Generating a Synthetic Dataset Using a Replicator#
In this lesson, you’ll learn how to generate a synthetic dataset using NVIDIA Replicator, focusing on creating diverse and realistic data for training AI perception models. We’ll guide you through the process of setting up a simulation environment, applying domain randomization, and capturing images with varying parameters such as object poses, lighting conditions, textures, and camera angles.
Learning Objectives#
Understand the basics of the Synthetic Data Generation (SDG) script and its role in data creation.
Apply domain randomization techniques to introduce variability into your dataset.
Use Python scripts with Replicator APIs to automate data generation efficiently.
Explore optional advanced features like the Semantics Schema Editor for generating detailed annotations.
Create a high-quality synthetic dataset that can be used for training AI perception models.
This hands-on lesson will give you practical experience in generating synthetic data and prepare you for the next steps in fine-tuning and validating your AI models. By the end of this lesson, you’ll have created a robust dataset tailored for detecting pallet jacks in a warehouse environment.
Understanding Basics of the SDG Script#
In this section, we’ll break down the key components of the Synthetic Data Generation (SDG) script. Using Isaac Sim, we’ll generate a synthetic dataset for detecting pallet jacks in a warehouse environment. By changing the color and pose of pallet jacks and varying the camera position, we’ll introduce enough diversity into the dataset to serve as a strong starting point. While this example generates 5,000 images, the focus here is on understanding the data generation process rather than creating a large dataset.
Install Isaac Sim#
Clone the Project#
Open a terminal and clone the Synthetic Data Generation Training Workflow repository:
git clone https://github.com/NVIDIA-AI-IOT/synthetic_data_generation_training_workflow.git
Locate and Configure generate_data.sh#
The script generate_data.sh is located in synthetic_data_generation_training_workflow/local. This script requires the absolute path of your Isaac Sim installation folder to be specified in the variable ISAAC_SIM_PATH. To find your Isaac Sim installation path:
In Omniverse Launcher, go to the Library tab and select Isaac Sim
Click on the hamburger icon next to the Launch button and select Settings
This will open up a window with the install path. Copy this path, we will use it in the next step.
For example:
#!/bin/bash
# This is the path where Isaac Sim is installed which contains the python.sh script
ISAAC_SIM_PATH="/home/abc/.local/share/ov/pkg/isaac-sim-4.2.0/"
Next, let’s make generate_data.sh executable.
Run the following command to make the script executable:
chmod +x synthetic_data_generation_training_workflow/local/generate_data.sh
Copy the absolute path of your Isaac Sim installation. This is where you unzipped the package during installation. If you followed the standard workstation installation steps, this will be /home/
/isaacsim. Copy this path in generate_data.sh in ISAAC_SIM_PATH and don’t forget to save it. For Example:
#!/bin/bash
# This is the path where Isaac Sim is installed which contains the python.sh script
ISAAC_SIM_PATH="/home/abc/isaacsim"
Run the following command to make the script executable:
chmod +x synthetic_data_generation_training_workflow/local/generate_data.sh
Understand What the Script Does#
Before running generate_data.sh, let’s review its functionality:
It calls a Python file named standalone_palletjack_sdg.py, located in synthetic_data_generation_training_workflow/palletjack_sdg.
This Python script sets up a warehouse environment, adds pallet jacks from the SimReady Asset Library, and applies domain randomization (DR) by varying object poses, colors, lighting, and camera positions.
Note
You do not need to run the code snippets in the rest of this section. These are just given here to understand what the data generation code does. We’ll run it in the next section.
Warehouse Environment Setup#
The following lines in standalone_palletjack_sdg.py load a simple warehouse environment in Isaac Sim:
ENV_URL = "/Isaac/Environments/Simple_Warehouse/warehouse.usd"
open_stage(prefix_with_isaac_asset_server(ENV_URL))
Adding Pallet Jacks and Camera#
Pallet jacks are added from the SimReady library, and a camera is placed in the scene:
PALLETJACKS = ["http://omniverse-content-production.s3-us-west-2.amazonaws.com/Assets/DigitalTwin/Assets/Warehouse/Equipment/Pallet_Trucks/Scale_A/PalletTruckScale_A01_PR_NVD_01.usd",
"http://omniverse-content-production.s3-us-west-2.amazonaws.com/Assets/DigitalTwin/Assets/Warehouse/Equipment/Pallet_Trucks/Heavy_Duty_A/HeavyDutyPalletTruck_A01_PR_NVD_01.usd",
"http://omniverse-content-production.s3-us-west-2.amazonaws.com/Assets/DigitalTwin/Assets/Warehouse/Equipment/Pallet_Trucks/Low_Profile_A/LowProfilePalletTruck_A01_PR_NVD_01.usd"]
cam = rep.create.camera(clipping_range=(0.1, 1000000))
Applying Domain Randomization (DR)#
Domain randomization is applied by randomizing camera positions, pallet jack colors, and object poses:
1with cam:
2 rep.modify.pose(position=rep.distribution.uniform((-9.2, -11.8, 0.4), (7.2, 15.8, 4)),
