Agentic Evaluation Metrics#
Evaluate agent-based and multi-step reasoning models using metrics powered by RAGAS. These metrics assess tool calling accuracy, goal completion, topic adherence, and answer correctness in agentic workflows.
Agent Workflow Evaluation Stages#
Key stages of agent workflow evaluation:
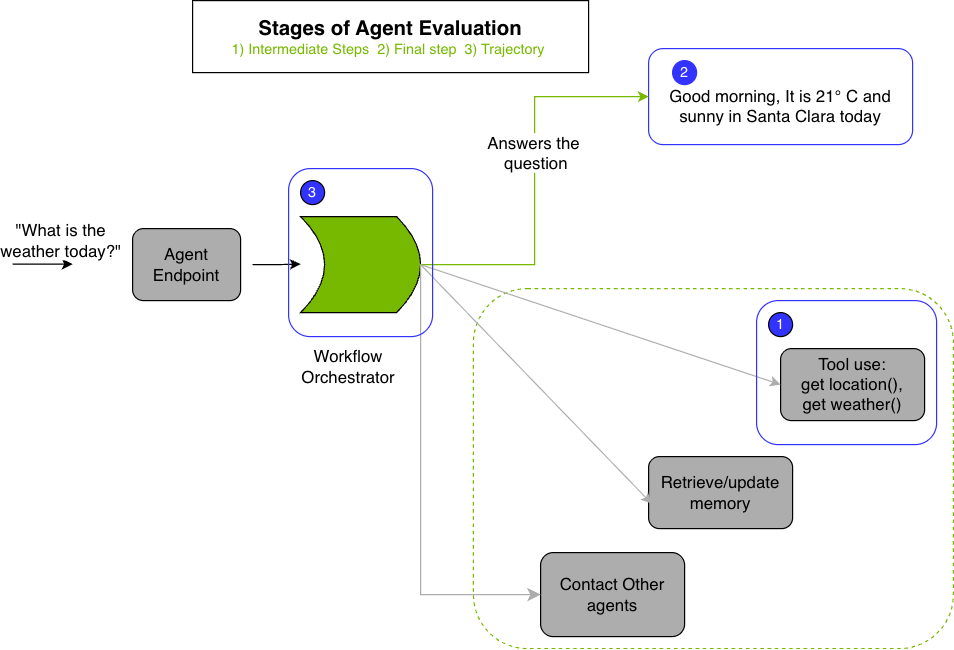
1. Intermediate Steps Evaluation Assesses the correctness of intermediate steps during agent execution:
Tool Use: Validates that the agent invoked the right tools with correct arguments at each step. Refer to Tool Call Accuracy for implementation details.
Retriever Models: Assesses effectiveness of document retrieval pipelines using retriever metrics.
2. Final-Step Evaluation Evaluates the quality of the agent’s final output using:
Agent Goal Accuracy: Measures whether the agent successfully completed the requested task. Refer to Agent Goal Accuracy.
Topic Adherence: Assesses how well the agent maintained focus on the assigned topic throughout the conversation. Refer to Topic Adherence.
Answer Accuracy: Evaluates the factual correctness of agent answers. Refer to Answer Accuracy.
Custom Metrics: For domain-specific or custom evaluation criteria, use LLM-as-a-Judge with the
datatask type.
3. Trajectory Evaluation Evaluates the agent’s decision-making process by analyzing the entire sequence of actions taken to accomplish a goal. This includes assessing whether the agent chose appropriate tools in the correct order. Refer to Trajectory Evaluation for configuration details.
Online vs Offline Evaluation#
Agentic metrics support both online and offline evaluation modes:
Online Evaluation#
For MetricOnlineJob, responses are generated automatically:
Job’s model and prompt_template are used to generate responses
Generated response (in
sample["output_text"]) is automatically used asresponsein RAGAS evaluationDataset variables can be included in the job’s
prompt_template:{{user_input}}- User input from dataset (can be a list for multi-turn conversations)Other dataset columns are also available in the template context
Offline Evaluation#
For MetricOfflineJob, pre-generated responses must be in the dataset:
Dataset must include a
responsecolumn with pre-generated agent responsesNo model generation is performed
Useful for evaluating existing agent outputs or comparing different response strategies
Note
Response Usage: In online mode, the generated response is automatically used by RAGAS metrics. The dataset’s response column is optional and will be overridden by the generated response if present.
