PeopleNet Transformer
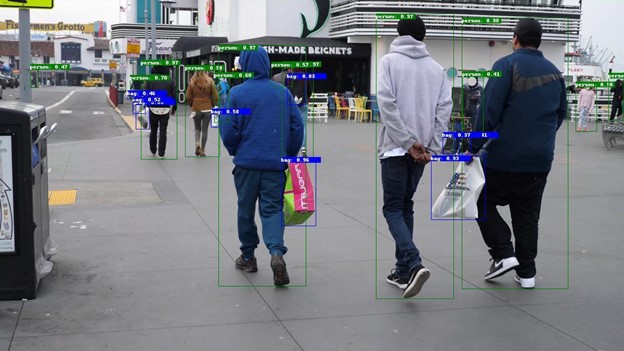
Like PeopleNet, the PeopleNet Transformer models detect one or more physical objects from three categories within an image and return a box around each object, as well as a category label for each object. Three categories of objects detected by these models are:
persons
bags
faces
These models are based on FAN-Small backbone with DINO as the feature extractor. We first trained a FAN-Small backbone on NVIDIA’s NVImageNetv2 dataset. Pseudo-label bounding boxes are obtained using open-source state-of-the-art detection network (FocalNet-L + DINO) on Open Images to obtain COCO class annotations. The next step is to train FAN-Small + DINO on Open Images (800K images) to learn the rich and diverse representation required by the transformer. Finally, FAN-Small + DINO are trained in a supervised manner on PeopleNet data (1.7M images) to focus on people detection.
Model Card
The datasheet for the models is captured in the model card hosted at NGC, which includes the detailed instructions to deploy the models with DeepStream.
TAO Fine-Tuning
You can retrain/fine-tune the PeopleNet Transformer models on customized datasets. This model uses DINO as the object detector with FAN-Small as the feature extractor.
For more details, refer to TAO tutorial notebook and TAO documentation for DINO.
Accuracy
The accuracy of PeopleNet Transformer model was measured against more than 90,000 proprietary images across a variety of environments. The frames are high resolution images 1920x1080 pixels resized to 960x544 pixels before passing to the PeopleNet Transformer detection model.
The true positives, false positives, false negatives are calculated using intersection-over-union (IOU) criterion greater than 0.5. In addition, we have also added KPI with IOU criterion of greater than 0.8 for low-density and extended-hand sequences where tight bounding box is a requirement for subsequent human pose estimation algorithms. The KPI for the evaluation data are reported in the table below. Model is evaluated based on detection accuracy.
Content |
Accuracy (FP16) |
People |
85.50% |
Office |
93.59% |
GoPro |
86.60% |
Low-contrast |
78.78% |
People (IOU > 0.8) |
76.01% |
Extended-hands (IOU > 0.8) |
89.29% |