3 look_at=(0, 0, 0))
4
5# Get the Palletjack body mesh and modify its color
6with rep.get.prims(path_pattern="SteerAxle"):
7 rep.randomizer.color(colors=rep.distribution.uniform((0, 0, 0), (1, 1, 1)))
8
9# Randomize the pose of all added palletjack
10with rep_palletjack_group:
11 rep.modify.pose(position=rep.distribution.uniform((-6, -6, 0), (6, 12, 0)),
12 rotation=rep.distribution.uniform((0, 0, 0), (0, 0, 360)),
13 scale=rep.distribution.uniform((0.01, 0.01, 0.01), (0.01, 0.01, 0.01)))
Annotations With KITTI Writer#
The script uses Replicator’s KITTI Writer to annotate data for object detection tasks:
1# Set up the writer
2writer = rep.WriterRegistry.get("KittiWriter")
Additional Features#
Varying Lighting Conditions: The script randomizes lighting attributes like color and intensity:
with rep.get.prims(path_pattern="RectLight"):
rep.modify.attribute("color", rep.distribution.uniform((0, 0, 0), (1, 1, 1)))
rep.modify.attribute("intensity", rep.distribution.normal(100000.0, 600000.0))
rep.modify.visibility(rep.distribution.choice([True, False, False, False]))
Adding Distractors: Additional objects like traffic cones or barrels are added for scene diversity:
1DISTRACTORS_WAREHOUSE = ["/Isaac/Environments/Simple_Warehouse/Props/S_TrafficCone.usd", "/Isaac/Environments/Simple_Warehouse/Props/S_WetFloorSign.usd", "/Isaac/Environments/Simple_Warehouse/Props/SM_BarelPlastic_A_01.usd"]
2
3
4# Modify poses of distractors
5with rep_distractor_group: rep.modify.pose(position=rep.distribution.uniform((-6, -6, 0), (6, 12, 0)), rotation=rep.distribution.uniform((0, 0, 0), (0, 0, 360)), scale=rep.distribution.uniform(1, 1.5))
6
With these steps understood and configured correctly in your environment setup files (generate_data.sh and standalone_palletjack_sdg.py), you’re ready to run the script to start generating synthetic data!
We’ll cover this process in detail in the next section.
Running the Script for Generating Training Data#
In this section, we’ll run the script to generate synthetic training data for pallet jack detection. The script uses Isaac Sim and Replicator to create diverse scenes with domain randomization, capturing images from different camera positions and configurations. Follow these steps to execute the script and understand the output:
Time Required for Data Generation#
The time taken depends on your GPU and dataset size. Using an NVIDIA RTX A6000 GPU with default settings (5000 images), data generation takes approximately one hour.
Run the Script#
Execute the script using the following command:
./generate_data.sh
Wait for Isaac Sim to Load#
After running the script, the Isaac Sim window will open.
A smaller window might pop up asking if you would like to “Force Quit” or “Wait” - click on Wait.
Allow up to a minute for the scene to load and data generation to begin. You will see scenes being rapidly generated with varying lighting, object positions, colors, and camera angles.
This process demonstrates domain randomization in action.
Default Dataset Configuration#
By default, the generate_data.sh script generates:
2000 images with warehouse distractors (e.g., cones, bins, boxes).
2000 images with additional distractors (e.g., furniture, bags, wheelchairs).
1000 images with no distractors (only pallet jacks).
These numbers can be modified in the script by changing the num_frames parameter in the following lines:
./python.sh $SCRIPT_PATH --height 544 --width 960 --num_frames 2000 --distractors warehouse --data_dir $OUTPUT_WAREHOUSE
`./python.sh $SCRIPT_PATH --height 544 --width 960 --num_frames 2000 --distractors additional --data_dir $OUTPUT_ADDITIONAL`
`./python.sh $SCRIPT_PATH --height 544 --width 960 --num_frames 1000 --distractors None --data_dir $OUTPUT_NO_DISTRACTORS`
Customizing Parameters#
You can adjust other parameters in the script as needed:
Image Dimensions : Modify height and width.
Distractor Types : Specify warehouse, additional, or None.
Output Folder : Change the directory where images are saved.
Generated Dataset Location#
By default, generated images are saved in this folder:
synthetic_data_generation_training_workflow/palletjack_sdg/palletjack_data/
After running the script, you’ll see three new folders:
distractors_warehouse : Contains images with warehouse objects like cones and bins alongside pallet jacks.
distractors_additional: Contains images with non-warehouse objects like furniture or wheelchairs alongside pallet jacks.
no_distractors : Contains images with only pallet jacks.
Explore Generated Data#
Navigate into one of the folders (e.g., distractors_warehouse) and then into the Camera folder. You’ll find subfolders containing different types of data:
rgb: RGB images for training models that use image input.
object_detection : Annotations in KITTI format corresponding to each image in rgb. These annotations include information about pallet jack locations in each image.

The generated dataset is now ready for use in training AI models! Below are some sample images generated by this process:

Generated Dataset with Wheelchair#

Generated Dataset Pallet Jack#
Key Takeaways#
Running generate_data.sh creates a synthetic dataset with domain randomization applied to lighting, object positions, colors, and camera angles.
