cuTensorNet functions#
Handle management API#
cutensornetCreate#
-
cutensornetStatus_t cutensornetCreate(cutensornetHandle_t *handle)#
Initializes the cuTensorNet library.
The device associated with a particular cuTensorNet handle is assumed to remain unchanged after the cutensornetCreate() call. In order for the cuTensorNet library to use a different device, the application must set the new device to be used by calling cudaSetDevice() and then create another cuTensorNet handle, which will be associated with the new device, by calling cutensornetCreate().
Remark
blocking, no reentrant, and thread-safe
Warning
If no CUDA capable device was detected, the created handle would be marked CPU-only, and only a subset of cuTensorNet APIs would able to execute.
- Parameters:
handle – [out] Pointer to cutensornetHandle_t
- Returns:
CUTENSORNET_STATUS_SUCCESS on success and an error code otherwise
cutensornetDestroy#
-
cutensornetStatus_t cutensornetDestroy(cutensornetHandle_t handle)#
Destroys the cuTensorNet library handle.
This function releases resources used by the cuTensorNet library handle. This function is the last call with a particular handle to the cuTensorNet library. Calling any cuTensorNet function which uses cutensornetHandle_t after cutensornetDestroy() will return an error.
- Parameters:
handle – [inout] Opaque handle holding cuTensorNet’s library context.
Network Creation API#
Note
Since cuTensorNet v2.9.0, the network-centric API (cutensornetCreateNetwork and the family of functions prefixed with cutensornetNetwork*) is the preferred way to define, prepare, and execute contractions and gradients. The legacy descriptor/plan-based APIs remain available for backward compatibility but are deprecated.
cutensornetCreateNetworkDescriptor#
- cutensornetStatus_t cutensornetCreateNetworkDescriptor(
- const cutensornetHandle_t handle,
- int32_t numInputs,
- const int32_t numModesIn[],
- const int64_t *const extentsIn[],
- const int64_t *const stridesIn[],
- const int32_t *const modesIn[],
- const cutensornetTensorQualifiers_t qualifiersIn[],
- int32_t numModesOut,
- const int64_t extentsOut[],
- const int64_t stridesOut[],
- const int32_t modesOut[],
- cudaDataType_t dataType,
- cutensornetComputeType_t computeType,
- cutensornetNetworkDescriptor_t *networkDesc
DEPRECATED: Initializes a cutensornetNetworkDescriptor_t, describing the connectivity (i.e., network topology) between the tensors.
Supported data-type combinations are:
Data type
Compute type
Tensor Core
CUDA_R_16F
CUTENSORNET_COMPUTE_32F
Volta+
CUDA_R_16BF
CUTENSORNET_COMPUTE_32F
Ampere+
CUDA_R_32F
CUTENSORNET_COMPUTE_32F
No
CUDA_R_32F
CUTENSORNET_COMPUTE_TF32
Ampere+
CUDA_R_32F
CUTENSORNET_COMPUTE_3XTF32
Ampere+
CUDA_R_32F
CUTENSORNET_COMPUTE_16BF
Ampere+
CUDA_R_32F
CUTENSORNET_COMPUTE_16F
Volta+
CUDA_R_64F
CUTENSORNET_COMPUTE_64F
Ampere+
CUDA_R_64F
CUTENSORNET_COMPUTE_32F
No
CUDA_C_32F
CUTENSORNET_COMPUTE_32F
No
CUDA_C_32F
CUTENSORNET_COMPUTE_TF32
Ampere+
CUDA_C_32F
CUTENSORNET_COMPUTE_3XTF32
Ampere+
CUDA_C_64F
CUTENSORNET_COMPUTE_64F
Ampere+
CUDA_C_64F
CUTENSORNET_COMPUTE_32F
No
Note
If
stridesIn(stridesOut) is set to 0 (NULL), it means the input tensors (output tensor) are in the Fortran (column-major) layout.Note
numModesOutcan be set to-1for cuTensorNet to infer the output modes based on the input modes, or to0to perform a full reduction.Note
If
qualifiersInis set to 0 (NULL), cuTensorNet will use the defaults in cutensornetTensorQualifiers_t .Warning
This function allocates data on the heap; hence, it is critical that cutensornetDestroyNetworkDescriptor() is called once
networkDescis no longer required.Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
numInputs – [in] Number of input tensors.
numModesIn – [in] Array of size
numInputs;numModesIn[i]denotes the number of modes available in the i-th tensor.extentsIn – [in] Array of size
numInputs;extentsIn[i]hasnumModesIn[i]many entries withextentsIn[i][j](j<numModesIn[i]) corresponding to the extent of the j-th mode of tensori.stridesIn – [in] Array of size
numInputs;stridesIn[i]hasnumModesIn[i]many entries withstridesIn[i][j](j<numModesIn[i]) corresponding to the linearized offset — in physical memory — between two logically-neighboring elements w.r.t the j-th mode of tensori.modesIn – [in] Array of size
numInputs;modesIn[i]hasnumModesIn[i]many entries — each entry corresponds to a mode. Each mode that does not appear in the input tensor is implicitly contracted.qualifiersIn – [in] Array of size
numInputs;qualifiersIn[i]denotes the qualifiers of i-th input tensor. Refer to cutensornetTensorQualifiers_tnumModesOut – [in] number of modes of the output tensor. On entry, if this value is
-1and the output modes are not provided, the network will infer the output modes. If this value is0, the network is force reduced.extentsOut – [in] Array of size
numModesOut;extentsOut[j](j<numModesOut) corresponding to the extent of the j-th mode of the output tensor.stridesOut – [in] Array of size
numModesOut;stridesOut[j](j<numModesOut) corresponding to the linearized offset — in physical memory — between two logically-neighboring elements w.r.t the j-th mode of the output tensor.modesOut – [in] Array of size
numModesOut;modesOut[j]denotes the j-th mode of the output tensor. output tensor.dataType – [in] Denotes the data type for all input an output tensors.
computeType – [in] Denotes the compute type used throughout the computation.
networkDesc – [out] Pointer to a cutensornetNetworkDescriptor_t.
cutensornetDestroyNetworkDescriptor#
- cutensornetStatus_t cutensornetDestroyNetworkDescriptor(
- cutensornetNetworkDescriptor_t networkDesc
DEPRECATED: Frees all the memory associated with the network descriptor.
- Parameters:
networkDesc – [inout] Opaque handle to a tensor network descriptor.
cutensornetCreateNetwork#
- cutensornetStatus_t cutensornetCreateNetwork(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t *networkDesc
Initializes an empty cutensornetNetworkDescriptor_t.
The input tensors need to be added to the network using cutensornetNetworkAppendTensor(). The output tensor needs to be set for the network using cutensornetNetworkSetOutputTensor(). If not set, the network will infer the output modes/extents and use default strides (refer to cutensornetCreateTensorDescriptor()). The network connectivity (i.e., network topology) between the tensors is auto inferred. The data type of the network is inferred from the appended tensors. All the input tensors, and the output tensor, must have the same data type. The compute type need to be set using cutensornetNetworkSetAttribute() using the atribute CUTENSORNET_NETWORK_COMPUTE_TYPE. If not set, the default compute type is used per the table below.
Supported data-type combinations are shown in the table below. The default compute-type is used for the corresponding data-type when the former is not explicitly set. All the input, output, adjoint, and gradient tensors should have the same data-type, an error is returned otherwise.
Data type
Compute type
Default
Uses Tensor Core
CUDA_R_16F
CUTENSORNET_COMPUTE_32F
Yes
Volta+
CUDA_R_16BF
CUTENSORNET_COMPUTE_32F
Yes
Ampere+
CUDA_R_32F
CUTENSORNET_COMPUTE_32F
Yes
No
CUDA_R_32F
CUTENSORNET_COMPUTE_TF32
No
Ampere+
CUDA_R_32F
CUTENSORNET_COMPUTE_3XTF32
No
Ampere+
CUDA_R_32F
CUTENSORNET_COMPUTE_16BF
No
Ampere+
CUDA_R_32F
CUTENSORNET_COMPUTE_16F
No
Volta+
CUDA_R_64F
CUTENSORNET_COMPUTE_64F
Yes
Ampere+
CUDA_R_64F
CUTENSORNET_COMPUTE_32F
No
No
CUDA_C_32F
CUTENSORNET_COMPUTE_32F
Yes
No
CUDA_C_32F
CUTENSORNET_COMPUTE_TF32
No
Ampere+
CUDA_C_32F
CUTENSORNET_COMPUTE_3XTF32
No
Ampere+
CUDA_C_64F
CUTENSORNET_COMPUTE_64F
Yes
Ampere+
CUDA_C_64F
CUTENSORNET_COMPUTE_32F
No
No
Warning
This function allocates data on the heap; hence, it is critical that cutensornetDestroyNetwork() is called once
networkDescis no longer required.Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [out] Pointer to a cutensornetNetworkDescriptor_t.
cutensornetDestroyNetwork#
- cutensornetStatus_t cutensornetDestroyNetwork(
- cutensornetNetworkDescriptor_t networkDesc
Frees all the memory associated with the network.
- Parameters:
networkDesc – [inout] Opaque handle to a tensor network descriptor.
cutensornetNetworkAppendTensor#
- cutensornetStatus_t cutensornetNetworkAppendTensor(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t networkDesc,
- int32_t numModes,
- const int64_t extents[],
- const int32_t modeLabels[],
- const cutensornetTensorQualifiers_t *const qualifiers,
- cudaDataType_t dataType,
- int64_t *tensorId
Appends an input tensor to the network.
Note
If
qualifiersis set to 0 (NULL), cuTensorNet will use the defaults in cutensornetTensorQualifiers_t.Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] Opaque handle to a tensor network descriptor, created using cutensornetCreateNetwork().
numModes – [in] The number of modes of the tensor.
extents – [in] Array of size
numModes;extents[j]corresponding to the extent of the j-th mode of the tensor.modeLabels – [in] Array of size
numModes;modeLabels[j]denotes the label of j-th mode of the tensor.qualifiers – [in] Denotes the qualifiers of the input tensor in relation to
networkDesc. Refer to cutensornetTensorQualifiers_tdataType – [in] Denotes the data type of the tensor.
tensorId – [out] On return, if not NULL, will hold the tensor identifier within the
networkDesc(may be not sequential, but is unique).
cutensornetNetworkSetOutputTensor#
- cutensornetStatus_t cutensornetNetworkSetOutputTensor(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t networkDesc,
- int32_t numModes,
- const int32_t modeLabels[],
- cudaDataType_t dataType
Sets the output tensor of the network If this function is not called on the network, the network output tensor metadata will be inferred (using default values where needed).
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] Opaque handle to a tensor network descriptor, created using cutensornetCreateNetwork().
numModes – [in] The number of modes of the tensor. If this value is
0, the network is force reduced.modeLabels – [in] Array of size
numModes;modeLabels[j]denotes the label of j-th mode of the tensor.dataType – [in] Denotes the data type of the output tensor.
cutensornetNetworkSetInputTensorMemory#
- cutensornetStatus_t cutensornetNetworkSetInputTensorMemory(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t networkDesc,
- int64_t tensorId,
- const void *const buffer,
- const int64_t strides[]
Provide memory buffer and strides corresponding to an input tensor for the network to be used for data reading.
Note
If
stridesis set toNULL, it means the tensor is in the Fortran (column-major) layout.Note
Data pointers are recommended to be at least 256-byte aligned for best performance.
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] The network descriptor.
tensorId – [in] The tensorId as returned by cutensornetNetworkAppendTensor().
buffer – [in] Pointer to memory buffer in device memory.
strides – [in] Array of size the number of modes of the corresponding tensor;
strides[j]corresponding to the linearized offset — in physical memory — between two logically-neighboring elements w.r.t the j-th mode of the tensor.
cutensornetNetworkSetOutputTensorMemory#
- cutensornetStatus_t cutensornetNetworkSetOutputTensorMemory(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t networkDesc,
- void *const buffer,
- const int64_t strides[]
Provide memory buffer and strides corresponding to the output tensor of the network to be used for data writing.
