

Evaluation
Goal: Understand what evaluation is, how to evaluate agents and models, and what makes a good evaluation.
Read first: Environments — what an environment is and how it decomposes into dataset, agent harness, verifier, and state.
For the end-to-end workflow, see Evaluation.
What is Evaluation?
Evaluation is the entire process of running an agent on tasks, scoring the results and measuring performance. It exists to guide improvements to the AI pipeline — evaluation scores give information on what’s working, what’s not, and where to focus next.
Model performance has many different dimensions, and evaluation can be used to measure them: from the model’s accuracy, or any other similar definition of intelligence, to the quality of its tool calling, the confidence in operating in a specific environment, and even latency or token usage.
The process of evaluating entails different components. For example: to evaluate how accurate a coding agent is at fixing bugs, the following are needed:
- The model (in Gym, accessed by deploying the model server)
- The agent harness, which determines the tools it can access (agent server)
- A set of real bugs to test against (the dataset, integrated into the environment in the resources server)
- A sandbox with the code repository for the agent to work in (state, that exists in an environment in the resources server)
- A test suite to check if the fix actually works (verifier, contained in the environment)
Environments vs Benchmarks
An environment is the executable task setup: dataset, resources server, verifier, state, tools, and the agent interaction pattern. It defines what the agent can do and how each attempt is scored.
A benchmark is a repeatable evaluation built on top of an environment. It fixes the dataset, the metrics being tracked and the comparison protocol, so different models or harnesses can be compared fairly.
Not every environment is a benchmark. Some environments are used mainly for training data or harness development. Conversely, a benchmark may use one environment with a fixed split, or a curated subset of an environment selected for a specific capability.
How to Evaluate Agents and Models
The model, the agent harness, or both can be evaluated together depending on what is being improved.
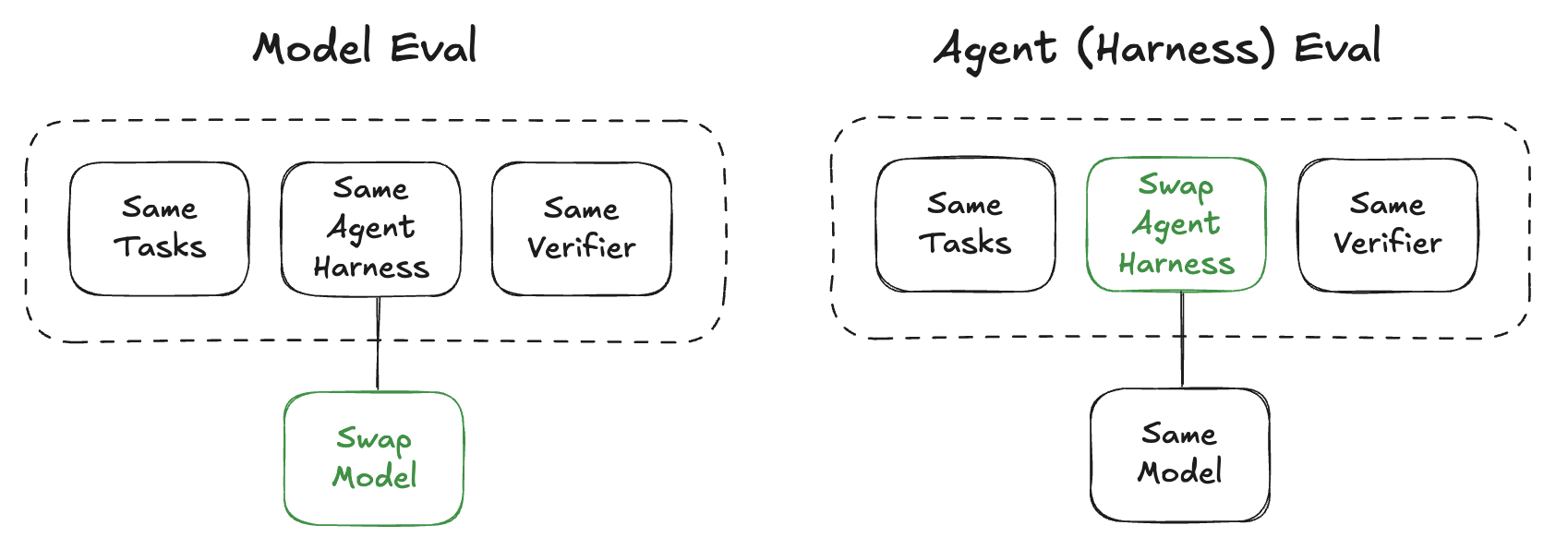
Model Capability
Swap the model, keep everything else the same.
E.g. compare Qwen vs Kimi on SWE-Bench with OpenHands
The agent harness (e.g. OpenHands) is held constant so the scores reflect model capability. Evaluation metrics can span accuracy, token usage, latency, and cost across models. The environment is the same for both runs — only the model changes.
Agent Capability
Swap the agent harness, keep everything else the same.
E.g. a new tool was added, the system prompt was rewritten, or the retry logic was changed — running the same tasks with the same model shows whether the agent improved.
The model is held constant so the scores reflect harness quality. A new tool might improve accuracy while tripling token usage; the eval should capture both. The environment and model are the same — only the harness changes.
Evaluation Data
The most important property of evaluation data is that it represents the actual use case. High scores on a public benchmark don’t guarantee performance on specific tasks if the distribution is different. When possible, combine public benchmarks with custom data drawn from the target domain. Tasks can come from multiple sources:
- Public benchmarks — standardized task sets for community comparison (e.g. SWE-Bench, AIME, HLE, Tau2).
- Custom datasets — tasks specific to the target use case, domain, or deployment.
- Production traces — real agent interactions captured from deployed systems.
How much data you need depends on what you’re measuring. A few hundred tasks can surface major capability gaps. Distinguishing small improvements (e.g. 2-3% accuracy gains) requires larger datasets and multiple repeats per task to separate signal from noise.
Characteristics of Good Evaluation
Coverage
Tasks should be diverse and representative of real usage. A narrow eval suite gives false confidence — high scores on one task type can mask failures elsewhere.
Verifier Design
The verifier defines what “good” means — not just correctness, but potentially efficiency, format adherence, or safety. A noisy or biased verifier gives misleading scores — the result is optimization for the wrong thing. Programmatic checks (exact match, test suites, code execution) are more consistent than LLM-as-Judge; use them when possible.
Realistic Interaction
The evaluation should reflect how the agent actually operates: multi-turn conversation, tool use, code execution, stateful environments. Simplifying the interaction pattern during eval means your scores won’t predict real-world performance.
Statistical Confidence
A single run is noisy. Multiple repeats on each task let you distinguish real improvements from variance. Increase repeats until scores stabilize across runs.
Reproducibility
Fixed components and clean state per task ensure that the same input produces the same score. Without this, you can’t tell whether a score difference reflects a real improvement or just environmental variation.
Next Steps
Evaluation scores guide what to improve next.