GKE (Google Kubernetes Engine)#
Overview#
Added in version 3.1.
Google Kubernetes Engine (GKE) provides a managed environment for deploying, managing, and scaling your containerized applications using Google infrastructure. NVIDIA AI Enterprise, the end-to-end software of the NVIDIA AI platform, is supported to run on GKE. The GKE environment consists of multiple machines (specifically, Compute Engine instances) grouped together to form a cluster. This guide provides details for deploying and running NVIDIA AI Enterprise on GKE clusters with NVIDIA GPU Accelerated nodes.
Note
The NVIDIA Terraform Modules offer an easy way to deploy Managed Kubernetes clusters that can be supported by NVIDIA AI Enterprise when used with supported OS and GPU Operator versions.
Prerequisites#
NVIDIA AI Enterprise License via BYOL or a Private Offer
Install the Google Cloud CLI
Note
NVIDIA recommends installing the Google Cloud CLI via download of the linux google-cloud-cli-xxx.x.x-linux-x86_64.tar.gz file. If a different OS distribution is being utilized, please continue to follow Google’s instructions for your desired OS.

Google Cloud account with Google Kubernetes Engine Admin Role and Kubernetes Engine Cluster Admin Role for more information please refer to Google’s IAM Policies
Ubuntu Nodes
Create a GKE Cluster#
Run the below comannds to install the GKE components.
1./google-cloud-sdk/bin/gcloud components install beta
2./google-cloud-sdk/bin/gcloud components install kubectl
3./google-cloud-sdk/bin/gcloud components update
Run the below command to create a GKE cluster.
1./google-cloud-sdk/bin/gcloud beta container --project <Google-Project-ID> clusters create <GKE-Cluster-Name> --zone us-west1-a --release-channel "regular" --machine-type "n1-standard-4" --accelerator "type=nvidia-tesla-t4,count=1" --image-type "UBUNTU_CONTAINERD" --disk-type "pd-standard" --disk-size "1000" --no-enable-intra-node-visibility --metadata disable-legacy-endpoints=true --max-pods-per-node "110" --num-nodes "1" --logging=SYSTEM,WORKLOAD --monitoring=SYSTEM --enable-ip-alias --no-enable-intra-node-visibility --default-max-pods-per-node "110" --no-enable-master-authorized-networks --tags=nvidia-ingress-all
Note
<Google-Project-ID>: You will find the Project ID within the Google console dashboard Settings and update accordingly.
If the network name is not “default” then get the network information from the console and append the below value with the appropriate network and subnetwork name.
1--network "<Google Kubernetes Network Name>" --subnetwork "<Google Kubernetes SubNetwork Name>"
2
3Example:
4
5--network "projects/<GKE-Project-ID>/global/networks/<GKE-Network-Name>" --subnetwork "projects/<GKE-Project-ID>/regions/us-west1/subnetworks/<GKE-Network-Name>"
Run the below command to get the kubeconfig credentials to the local system.
1$ export USE_GKE_GCLOUD_AUTH_PLUGIN=True
2
3./google-cloud-sdk/bin/gcloud container clusters get-credentials <GKE-Cluster-Name> --zone us-west1-a
Run the below command to verify the node information
kubectl get nodes -o wide
Example output result
1NAME STATUS ROLES AGE VERSION INTERNAL-IP EXTERNAL-IP OS-IMAGE KERNEL-VERSION CONTAINER-RUNTIME
2gke-<GKE-Cluster-Name>-default-pool-db9e3df9-r0jf Ready <none> 5m15s v1.25.6 192.168.50.108 13.57.187.63 Ubuntu 20.04.6 LTS 5.15.0-1033-gke containerd://1.6.12
Create a Resources to Install the GPU Operator on GKE#
Create a resource quota file with the below command.
1cat <<EOF | tee resourcequota.yaml
2apiVersion: v1
3kind: ResourceQuota
4metadata:
5name: gpu-operator-quota
6namespace: gpu-operator
7spec:
8hard:
9 pods: 100
10scopeSelector:
11 matchExpressions:
12 - operator: In
13 scopeName: PriorityClass
14 values:
15 - system-node-critical
16 - system-cluster-critical
17EOF
Run the below commands to create a namespace and resource quota to the namespace on GKE cluster.
1./google-cloud-sdk/bin/kubectl create ns gpu-operator
2
3./google-cloud-sdk/bin/kubectl apply -f resourcequota.yaml
4
5./google-cloud-sdk/bin/kubectl get ResourceQuota -n gpu-operator
Example output result:
1NAME AGE REQUEST LIMIT
2gke-resource-quotas 24s count/ingresses.extensions: 0/100, count/ingresses.networking.k8s.io: 0/100, count/jobs.batch: 0/5k, pods: 0/1500, services: 0/500
3gpu-operator-quota 21s pods: 0/100
For more information, please refer to GKE’s quotas and limits overview
Verify the default Pod Security Policies on GKE with below command.