Note
If
stridesis set toNULL, it means the tensor is in the Fortran (column-major) layout.Note
Data pointers are recommended to be at least 256-byte aligned for best performance.
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] The network descriptor.
buffer – [in] Pointer to memory buffer in device memory.
strides – [in] Array of size the number of modes of the corresponding tensor;
strides[j]corresponding to the linearized offset — in physical memory — between two logically-neighboring elements w.r.t the j-th mode of the tensor.
cutensornetNetworkSetAdjointTensorMemory#
- cutensornetStatus_t cutensornetNetworkSetAdjointTensorMemory(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t networkDesc,
- const void *const buffer,
- const int64_t strides[]
Provide memory buffer and strides for the adjoint/activation tensor of the network to be used for data reading.
Note
If
stridesis set toNULL, it means the tensor is in the Fortran (column-major) layout.Note
Data pointers are recommended to be at least 256-byte aligned for best performance.
Note
If this function was not called, the adjoint/activation will be assumed all ones upon gradient computation call.
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] The network descriptor.
buffer – [in] Pointer to memory bugger in device memory.
strides – [in] Array of size the number of modes of the corresponding tensor;
strides[j]corresponding to the linearized offset — in physical memory — between two logically-neighboring elements w.r.t the j-th mode of the tensor.
cutensornetNetworkSetGradientTensorMemory#
- cutensornetStatus_t cutensornetNetworkSetGradientTensorMemory(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t networkDesc,
- int64_t correspondingTensorId,
- void *const buffer,
- const int64_t strides[]
Provide memory buffer and strides of the gradient corresponding to tensorId of the network to be used for data writing.
Note
If
stridesis set toNULL, it means the tensor is in the Fortran (column-major) layout.Note
Data pointers are recommended to be at least 256-byte aligned for best performance.
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] The network descriptor.
correspondingTensorId – [in] The tensorId as returned by cutensornetNetworkAppendTensor() for the tensor whose gradient is to be computed.
buffer – [in] Pointer to memory bugger in device memory.
strides – [in] Array of size the number of modes of the corresponding tensor;
strides[j]corresponding to the linearized offset — in physical memory — between two logically-neighboring elements w.r.t the j-th mode of the tensor.
cutensornetNetworkGetAttribute#
- cutensornetStatus_t cutensornetNetworkGetAttribute(
- const cutensornetHandle_t handle,
- const cutensornetNetworkDescriptor_t networkDesc,
- cutensornetNetworkAttributes_t attr,
- void *buffer,
- size_t sizeInBytes
Gets attributes of networkDescriptor.
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [in] Opaque structure that is accessed.
attr – [in] Specifies the attribute that is requested.
buffer – [out] On return, this buffer (of size
sizeInBytes) holds the value that corresponds toattrwithinnetworkDesc.sizeInBytes – [in] Size of
buffer(in bytes).
cutensornetNetworkSetAttribute#
- cutensornetStatus_t cutensornetNetworkSetAttribute(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t networkDesc,
- cutensornetNetworkAttributes_t attr,
- const void *const buffer,
- size_t sizeInBytes
Sets attributes of networkDescriptor.
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] Opaque structure that is accessed.
attr – [in] Specifies the attribute that is requested.
buffer – [in] This buffer (of size
sizeInBytes) determines the value to whichattrwill be set.sizeInBytes – [in] Size of
buffer(in bytes).
cutensornetGetOutputTensorDetails#
- cutensornetStatus_t cutensornetGetOutputTensorDetails(
- const cutensornetHandle_t handle,
- const cutensornetNetworkDescriptor_t networkDesc,
- int32_t *numModes,
- size_t *dataSize,
- int32_t *modeLabels,
- int64_t *extents,
- int64_t *strides
DEPRECATED: Gets the number of output modes, data size, modes, extents, and strides of the output tensor.
If all information regarding the output tensor is needed by the user, this function should be called twice (the first time to retrieve
numModesfor allocating memory, and the second to retrievemodesLabels,extents, andstrides).Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [in] Pointer to a cutensornetNetworkDescriptor_t.
numModes – [out] on return, holds the number of modes of the output tensor. Cannot be null.
dataSize – [out] if not null on return, holds the size (in bytes) of the memory needed for the output tensor. Optionally, can be null.
modeLabels – [out] if not null on return, holds the mode labels of the output tensor. Optionally, can be null.
extents – [out] if not null on return, holds the extents of the output tensor. Optionally, can be null.
strides – [out] if not null on return, holds the strides of the output tensor. Optionally, can be null.
cutensornetGetOutputTensorDescriptor#
- cutensornetStatus_t cutensornetGetOutputTensorDescriptor(
- const cutensornetHandle_t handle,
- const cutensornetNetworkDescriptor_t networkDesc,
- cutensornetTensorDescriptor_t *outputTensorDesc
Creates a cutensornetTensorDescriptor_t representing the output tensor of the network.
This function will create a descriptor pointed to by
outputTensorDesc. The user is responsible for calling cutensornetDestroyTensorDescriptor to destroy the descriptor.Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [in] Pointer to a cutensornetNetworkDescriptor_t.
outputTensorDesc – [out] an opaque cutensornetTensorDescriptor_t struct. Cannot be null. On return, a new cutensornetTensorDescriptor_t holds the meta-data of the
networkDescoutput tensor.
Tensor descriptor API#
cutensornetCreateTensorDescriptor#
- cutensornetStatus_t cutensornetCreateTensorDescriptor(
- const cutensornetHandle_t handle,
- int32_t numModes,
- const int64_t extents[],
- const int64_t strides[],
- const int32_t modeLabels[],
- cudaDataType_t dataType,
- cutensornetTensorDescriptor_t *tensorDesc
Initializes a cutensornetTensorDescriptor_t, describing the information of a tensor.
Note that this function allocates data on the heap; hence, it is critical that cutensornetDestroyTensorDescriptor() is called once
tensorDescis no longer required.Note
If
stridesis set toNULL, it means the tensor is in the Fortran (column-major) layout.Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
numModes – [in] The number of modes of the tensor.
extents – [in] Array of size
numModes;extents[j]corresponding to the extent of the j-th mode of the tensor.strides – [in] Array of size
numModes;strides[j]corresponding to the linearized offset — in physical memory — between two logically-neighboring elements w.r.t the j-th mode of the tensor.modeLabels – [in] Array of size
numModes;modeLabels[j]denotes the label of j-th mode of the tensor.dataType – [in] Denotes the data type for the tensor.
tensorDesc – [out] Pointer to a cutensornetTensorDescriptor_t.
cutensornetGetTensorDetails#
- cutensornetStatus_t cutensornetGetTensorDetails(
- const cutensornetHandle_t handle,
- const cutensornetTensorDescriptor_t tensorDesc,
- int32_t *numModes,
- size_t *dataSize,
- int32_t *modeLabels,
- int64_t *extents,
- int64_t *strides
Gets the number of output modes, data size, mode labels, extents, and strides of a tensor.
If all information regarding the tensor is needed by the user, this function should be called twice (the first time to retrieve
numModesfor allocating memory, and the second to retrievemodeLabels,extents, andstrides).Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
tensorDesc – [in] Opaque handle to a tensor descriptor.
numModes – [out] On return, holds the number of modes of the tensor. Cannot be null.
dataSize – [out] If not null on return, holds the size (in bytes) of the memory needed for the tensor. Optionally, can be null.
modeLabels – [out] If not null on return, holds the mode labels of the tensor. Optionally, can be null.
extents – [out] If not null on return, holds the extents of the tensor. Optionally, can be null.
strides – [out] If not null on return, holds the strides of the tensor. Optionally, can be null.
cutensornetDestroyTensorDescriptor#
- cutensornetStatus_t cutensornetDestroyTensorDescriptor(
- cutensornetTensorDescriptor_t tensorDesc
Frees all the memory associated with the tensor descriptor.
- Parameters:
tensorDesc – [inout] Opaque handle to a tensor descriptor.
Contraction optimizer API#
cutensornetCreateContractionOptimizerConfig#
- cutensornetStatus_t cutensornetCreateContractionOptimizerConfig(
- const cutensornetHandle_t handle,
- cutensornetContractionOptimizerConfig_t *optimizerConfig
Sets up the required hyper-optimization parameters for the contraction order solver (see cutensornetContractionOptimize())
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
This function allocates data on the heap; hence, it is critical that cutensornetDestroyContractionOptimizerConfig() is called once
optimizerConfigis no longer required.- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
optimizerConfig – [out] This data structure holds all information about the user-requested hyper-optimization parameters.
cutensornetDestroyContractionOptimizerConfig#
- cutensornetStatus_t cutensornetDestroyContractionOptimizerConfig(
- cutensornetContractionOptimizerConfig_t optimizerConfig
Frees all the memory associated with
optimizerConfig.- Parameters:
optimizerConfig – [inout] Opaque structure.
cutensornetContractionOptimizerConfigGetAttribute#
- cutensornetStatus_t cutensornetContractionOptimizerConfigGetAttribute(
- const cutensornetHandle_t handle,
- const cutensornetContractionOptimizerConfig_t optimizerConfig,
- cutensornetContractionOptimizerConfigAttributes_t attr,
- void *buffer,
- size_t sizeInBytes
Gets attributes of
optimizerConfig.Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
optimizerConfig – [in] Opaque structure that is accessed.
attr – [in] Specifies the attribute that is requested.
buffer – [out] On return, this buffer (of size
sizeInBytes) holds the value that corresponds toattrwithinoptimizerConfig.sizeInBytes – [in] Size of
buffer(in bytes).
cutensornetContractionOptimizerConfigSetAttribute#
- cutensornetStatus_t cutensornetContractionOptimizerConfigSetAttribute(
- const cutensornetHandle_t handle,
- cutensornetContractionOptimizerConfig_t optimizerConfig,
- cutensornetContractionOptimizerConfigAttributes_t attr,
- const void *buffer,
- size_t sizeInBytes
Sets attributes of
optimizerConfig.Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
optimizerConfig – [inout] Opaque structure that is accessed.
attr – [in] Specifies the attribute that is requested.
buffer – [in] This buffer (of size
sizeInBytes) determines the value to whichattrwill be set.sizeInBytes – [in] Size of
buffer(in bytes).
cutensornetCreateContractionOptimizerInfo#
- cutensornetStatus_t cutensornetCreateContractionOptimizerInfo(
- const cutensornetHandle_t handle,
- const cutensornetNetworkDescriptor_t networkDesc,
- cutensornetContractionOptimizerInfo_t *optimizerInfo
Allocates resources for
optimizerInfo.Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
This function allocates data on the heap; hence, it is critical that cutensornetDestroyContractionOptimizerInfo() is called once
optimizerInfois no longer required.- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [in] Describes the tensor network (i.e., its tensors and their connectivity) for which
optimizerInfois created.optimizerInfo – [out] Pointer to cutensornetContractionOptimizerInfo_t.
cutensornetDestroyContractionOptimizerInfo#
- cutensornetStatus_t cutensornetDestroyContractionOptimizerInfo(
- cutensornetContractionOptimizerInfo_t optimizerInfo
Frees all the memory associated with
optimizerInfo.- Parameters:
optimizerInfo – [inout] Opaque structure.
cutensornetContractionOptimize#
- cutensornetStatus_t cutensornetContractionOptimize(
- const cutensornetHandle_t handle,
- const cutensornetNetworkDescriptor_t networkDesc,
- const cutensornetContractionOptimizerConfig_t optimizerConfig,
- uint64_t workspaceSizeConstraint,
- cutensornetContractionOptimizerInfo_t optimizerInfo
Computes an “optimized” contraction order as well as slicing info (for more information see Overview section) for a given tensor network such that the total time to solution is minimized while adhering to the user-provided memory constraint.
