VLM Workflow#
Overview#
Jetson Platform Services provide several reference workflows that illustrate how various foundational and AI services can be integrated to create end to end applications. This section described the VLM workflow, that integrates the corresponding AI service with associated pieces including VST, monitoring and the mobile app. The resulting application provides a mobile app based UI with which a user can set alerts to be evaluated by the VLM on input live streams. When the alerts are determined to be True by the VLM, notifications will be sent to the mobile app. The workflow also leverages VST for stream input and management. Users can use this as a reference to carve out relevant pieces for creating their own applications utilizing the VLM service.
To get the docker compose and config files for this workflow, download the Jetson Platform Services resources bundle from NGC or SDK Manager.
To launch this workflow, first follow steps on the Visual Language Models (VLM) with Jetson Platform Services page to ensure the VLM service is functional on your system.
After verifying the VLM service works as expected, bring it down with sudo docker compose down from the same folder it was launched.
Getting Started#
Ensure the necessary foundation services are running
sudo systemctl start jetson-monitoring
sudo systemctl start jetson-sys-monitoring
sudo systemctl start jetson-gpu-monitoring
Verify all the lines (for monitoring services) in the platform ingress config file are uncommented in the following file:
/opt/nvidia/jetson/services/ingress/config/platform-nginx.conf
This will ensure that monitoring dashboards are accessible through the API Gateway.
sudo systemctl restart jetson-ingress
sudo systemctl restart jetson-redis
sudo systemctl restart jetson-vst
Note that we will also start jetson-vst as this will be the source of our live streams in this workflow example.
Launch the VLM Service
cd ~/vlm/example_1
sudo docker compose up
Once launched, the VLM service will wait for commands from the mobile app.
Video Ingestion with VST#
It is typical for generative AI video applications to be developed accepting file input for video source. In production, these applications need to interact with video streams from the real world, including from cameras and network streams. The Video Storage Toolkit microservice provides an out of the box mechanism to ingest video, including camera discovery, camera reconnection, monitoring and camera events notification. In the process, VST provides a proxy RTSP link for camera video sources that services can query for based on VST APIs.
VST supports the ONVIF protocol for discovering cameras. These cameras could be connected directly to the Jetson system through a dedicated power over Ethernet (PoE) switch; or to the network that the device is connected to. Another option is for users to manually add devices based on its IP address.