Overview#
Agentic metrics evaluate different aspects of agent behavior:
Metric |
Use Case |
Requires Judge |
Evaluation Mode |
|---|---|---|---|
Evaluates tool/function call correctness |
No |
Live + Job |
|
Evaluates tool/function call correctness using Jinja templates |
No |
Live + Job |
|
Measures topic focus in multi-turn conversations |
Yes |
Live + Job |
|
Assesses goal completion, with or without reference. |
Yes |
Live + Job |
|
Checks factual correctness |
Yes |
Live + Job |
|
Evaluates decision-making across action sequence |
Yes |
Job only |
Note
Live evaluation: Immediate results, ideal for quick evaluations with small datasets (up to 10 rows)
Job evaluation: Asynchronous processing, suitable for large datasets with progress monitoring
Prerequisites#
Before running agentic evaluations:
Workspace: Have a workspace created. All resources (metrics, secrets, jobs) are scoped to a workspace.
Judge LLM endpoint (for most metrics): Have access to an LLM that will serve as your judge.
API key secret (if judge requires auth): If your judge endpoint requires authentication, create a secret to store the API key.
Initialize the SDK:
import os
from nemo_platform import NeMoPlatform
client = NeMoPlatform(
base_url=os.environ.get("NMP_BASE_URL", "http://localhost:8080"),
workspace="default",
)
Creating a Secret for API Keys#
If using external endpoints (for example, the NVIDIA API), create a secret first:
client.secrets.create(
name="nvidia-api-key",
data="nvapi-YOUR_API_KEY_HERE",
description="NVIDIA API key for RAGAS metrics"
)
SDK Types Reference#
The SDK provides typed classes for metric definitions. Import them from nemo_platform.types.evaluation:
from nemo_platform.types.evaluation import (
# Metric types
ToolCallAccuracyMetricParam,
TopicAdherenceMetricParam,
AgentGoalAccuracyMetricParam,
AnswerAccuracyMetricParam,
ToolCallingMetricParam,
# Supporting types
DatasetRowsParam,
EvaluationJobParamsParam,
MetricOfflineJobParam,
MetricOnlineJobParam,
ModelParam,
)
These types provide IDE autocompletion and type checking. Examples in this guide use dictionary syntax for simplicity, but SDK types are recommended for production code.
Agentic Metrics#
Tool Call Accuracy#
Evaluates whether the agent invoked the correct tools with the correct arguments. This metric does not require a judge LLM.
Note
Online/Offline support: Tool Call Accuracy supports both online and offline jobs. In online jobs, the generation model can produce tool calls that are then scored. In offline jobs, pre-generated tool calls from the dataset are scored directly.
Data Format#
{
"user_input": [
{"content": "What's the weather like in New York?", "type": "human"},
{"content": "Let me check that for you.", "type": "ai", "tool_calls": [{"name": "weather_check", "args": {"location": "New York"}}]},
{"content": "It's 75°F and partly cloudy.", "type": "tool"},
{"content": "The weather in New York is 75°F and partly cloudy.", "type": "ai"}
],
"reference_tool_calls": [
{"name": "weather_check", "args": {"location": "New York"}}
]
}
from nemo_platform.types.evaluation import (
DatasetRowsParam,
ToolCallAccuracyMetricParam,
)
result = client.evaluation.metrics.evaluate(
metric=ToolCallAccuracyMetricParam(type="tool_call_accuracy"),
dataset=DatasetRowsParam(rows=[{
"user_input": [
{"content": "What's the weather in Paris?", "type": "human"},
{"content": "Let me check.", "type": "ai",
"tool_calls": [{"name": "weather_api", "args": {"city": "Paris"}}]},
{"content": "Sunny, 22°C", "type": "tool"},
{"content": "It's sunny and 22°C in Paris.", "type": "ai"},
],
"reference_tool_calls": [{"name": "weather_api", "args": {"city": "Paris"}}],
}]),
)
for score in result.aggregate_scores:
print(f"{score.name}: mean={score.mean}")
from nemo_platform.types.evaluation import (
EvaluationJobParamsParam,
MetricOfflineJobParam,
ToolCallAccuracyMetricParam,
)
# Create a metric entity (optional - can use inline metric)
client.evaluation.metrics.create(
name="my-tool-call-accuracy",
metric=ToolCallAccuracyMetricParam(type="tool_call_accuracy"),
)
# Create the evaluation job
job = client.evaluation.metric_jobs.create(
spec=MetricOfflineJobParam(
metric="my-workspace/my-tool-call-accuracy",
dataset="my-workspace/tool-call-dataset",
params=EvaluationJobParamsParam(parallelism=16),
),
)
print(f"Job created: {job.name}")
{
"aggregate_scores": [
{
"name": "tool_call_accuracy",
"count": 1,
"mean": 1.0,
"min": 1.0,
"max": 1.0
}
],
"row_scores": [
{
"index": 0,
"scores": {"tool_call_accuracy": 1.0}
}
]
}
Tool Calling (Template)#
A template-based metric for evaluating tool/function call accuracy. Unlike the RAGAS Tool Call Accuracy metric, this metric uses configurable templates and produces multiple scores.