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] Describes the topology of the tensor network (i.e., all tensors, their connectivity and modes). Will be updated with
optimizerInfodata.optimizerConfig – [in] Holds all hyper-optimization parameters that govern the search for an “optimal” contraction order.
workspaceSizeConstraint – [in] Maximal device memory that will be provided by the user (i.e., cuTensorNet has to find a viable path/slicing solution within this user-defined constraint).
optimizerInfo – [inout] On return, this object will hold all necessary information about the optimized path and the related slicing information.
optimizerInfowill hold information including (see cutensornetContractionOptimizerInfoAttributes_t):Total number of slices.
Total number of sliced modes.
Information about the sliced modes (i.e., the IDs of the sliced modes (see
modesInw.r.t. cutensornetCreateNetworkDescriptor()) as well as their extents (see Overview section for additional documentation).Optimized path.
FLOP count.
Total number of elements in the largest intermediate tensor.
The mode labels for all intermediate tensors.
The estimated runtime and “effective” flops.
cutensornetNetworkSetOptimizerInfo#
- cutensornetStatus_t cutensornetNetworkSetOptimizerInfo(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t networkDesc,
- const cutensornetContractionOptimizerInfo_t optimizerInfo
Provides an optimized contraction path as well as slicing info to the tensor network.
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] Describes the topology of the tensor network (i.e., all tensors, their connectivity, and modes).
optimizerInfo – [in] Pointer to cutensornetContractionOptimizerInfo_t holding path and slicing configs.
cutensornetContractionOptimizerInfoGetAttribute#
- cutensornetStatus_t cutensornetContractionOptimizerInfoGetAttribute(
- const cutensornetHandle_t handle,
- const cutensornetContractionOptimizerInfo_t optimizerInfo,
- cutensornetContractionOptimizerInfoAttributes_t attr,
- void *buffer,
- size_t sizeInBytes
Gets attributes of
optimizerInfo.Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
optimizerInfo – [in] Opaque structure that is accessed.
attr – [in] Specifies the attribute that is requested.
buffer – [out] On return, this buffer (of size
sizeInBytes) holds the value that corresponds toattrwithinoptimizeInfo.sizeInBytes – [in] Size of
buffer(in bytes).
cutensornetContractionOptimizerInfoSetAttribute#
- cutensornetStatus_t cutensornetContractionOptimizerInfoSetAttribute(
- const cutensornetHandle_t handle,
- cutensornetContractionOptimizerInfo_t optimizerInfo,
- cutensornetContractionOptimizerInfoAttributes_t attr,
- const void *buffer,
- size_t sizeInBytes
Sets attributes of optimizerInfo.
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
optimizerInfo – [inout] Opaque structure that is accessed.
attr – [in] Specifies the attribute that is requested.
buffer – [in] This buffer (of size
sizeInBytes) determines the value to whichattrwill be set.sizeInBytes – [in] Size of
buffer(in bytes).
cutensornetContractionOptimizerInfoGetPackedSize#
- cutensornetStatus_t cutensornetContractionOptimizerInfoGetPackedSize(
- const cutensornetHandle_t handle,
- const cutensornetContractionOptimizerInfo_t optimizerInfo,
- size_t *sizeInBytes
Gets the packed size of the
optimizerInfoobject.Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
optimizerInfo – [in] Opaque structure of type cutensornetContractionOptimizerInfo_t.
sizeInBytes – [out] The packed size (in bytes).
cutensornetContractionOptimizerInfoPackData#
- cutensornetStatus_t cutensornetContractionOptimizerInfoPackData(
- const cutensornetHandle_t handle,
- const cutensornetContractionOptimizerInfo_t optimizerInfo,
- void *buffer,
- size_t sizeInBytes
Packs the
optimizerInfoobject into the provided buffer.Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
optimizerInfo – [in] Opaque structure of type cutensornetContractionOptimizerInfo_t.
buffer – [out] On return, this buffer holds the contents of optimizerInfo in packed form.
sizeInBytes – [in] The size of the buffer (in bytes).
cutensornetCreateContractionOptimizerInfoFromPackedData#
- cutensornetStatus_t cutensornetCreateContractionOptimizerInfoFromPackedData(
- const cutensornetHandle_t handle,
- const cutensornetNetworkDescriptor_t networkDesc,
- const void *buffer,
- size_t sizeInBytes,
- cutensornetContractionOptimizerInfo_t *optimizerInfo
Create an optimizerInfo object from the provided buffer.
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [in] Describes the tensor network (i.e., its tensors and their connectivity) for which
optimizerInfois created.buffer – [in] A buffer with the contents of optimizerInfo in packed form.
sizeInBytes – [in] The size of the buffer (in bytes).
optimizerInfo – [out] Pointer to cutensornetContractionOptimizerInfo_t.
cutensornetUpdateContractionOptimizerInfoFromPackedData#
- cutensornetStatus_t cutensornetUpdateContractionOptimizerInfoFromPackedData(
- const cutensornetHandle_t handle,
- const void *buffer,
- size_t sizeInBytes,
- cutensornetContractionOptimizerInfo_t optimizerInfo
Update the provided
optimizerInfoobject from the provided buffer.Note
A call to this function must be followed by a call to cutensornetNetworkSetOptimizerInfo() to update the network with the modified
optimizerInfounless the network object was created by legacy API cutensornetCreateNetworkDescriptor().Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
buffer – [in] A buffer with the contents of optimizerInfo in packed form.
sizeInBytes – [in] The size of the buffer (in bytes).
optimizerInfo – [inout] Opaque object of type cutensornetContractionOptimizerInfo_t that will be updated.
Contraction plan API#
Warning
Legacy plan-based API. Prefer the network-centric flow documented in cutensornetNetworkPrepareContraction and cutensornetNetworkContract introduced in v2.9.0. The plan-based APIs will remain for backward compatibility but are deprecated.
cutensornetCreateContractionPlan#
- cutensornetStatus_t cutensornetCreateContractionPlan(
- const cutensornetHandle_t handle,
- const cutensornetNetworkDescriptor_t networkDesc,
- const cutensornetContractionOptimizerInfo_t optimizerInfo,
- const cutensornetWorkspaceDescriptor_t workDesc,
- cutensornetContractionPlan_t *plan
DEPRECATED: Initializes a cutensornetContractionPlan_t.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
This function allocates data on the heap; hence, it is critical that cutensornetDestroyContractionPlan() is called once
planis no longer required.- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [in] Describes the tensor network (i.e., its tensors and their connectivity).
optimizerInfo – [in] Opaque structure.
workDesc – [in] Opaque structure describing the workspace. At the creation of the contraction plan, only the workspace size is needed; the pointer to the workspace memory may be left null. If a device memory handler is set,
workDesccan be set either to null (in which case the “recommended” workspace size is inferred, see CUTENSORNET_WORKSIZE_PREF_RECOMMENDED) or to a valid cutensornetWorkspaceDescriptor_t with the desired workspace size set and a null workspace pointer, see Memory Management API section.plan – [out] cuTensorNet’s contraction plan holds all the information required to perform the tensor contractions; to be precise, it initializes a
cutensorContractionPlan_tfor each tensor contraction that is required to contract the entire tensor network.
cutensornetDestroyContractionPlan#
- cutensornetStatus_t cutensornetDestroyContractionPlan( )#
DEPRECATED: Frees all resources owned by
plan.- Parameters:
plan – [inout] Opaque structure.
Network Autotune API#
cutensornetContractionAutotune#
- cutensornetStatus_t cutensornetContractionAutotune(
- const cutensornetHandle_t handle,
- cutensornetContractionPlan_t plan,
- const void *const rawDataIn[],
- void *rawDataOut,
- cutensornetWorkspaceDescriptor_t workDesc,
- const cutensornetContractionAutotunePreference_t pref,
- cudaStream_t stream
DEPRECATED: Auto-tunes the contraction plan to find the best
cutensorContractionPlan_tfor each pair-wise contraction.Note
This function is blocking due to the nature of the auto-tuning process.
Note
Input and output data pointers are recommended to be 256-byte aligned for best performance.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
plan – [inout] The plan must already be created (see cutensornetCreateContractionPlan()); the individual contraction plans will be fine-tuned.
rawDataIn – [in] Array of N pointers (N being the number of input tensors specified cutensornetCreateNetworkDescriptor());
rawDataIn[i]points to the data associated with the i-th input tensor (in device memory).rawDataOut – [out] Points to the raw data of the output tensor (in device memory).
workDesc – [in] Opaque structure describing the workspace. The provided workspace must be valid (the workspace size must be the same as or larger than both the minimum needed and the value provided at plan creation). See cutensornetCreateContractionPlan(), cutensornetWorkspaceGetMemorySize() & cutensornetWorkspaceSetMemory(). If a device memory handler is set, the
workDesccan be set to null, or the workspace pointer inworkDesccan be set to null, and the workspace size can be set either to 0 (in which case the “recommended” size is used, see CUTENSORNET_WORKSIZE_PREF_RECOMMENDED) or to a valid size. A workspace of the specified size will be drawn from the user’s mempool and released back once done.pref – [in] Controls the auto-tuning process and gives the user control over how much time is spent in this routine.
stream – [in] The CUDA stream on which the computation is performed.
cutensornetNetworkAutotuneContraction#
- cutensornetStatus_t cutensornetNetworkAutotuneContraction(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t networkDesc,
- const cutensornetWorkspaceDescriptor_t workDesc,
- const cutensornetNetworkAutotunePreference_t pref,
- cudaStream_t stream
Auto-tunes the internal contraction plan to find the best
cutensorContractionPlan_tfor each pair-wise contraction of the network contraction phase.Note
This function is blocking due to the nature of the auto-tuning process.
Note
Input and output data pointers and strides must be provided ahead of calling this function using the cutensornetNetworkSetInputTensorMemory() and cutensornetNetworkSetOutputTensorMemory() functions.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] The network descriptor whose internal contraction plan will be fine-tuned.
workDesc – [in] Opaque structure describing the workspace. The provided workspace must be valid (the workspace size must be the same as or larger than both the minimum needed and the value provided at contraction preparation). See cutensornetNetworkPrepareContraction(), cutensornetWorkspaceGetMemorySize() & cutensornetWorkspaceSetMemory(). If a device memory handler is set, the
workDesccan be set to null, or the workspace pointer inworkDesccan be set to null, and the workspace size can be set either to 0 (in which case the “recommended” size is used, see CUTENSORNET_WORKSIZE_PREF_RECOMMENDED) or to a valid size. A workspace of the specified size will be drawn from the user’s mempool and released back once done.pref – [in] Controls the auto-tuning process and gives the user control over how much time is spent in this routine.
stream – [in] The CUDA stream on which the computation is performed.
cutensornetCreateContractionAutotunePreference#
- cutensornetStatus_t cutensornetCreateContractionAutotunePreference(
- const cutensornetHandle_t handle,
- cutensornetContractionAutotunePreference_t *autotunePreference
DEPRECATED: Sets up the required auto-tune parameters for the contraction plan.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
This function allocates data on the heap; hence, it is critical that cutensornetDestroyContractionAutotunePreference() is called once
autotunePreferenceis no longer required.- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
autotunePreference – [out] This data structure holds all information about the user-requested auto-tune parameters.
cutensornetContractionAutotunePreferenceGetAttribute#
- cutensornetStatus_t cutensornetContractionAutotunePreferenceGetAttribute(
- const cutensornetHandle_t handle,
- const cutensornetContractionAutotunePreference_t autotunePreference,
- cutensornetContractionAutotunePreferenceAttributes_t attr,
- void *buffer,
- size_t sizeInBytes
DEPRECATED: Gets attributes of
autotunePreference.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
autotunePreference – [in] Opaque structure that is accessed.
