Query Decomposition for NVIDIA RAG Blueprint#
By default, query decomposition is disabled in the NVIDIA RAG Blueprint. When you turn on query decomposition you boost accuracy for multi-hop reasoning or context-rich queries.
Query decomposition is an advanced Retrieval-Augmented Generation (RAG) technique that breaks down complex, multi-faceted queries into simpler, focused subqueries. Each subquery is processed independently to gather comprehensive context, which is then synthesized into a final comprehensive response.
Key Benefits
Better Context Coverage – Captures multiple aspects of complex queries.
Iterative Refinement – Follows up with additional questions based on initial findings.
Multi-perspective Analysis – Approaches queries from different angles.
Core Components
Subquery Generation – LLM-powered breakdown of complex queries.
Iterative Processing – Multi-round refinement with follow-up questions.
Response Synthesis – Combines insights from all subqueries.
Accuracy Improvement Example#
The following example that uses the Google Frame benchmark demonstrates the accuracy improvement from enabling query decomposition.
Query: I am thinking of a Ancient Roman City. The city was destroyed by volcanic eruption. The eruption occurred in the year 79 AD. The volcano was a stratovolcano. Where was the session held where it was decided that the city would be named a UNESCO world heritage site?
Reference Answer: Naples
The response with no query decomposition is:
"The session where it was decided that the city would be named a UNESCO World Heritage Site was held in 1997. However, the specific location of this session is not mentioned in the provided context."
The response with query decomposition is:
"Naples"
Docker Deployment#
Deploy all the dependent services#
Follow the deployment guide for Self-Hosted Models or NVIDIA-Hosted Models.
Enable query decomposition#
Set the environment variable to enable query decomposition:
export ENABLE_QUERY_DECOMPOSITION=true
export MAX_RECURSION_DEPTH=3
After setting these environment variables, you must restart the RAG server for ENABLE_QUERY_DECOMPOSITION to take effect:
docker compose -f deploy/compose/docker-compose-rag-server.yaml up -d
Helm Deployment#
You can deploy RAG with query decomposition using Helm for Kubernetes environments. For details, see Deploy with Helm.
Update RAG Blueprint Deployment with Query Decomposition#
To enable query decomposition in RAG Blueprint:
Modify values.yaml to enable query decomposition:
# Environment variables for rag-server
envVars:
# ... existing configurations ...
# === Query Decomposition ===
ENABLE_QUERY_DECOMPOSITION: "true"
MAX_RECURSION_DEPTH: "3"
After modifying values.yaml, apply the changes as described in Change a Deployment.
For detailed HELM deployment instructions, see Helm Deployment Guide.
When to Use Query Decomposition#
Query decomposition is especially valuable for multi-hop or complex queries that involve multiple steps or aspects. By breaking down a complex question into smaller, focused subqueries, the system can generate intermediate answers for each part. These intermediate responses are then combined to produce a comprehensive and accurate final answer.
Example: Complex Multihop Query
"If my future wife has the same first name as the 15th first lady of the United States' mother
and her surname is the same as the second assassinated president's mother's maiden name,
what is my future wife's name?"
This query requires multiple interconnected steps:
1. Identify the 15th first lady of the United States
2. Find the 15th first lady's mother's first name
3. Identify the second assassinated president
4. Find that president's mother's maiden name
5. Combine the two names to form the final answer
When NOT to Use Query Decomposition#
Simple Factual Questions
"What is the capital of France?"
(Simple lookup, no decomposition needed)
Single-concept Queries
"Define machine learning"
(Direct definition, no sub-aspects needed)
Time-sensitive Queries
"What's the current stock price of NVIDIA?"
(Real-time data, decomposition adds latency)
Highly Specific Technical Questions
"What's the syntax for creating a Python dictionary?"