Note
Online/Offline support: Tool Calling supports both online and offline jobs. Use online jobs when you want the model to generate tool calls first, or offline jobs when your dataset already contains tool-call outputs.
Scores Produced#
function_name_accuracy— Accuracy of function names onlyfunction_name_and_args_accuracy— Accuracy of both function names and arguments
Data Format#
Data must use OpenAI-compliant tool calling format:
{
"messages": [
{"role": "user", "content": "Book a table for 2 at 7pm."},
{"role": "assistant", "content": "Booking a table...", "tool_calls": [{"function": {"name": "book_table", "arguments": {"people": 2, "time": "7pm"}}}]}
],
"tool_calls": [
{"function": {"name": "book_table", "arguments": {"people": 2, "time": "7pm"}}}
],
"response": {
"choices": [
{
"message": {
"tool_calls": [
{
"function": {
"name": "book_table",
"arguments": "{\"people\": 2, \"time\": \"7pm\"}"
}
}
]
}
}
]
}
}
Note
Function names with dots (
.) must be replaced with underscores (_)Comparison is case-sensitive
Order of tool calls is ignored (supports parallel tool calling)
from nemo_platform.types.evaluation import (
DatasetRowsParam,
ToolCallingMetricParam,
)
result = client.evaluation.metrics.evaluate(
dataset=DatasetRowsParam(
rows=[
{
"messages": [
{"role": "user", "content": "Book a table for 2 at 7pm."},
{"role": "assistant", "content": "Booking...", "tool_calls": [{"function": {"name": "book_table", "arguments": {"people": 2, "time": "7pm"}}}]}
],
"tool_calls": [
{"function": {"name": "book_table", "arguments": {"people": 2, "time": "7pm"}}}
],
"response": {
"choices": [
{
"message": {
"tool_calls": [
{
"function": {
"name": "book_table",
"arguments": "{\"people\": 2, \"time\": \"7pm\"}"
}
}
]
}
}
]
}
}
]
),
metric=ToolCallingMetricParam(
type="tool-calling",
reference="{{tool_calls}}",
),
)
for score in result.aggregate_scores:
print(f"{score.name}: mean={score.mean:.2f}")
For job-based evaluation, first create a metric entity, then reference it by the unique workspace and metric name:
from nemo_platform.types.evaluation import (
EvaluationJobParamsParam,
MetricOfflineJobParam,
ToolCallingMetricParam,
)
# Step 1: Create the metric entity
client.evaluation.metrics.create(
name="my-tool-calling-metric",
metric=ToolCallingMetricParam(
type="tool-calling",
reference="{{tool_calls}}",
),
)
# Step 2: Create the evaluation job
# Dataset rows must include the same `response.choices[0].message.tool_calls` shape shown above.
job = client.evaluation.metric_jobs.create(
spec=MetricOfflineJobParam(
metric="my-workspace/my-tool-calling-metric",
dataset="my-workspace/tool-calling-dataset",
params=EvaluationJobParamsParam(parallelism=16),
),
)
{
"aggregate_scores": [
{
"name": "function_name_accuracy",
"count": 1,
"mean": 1.0,
"min": 1.0,
"max": 1.0
},
{
"name": "function_name_and_args_accuracy",
"count": 1,
"mean": 1.0,
"min": 1.0,
"max": 1.0
}
]
}
Topic Adherence#
Measures how well the agent maintained focus on assigned topics throughout a conversation. Supports F1, precision, or recall scoring modes.