attr – [in] Specifies the attribute that is requested.
buffer – [out] On return, this buffer (of size
sizeInBytes) holds the value that corresponds toattrwithinautotunePreference.sizeInBytes – [in] Size of
buffer(in bytes).
cutensornetContractionAutotunePreferenceSetAttribute#
- cutensornetStatus_t cutensornetContractionAutotunePreferenceSetAttribute(
- const cutensornetHandle_t handle,
- cutensornetContractionAutotunePreference_t autotunePreference,
- cutensornetContractionAutotunePreferenceAttributes_t attr,
- const void *buffer,
- size_t sizeInBytes
DEPRECATED: Sets attributes of
autotunePreference.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
autotunePreference – [inout] Opaque structure that is accessed.
attr – [in] Specifies the attribute that is requested.
buffer – [in] This buffer (of size
sizeInBytes) determines the value to whichattrwill be set.sizeInBytes – [in] Size of
buffer(in bytes).
cutensornetDestroyContractionAutotunePreference#
- cutensornetStatus_t cutensornetDestroyContractionAutotunePreference(
- cutensornetContractionAutotunePreference_t autotunePreference
DEPRECATED: Frees all the memory associated with
autotunePreference.- Parameters:
autotunePreference – [inout] Opaque structure.
cutensornetCreateNetworkAutotunePreference#
- cutensornetStatus_t cutensornetCreateNetworkAutotunePreference(
- const cutensornetHandle_t handle,
- cutensornetNetworkAutotunePreference_t *autotunePreference
Sets up the required auto-tune parameters for the network.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
This function allocates data on the heap; hence, it is critical that cutensornetDestroyNetworkAutotunePreference() is called once
autotunePreferenceis no longer required.- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
autotunePreference – [out] This data structure holds all information about the user-requested auto-tune parameters.
cutensornetNetworkAutotunePreferenceSetAttribute#
- cutensornetStatus_t cutensornetNetworkAutotunePreferenceSetAttribute(
- const cutensornetHandle_t handle,
- cutensornetNetworkAutotunePreference_t autotunePreference,
- cutensornetNetworkAutotunePreferenceAttributes_t attr,
- const void *buf,
- size_t sizeInBytes
Sets attributes of network
autotunePreference.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
autotunePreference – [inout] Opaque structure that is accessed.
attr – [in] Specifies the attribute that is requested.
buf – [in] This buffer (of size
sizeInBytes) determines the value to whichattrwill be set.sizeInBytes – [in] Size of
buf(in bytes).
cutensornetNetworkAutotunePreferenceGetAttribute#
- cutensornetStatus_t cutensornetNetworkAutotunePreferenceGetAttribute(
- const cutensornetHandle_t handle,
- const cutensornetNetworkAutotunePreference_t autotunePreference,
- cutensornetNetworkAutotunePreferenceAttributes_t attr,
- void *buffer,
- size_t sizeInBytes
Gets attributes of network
autotunePreference.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
autotunePreference – [in] Opaque structure that is accessed.
attr – [in] Specifies the attribute that is requested.
buffer – [out] On return, this buffer (of size
sizeInBytes) holds the value that corresponds toattrwithinautotunePreference.sizeInBytes – [in] Size of
buffer(in bytes).
cutensornetDestroyNetworkAutotunePreference#
- cutensornetStatus_t cutensornetDestroyNetworkAutotunePreference(
- cutensornetNetworkAutotunePreference_t autotunePreference
Frees all the memory associated with
autotunePreference.- Parameters:
autotunePreference – [inout] Opaque structure.
Workspace management API#
cutensornetCreateWorkspaceDescriptor#
- cutensornetStatus_t cutensornetCreateWorkspaceDescriptor(
- const cutensornetHandle_t handle,
- cutensornetWorkspaceDescriptor_t *workDesc
Creates a workspace descriptor that holds information about the user provided memory buffer.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
workDesc – [out] Pointer to the opaque workspace descriptor.
cutensornetWorkspaceComputeSizes#
- cutensornetStatus_t cutensornetWorkspaceComputeSizes(
- const cutensornetHandle_t handle,
- const cutensornetNetworkDescriptor_t networkDesc,
- const cutensornetContractionOptimizerInfo_t optimizerInfo,
- cutensornetWorkspaceDescriptor_t workDesc
DEPRECATED: Computes the workspace size needed to contract the input tensor network using the provided contraction path.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [in] Describes the tensor network (i.e., its tensors and their connectivity).
optimizerInfo – [in] Opaque structure.
workDesc – [out] The workspace descriptor in which the information is collected.
cutensornetWorkspaceComputeContractionSizes#
- cutensornetStatus_t cutensornetWorkspaceComputeContractionSizes(
- const cutensornetHandle_t handle,
- const cutensornetNetworkDescriptor_t networkDesc,
- const cutensornetContractionOptimizerInfo_t optimizerInfo,
- cutensornetWorkspaceDescriptor_t workDesc
Computes the workspace size needed to contract the tensor network using the provided contraction path.
This function will compute the required SCRATCH and CACHE memory sizes needed for contracting the network, as well as for computing the gradients if necessary.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] Describes the tensor network (i.e., its tensors and their connectivity).
optimizerInfo – [in] Opaque structure.
workDesc – [out] The workspace descriptor in which the information is collected.
cutensornetWorkspaceComputeQRSizes#
- cutensornetStatus_t cutensornetWorkspaceComputeQRSizes(
- const cutensornetHandle_t handle,
- const cutensornetTensorDescriptor_t descTensorIn,
- const cutensornetTensorDescriptor_t descTensorQ,
- const cutensornetTensorDescriptor_t descTensorR,
- cutensornetWorkspaceDescriptor_t workDesc
Computes the workspace size needed to perform the tensor QR operation.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
descTensorIn – [in] Describes the modes, extents and other metadata information for a tensor.
descTensorQ – [in] Describes the modes, extents and other metadata information for the output tensor Q.
descTensorR – [in] Describes the modes, extents and other metadata information for the output tensor R.
workDesc – [out] The workspace descriptor in which the information is collected.
cutensornetWorkspaceComputeSVDSizes#
- cutensornetStatus_t cutensornetWorkspaceComputeSVDSizes(
- const cutensornetHandle_t handle,
- const cutensornetTensorDescriptor_t descTensorIn,
- const cutensornetTensorDescriptor_t descTensorU,
- const cutensornetTensorDescriptor_t descTensorV,
- const cutensornetTensorSVDConfig_t svdConfig,
- cutensornetWorkspaceDescriptor_t workDesc
Computes the workspace size needed to perform the tensor SVD operation.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
descTensorIn – [in] Describes the modes, extents and other metadata information for a tensor.
descTensorU – [in] Describes the modes, extents and other metadata information for the output tensor U.
descTensorV – [in] Describes the modes, extents and other metadata information for the output tensor V.
svdConfig – [in] This data structure holds the user-requested svd parameters.
workDesc – [out] The workspace descriptor in which the information is collected.
cutensornetWorkspaceComputeGateSplitSizes#
- cutensornetStatus_t cutensornetWorkspaceComputeGateSplitSizes(
- const cutensornetHandle_t handle,
- const cutensornetTensorDescriptor_t descTensorInA,
- const cutensornetTensorDescriptor_t descTensorInB,
- const cutensornetTensorDescriptor_t descTensorInG,
- const cutensornetTensorDescriptor_t descTensorU,
- const cutensornetTensorDescriptor_t descTensorV,
- const cutensornetGateSplitAlgo_t gateAlgo,
- const cutensornetTensorSVDConfig_t svdConfig,
- cutensornetComputeType_t computeType,
- cutensornetWorkspaceDescriptor_t workDesc
Computes the workspace size needed to perform the gating operation.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
descTensorInA – [in] Describes the modes, extents, and other metadata information of the input tensor A.
descTensorInB – [in] Describes the modes, extents, and other metadata information of the input tensor B.
descTensorInG – [in] Describes the modes, extents, and other metadata information of the input gate tensor.
descTensorU – [in] Describes the modes, extents, and other metadata information of the output U tensor. The extents of uncontracted modes are expected to be consistent with
descTensorInAanddescTensorInG.descTensorV – [in] Describes the modes, extents, and other metadata information of the output V tensor. The extents of uncontracted modes are expected to be consistent with
descTensorInBanddescTensorInG.gateAlgo – [in] The algorithm to use for splitting the gate tensor onto tensor A and B.
svdConfig – [in] Opaque structure holding the user-requested SVD parameters.
computeType – [in] Denotes the compute type used throughout the computation.
workDesc – [out] Opaque structure describing the workspace.
cutensornetWorkspaceGetSize#
- cutensornetStatus_t cutensornetWorkspaceGetSize(
- const cutensornetHandle_t handle,
- const cutensornetWorkspaceDescriptor_t workDesc,
- cutensornetWorksizePref_t workPref,
- cutensornetMemspace_t memSpace,
- uint64_t *workspaceSize
DEPRECATED: Retrieves the needed workspace size for the given workspace preference and memory space.
The needed sizes for different tasks must be pre-calculated by calling the corresponding API, e.g, cutensornetWorkspaceComputeContractionSizes(), cutensornetWorkspaceComputeQRSizes(), cutensornetWorkspaceComputeSVDSizes() and cutensornetWorkspaceComputeGateSplitSizes().
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
workDesc – [in] Opaque structure describing the workspace.
workPref – [in] Preference of workspace for planning.
memSpace – [in] The memory space where the workspace is allocated.
workspaceSize – [out] Needed workspace size.
cutensornetWorkspaceGetMemorySize#
- cutensornetStatus_t cutensornetWorkspaceGetMemorySize(
- const cutensornetHandle_t handle,
- const cutensornetWorkspaceDescriptor_t workDesc,
- cutensornetWorksizePref_t workPref,
- cutensornetMemspace_t memSpace,
- cutensornetWorkspaceKind_t workKind,
- int64_t *memorySize
Retrieves the needed workspace size for the given workspace preference, memory space, workspace kind.
The needed sizes for different tasks must be pre-calculated by calling the corresponding API, e.g, cutensornetWorkspaceComputeContractionSizes(), cutensornetWorkspaceComputeQRSizes(), cutensornetWorkspaceComputeSVDSizes() and cutensornetWorkspaceComputeGateSplitSizes().
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
workDesc – [in] Opaque structure describing the workspace.
workPref – [in] Preference of workspace for planning.
memSpace – [in] The memory space where the workspace is allocated.
workKind – [in] The kind of workspace.
memorySize – [out] Needed workspace size.
cutensornetWorkspaceSet#
- cutensornetStatus_t cutensornetWorkspaceSet(
- const cutensornetHandle_t handle,
- cutensornetWorkspaceDescriptor_t workDesc,
- cutensornetMemspace_t memSpace,
- void *const workspacePtr,
- uint64_t workspaceSize
DEPRECATED: Sets the memory address and workspace size of workspace provided by user.
A workspace is valid in the following cases:
workspacePtris valid andworkspaceSize> 0workspacePtris null andworkspaceSize> 0 (used during cutensornetCreateContractionPlan() to provide the available workspace).workspacePtris null andworkspaceSize= 0 (workspace memory will be drawn from the user’s mempool)
A workspace will be validated against the minimal required at usage (cutensornetCreateContractionPlan(), cutensornetContractionAutotune(), cutensornetContraction())
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
workDesc – [inout] Opaque structure describing the workspace.
memSpace – [in] The memory space where the workspace is allocated.
workspacePtr – [in] Workspace memory pointer, may be null.
workspaceSize – [in] Workspace size, must be >= 0.
cutensornetWorkspaceSetMemory#
- cutensornetStatus_t cutensornetWorkspaceSetMemory(
- const cutensornetHandle_t handle,
- cutensornetWorkspaceDescriptor_t workDesc,
- cutensornetMemspace_t memSpace,
- cutensornetWorkspaceKind_t workKind,
- void *const memoryPtr,
- int64_t memorySize
Sets the memory address and workspace size of the workspace provided by user.