./google-cloud-sdk/bin/kubectl get psp
Example Output result:
1Warning: policy/v1beta1 PodSecurityPolicy is deprecated in v1.21+, unavailable in v1.25+
2NAME PRIV CAPS SELINUX RUNASUSER FSGROUP SUPGROUP READONLYROOTFS VOLUMES
3gce.gke-metrics-agent false RunAsAny RunAsAny RunAsAny RunAsAny false hostPath,secret,configMap
Deploy GPU Operator#
Now that the cluster and appropriate resources are created, the NVIDIA GPU Operator can be installed
Important
The commands below serve as an example and will be similar, albeit slightly different, to the latest version of the GPU Operator. Please refer to the latest GPU Operator release notes for more information.
First we will access our NGC API Key.
Log into your NGC account and generate a new API Key or locate your existing API key. Please refer to the Accessing NGC section of the Appendix.
Generate an API key for accessing the catalog
Next you must generate an API Key that will give you access to the NGC Catalog.
Navigate to the user account icon in the top right corner and select Setup.
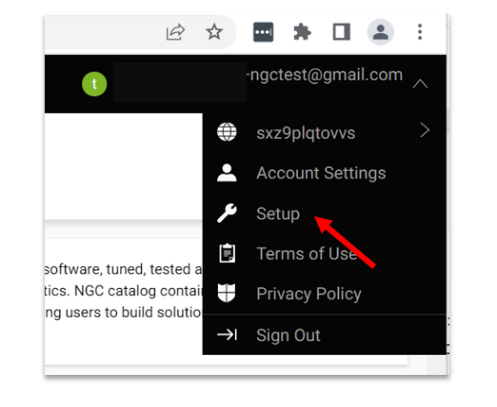
Select Get API key to open the Setup > API Key page.
Select Generate API Key to generate your API key.
Select Confirm to generate the key, and copy it from the bottom of the page. NGC does not save your key, so store it in a secure place.

Note
Generating a new API Key invalidates the previously generated key.
Add the Helm repo and update with the below commands.
1helm repo add nvidia https://helm.ngc.nvidia.com/nvaie --username='$oauthtoken' --password=<YOUR API KEY>
2helm repo update
Create a NGC Secret with your NGC API key on “gpu-operator” namespace as per below.
1./google-cloud-sdk/bin/kubectl create secret docker-registry ngc-secret \
2--docker-server=nvcr.io/nvaie --docker-username=\$oauthtoken \
3--docker-password=<NGC-API-KEY> \
4--docker-email=<NGC-email> -n gpu-operator
Create an empty gridd.conf file, then create a configmap with NVIDIA vGPU Licence token file as per below
./google-cloud-sdk/bin/kubectl create configmap licensing-config -n gpu-operator --from-file=./client_configuration_token.tok --from-file=./gridd.conf
Note
The configmap will look for the file client_configuration_token.tok, if your token is in a different form such as client_configuration_token_date_xx_xx.tok, then please run the below command:
mv client_configuration_token_date_xx_xx.tok client_configuration_token.tok
Install the GPU Operator from NGC Catalog with License token and driver repository.
helm install gpu-operator nvidia/gpu-operator-3-0 --version 22.9.1 --set driver.repository=nvcr.io/nvaie,driver.licensingConfig.configMapName=licensing-config,psp.enabled=true --namespace gpu-operator
Important
Ensure that you have the correct role as either a Kubernetes Engine Admin or Kubernetes Engine Cluster Admin in order to install the GPU Operator. Please refer to Create IAM policies if you lack the required permissions.
Once installed, please wait at least 5 minutes and verify that all the pods are either running or completed as per below.
1./google-cloud-sdk/bin/kubectl get pods -n gpu-operator
2NAME READY STATUS RESTARTS AGE
3gpu-feature-discovery-fzgv9 1/1 Running 0 6m1s
4gpu-operator-69f476f875-w4hwr 1/1 Running 0 6m29s
5gpu-operator-node-feature-discovery-master-84c7c7c6cf-hxlk4 1/1 Running 0 6m29s
6gpu-operator-node-feature-discovery-worker-86bbx 1/1 Running 0 6m29s
7nvidia-container-toolkit-daemonset-c7k5p 1/1 Running 0 6m
8nvidia-cuda-validator-qjcsf 0/1 Completed 0 59s
9nvidia-dcgm-exporter-9tggn 1/1 Running 0 6m
10nvidia-device-plugin-daemonset-tpx9z 1/1 Running 0 6m
11nvidia-device-plugin-validator-gz85d 0/1 Completed 0 44s
12nvidia-driver-daemonset-jwzx8 1/1 Running 0 6m9s
13nvidia-operator-validator-qj57n 1/1 Running 0 6m
Verify the GPU Operator Installation#
Verify the NVIDIA GPU Driver loaded with below command.