Data Format#
{
"user_input": [
{"content": "How do I stay healthy?", "type": "human"},
{"content": "Eat more fruits and vegetables, and exercise regularly.", "type": "ai"}
],
"reference_topics": ["health", "nutrition", "fitness"]
}
Configuration Options#
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
string |
|
Scoring mode: |
Using SDK types for better IDE support and type safety:
from nemo_platform.types.evaluation import (
TopicAdherenceMetricParam,
DatasetRowsParam,
ModelParam,
)
result = client.evaluation.metrics.evaluate(
metric=TopicAdherenceMetricParam(
type="topic_adherence",
metric_mode="f1",
judge_model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
),
),
dataset=DatasetRowsParam(
rows=[{
"user_input": [
{"content": "Tell me about healthy eating", "type": "human"},
{"content": "Eating fruits and vegetables is essential for good health.", "type": "ai"},
],
"reference_topics": ["health", "nutrition", "diet"],
}]
),
)
for score in result.aggregate_scores:
print(f"{score.name}: mean={score.mean}")
from nemo_platform.types.evaluation import (
EvaluationJobParamsParam,
MetricOfflineJobParam,
ModelParam,
TopicAdherenceMetricParam,
)
# Create the metric entity
client.evaluation.metrics.create(
name="my-topic-adherence",
metric=TopicAdherenceMetricParam(
type="topic_adherence",
metric_mode="f1",
judge_model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
),
),
)
# Create the offline evaluation job (dataset must include response)
job = client.evaluation.metric_jobs.create(
spec=MetricOfflineJobParam(
metric="my-workspace/my-topic-adherence",
dataset="my-workspace/my-topic-dataset", # Must include response column
params=EvaluationJobParamsParam(parallelism=16),
),
)
print(f"Job created: {job.name}")
from nemo_platform.types.evaluation import (
EvaluationJobParamsParam,
MetricOnlineJobParam,
ModelParam,
TopicAdherenceMetricParam,
)
# Create the metric entity
client.evaluation.metrics.create(
name="my-topic-adherence",
metric=TopicAdherenceMetricParam(
type="topic_adherence",
metric_mode="f1",
judge_model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
),
),
)
# Create the online evaluation job (response will be generated automatically)
job = client.evaluation.metric_jobs.create(
spec=MetricOnlineJobParam(
metric="my-workspace/my-topic-adherence",
model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="nvidia/llama-3.3-nemotron-super-49b-v1",
api_key_secret="nvidia-api-key",
),
prompt_template={
"messages": [{
"role": "user",
"content": "{{ user_input if user_input is string else (user_input | string) }}"
}]
},
dataset="my-workspace/my-topic-dataset", # response column optional
params=EvaluationJobParamsParam(
parallelism=16,
inference={
"temperature": 0.7,
"max_tokens": 1024
},
),
),
)
print(f"Job created: {job.name}")
{
"aggregate_scores": [
{
"name": "topic_adherence(mode=f1)",
"count": 1,
"mean": 0.85,
"min": 0.85,
"max": 0.85
}
],
"row_scores": [
{
"index": 0,
"scores": {"topic_adherence(mode=f1)": 0.85}
}
]
}
Agent Goal Accuracy#
Evaluates whether the agent successfully completed the requested task. Returns a binary score (0 or 1). Supports evaluation with or without a reference outcome.
