. In other words, it does the following:
enqueue batch 0 -> enqueue batch 1 -> wait until batch 0 is done -> enqueue batch 2 -> wait until batch 1 is done -> enqueue batch 3 -> wait until batch 2 is done -> enqueue batch 4 -> ...
If Cross-Inference Multi-Streaming (--infStreams=N flag) is used, trtexec follows this pattern on each stream separately.
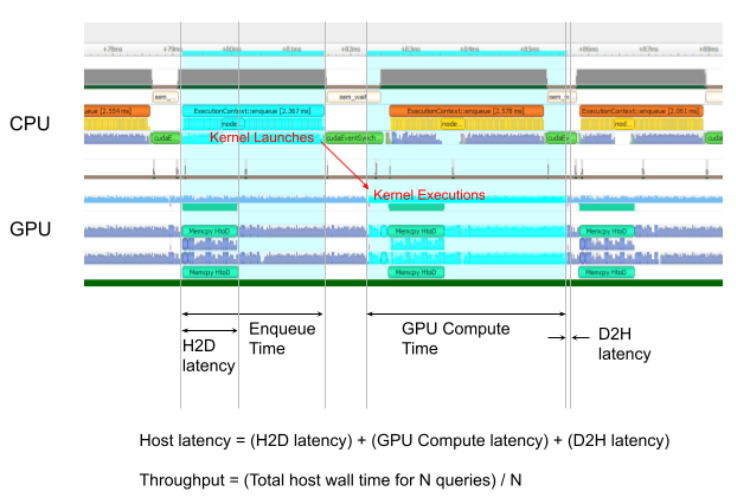
The trtexec tool prints the following performance metrics. The following figure shows an example of an Nsight System profile of a trtexec run with markers showing each performance metric.
Throughput: The observed throughput is computed by dividing the number of inferences by the Total Host Walltime. If this is significantly lower than the reciprocal of GPU Compute Time, the GPU can be underutilized because of host-side overheads or data transfers. CUDA graphs (with
--useCudaGraph) or disabling H2D/D2H transfers (with--noDataTransfer) can improve GPU utilization. The output log guides which flag to use whentrtexecdetects that the GPU is underutilized.Host Latency: The summation of H2D Latency, GPU Compute Time, and D2H Latency. This is the latency to infer a single inference.
Enqueue Time: The host latency to enqueue an inference, including calling H2D/D2H CUDA APIs, running host-side heuristics, and launching CUDA kernels. If this is longer than the GPU Compute Time, the GPU can be underutilized, and the throughput can be dominated by host-side overhead. Using CUDA graphs (with
--useCudaGraph) can reduce Enqueue Time.H2D Latency: The latency for host-to-device data transfers for input tensors of a single inference. Add
--noDataTransferto disable H2D/D2H data transfers.D2H Latency: The latency for device-to-host data transfers for output tensors of a single inference. Add
--noDataTransferto disable H2D/D2H data transfers.GPU Compute Time: The GPU latency to execute the CUDA kernels for an inference.
Total Host Walltime: The Host Walltime from when the first inference (after warm-ups) is enqueued to when the last inference was completed.
Total GPU Compute Time: The summation of the GPU Compute Time of all the inferences. If this is significantly shorter than the Total Host Walltime, the GPU can be under-utilized because of host-side overheads or data transfers.
Note
In the latest Nsight Systems, the GPU rows appear above the CPU rows rather than beneath them.
Add the --dumpProfile flag to trtexec to show per-layer performance profiles, which allows users to understand which layers in the network take the most time in GPU execution. The per-layer performance profiling also works with launching inference as a CUDA graph. In addition, build the engine with the --profilingVerbosity=detailed flag and add the --dumpLayerInfo flag to show detailed engine information, including per-layer detail and binding information. This allows you to understand which operation each layer in the engine corresponds to and their parameters.
Serialized Engine Generation#
If you generate a saved serialized engine file, you can pull it into another inference application. For example, you can use the NVIDIA Triton Inference Server to run the engine with multiple execution contexts from multiple threads in a fully pipelined asynchronous way to test parallel inference performance. There are some caveats; for example, in INT8 mode, trtexec sets random dynamic ranges for tensors unless the calibration cache file is provided with the --calib=<file> flag, so the resulting accuracy will not be as expected.
Serialized Timing Cache Generation#
If you provide a timing cache file to the --timingCacheFile option, the builder can load existing profiling data from it and add new profiling data entries during layer profiling. The timing cache file can be reused in other builder instances to improve the execution time. This cache is suggested to be reused only in the same hardware/software configurations (such as CUDA/cuDNN/TensorRT versions, device model, and clock frequency); otherwise, functional or performance issues can occur.