Streams can be added through the VST web dashboard at http://0.0.0.0:30080/vst. All the streams added in VST will become available to use with the VLM service through the mobile app. These streams can come from NVStreamer, IP Cameras or any RTSP source.
Mobile App Integration#
With the VLM service launched and streams added to VST, the mobile app can now be used to connect with the VLM service and do the following:
To install the app, follow the installation section on the app overview page.
Once installed, you can open the app and connect it to your Jetson.
You can then do the following from the app,
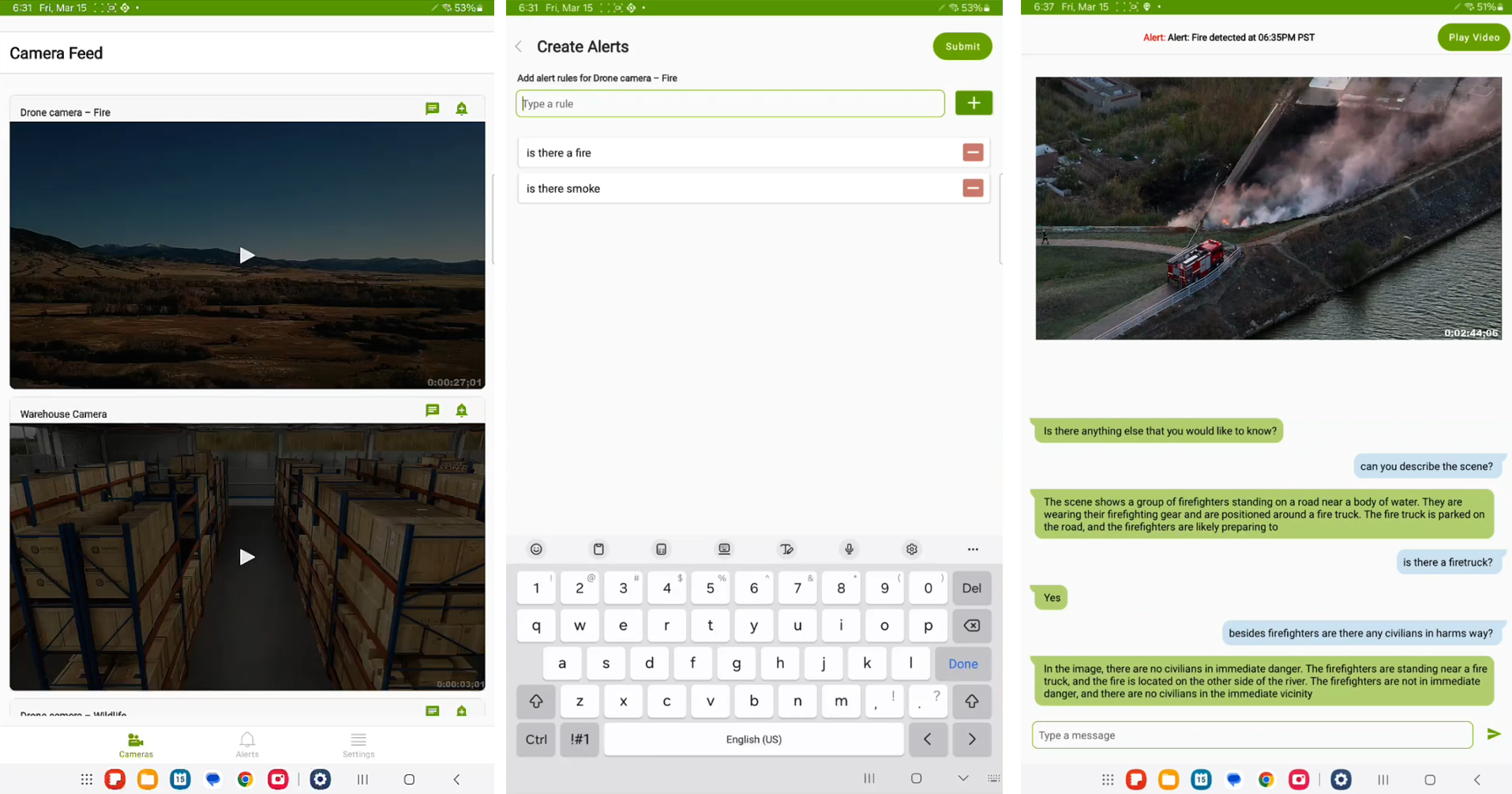
View available live streams
Set alerts on any available live stream such “Is there a fire?”
Receive push notifications when the alerts are evaluated as True
Ask open ended questions to the VLM about the live stream through chat mode
Note that only streams that have been added to VST will be available in the mobile app.
Monitoring#
Jetson Platform Services provides monitoring as a ready to use platform service, enabling developers to track system utilization and performance KPIs. Given generative AI applications push the system capabilities both in terms of GPU utilization and memory availability, the Prometheus based monitoring dashboards provide a ready means to observe utilization of these metrics as applications are run. These metrics are updated live, presenting to users a real time view of the utilization as the application executes and starts processing different inputs.
View the Usage & Configuration page for more details on the monitoring service and capabilities.
Secure Storage#
AI applications use and generate various data, including model, inference output etc. Jetson Platform Services offers encryption of storage used by microservices that can be leveraged by AI applications so that their data (model, weights, input, output) is safe at rest. The storage platform service describes how to enable encryption and also how microservices can request storage quotas from attached external storage such as hard disk.
Further Customization & Integration#
To facilitate integration of Generative AI applications (typically written in Python) into systems using Jetson Platform Services, we highlight a collection of Python modules that developers can leverage. The source code for the Zero Shot Detection service available on GitHub illustrates the use of these modules to achieve this integration.
The list of these Python modules include:
jetson-containers : provides containers, models, vectorDB, and other building blocks for generative AI applications on Jetson
jetson-utils : NVIDIA provided python module for hardware accelerated image and multimedia operations relating supporting RTSP stream input/output, video decode, and efficient video overlay creation
moj-utils: New NVIDIA provided python module for integration with rest of Jetson Platform Services
jetson-platform-services : Open Source GitHub repository with reference AI services and workflows.