With Reference#
Compare the agent’s outcome against a known reference:
Data Format
{
"user_input": [
{"content": "Book a table at a Chinese restaurant for 8pm", "type": "human"},
{"content": "I'll search for restaurants.", "type": "ai",
"tool_calls": [{"name": "restaurant_search", "args": {}}]},
{"content": "Found: Italian Place", "type": "tool"},
{"content": "Your table at Italian Place is booked for 8pm.", "type": "ai"}
],
"reference": "Successfully booked a table at a restaurant for 8pm"
}
Configuration Options
Parameter |
Type |
Default |
Description |
|---|---|---|---|
|
boolean |
|
Whether to compare against a reference outcome |
from nemo_platform.types.evaluation import (
AgentGoalAccuracyMetricParam,
DatasetRowsParam,
ModelParam,
)
result = client.evaluation.metrics.evaluate(
metric=AgentGoalAccuracyMetricParam(
type="agent_goal_accuracy",
use_reference=True,
judge_model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
),
),
dataset=DatasetRowsParam(rows=[{
"user_input": [
{"content": "Book a table at a restaurant for 8pm", "type": "human"},
{"content": "I'll search for restaurants.", "type": "ai",
"tool_calls": [{"name": "restaurant_search", "args": {}}]},
{"content": "Found: Italian Place", "type": "tool"},
{"content": "Your table at Italian Place is booked for 8pm.", "type": "ai"},
],
"reference": "Successfully booked a table at a restaurant for 8pm",
}]),
)
for score in result.aggregate_scores:
print(f"{score.name}: mean={score.mean}")
from nemo_platform.types.evaluation import (
AgentGoalAccuracyMetricParam,
EvaluationJobParamsParam,
MetricOfflineJobParam,
ModelParam,
)
# Create the metric entity
client.evaluation.metrics.create(
name="my-goal-accuracy-with-ref",
metric=AgentGoalAccuracyMetricParam(
type="agent_goal_accuracy",
use_reference=True,
judge_model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
),
),
)
# Create the offline evaluation job (dataset must include response)
job = client.evaluation.metric_jobs.create(
spec=MetricOfflineJobParam(
metric="my-workspace/my-goal-accuracy-with-ref",
dataset="my-workspace/goal-accuracy-dataset", # Must include response column
params=EvaluationJobParamsParam(parallelism=16),
),
)
print(f"Job created: {job.name}")
from nemo_platform.types.evaluation import (
AgentGoalAccuracyMetricParam,
EvaluationJobParamsParam,
MetricOnlineJobParam,
ModelParam,
)
# Create the metric entity
client.evaluation.metrics.create(
name="my-goal-accuracy-with-ref",
metric=AgentGoalAccuracyMetricParam(
type="agent_goal_accuracy",
use_reference=True,
judge_model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
),
),
)
# Create the online evaluation job (response will be generated automatically)
job = client.evaluation.metric_jobs.create(
spec=MetricOnlineJobParam(
metric="my-workspace/my-goal-accuracy-with-ref",
model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="nvidia/llama-3.3-nemotron-super-49b-v1",
api_key_secret="nvidia-api-key",
),
prompt_template={
"messages": [{
"role": "user",
"content": "{{ user_input if user_input is string else (user_input | string) }}"
}]
},
dataset="my-workspace/goal-accuracy-dataset", # response column optional
params=EvaluationJobParamsParam(
parallelism=16,
inference={
"temperature": 0.7,
"max_tokens": 1024
},
),
),
)
print(f"Job created: {job.name}")
{
"aggregate_scores": [
{
"name": "agent_goal_accuracy",
"count": 1,
"mean": 1.0,
"min": 1.0,
"max": 1.0
}
],
"row_scores": [
{
"index": 0,
"scores": {"agent_goal_accuracy": 1.0}
}
]
}
Without Reference#
The judge LLM infers the goal from the conversation context:
Data Format
{
"user_input": [
{"content": "Set a reminder for my dentist appointment tomorrow at 2pm", "type": "human"},
{"content": "I'll set that reminder for you.", "type": "ai", "tool_calls": [{"name": "set_reminder", "args": {"title": "Dentist appointment", "date": "tomorrow", "time": "2pm"}}]},
{"content": "Reminder set successfully.", "type": "tool"},
{"content": "Your reminder for the dentist appointment tomorrow at 2pm has been set.", "type": "ai"}
]
}
from nemo_platform.types.evaluation import (
AgentGoalAccuracyMetricParam,
DatasetRowsParam,
ModelParam,
)
result = client.evaluation.metrics.evaluate(
metric=AgentGoalAccuracyMetricParam(