A workspace is valid in the following cases:
memoryPtris valid andmemorySize> 0memoryPtris null andmemorySize> 0: used to indicate memory with the indicatedmemorySizeshould be drawn from the mempool, or for cutensornetNetworkPrepareContraction() to indicate the available workspace size.memoryPtris null andmemorySize= 0: indicates the workspace of the specified kind is disabled (currently applies to CACHE kind only).memoryPtris null andmemorySize< 0: indicates workspace memory should be drawn from the user’s mempool with the CUTENSORNET_WORKSIZE_PREF_RECOMMENDED size (see cutensornetWorksizePref_t).
The
memorySizeof the SCRATCH kind will be validated against the minimal required at usage (cutensornetNetworkPrepareContraction(), cutensornetNetworkAutotuneContraction(), cutensornetNetworkContract()) The CACHE memory size can be any, the larger the better.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
workDesc – [inout] Opaque structure describing the workspace.
memSpace – [in] The memory space where the workspace is allocated.
workKind – [in] The kind of workspace.
memoryPtr – [in] Workspace memory pointer, may be null.
memorySize – [in] Workspace size.
cutensornetWorkspaceGet#
- cutensornetStatus_t cutensornetWorkspaceGet(
- const cutensornetHandle_t handle,
- const cutensornetWorkspaceDescriptor_t workDesc,
- cutensornetMemspace_t memSpace,
- void **workspacePtr,
- uint64_t *workspaceSize
DEPRECATED: Retrieves the memory address and workspace size of workspace hosted in the workspace descriptor.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
workDesc – [in] Opaque structure describing the workspace.
memSpace – [in] The memory space where the workspace is allocated.
workspacePtr – [out] Workspace memory pointer.
workspaceSize – [out] Workspace size.
cutensornetWorkspaceGetMemory#
- cutensornetStatus_t cutensornetWorkspaceGetMemory(
- const cutensornetHandle_t handle,
- const cutensornetWorkspaceDescriptor_t workDesc,
- cutensornetMemspace_t memSpace,
- cutensornetWorkspaceKind_t workKind,
- void **memoryPtr,
- int64_t *memorySize
Retrieves the memory address and workspace size of workspace hosted in the workspace descriptor.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
workDesc – [in] Opaque structure describing the workspace.
memSpace – [in] The memory space where the workspace is allocated.
workKind – [in] The kind of workspace.
memoryPtr – [out] Workspace memory pointer.
memorySize – [out] Workspace size.
cutensornetWorkspacePurgeCache#
- cutensornetStatus_t cutensornetWorkspacePurgeCache(
- const cutensornetHandle_t handle,
- cutensornetWorkspaceDescriptor_t workDesc,
- cutensornetMemspace_t memSpace
Purges the cached data in the specified memory space.
Purges/invalidates the cached data in the CUTENSORNET_WORKSPACE_CACHE workspace kind on the
memSpacememory space, but does not free the memory nor return it to the memory pool.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
workDesc – [inout] Opaque structure describing the workspace.
memSpace – [in] The memory space where the workspace is allocated.
cutensornetDestroyWorkspaceDescriptor#
- cutensornetStatus_t cutensornetDestroyWorkspaceDescriptor(
- cutensornetWorkspaceDescriptor_t workDesc
Frees the workspace descriptor.
Warning
This API does not free the memory provided by cutensornetWorkspaceSetMemory().
- Parameters:
workDesc – [inout] Opaque structure.
Network contraction API#
The network-centric execution flow functions introduced in cuTensorNet v2.9.0 are the preferred, and supersede the plan-based calls that are deprecated.
cutensornetContraction#
- cutensornetStatus_t cutensornetContraction(
- const cutensornetHandle_t handle,
- cutensornetContractionPlan_t plan,
- const void *const rawDataIn[],
- void *rawDataOut,
- cutensornetWorkspaceDescriptor_t workDesc,
- int64_t sliceId,
- cudaStream_t stream
DEPRECATED: Performs the actual contraction of the tensor network.
Note
If multiple slices are created, the order of contracting over slices using cutensornetContraction() should be ascending starting from slice 0. If parallelizing over slices manually (in any fashion: streams, devices, processes, etc.), please make sure the output tensors (that are subject to a global reduction) are zero-initialized.
Note
Input and output data pointers are recommended to be 256-byte aligned for best performance.
Note
This function is asynchronous w.r.t. the calling CPU thread. The user should guarantee that the memory buffer provided in
workDescis valid until a synchronization with the stream or the device is executed.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
plan – [inout] Encodes the execution of a tensor network contraction (see cutensornetCreateContractionPlan() and cutensornetContractionAutotune()). Some internal meta-data may be updated upon contraction.
rawDataIn – [in] Array of N pointers (N being the number of input tensors specified cutensornetCreateNetworkDescriptor());
rawDataIn[i]points to the data associated with the i-th input tensor (in device memory).rawDataOut – [out] Points to the raw data of the output tensor (in device memory).
workDesc – [in] Opaque structure describing the workspace. The provided workspace must be valid (the workspace size must be the same as or larger than both the minimum needed and the value provided at plan creation). See cutensornetCreateContractionPlan(), cutensornetWorkspaceGetMemorySize() & cutensornetWorkspaceSetMemory()). If a device memory handler is set, then
workDesccan be set to null, or the workspace pointer inworkDesccan be set to null, and the workspace size can be set either to 0 (in which case the “recommended” size is used, see CUTENSORNET_WORKSIZE_PREF_RECOMMENDED) or to a valid size. A workspace of the specified size will be drawn from the user’s mempool and released back once done.sliceId – [in] The ID of the slice that is currently contracted (this value ranges between
0andoptimizerInfo.numSlices); use0if no slices are used.stream – [in] The CUDA stream on which the computation is performed.
cutensornetContractSlices#
- cutensornetStatus_t cutensornetContractSlices(
- const cutensornetHandle_t handle,
- cutensornetContractionPlan_t plan,
- const void *const rawDataIn[],
- void *rawDataOut,
- int32_t accumulateOutput,
- cutensornetWorkspaceDescriptor_t workDesc,
- const cutensornetSliceGroup_t sliceGroup,
- cudaStream_t stream
DEPRECATED: Performs the actual contraction of the tensor network.
Note
Input and output data pointers are recommended to be at least 256-byte aligned for best performance.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
In the current release, this function will synchronize the stream in case distributed execution is activated (via cutensornetDistributedResetConfiguration)
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
plan – [inout] Encodes the execution of a tensor network contraction (see cutensornetCreateContractionPlan() and cutensornetContractionAutotune()). Some internal meta-data may be updated upon contraction.
rawDataIn – [in] Array of N pointers (N being the number of input tensors specified in cutensornetCreateNetworkDescriptor()):
rawDataIn[i]points to the data associated with the i-th input tensor (in device memory). The order of the provided memory pointers for the input tensors should match the order at which the input tensors have been appended to the network.rawDataOut – [out] Points to the raw data of the output tensor (in device memory).
accumulateOutput – [in] If 0, write the contraction result into rawDataOut; otherwise accumulate the result into rawDataOut.
workDesc – [in] Opaque structure describing the workspace. The provided CUTENSORNET_WORKSPACE_SCRATCH workspace must be valid (the workspace pointer must be device accessible, see cutensornetMemspace_t, and the workspace size must be the same as or larger than both the minimum needed and the value provided at plan creation). See cutensornetCreateContractionPlan(), cutensornetWorkspaceGetMemorySize() & cutensornetWorkspaceSetMemory(). The provided CUTENSORNET_WORKSPACE_CACHE workspace must be device accessible, see cutensornetMemspace_t; it can be of any size, the larger the better, up to the size that can be queried with cutensornetWorkspaceGetMemorySize(). If a device memory handler is set, then
workDesccan be set to null, or the memory pointer inworkDescof either the workspace kinds can be set to null, and the workspace size can be set either to a negative value (in which case the “recommended” size is used, see CUTENSORNET_WORKSIZE_PREF_RECOMMENDED) or to a valid size. For a workspace of kind CUTENSORNET_WORKSPACE_SCRATCH, a memory buffer with the specified size will be drawn from the user’s mempool and released back once done. For a workspace of kind CUTENSORNET_WORKSPACE_CACHE, a memory buffer with the specified size will be drawn from the user’s mempool and released back once theworkDescis destroyed, ifworkDesc!= NULL, otherwise, once theplanis destroyed, or an alternativeworkDescwith a different memory address/size is provided in a subsequent cutensornetContractSlices() call.sliceGroup – [in] Opaque object specifying the slices to be contracted (see cutensornetCreateSliceGroupFromIDRange() and cutensornetCreateSliceGroupFromIDs()). If set to null, all slices will be contracted.
stream – [in] The CUDA stream on which the computation is performed.
cutensornetNetworkPrepareContraction#
- cutensornetStatus_t cutensornetNetworkPrepareContraction(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t networkDesc,
- const cutensornetWorkspaceDescriptor_t workDesc
Prepares the network for contraction.
Prepares the network for contraction by generating the corresponding cuTENSOR pairwise contraction plans for intermediate tensors and optimizing their mode-order.
Note
This function must be preceded by a call to cutensornetContractionOptimize(), or cutensornetNetworkSetOptimizerInfo().
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] The network descriptor whose internal contraction plan will be built.
workDesc – [in] Opaque structure describing the workspace sizes that are available. At the preparation of the network contraction, only the workspace size is needed; the pointer to the workspace memory may be left null.
cutensornetNetworkContract#
- cutensornetStatus_t cutensornetNetworkContract(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t networkDesc,
- int32_t accumulateOutput,
- const cutensornetWorkspaceDescriptor_t workDesc,
- const cutensornetSliceGroup_t sliceGroup,
- cudaStream_t stream
Performs the actual contraction of the tensor network.
Note
Input and output data pointers are recommended to be at least 256-byte aligned for best performance.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
In the current release, this function will synchronize the stream in case distributed execution is activated (via cutensornetDistributedResetConfiguration)
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] The network descriptor whose specifed slices (
sliceGroup) will be contracted (see cutensornetNetworkPrepareContraction() and cutensornetNetworkAutotuneContraction()). Some internal meta-data may be updated upon contraction.accumulateOutput – [in] If 0, write the contraction result into output data buffer as provided by cutensornetNetworkSetOutputTensorMemory(); otherwise, accumulate the results.
workDesc – [in] Opaque structure describing the workspace. The provided CUTENSORNET_WORKSPACE_SCRATCH workspace must be valid (the workspace pointer must be device accessible, see cutensornetMemspace_t, and the workspace size must be the same as or larger than both the minimum needed and the value provided at contraction preparation). See cutensornetNetworkPrepareContraction(), cutensornetWorkspaceGetMemorySize() & cutensornetWorkspaceSetMemory(). The provided CUTENSORNET_WORKSPACE_CACHE workspace must be device accessible, see cutensornetMemspace_t; it can be of any size, the larger the better, up to the size that can be queried with cutensornetWorkspaceGetMemorySize(). If a device memory handler is set (see cutensornetSetDeviceMemHandler()), then
workDesccan be set to null, or the memory pointer inworkDescof either the workspace kinds can be set to null, and the workspace size can be set either to a negative value (in which case the “recommended” size is used, see CUTENSORNET_WORKSIZE_PREF_RECOMMENDED) or to a valid size. For a workspace of kind CUTENSORNET_WORKSPACE_SCRATCH, a memory buffer with the specified size will be drawn from the user’s mempool and released back once done. For a workspace of kind CUTENSORNET_WORKSPACE_CACHE, a memory buffer with the specified size will be drawn from the user’s mempool and released back once theworkDescis destroyed, ifworkDesc!= NULL, otherwise, once thenetworkDescis destroyed, cutensornetWorkspacePurgeCache() is called, or an alternativeworkDescwith a different memory address/size is provided in a subsequent cutensornetNetworkContract() call.sliceGroup – [in] Opaque object specifying the slices to be contracted (see cutensornetCreateSliceGroupFromIDRange() and cutensornetCreateSliceGroupFromIDs()). If set to null, all slices will be contracted.
stream – [in] The CUDA stream on which the computation is performed.