Commonly Used Command-Line Flags#
The section lists the commonly used trtexec command-line flags.
Flag for the Build Phase |
Description |
|---|---|
|
Allow layers unsupported on DLA to run on GPU instead. |
|
Enables an engine that can stream its weights. Must be specified with |
|
Set the builder optimization level to use when building the engine. A higher level allows TensorRT to spend more building time on more optimization options. |
|
Print and save the engine layer information. |
|
Load the plugin library dynamically and serialize it with the engine when included in |
|
When |
|
Specify network-level precision. |
|
Explicitly set the per-layer device type to |
|
Control per-layer output type constraints. Effective only when |
|
Control per-layer precision constraints. This is effective only when |
|
Specify a list of tensor names to be marked as debug tensors. Separate names with a comma. |
|
Mark unfused tensors as debug tensors. |
|
Set the maximum number of auxiliary streams per inference stream that TensorRT can use to run kernels in parallel if the network contains ops that can run in parallel, with the cost of more memory usage. Set this to 0 for optimal memory usage. Refer to the Within-Inference Multi-Streaming section for more information. |
|
Specify the maximum size of the workspace tactics allowed to be used and the sizes of the memory pools that DLA will allocate per loadable. Supported pool types include |
|
Specify the range of input shapes with which to build the engine. This is only required if the input model is in ONNX format. |
|
Disable the compilation cache in the builder, which is part of the timing cache (the default is to enable the compilation cache). |
|
Specify the input ONNX model. If the input model is in ONNX format, use the |
|
Control precision constraint setting.
|
|
Specify the profiling verbosity to build the engine. |
|
Specify the path to save the engine. |
|
Set the plugin library to be serialized with the engine (can be specified multiple times). |
|
Build and save the engine without running inference. |
|
Specify whether to use tactics that support structured sparsity.
Note This has been deprecated. Use Polygraphy ( |
|
Strip weights from the plan. This flag works with either |
|
Create a strongly typed network. |
|
This option overrides TensorRT’s default temporary directory when creating temporary files. For more information, refer to the |
|
Controls what TensorRT can use when creating temporary executable files. It should be a comma-separated list with entries in the format
|
|
Specify the timing cache to load from and save to. |
|
Use the specified DLA core for layers that support DLA. |
|
Turn on verbose logging. |
|
Enable version-compatible mode for engine build and inference. Any engine built with this flag enabled is compatible with newer versions of TensorRT on the same host OS when run with TensorRT’s dispatch and lean runtimes. Only supported with explicit batch mode. |
Flag for the Inference Phase |
Description |
|---|---|
|
Specify how the internal device memory for inference is allocated. You can choose from |
|
Load a serialized engine using an async stream reader. This method uses the |
|
Print layer information of the engine. |
|
Print and save the per-layer performance profile. |
|
Load the plugin library dynamically when not included in the engine plan file (it can be specified multiple times). |
|
Print the TensorRT version when the loaded plan is created. This works without deserializing the plan. Use it together with |
|
Run inference with multiple cross-inference streams in parallel. Refer to the Cross-Inference Multi-Streaming section for more information. |
|
External lean runtime DLL is to be used in version-compatible mode. Requires |
|
Load the engine from a serialized plan file instead of building it from the input ONNX model. |
|
Load input values from files. The default is to generate random inputs. |
|
Turn off host-to-device and device-to-host data transfers. |
|
Specify the profiling verbosity to run the inference. |
|
Specify a list of tensor names to turn on the debug state and a filename to save raw outputs. These tensors must be specified as debug tensors during build time. |
|
Save all debug tensors to files. Including debug tensors marked by |
|
Specify the input shapes with which to run the inference. If the input model is in ONNX format or the engine is built with explicit batch dimensions, use |
|
Specify the minimum duration of the warm-up runs, the minimum duration for the inference runs, and the minimum iterations. For example, setting |
|
Manually set the weight streaming budget. Base-2 unit suffixes are supported: B (Bytes), G (Gibibytes), K (Kibibytes), and M (Mebibytes). If the weights do not fit on the device, a value of |
|
Capture the inference to a CUDA Graph and run the inference by launching the graph. This argument can be ignored when the built TensorRT engine contains operations not permitted under CUDA Graph capture mode. |
|
TensorRT runtime to execute the engine. |
|
Actively synchronize on GPU events. This option makes latency measurement more stable but increases CPU usage and power. |
|
Turn on verbose logging. |
Refer to trtexec --help for all supported flags and detailed explanations.
Refer to the GitHub: trtexec/README.md file for detailed information about building this tool and examples of its usage.