type="agent_goal_accuracy",
use_reference=False,
judge_model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
),
),
dataset=DatasetRowsParam(rows=[{
"user_input": [
{"content": "Set a reminder for my dentist appointment tomorrow at 2pm", "type": "human"},
{"content": "I'll set that reminder for you.", "type": "ai",
"tool_calls": [{"name": "set_reminder", "args": {"title": "Dentist appointment", "date": "tomorrow", "time": "2pm"}}]},
{"content": "Reminder set successfully.", "type": "tool"},
{"content": "Your reminder has been set.", "type": "ai"},
],
}]),
)
for score in result.aggregate_scores:
print(f"{score.name}: mean={score.mean}")
from nemo_platform.types.evaluation import (
AgentGoalAccuracyMetricParam,
EvaluationJobParamsParam,
MetricOfflineJobParam,
ModelParam,
)
# Create the metric entity
client.evaluation.metrics.create(
name="my-goal-accuracy-no-ref",
metric=AgentGoalAccuracyMetricParam(
type="agent_goal_accuracy",
use_reference=False,
judge_model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
),
),
)
# Create the offline evaluation job (dataset must include response)
job = client.evaluation.metric_jobs.create(
spec=MetricOfflineJobParam(
metric="my-workspace/my-goal-accuracy-no-ref",
dataset="my-workspace/goal-accuracy-dataset", # Must include response column
params=EvaluationJobParamsParam(parallelism=16),
),
)
print(f"Job created: {job.name}")
from nemo_platform.types.evaluation import (
AgentGoalAccuracyMetricParam,
EvaluationJobParamsParam,
MetricOnlineJobParam,
ModelParam,
)
# Create the metric entity
client.evaluation.metrics.create(
name="my-goal-accuracy-no-ref",
metric=AgentGoalAccuracyMetricParam(
type="agent_goal_accuracy",
use_reference=False,
judge_model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
),
),
)
# Create the online evaluation job (response will be generated automatically)
job = client.evaluation.metric_jobs.create(
spec=MetricOnlineJobParam(
metric="my-workspace/my-goal-accuracy-no-ref",
model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="nvidia/llama-3.3-nemotron-super-49b-v1",
api_key_secret="nvidia-api-key",
),
prompt_template={
"messages": [{
"role": "user",
"content": "{{ user_input if user_input is string else (user_input | string) }}"
}]
},
dataset="my-workspace/goal-accuracy-dataset", # response column optional
params=EvaluationJobParamsParam(
parallelism=16,
inference={
"temperature": 0.7,
"max_tokens": 1024
},
),
),
)
print(f"Job created: {job.name}")
Answer Accuracy#
Evaluates the factual correctness of an agent’s answer by comparing it against a reference answer. Two LLM judges independently rate the agreement, and scores are averaged. Scores range from 0 (incorrect) to 0.5 (partial match) to 1 (exact match).
Data Format#
{
"user_input": "What is the capital of France?",
"response": "The capital of France is Paris.",
"reference": "Paris"
}
from nemo_platform.types.evaluation import (
AnswerAccuracyMetricParam,
DatasetRowsParam,
ModelParam,
)
result = client.evaluation.metrics.evaluate(
metric=AnswerAccuracyMetricParam(
type="answer_accuracy",
judge_model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
),
),
dataset=DatasetRowsParam(rows=[{
"user_input": "What is the capital of France?",
"response": "The capital of France is Paris.",
"reference": "Paris",
}]),
)
for score in result.aggregate_scores:
print(f"{score.name}: mean={score.mean}")
from nemo_platform.types.evaluation import (
AnswerAccuracyMetricParam,
EvaluationJobParamsParam,
MetricOfflineJobParam,
ModelParam,
)
# Create the metric entity
client.evaluation.metrics.create(
name="my-answer-accuracy",
metric=AnswerAccuracyMetricParam(
type="answer_accuracy",
judge_model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
),
),
)
# Create the offline evaluation job (dataset must include response)
job = client.evaluation.metric_jobs.create(
spec=MetricOfflineJobParam(
metric="my-workspace/my-answer-accuracy",
dataset="my-workspace/qa-dataset", # Must include response column
params=EvaluationJobParamsParam(parallelism=16),
),
)
print(f"Job created: {job.name}")
from nemo_platform.types.evaluation import (
AnswerAccuracyMetricParam,
EvaluationJobParamsParam,
MetricOnlineJobParam,
ModelParam,
