Overview
Introduction
The Perception microservice, also called DeepStream or Detection, Tracking, & Embedding microservice, uses NVIDIA DeepStream SDK, a complete streaming analytics toolkit for AI-based multi-sensor video, audio, and image understanding. The DeepStream microservice generates the perception metadata for each stream that other microservices can use to generate higher-order reasoning and insights.
The microservice features deepstream-fewshot-learning-app, a DeepStream app/pipeline, based on the built-in deepstream-test5 app in the DeepStream SDK. That perception app is a complete application which takes streaming video inputs, decodes the incoming stream, performs inference & tracking, and lastly sends the data to other Metropolis Microservices, using the defined schema.
The app allows us to specify PGIE (Primary GPU Inference Engines), Multi-Object Tracker and SGIE (Secondary GPU Inference Engines) components and provide optional sinks. Multi-Object Tracker primarily uses NvDCF (NVIDIA-enhanced Discriminative Correlation Filter) with re-identification capability. It performs 2D object tracking for each stream in the default configuration, but users can enable 3D Tracking to track objects in an estimated world ground coordinate and acquire more accurate foot location/visibility reconstructed from 3D, which can be used to further improve multi-camera tracking accuracy. The re-identification models for the Multi-Camera Tracking/RTLS and Few-Shot Product Recognition (FSL) reference applications comprise of different AI models that produce 256- to 2048-dimensional embedding vectors. Multi-Camera Tracking and RTLS use a people re-identification model in the Multi-Object Tracker for both single- and multi-camera tracking purposes, while FSL deploys the re-identification model for retail items as an SGIE module. Then the pipeline connects to a Kafka (Multi-Camera Tracking, RTLS) or Redis (FSL) message broker to send metadata of each incoming frame following the DeepStream’s message format.
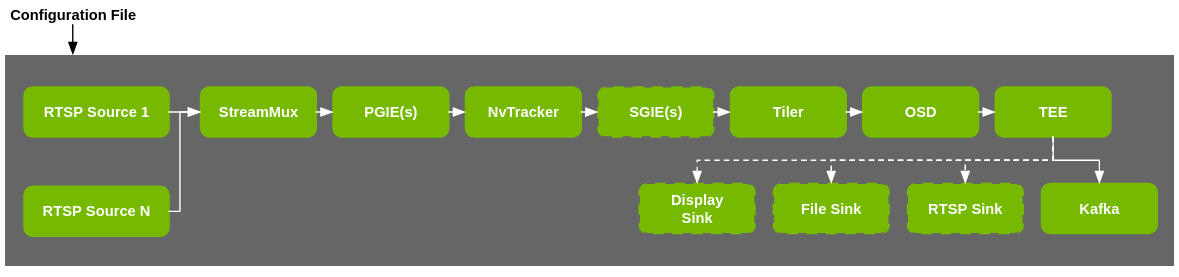
The diagram below shows the perception pipeline used in the microservice:
Models
For inference, the sample application packages the following models:
People Detection and Tracking models
Retail Item Recognition models
More information on the data used to train these models can be found in respective model cards on NGC.
These models are completely customizable for your use case using NVIDIA TAO Toolkit.
Model Guide
The following table provides a brief comparison to help developers evaluate & deploy the appropriate model combinations for the Multi-Camera Tracking reference app (and indirectly for Occupancy Analytics app).
Detection Model |
ReID Model |
Accuracy Impact |
Performance Impact |
How to Enable |
|---|---|---|---|---|
PeopleNet (ResNet-34) |
ReIdentificationNet (ResNet-50) |
Baseline accuracy. The HOTA scores are 37% and 40% on our internal real and synthetic datasets, respectively. |
Best throughput. For the sample input dataset, can support up to 21 streams (1080p @ 30 FPS) on one NVIDIA A100 at ~65% GPU utilization. |
Docker Compose: Default models for the deployment. Refer to quickstart deployment env vars.
K8s: The Transformer-based model combination is used by default. Refer to the model update guide to revert both the detection & ReID models.
|
PeopleNet (ResNet-34) |
ReIdentificationNet Transformer (Swin-Tiny) |
Best ReID. The association accuracy (AssA) improves by ~4% on real data and ~2% on synthetic data.
ReIdentificationNet Transformer is more generalizable than the CNN-variant. Thus recommended when the appearance distribution of people in the target domain differs substantially from that in Market-1501 and/or AICity’23, our training sets.
|
Moderate throughput. Due to the added compute demand of ReIdentificationNet Transformer, this combination can support up to 10 streams on a single NVIDIA A100 at 94% GPU utilization. |
Docker Compose: Set
MODEL_TYPE to cnn (more here) and refer to MTMC model update overview to update the ReID model. Or vice versa, set to transformer and revert the detection model.K8s: The Transformer-based model combination is used by default. Refer to the model update guide to revert the detection model.
|
PeopleNet Transformer (FAN-Small + DINO) |
ReIdentificationNet (ResNet-50) |
Best detection. The detection accuracy (DetA) improves by ~4% on real data and ~23% on synthetic data. PeopleNet was trained on real data only, and PeopleNet Transformer can generalize better to unseen domains such as synthetic data. |
Low-moderate throughput. PeopleNet Transformer is even more compute-intensive than ReIdentificationNet Transformer. This combination can support up to 4 streams on a single NVIDIA A100 at 71% GPU utilization. |
Docker Compose: Set
MODEL_TYPE to cnn (more here) and refer to MTMC model update overview to update the detection model. Or vice versa, set to transformer and revert the ReID model.K8s: The Transformer-based model combination is used by default. Refer to the model update guide to revert the ReID model.
|
PeopleNet Transformer (FAN-Small + DINO) |
ReIdentificationNet Transformer (Swin Tiny) |
Best accuracy. The HOTA scores are 43% and 62% on our internal real and synthetic KPIs, respectively. |
Lowest throughput. Up to 4 streams can be supported on a single NVIDIA A100 at 96% GPU utilization. If using an NVIDIA H100, it can support 6-8 streams. |
K8s: The Transformer-based model combination is used by default.
|