Gradient computation API#
cutensornetNetworkPrepareGradientsBackward#
- cutensornetStatus_t cutensornetNetworkPrepareGradientsBackward(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t networkDesc,
- const cutensornetWorkspaceDescriptor_t workDesc
Prepares the network for gradient computation.
Prepares the network for gradient computation by generating the corresponding cuTENSOR pairwise contraction plans for intermediate tensors and optimizing their mode-order.
Note
This function must be preceded by a call to cutensornetContractionOptimize(), or cutensornetNetworkSetOptimizerInfo().
Note
This function allocates internal data structures on the heap; hence, it is critical that cutensornetDestroyNetwork() is called once
networkDescis no longer required.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] The network descriptor whose internal contraction plan will be built.
workDesc – [in] Opaque structure describing the workspace. At the preparation of the network contraction, only the workspace size is needed; the pointer to the workspace memory may be left null.
cutensornetNetworkComputeGradientsBackward#
- cutensornetStatus_t cutensornetNetworkComputeGradientsBackward(
- const cutensornetHandle_t handle,
- cutensornetNetworkDescriptor_t networkDesc,
- int32_t accumulateOutput,
- const cutensornetWorkspaceDescriptor_t workDesc,
- const cutensornetSliceGroup_t sliceGroup,
- cudaStream_t stream
Computes the gradients of the network w.r.t. the input tensors whose gradients are required. The network must have been contracted and loaded in the
workDescCACHE. Operates only on networks with single slice and no singleton modes.Note
This function should be preceded with a call to both cutensornetNetworkPrepareGradientsBackward() and cutensornetNetworkContract() (in any order); Both calls to cutensornetNetworkContract() and cutensornetNetworkComputeGradientsBackward() should use either the same
workDescinstance (in order to share the CACHE memory), or both pass null toworkDescto use same mempool allocation for CACHE.networkDescmeta-data andworkDescshould not be altered in between these calls.Note
Calling cutensornetWorkspacePurgeCache() is necessary for computing gradients of different data sets (the combo cutensornetNetworkContract() and cutensornetNetworkComputeGradientsBackward() calls generate cached data that is only valid for the corresponding dataset and should be purged when the input tensors’ data change).
Note
Input data’s, output data’s, and workspace buffers’ pointers are recommended to be at least 256-byte aligned for best performance.
Note
When the provided CUTENSORNET_WORKSPACE_CACHE workspace is allocated on the host memory, this function will optimize data transfer from/to CPU memory through the provided SCRATCH buffer. Thus, providing a larger SCRATCH memory than the minimum required enables better performance.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
networkDesc – [inout] The network descriptor whose specifed slices (
sliceGroup) gradients will be computed (see cutensornetNetworkPrepareGradientsBackward()). Some internal meta-data may be updated upon contraction.accumulateOutput – [in] If 0, write the gradient results into gradients memory buffers; otherwise accumulates the results into gradients memory buffers.
workDesc – [in] Opaque structure describing the workspace. The provided CUTENSORNET_WORKSPACE_SCRATCH workspace must be valid (the workspace pointer must be device accessible, see cutensornetMemspace_t, and the workspace size must be the same as or larger than the minimum needed). See cutensornetWorkspaceComputeContractionSizes(), cutensornetWorkspaceGetMemorySize() & cutensornetWorkspaceSetMemory(). The provided CUTENSORNET_WORKSPACE_CACHE workspace must be valid (the workspace pointer must be device accessible, see cutensornetMemspace_t), and contains the cached intermediate tensors from the corresponding cutensornetNetworkContract() call. If a device memory handler is set, and
workDescis set to null, or the memory pointer inworkDescof either the workspace kinds is set to null, for both calls to cutensornetNetworkContract() and cutensornetNetworkComputeGradientsBackward(), memory will be drawn from the memory pool. See cutensornetNetworkContract() for details.sliceGroup – [in] Opaque object specifying the slices of the gradients to be computed (see cutensornetCreateSliceGroupFromIDRange() and cutensornetCreateSliceGroupFromIDs()). If set to null, all slices will be computed.
stream – [in] The CUDA stream on which the computation is performed.
Slice group API#
cutensornetCreateSliceGroupFromIDRange#
- cutensornetStatus_t cutensornetCreateSliceGroupFromIDRange(
- const cutensornetHandle_t handle,
- int64_t sliceIdStart,
- int64_t sliceIdStop,
- int64_t sliceIdStep,
- cutensornetSliceGroup_t *sliceGroup
Create a
cutensornetSliceGroup_tobject from a range, which produces a sequence of slice IDs from the specified start (inclusive) to the specified stop (exclusive) values with the specified step. The sequence can be increasing or decreasing depending on the start and stop values.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
sliceIdStart – [in] The start slice ID.
sliceIdStop – [in] The final slice ID is the largest (smallest) integer that excludes this value and all those above (below) for an increasing (decreasing) sequence.
sliceIdStep – [in] The step size between two successive slice IDs. A negative step size should be specified for a decreasing sequence.
sliceGroup – [out] Opaque object specifying the slice IDs.
cutensornetCreateSliceGroupFromIDs#
- cutensornetStatus_t cutensornetCreateSliceGroupFromIDs(
- const cutensornetHandle_t handle,
- const int64_t *beginIDSequence,
- const int64_t *endIDSequence,
- cutensornetSliceGroup_t *sliceGroup
Create a
cutensornetSliceGroup_tobject from a sequence of slice IDs. Duplicates in the input slice ID sequence will be removed.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
beginIDSequence – [in] A pointer to the beginning of the slice ID sequence.
endIDSequence – [in] A pointer to the end of the slice ID sequence.
sliceGroup – [out] Opaque object specifying the slice IDs.
cutensornetDestroySliceGroup#
- cutensornetStatus_t cutensornetDestroySliceGroup(
- cutensornetSliceGroup_t sliceGroup
Releases the resources associated with a
cutensornetSliceGroup_tobject and sets its value to null.- Parameters:
sliceGroup – [inout] Opaque object specifying the slices to be contracted (see cutensornetCreateSliceGroupFromIDRange() and cutensornetCreateSliceGroupFromIDs()).
Approximate tensor network execution API#
cutensornetTensorQR#
- cutensornetStatus_t cutensornetTensorQR(
- const cutensornetHandle_t handle,
- const cutensornetTensorDescriptor_t descTensorIn,
- const void *const rawDataIn,
- const cutensornetTensorDescriptor_t descTensorQ,
- void *q,
- const cutensornetTensorDescriptor_t descTensorR,
- void *r,
- const cutensornetWorkspaceDescriptor_t workDesc,
- cudaStream_t stream
Performs QR decomposition of a tensor.
The partition of all input modes in
descTensorInis specified indescTensorQanddescTensorR.descTensorQanddescTensorRare expected to share exactly one mode and the extent of that mode shall not exceed the minimum of m (row dimension) and n (column dimension) of the equivalent combined matrix QR.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
descTensorIn – [in] Describes the modes, extents, and other metadata information of a tensor.
rawDataIn – [in] Pointer to the raw data of the input tensor (in device memory).
descTensorQ – [in] Describes the modes, extents, and other metadata information of the output tensor Q.
q – [out] Pointer to the output tensor data Q (in device memory).
descTensorR – [in] Describes the modes, extents, and other metadata information of the output tensor R.
r – [out] Pointer to the output tensor data R (in device memory).
workDesc – [in] Opaque structure describing the workspace. The provided workspace must be valid (the workspace size must be the same as or larger than the minimum needed). See cutensornetWorkspaceGetMemorySize() & cutensornetWorkspaceSetMemory().
stream – [in] The CUDA stream on which the computation is performed.
cutensornetTensorSVD#
- cutensornetStatus_t cutensornetTensorSVD(
- const cutensornetHandle_t handle,
- const cutensornetTensorDescriptor_t descTensorIn,
- const void *const rawDataIn,
- cutensornetTensorDescriptor_t descTensorU,
- void *u,
- void *s,
- cutensornetTensorDescriptor_t descTensorV,
- void *v,
- const cutensornetTensorSVDConfig_t svdConfig,
- cutensornetTensorSVDInfo_t svdInfo,
- const cutensornetWorkspaceDescriptor_t workDesc,
- cudaStream_t stream
Performs SVD decomposition of a tensor.
The partition of all input modes in
descTensorInis specified indescTensorUanddescTensorV.descTensorUanddescTensorVare expected to share exactly one mode. The extent of the shared mode shall not exceed the minimum of m (row dimension) and n (column dimension) for the equivalent combined matrix SVD. The following variants of tensor SVD are supported:1. Exact SVD: This can be specified by setting the extent of the shared mode in
descTensorUanddescTensorVto be the mininum of m and n, and settingsvdConfigtoNULL.2. SVD with fixed extent truncation: This can be specified by setting the extent of the shared mode in
descTensorUanddescTensorVto be lower than the mininum of m and n.3. SVD with value-based truncation: This can be specified by setting CUTENSORNET_TENSOR_SVD_CONFIG_ABS_CUTOFF or CUTENSORNET_TENSOR_SVD_CONFIG_REL_CUTOFF attribute of
svdConfig.4. SVD with a combination of fixed extent and value-based truncation as described above.
Note
In the case of exact SVD or SVD with fixed extent truncation,
descTensorUanddescTensorVwill remain constant after the execution. The data inuandvwill respect theextentandstridein these tensor descriptors.Note
When value-based truncation is requested in
svdConfig,cutensornetTensorSVDsearches for the minimal extent that satifies both the value-based truncation and fixed extent requirement. If the resulting extent is found to be the same as the one specified in U/V tensor descriptors, theextentandstridefrom the tensor descriptors will be respected. If the resulting extent is found to be lower than the one specified in U/V tensor descriptors, the data inuandvwill adopt a new Fortran-layout matching the reduced extent found. TheextentandstrideindescTensorUanddescTensorVwill also be overwritten to reflect this change. The user can query the reduced extent with cutensornetTensorSVDInfoGetAttribute() or cutensornetGetTensorDetails() (which also returns the new strides).Note
As the reduced size for value-based truncation is not known until runtime, the user should always allocate based on the full data size specified by the initial
descTensorUanddescTensorVforuandv.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
descTensorIn – [in] Describes the modes, extents, and other metadata information of a tensor.
rawDataIn – [in] Pointer to the raw data of the input tensor (in device memory).
descTensorU – [inout] Describes the modes, extents, and other metadata information of the output tensor U. The extents for uncontracted modes are expected to be consistent with
descTensorIn.u – [out] Pointer to the output tensor data U (in device memory).
s – [out] Pointer to the output tensor data S (in device memory). Can be
NULLwhen the CUTENSORNET_TENSOR_SVD_CONFIG_S_PARTITION attribute ofsvdConfigis not set to default (CUTENSORNET_TENSOR_SVD_PARTITION_NONE).descTensorV – [inout] Describes the modes, extents, and other metadata information of the output tensor V.
v – [out] Pointer to the output tensor data V (in device memory).
svdConfig – [in] This data structure holds the user-requested SVD parameters. Can be
NULLif users do not need to perform value-based truncation or singular value partitioning.svdInfo – [out] Opaque structure holding all information about the trucation at runtime. Can be
NULLif runtime information on singular value truncation is not needed.workDesc – [in] Opaque structure describing the workspace. The provided workspace must be valid (the workspace size must be the same as or larger than the minimum needed). See cutensornetWorkspaceGetMemorySize() & cutensornetWorkspaceSetMemory().