)
# Create the metric entity
client.evaluation.metrics.create(
name="my-answer-accuracy",
metric=AnswerAccuracyMetricParam(
type="answer_accuracy",
judge_model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
),
),
)
# Create the online evaluation job (response will be generated automatically)
job = client.evaluation.metric_jobs.create(
spec=MetricOnlineJobParam(
metric="my-workspace/my-answer-accuracy",
model=ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="nvidia/llama-3.3-nemotron-super-49b-v1",
api_key_secret="nvidia-api-key",
),
prompt_template={
"messages": [{
"role": "user",
"content": "{{ user_input }}"
}]
},
dataset="my-workspace/qa-dataset", # response column optional
params=EvaluationJobParamsParam(
parallelism=16,
inference={
"temperature": 0.7,
"max_tokens": 1024
},
),
),
)
print(f"Job created: {job.name}")
{
"aggregate_scores": [
{
"name": "nv_accuracy",
"count": 1,
"mean": 1.0,
"min": 1.0,
"max": 1.0
}
],
"row_scores": [
{"index": 0, "scores": {"nv_accuracy": 1.0}}
]
}
Trajectory Evaluation#
Evaluates the agent’s decision-making process by analyzing the entire sequence of actions (trajectory) taken to accomplish a goal. This system metric assesses whether the agent chose appropriate tools in the correct order.
Important
NAT Format Requirement: This metric supports the NVIDIA Agent Toolkit format with intermediate_steps containing detailed event traces.
Job-Only: This is a system metric that only supports job-based evaluation.
Data Format#
Each data entry must follow the NeMo Agent Toolkit format:
{
"question": "What are LLMs",
"generated_answer": "LLMs, or Large Language Models, are a type of artificial intelligence designed to process and generate human-like language. They are trained on vast amounts of text data and can be fine-tuned for specific tasks or guided by prompt engineering.",
"answer": "LLMs stand for Large Language Models, which are a type of machine learning model designed for natural language processing tasks such as language generation.",
"intermediate_steps": [
{
"payload": {
"event_type": "LLM_END",
"name": "nvidia/llama-3.3-nemotron-super-49b-v1",
"data": {
"input": "\nPrevious conversation history:\n\n\nQuestion: What are LLMs\n",
"output": "Thought: I need to find information about LLMs to answer this question.\n\nAction: wikipedia_search\nAction Input: {'question': 'LLMs'}\n\n"
}
}
},
{
"payload": {
"event_type": "TOOL_END",
"name": "wikipedia_search",
"data": {
"input": "{'question': 'LLMs'}",
"output": "<Document source=\"https://en.wikipedia.org/wiki/Large_language_model\" page=\"\"/>\nA large language model (LLM) is a language model trained with self-supervised machine learning..."
}
}
},
{
"payload": {
"event_type": "LLM_END",
"name": "meta/llama-3.1-70b-instruct",
"data": {
"input": "...",
"output": "Thought: I now know the final answer\n\nFinal Answer: LLMs, or Large Language Models, are a type of artificial intelligence..."
}
}
}
]
}
Parameters#
Parameter |
Required |
Type |
Description |
|---|---|---|---|
|
required |
object |
Judge LLM configuration |
|
required |
string |
Comma-separated list of tools available to the agent. Example: |
|
optional |
object |
JSON mapping custom tool names to descriptions for non-default tools |
from nemo_platform.types.evaluation import (
EvaluationJobParamsParam,
MetricOfflineJobParam,
)
job = client.evaluation.metric_jobs.create(
spec=MetricOfflineJobParam(
metric="system/trajectory-evaluation",
dataset="my-workspace/trajectory-dataset",
params=EvaluationJobParamsParam(parallelism=1),
metric_params={
"judge": {
"model": {
"url": "<judge-nim-url>/v1/chat/completions",
"name": "nvidia/llama-3.3-nemotron-super-49b-v1"
}
},
"trajectory_used_tools": "wikipedia_search,current_datetime,code_generation,dummy_custom_tool",
"trajectory_custom_tools": {
"dummy_custom_tool": "Do nothing. This tool is for test only",
"code_generation": "Useful to generate Python code. For any questions about code generation, you must only use this tool!",
"wikipedia_search": "Tool that retrieves relevant contexts from wikipedia search for the given question.\n\n Args:\n _type (str): The type of the object.\n max_results (int): Description unavailable. Defaults to 2."