./google-cloud-sdk/bin/kubectl exec -it nvidia-driver-daemonset-jwzx8 -n gpu-operator -- nvidia-smi
1Defaulted container "nvidia-driver-ctr" out of: nvidia-driver-ctr, k8s-driver-manager (init)
2Tue Feb 14 22:24:31 2023
3+-----------------------------------------------------------------------------+
4| NVIDIA-SMI 520.60.13 Driver Version: 520.60.13 CUDA Version: 12.0 |
5|-------------------------------+----------------------+----------------------+
6| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
7| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
8| | | MIG M. |
9|===============================+======================+======================|
10| 0 Tesla T4 On | 00000000:00:04.0 Off | 0 |
11| N/A 51C P8 17W / 70W | 0MiB / 15360MiB | 0% Default |
12| | | N/A |
13+-------------------------------+----------------------+----------------------+
14
15+-----------------------------------------------------------------------------+
16| Processes: |
17| GPU GI CI PID Type Process name GPU Memory |
18| ID ID Usage |
19|=============================================================================|
20| No running processes found |
21+-----------------------------------------------------------------------------+
Note
nvidia-driver-daemonset-xxxxx will be different within your own environment for the above command to verify the NVIDIA vGPU Driver.
Verify the NVIDIA vGPU license information with below command
./google-cloud-sdk/bin/kubectl exec -it nvidia-driver-daemonset-jwzx8 -n gpu-operator-resources -- nvidia-smi -q
Run Sample NVIDIA AI Enterprise Container#
Important
Container images will be similar, albeit slightly different when using the latest image. Please refer to Pulling and Running NVIDIA AI Enterprise Containers to find the latest images on NGC.
Create a docker-regirty secret. This will be used in a custom yaml to pull containers from the NGC Catalog.
1./google-cloud-sdk/bin/kubectl create secret docker-registry regcred --docker-server=nvcr.io/nvaie --docker-username=\$oauthtoken --docker-password=<YOUR_NGC_KEY> --docker-email=<your_email_id> -n default
Create a custom yaml file to deploy an NVIDIA AI Enterprise Container and run sample training code.
nano pytoch-mnist.yaml
Paste the below contents into the file and save
1---
2apiVersion: apps/v1
3kind: Deployment
4metadata:
5 name: pytorch-mnist
6 labels:
7 app: pytorch-mnist
8spec:
9 replicas: 1
10 selector:
11 matchLabels:
12 app: pytorch-mnist
13template:
14 metadata:
15 labels:
16 app: pytorch-mnist
17 spec:
18 containers:
19 - name: pytorch-container
20 image: nvcr.io/nvaie/pytorch-2-0:22.02-nvaie-2.0-py3
21 command:
22 - python
23 args:
24 - /workspace/examples/upstream/mnist/main.py
25 resources:
26 requests:
27 nvidia.com/gpu: 1
28 limits:
29 nvidia.com/gpu: 1
30 imagePullSecrets:
31 - name: regcred
Check the status of the pod.
1./google-cloud-sdk/bin/kubectl get pods
View the output of the sample mnist training job.
1./google-cloud-sdk/bin/kubectl logs -l app=pytorch-mnist
The output will look similar to this.
1~$ ./google-cloud-sdk/bin/kubectl logs -l app=pytorch-mnist
2Train Epoch: 7 [55680/60000 (93%)] Loss: 0.040756
3Train Epoch: 7 [56320/60000 (94%)] Loss: 0.028230
4Train Epoch: 7 [56960/60000 (95%)] Loss: 0.019917
5Train Epoch: 7 [57600/60000 (96%)] Loss: 0.005957
6Train Epoch: 7 [58240/60000 (97%)] Loss: 0.003768
7Train Epoch: 7 [58880/60000 (98%)] Loss: 0.277371
8Train Epoch: 7 [59520/60000 (99%)] Loss: 0.115487
9
10
11Test set: Average loss: 0.0270, Accuracy: 9913/10000 (99%)
Delete the GKE Cluster#
Run the below command to delete the GKE cluster
./google-cloud-sdk/bin/gcloud beta container clusters delete <cluster-name> --zone <zone-name>