(Specific syntax, no multiple perspectives needed)
How Query Decomposition Works#
To visualize how query decomposition works, see the diagram below:
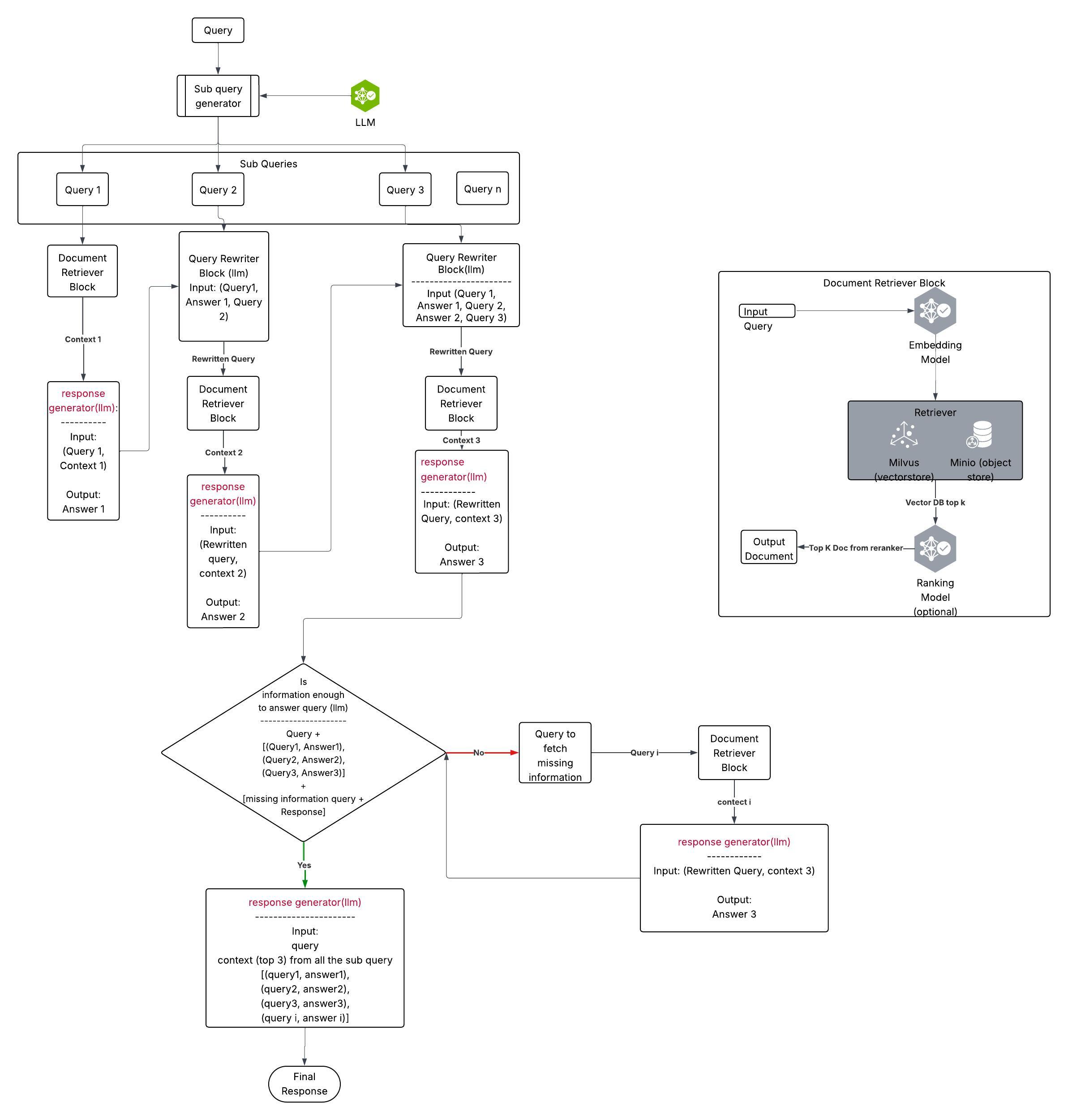
Query Decomposition Flow — The system breaks down a complex query into subqueries, processes each iteratively, and synthesizes a comprehensive answer.#
Core Algorithm#
Subquery Generation: Break down into focused questions
Iterative Processing: For each recursion depth:
Process each subquery independently
Rewrite queries with accumulated context
Retrieve and rank relevant documents
Generate focused answers
Collect contexts for synthesis
Follow-up Generation: Create follow-up questions for information missing from original query
Termination Check: Stop if no follow-up needed or max depth reached
Final Synthesis: Generate comprehensive response from all contexts and conversation
Important
Query decomposition is not available for direct LLM calls (when use_kb=false). This feature requires the knowledge base integration to process subqueries and retrieve relevant documents. For direct LLM interactions, queries are processed without decomposition.
Note
Query decomposition is currently limited to single collection operations. When query decomposition is enabled, multi-collection queries are not supported and will not function as expected.