},
}
)
)
print(f"Job created: {job.name}")
client.evaluation.metric_jobs.results.aggregate_scores.download(job=job.name)
{
"scores": [
{
"name": "trajectory_evaluation",
"score_type": "range",
"count": 1,
"nan_count": 0,
"sum": 0.5,
"mean": 0.5,
"min": 0.5,
"max": 0.5,
"std_dev": 0.0,
"variance": 0.0
}
]
}
Judge Configuration#
Most agentic metrics require a judge LLM. Configure the judge model in the metric definition:
from nemo_platform.types.evaluation import ModelParam
judge_model = ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
)
Important
Recommended model size: Use a 70B+ parameter model as the judge for reliable results. Smaller models may fail to follow the required output schema, causing parsing errors.
Using Reasoning Models#
For models that support extended reasoning (like nvidia/llama-3.3-nemotron-super-49b-v1), add system prompt and reasoning parameters:
from nemo_platform.types.evaluation import (
EvaluationJobParamsParam,
ModelParam,
ReasoningParamsParam,
)
judge_model = ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="nvidia/llama-3.3-nemotron-super-49b-v1",
api_key_secret="nvidia-api-key",
)
params = EvaluationJobParamsParam(
system_prompt="detailed thinking on",
reasoning=ReasoningParamsParam(end_token="</think>"),
)
Managing Secrets for Authenticated Endpoints#
If your judge endpoint requires an API key, store it as a secret:
from nemo_platform.types.evaluation import (
ModelParam,
)
# Create the secret
client.secrets.create(
name="nvidia-api-key",
data="nvapi-YOUR_API_KEY_HERE"
)
# Reference in your metric configuration
judge_model = ModelParam(
url="https://integrate.api.nvidia.com/v1/chat/completions",
name="meta/llama-3.1-70b-instruct",
api_key_secret="nvidia-api-key",
)
For more details on secret management, refer to Managing Secrets.
Job Management#
After successfully creating a job, navigate to Metrics Job Management to oversee its execution and monitor progress.
Using Filesets for Large Datasets#
For datasets larger than 10 rows, upload your data to a fileset:
from nemo_platform.types.evaluation import (
EvaluationJobParamsParam,
MetricOfflineJobParam,
)
# Create a fileset
client.files.filesets.create(
name="agentic-eval-dataset",
description="Dataset for agentic evaluation"
)
# Upload data file (JSONL format)
client.files.upload(
local_path="evaluation_data.jsonl",
remote_path="data.jsonl",
fileset="agentic-eval-dataset"
)
# Reference in job by workspace and name (workspace/fileset-name)
job = client.evaluation.metric_jobs.create(
spec=MetricOfflineJobParam(
metric="my-workspace/my-tool-call-accuracy",
dataset="my-workspace/agentic-eval-dataset",
params=EvaluationJobParamsParam(parallelism=16),
),
)
For more details on dataset management, refer to Managing Dataset Files.
Important Notes#
Live vs Job Evaluation: Live evaluation supports up to 10 rows per request. For larger evaluations, use job-based evaluation.
Column Names: RAGAS metrics use specific column names:
user_input(notquestion)response(notanswer)reference(notground_truth)
Judge Model Quality: For metrics requiring a judge, evaluation quality depends on the judge model’s ability to follow instructions. Larger models (70B+) produce more consistent results.
RAGAS Dependency: These metrics are powered by RAGAS and may have version-specific behavior.
NaN troubleshooting for judge-based metrics: If you see
nan_count > 0withmean = null, check judge model authentication first (API key secret, endpoint access, and model permissions). Some RAGAS metrics are known to convert auth failures intoNaNscores instead of raising a hard error.
See also
Agentic Benchmarks - BFCL benchmark for tool-calling evaluation
LLM-as-a-Judge - Custom judge-based evaluation
Evaluation Results - Understanding and downloading results
RAG Metrics - RAGAS metrics for RAG pipelines