stream – [in] The CUDA stream on which the computation is performed.
cutensornetGateSplit#
- cutensornetStatus_t cutensornetGateSplit(
- const cutensornetHandle_t handle,
- const cutensornetTensorDescriptor_t descTensorInA,
- const void *rawDataInA,
- const cutensornetTensorDescriptor_t descTensorInB,
- const void *rawDataInB,
- const cutensornetTensorDescriptor_t descTensorInG,
- const void *rawDataInG,
- cutensornetTensorDescriptor_t descTensorU,
- void *u,
- void *s,
- cutensornetTensorDescriptor_t descTensorV,
- void *v,
- const cutensornetGateSplitAlgo_t gateAlgo,
- const cutensornetTensorSVDConfig_t svdConfig,
- cutensornetComputeType_t computeType,
- cutensornetTensorSVDInfo_t svdInfo,
- const cutensornetWorkspaceDescriptor_t workDesc,
- cudaStream_t stream
Performs gate split operation.
descTensorInA,descTensorInB, anddescTensorInGare expected to form a fully connected graph where the uncontracted modes are partitioned ontodescTensorUanddescTensorVvia tensor SVD.descTensorUanddescTensorVare expected to share exactly one mode. The extent of that mode shall not exceed the minimum of m (row dimension) and n (column dimension) of the smallest equivalent matrix SVD problem.Note
The options for truncation and the treatment of
extentandstridefollows the same logic as tensor SVD, see cutensornetTensorSVD().Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
descTensorInA – [in] Describes the modes, extents, and other metadata information of the input tensor A.
rawDataInA – [in] Pointer to the raw data of the input tensor A (in device memory).
descTensorInB – [in] Describes the modes, extents, and other metadata information of the input tensor B.
rawDataInB – [in] Pointer to the raw data of the input tensor B (in device memory).
descTensorInG – [in] Describes the modes, extents, and other metadata information of the input gate tensor.
rawDataInG – [in] Pointer to the raw data of the input gate tensor G (in device memory).
descTensorU – [in] Describes the modes, extents, and other metadata information of the output U tensor. The extents of uncontracted modes are expected to be consistent with
descTensorInAanddescTensorInG.u – [out] Pointer to the output tensor data U (in device memory).
s – [out] Pointer to the output tensor data S (in device memory). Can be
NULLwhen the CUTENSORNET_TENSOR_SVD_CONFIG_S_PARTITION attribute ofsvdConfigis not set to default (CUTENSORNET_TENSOR_SVD_PARTITION_NONE).descTensorV – [in] Describes the modes, extents, and other metadata information of the output V tensor. The extents of uncontracted modes are expected to be consistent with
descTensorInBanddescTensorInG.v – [out] Pointer to the output tensor data V (in device memory).
gateAlgo – [in] The algorithm to use for splitting the gate tensor into tensor A and B.
svdConfig – [in] Opaque structure holding the user-requested SVD parameters.
computeType – [in] Denotes the compute type used throughout the computation.
svdInfo – [out] Opaque structure holding all information about the truncation at runtime.
workDesc – [in] Opaque structure describing the workspace.
stream – [in] The CUDA stream on which the computation is performed.
Tensor SVD config API#
cutensornetCreateTensorSVDConfig#
- cutensornetStatus_t cutensornetCreateTensorSVDConfig(
- const cutensornetHandle_t handle,
- cutensornetTensorSVDConfig_t *svdConfig
Sets up the options for singular value decomposition and truncation.
Note
This function allocates data on the heap; hence, it is critical that cutensornetDestroyTensorSVDConfig() is called once
svdConfigis no longer required.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
svdConfig – [out] This data structure holds the user-requested svd parameters.
cutensornetDestroyTensorSVDConfig#
- cutensornetStatus_t cutensornetDestroyTensorSVDConfig(
- cutensornetTensorSVDConfig_t svdConfig
Frees all the memory associated with the tensor svd configuration.
- Parameters:
svdConfig – [inout] Opaque handle to a tensor svd configuration.
cutensornetTensorSVDConfigGetAttribute#
- cutensornetStatus_t cutensornetTensorSVDConfigGetAttribute(
- const cutensornetHandle_t handle,
- const cutensornetTensorSVDConfig_t svdConfig,
- cutensornetTensorSVDConfigAttributes_t attr,
- void *buffer,
- size_t sizeInBytes
Gets attributes of
svdConfig.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
svdConfig – [in] Opaque structure that is accessed.
attr – [in] Specifies the attribute that is requested.
buffer – [out] On return, this buffer (of size
sizeInBytes) holds the value that corresponds toattrwithinsvdConfig.sizeInBytes – [in] Size of
buffer(in bytes).
cutensornetTensorSVDConfigSetAttribute#
- cutensornetStatus_t cutensornetTensorSVDConfigSetAttribute(
- const cutensornetHandle_t handle,
- cutensornetTensorSVDConfig_t svdConfig,
- cutensornetTensorSVDConfigAttributes_t attr,
- const void *buffer,
- size_t sizeInBytes
Sets attributes of
svdConfig.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
svdConfig – [in] Opaque structure that is accessed.
attr – [in] Specifies the attribute that is requested.
buffer – [in] This buffer (of size
sizeInBytes) determines the value to whichattrwill be set.sizeInBytes – [in] Size of
buffer(in bytes).
Tensor SVD info API#
cutensornetCreateTensorSVDInfo#
- cutensornetStatus_t cutensornetCreateTensorSVDInfo(
- const cutensornetHandle_t handle,
- cutensornetTensorSVDInfo_t *svdInfo
Sets up the information for singular value decomposition.
Note
This function allocates data on the heap; hence, it is critical that cutensornetDestroyTensorSVDInfo() is called once
svdInfois no longer required.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
svdInfo – [out] This data structure holds all information about the trucation at runtime.
cutensornetDestroyTensorSVDInfo#
- cutensornetStatus_t cutensornetDestroyTensorSVDInfo(
- cutensornetTensorSVDInfo_t svdInfo
Frees all the memory associated with the TensorSVDInfo object.
- Parameters:
svdInfo – [inout] Opaque handle to a TensorSVDInfo object.
cutensornetTensorSVDInfoGetAttribute#
- cutensornetStatus_t cutensornetTensorSVDInfoGetAttribute(
- const cutensornetHandle_t handle,
- const cutensornetTensorSVDInfo_t svdInfo,
- cutensornetTensorSVDInfoAttributes_t attr,
- void *buffer,
- size_t sizeInBytes
Gets attributes of
svdInfo.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
svdInfo – [in] Opaque structure that is accessed.
attr – [in] Specifies the attribute that is requested.
buffer – [out] On return, this buffer (of size
sizeInBytes) holds the value that corresponds toattrwithinsvdConfig.sizeInBytes – [in] Size of
buffer(in bytes).
Distributed parallelization API#
cutensornetDistributedResetConfiguration#
- cutensornetStatus_t cutensornetDistributedResetConfiguration(
- cutensornetHandle_t handle,
- const void *commPtr,
- size_t commSize
Resets the distributed MPI parallelization configuration.
This function accepts a user-provided MPI communicator in a type-erased form and stores a copy of it inside the cuTensorNet library handle. The provided MPI communicator must be explicitly created by calling MPI_Comm_dup (please see the MPI specification). The subsequent calls to the contraction path finder, contraction plan autotuning, and contraction execution will be parallelized across all MPI processes in the provided MPI communicator. The provided MPI communicator is owned by the user, it should stay alive until the next reset call with a different MPI communicator. If NULL is provided as the pointer to the MPI communicator, no parallelization will be applied to the above mentioned procedures such that those procedures will execute redundantly across all MPI processes. As an example, please refer to the tensornet_example_mpi_auto.cu sample.
To enable distributed parallelism, cuTensorNet requires users to set an environment variable
$CUTENSORNET_COMM_LIBcontaining the path to a shared library wrapping the communication primitives. For MPI users, we ship a wrapper source filecutensornet_distributed_interface_mpi.cthat can be compiled against the target MPI library using the build script provided in the same folder inside the tar archive distribution. cuTensorNet will use the included function pointers to perform inter-process communication using the chosen MPI library.Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
This is a collective call that must be executed by all MPI processes. Note that one can still provide different (non-NULL) MPI communicators to different subgroups of MPI processes (to create concurrent cuTensorNet distributed subgroups).
Warning
The provided MPI communicator must not be used by more than one cuTensorNet library handle. This is automatically ensured by using MPI_Comm_dup.
Warning
The current library implementation assumes one GPU instance per MPI rank since the cutensornet library handle is associated with a single GPU instance. In case of multiple GPUs per node, each MPI process running on the same node may still see all GPU devices if CUDA_VISIBLE_DEVICES was not set to provide an exclusive access to each GPU. In such a case, the cutensornet library runtime will assign GPU #(processRank % numVisibleDevices), where processRank is the rank of the current process in its MPI communicator, and numVisibleDevices is the number of GPU devices visible to the current MPI process. The assigned GPU must coincide with the one associated with the cutensornet library handle, otherwise resulting in an error. To ensure consistency, the user must call cudaSetDevice in each MPI process to select the correct GPU device prior to creating a cutensornet library handle.
Warning
It is user’s responsibility to ensure that each MPI process in each provided MPI communicator executes exactly the same sequence of cutensornet API calls, which otherwise will result in an undefined behavior.
- Parameters:
handle – [in] cuTensorNet library handle.
commPtr – [in] A pointer to the provided MPI communicator created by MPI_Comm_dup.
commSize – [in] The size of the provided MPI communicator: sizeof(MPI_Comm).
cutensornetDistributedGetNumRanks#
- cutensornetStatus_t cutensornetDistributedGetNumRanks(
- const cutensornetHandle_t handle,
- int32_t *numRanks
Queries the number of MPI ranks in the current distributed MPI configuration.
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The number of ranks corresponds to the MPI communicator used by the current MPI process. If different subgroups of MPI processes used different MPI communicators, the reported number will refer to their specific MPI communicators.
- Parameters:
handle – [in] cuTensorNet library handle.
numRanks – [out] Number of MPI ranks in the current distributed MPI configuration.
cutensornetDistributedGetProcRank#
- cutensornetStatus_t cutensornetDistributedGetProcRank(
- const cutensornetHandle_t handle,
- int32_t *procRank
Queries the rank of the current MPI process in the current distributed MPI configuration.
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The MPI process rank corresponds to the MPI communicator used by that MPI process. If different subgroups of MPI processes used different MPI communicators, the reported number will refer to their specific MPI communicators.
- Parameters:
handle – [in] cuTensorNet library handle.
procRank – [out] Rank of the current MPI process in the current distributed MPI configuration.
cutensornetDistributedSynchronize#
- cutensornetStatus_t cutensornetDistributedSynchronize(
- const cutensornetHandle_t handle
Globally synchronizes all MPI processes in the current distributed MPI configuration, ensuring that all preceding cutensornet API calls have completed across all MPI processes.
Note
Requires a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
This is a collective call that must be executed by all MPI processes.
Warning
Prior to performing the global synchronization, the user is still required to synchronize GPU operations locally (via CUDA stream synchronization).
- Parameters:
handle – [in] cuTensorNet library handle.
Tensor network state API#
The tensor network (TN) state API functions centered around cutensornetState_t allow users to define
complex tensor network states by gradually applying tensor operators (e.g., quantum gates) to
the initial (vacuum) state residing in the user-defined direct-product space, that is, a tensor space
constructed as a direct product of multiple vector spaces of given dimensions. In particular, this way
of defining a tensor network state is very convenient for quantum circuit simulators since the final output
state of a given quantum circuit is constructed by gradually applying quantum gates to the initial (vacuum)
state of all qubits (or qudits). Once the action of all tensor operators has been specified, the underlying
tensor network is completely defined, together with the final state of the tensor network that resides in
the same direct-product space as the initial (vacuum) state. Users also have the following options to request
certain approximations or actions applied to the final state before computing its various properties:
No additional approximations or actions. No additional API calls are required and users may directly proceed to the next steps for property computation. All properties will be computed by direct contraction of the full tensor network(s) corresponding to the property of interest.
