

Training
Goal: Understand post-training techniques and how environments are used for training.
Read first: Environments — what an environment is and how it decomposes into dataset, agent harness, verifier, and state.
What is Training?
Training updates model weights to improve performance. This page focuses on post-training: techniques applied after pre-training to specialize behavior for target tasks. If you are developing an agent, training the underlying model on your target environments improves how reliably it follows instructions, uses tools, and reasons within your harness.
Training Techniques
Supervised Fine-Tuning (SFT)
SFT fits best when clear target behaviors can be provided via demonstrations (instruction-response pairs). It is effective for teaching format, style, and tool-calling conventions. However, SFT has limitations:
- Imitation over adaptivity: when the dataset is small, models learn to mimic the answer rather than learn the process to get there.
- Data bottlenecks: curating high-quality demonstrations for every edge case is expensive.
- Brittleness: SFT models often struggle when scenarios fall outside their training distribution, so the dataset needs to be diverse and large.
Reinforcement Learning (RL)
RL becomes the better choice as complexity grows. Instead of telling the model “say exactly this,” RL provides a goal and a way to verify it. This allows the model to explore reasoning paths, making it resilient to edge cases. RL works well for tasks with clear verification: math, code, and tool calling.
Modern workflows favor efficient algorithms that replace expensive critic models with verifiable rewards such as:
GRPO (Group Relative Policy Optimization) generates groups of outputs and scores them against a deterministic verifier. Eliminating the value model and reward model from PPO significantly reduces memory overhead and is a key factor in scaling reasoning capabilities. During GRPO training, the environment scores each rollout, and the algorithm uses those scores to update the model in real time.
DAPO (Decoupled Clip and Dynamic Sampling Policy Optimization) improves on GRPO with dynamic sampling (skips prompts where all rollouts score the same, since there’s no learning signal) and asymmetric clipping to maintain exploration diversity.
GSPO (Group Sequence Policy Optimization) operates at the sequence level rather than token level, reducing variance and improving training stability, particularly for Mixture-of-Experts models.
Combining SFT + RL
In practice, SFT and RL are complementary:
- SFT for warm-starting RL: use demonstrations to teach the chat template, tool-calling format, and general readability. This prevents RL from wasting compute learning format.
- RL for scaling: transition to RL to allow the model to explore and self-correct. This is where reasoning and robustness are forged.
The industry is shifting toward allocating more compute during RL stages, especially as RL environments become more sophisticated and accessible.
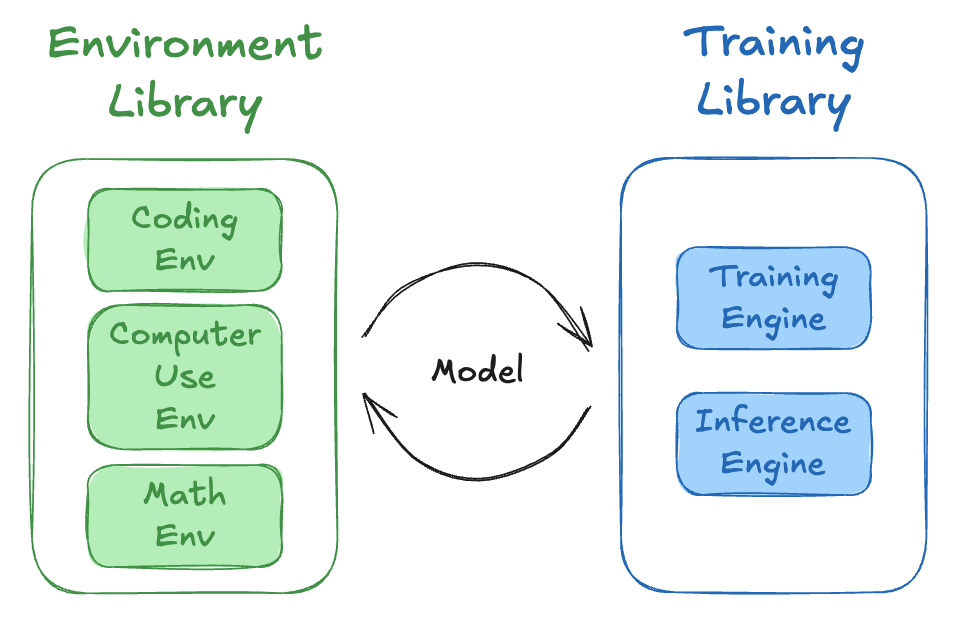
Training Environments
As Reward Signal (RL)
During RL training, the agent executes a task in an environment, and then is scored by a verifier to calculate a reward. The agent trajectory and reward scores are consumed by the training engine to update the model weights. Multiple environments are often used simultaneously during training; this is typically referred to as multi-environment or multi-verifier training.
As Synthetic Data Generators
Environments can also generate training data for offline methods. The workflow:
- Collect rollouts — run an agent in environments and score each attempt.
- Filter by reward — keep successful rollouts (high reward) and discard failures.
- Format as training data — successful rollouts become SFT demonstrations; pairs of high-reward and low-reward rollouts on the same task become DPO preference pairs.
This turns an environment into a synthetic data generation (SDG) pipeline.