By default, 5000 images are generated across three categories: warehouse distractors, additional distractors, and no distractors.
Parameters such as image dimensions (height, width), number of frames (num_frames), and distractor types can be customized in the script.
The dataset includes RGB images for model training and KITTI-format annotations for object detection tasks.
Generated data is saved in structured folders under palletjack_data, ready for use in AI model training workflows.
In the next section, we’ll explore advanced techniques for customizing data generation further using Replicator’s APIs.
Advanced Techniques With Replicator#
Note
This section introduces an advanced feature you can explore if you’re interested, though it is not required to continue with the module.
The Semantics Schema Editor, an Omniverse extension, allows you to generate annotations such as segmentation masks and bounding boxes by assigning semantic information to objects in your scene. Semantic information includes object classes, which are essential for creating ground truth data for training AI models.
Using the Semantics Schema Editor#
First, let’s enable the extension:
Open the Extension Manager in Isaac Sim by navigating to Window > Extensions.
Search for and enable the Semantics Schema Editor.
Access the Editor via Tools > Replicator > Semantics Schema Editor.
Make sure it is enabled with a blue tick:
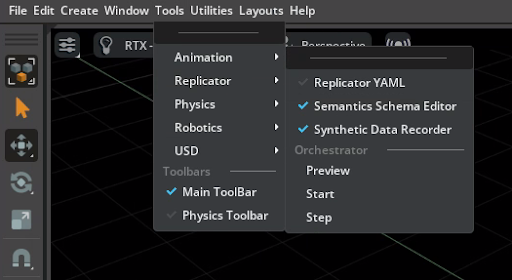
Assign Semantic Labels#
There are two methods to assign semantic labels to objects in your scene.
Using Selected Objects: Select a group of objects, and for each object, specify the Type field as class and the Data field as the desired semantic label.
Using Prim Names: Use a heuristic-based approach to assign semantic labels based on object names (prim names). Prefixes or suffixes like SM (Static Mesh) or SK (Skeletal Mesh) can be removed to simplify labels.
Generate Annotations#
More information on this process can be found in the Semantics Schema Editor documentation.
Once semantic labels are assigned, annotations such as segmentation masks or bounding boxes can be generated. These annotations are critical for tasks like object detection or instance segmentation.
Programmatic Labeling (Optional)#
For advanced users, semantics can also be defined programmatically using Python scripts. For example:
rep.modify.semantics([('class', 'avocado')])
Filtering Semantics (Optional)#
Semantic filters can be applied globally to extract specific ground truth data. For instance:
Retrieve all objects labeled as vehicle or person:
class:vehicle|personExclude objects labeled as sports_car:
!class:sports_car
By using these techniques, you can create tailored datasets with detailed annotations for training complex AI models.
Key Takeaways#
The Semantics Schema Editor is an Omniverse extension that enables you to assign semantic labels to objects for generating annotations like segmentation masks and bounding boxes.
Semantic labels can be assigned manually through selected objects or automatically using prim names.
Advanced users can define semantics programmatically or apply filters to extract specific ground truth data.
This tool is useful for creating high-quality datasets with detailed annotations, but it is optional for this beginner-friendly module.
Feel free to explore this feature if you want to dive deeper into advanced annotation techniques, but it is not necessary to proceed with the rest of the module.
Review#
In this lesson, we generated a synthetic dataset for detecting pallet jacks in a warehouse environment using NVIDIA Replicator and Isaac Sim. By modifying pallet jack colors, poses, and camera positions, we applied domain randomization to create a robust dataset of 5,000 images with varying lighting, object placements, and distractors. Additionally, we introduced the Semantics Schema Editor for advanced users to assign semantic labels and generate detailed annotations like segmentation masks and bounding boxes.
While optional, these techniques enhance dataset quality for specific AI tasks. By the end of this lesson, you gained hands-on experience in synthetic data generation and prepared for fine-tuning and validating AI perception models.
Quiz#
What is the primary purpose of using NVIDIA Replicator in synthetic data generation?
To create diverse and realistic synthetic datasets for training AI models
To manually label real-world datasets
To train AI models directly without data
To replace the need for model validation
Answer
A
NVIDIA Replicator is used to generate synthetic datasets with domain randomization, introducing variability in parameters like lighting, textures, and object poses. This helps create diverse and realistic data for training AI models.
Which technique is used in this lesson to introduce variability into the dataset?
Data augmentation
Domain randomization
Generative AI modeling
Manual scene adjustments
Answer
B
Domain randomization is used to introduce variability in parameters such as lighting, object positions, textures, and camera angles during synthetic data generation. This ensures a robust and diverse dataset.
What optional advanced feature can be used to add semantic labels to objects in the dataset?
Domain Randomizer Tool
Semantics Schema Editor
Texture Mapping Tool
Object Pose Estimator
Answer
B
The Semantics Schema Editor is an optional advanced tool that allows users to assign semantic labels to objects, enabling the generation of detailed annotations like segmentation masks and bounding boxes.