Explicitly precompute the full state tensor. This can be achieved via a sequence of calls to
cutensornetStateConfigure(),cutensornetStatePrepare(), andcutensornetStateCompute()to configure, prepare, and finally compute the full state tensor. The calculation of all subsequent properties may leverage the computed full state tensor (it is not guaranteed to do so).Provide the initial quantum state to be a non-vacuum state in the Matrix Product State (MPS) form. This can be achieved by calling the
cutensornetStateInitializeMPS()API to provide the initial state before subsequent calls to the configure, prepare, and compute API functions. Note that this API does not specify that the final state is to be computed in MPS (see below) and therefore can be used in conjunction with either contraction-based computation or MPS-based representation.Factorize the final state in the MPS form. The
cutensornetStateFinalizeMPS()API function can be used to specify the MPS factorization structure for the defined tensor network state. Once the desired MPS factorization has been specified, subsequent calls to the configure, prepare, and compute API functions will configure the MPS computation, prepare the MPS computation, and, finally, compute the MPS factorization. All subsequent properties will be computed by using the MPS-factorized form of the original tensor network state.
After choosing one of the approaches above, users can take advantage of the following APIs to compute various properties associated with the tensor network state:
cutensornetStateAccessor_tand corresponding APIs can be used to compute the full state tensor, any of its cartesian slices, or individual amplitudes.
cutensornetStateExpectation_tand corresponding APIs can be used to compute an expectation value of a given tensor network operator with respect to the given tensor network state. A tensor network operator (cutensornetNetworkOperator_t) is defined as a sum of products of tensor operators where tensors constituting each product (component) act on disjoint degrees of freedom (e.g., disjoint subsets of qudits).
cutensornetStateMarginal_tand corresponding APIs can be used to compute the marginal probability distribution tensors (reduced density matrices) over the specified modes of the tensor network state. In particular, including all tensor network state modes would result in the computation of the full density matrix of the tensor network state.
cutensornetStateSampler_tand corresponding APIs can be used to sample from the probability distribution associated with the specified tensor network state modes.
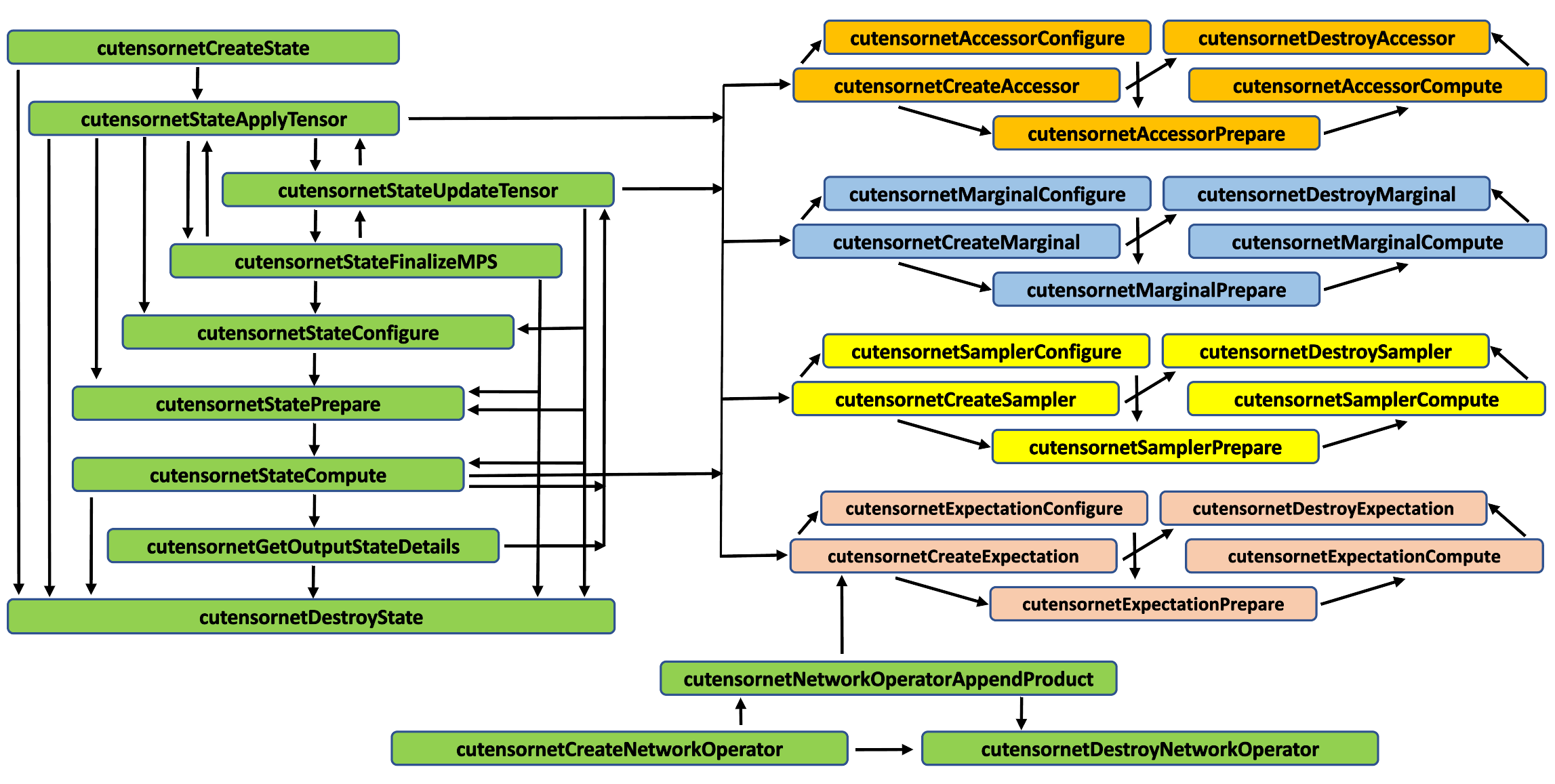
Figure 1. cuTensorNet TN state API workflow logic. Arrows indicate allowed sequences of API calls.#
For each such property of the tensor network state that one may want to compute, the corresponding subset of the TN state API includes API functions for defining (creating) the feature-providing object (Create), like those named above, configuring it by setting specific attributes (Configure), preparing it for computation (Prepare), and, finally, computing it (Compute), and, of course, destroying it at the end (Destroy). See Figure 1 for the API workflow logic, where arrows indicate allowed sequences of API calls.
Note
When the properties are to be computed for an MPS-factorized form of the tensor network state,
users are responsible for explicitly allocating memory for the MPS state tensor(s) and maintaining it for the lifetime
of the cutensornetState_t object. For more detailed descriptions of MPS-based property computations, please refer to these
sections on amplitudes, expectation value,
marginal distribution, and sampling.
cutensornetCreateState#
- cutensornetStatus_t cutensornetCreateState(
- const cutensornetHandle_t handle,
- cutensornetStatePurity_t purity,
- int32_t numStateModes,
- const int64_t *stateModeExtents,
- cudaDataType_t dataType,
- cutensornetState_t *tensorNetworkState
Creates an empty tensor network state of a given shape defined by the number of primary tensor modes and their extents.
A tensor network state is a tensor representing the result of a full contraction of some (yet unspecified) tensor network. That is, a tensor network state is simply a tensor living in a given primary tensor space constructed as a direct product of a given number of vector spaces which are specified by their dimensions (each vector space represents a state mode). A tensor network state (state tensor) can be either pure or mixed. A pure state tensor resides in the defining primary direct-product space and is represented by a tensor from that space. A mixed tensor network state (state tensor) resides in the direct-product space formed by the defining primary direct-product space tensored with its dual (conjugate) tensor space. A mixed state tensor is a tensor with twice more modes, namely, the modes from the defining primary direct-product space, followed by the same number of modes from its dual (conjugate) space. Subsequently, the initial (empty) vacuum tensor state can be evolved into the final target tensor state by applying user-defined tensor operators (e.g., quantum gates) via cutensornetStateApplyTensorOperator(). By default, the final target tensor state is formally represented by a single output tensor, the result of the full tensor network contraction (it does not have to be explicitly computed). However, the user may choose to impose a certain tensor factorization on the final tensor state via the cutensornetStateFinalizeXXX() call, where the supported tensor factorizations (XXX) are: MPS (Matrix Product State). In this case, the final tensor state, which now has to be computed explicitly, will be represented by a tuple of output tensors according to the chosen factorization scheme. The information on the output tensor(s) can be queried by calling cutensornetGetOutputStateDetails().
Note
To give a concrete example, a pure state tensor of any quantum circuit with 4 qubits has the shape [2,2,2,2] (quantum circuit is a specific kind of tensor network). A mixed state tensor in this case will have the shape [2,2,2,2, 2,2,2,2] corresponding to the density matrix of the 4-qubit register, although there are still only 4 defining modes associated with the primary direct-product space of 4 qubits in this case (direct product of 4 vector spaces of dimension 2). That is, a mixed state tensor contains two sets of modes, one from the primary direct-product space and one from its dual space, but it is still defined by the modes of the primary direct-product space, specifically, by a tuple of dimensions of the constituting vector spaces (2-dimensional vector spaces in case of qubits). For clarity, we will refer to the modes of the primary direct-product tensor space as State Modes. Subsequent actions of quantum gates on the tensor network state via calls to cutensornetStateAppyTensor() can now be conveniently specified via subsets of the state modes acted on by the quantum gate.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The current cuTensorNet library release only supports pure tensor network states and provides the MPS factorization as a preview feature.
- Parameters:
handle – [in] cuTensorNet library handle.
purity – [in] Desired purity of the tensor network state (pure or mixed).
numStateModes – [in] Number of the defining state modes, irrespective of state purity. Note that both pure and mixed tensor network states are defined solely by the modes of the primary direct-product space.
stateModeExtents – [in] Pointer to the extents of the defining state modes (dimensions of the vector spaces constituting the primary direct-product space).
dataType – [in] Data type of the state tensor.
tensorNetworkState – [out] Tensor network state (empty at this point, aka vacuum).
cutensornetDestroyState#
- cutensornetStatus_t cutensornetDestroyState(
- cutensornetState_t tensorNetworkState
Frees all resources owned by the tensor network state.
Note
After the tensor network state is destroyed, all pointers to the tensor operator data used for specifying the final target state may be invalidated.
- Parameters:
tensorNetworkState – [in] Tensor network state.
cutensornetStateApplyTensor#
- cutensornetStatus_t cutensornetStateApplyTensor(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- int32_t numStateModes,
- const int32_t *stateModes,
- void *tensorData,
- const int64_t *tensorModeStrides,
- const int32_t immutable,
- const int32_t adjoint,
- const int32_t unitary,
- int64_t *tensorId
DEPRECATED: Applies a tensor operator to the tensor network state.
A tensor operator acts on a specified subset of the tensor state modes, where the number of state modes acted upon defines its rank. A tensor operator is represented by a tensor with twice more modes than the number of state modes it acts on, where the first half of the tensor operator modes is contracted with the state modes of the input state tensor while the second half of the tensor operator modes forms the output state tensor modes. Since the default tensor storage strides follow the generalized columnwise layout, the action of a rank-2 tensor operator G on a rank-2 state tensor Q0 can be expressed symbolically as: Q1(i1,i0) = Q0(j1,j0) * G(j1,j0,i1,i0), which is simply the reversed form of the standard notation: Q1(i0,i1) = G(i0,i1,j0,j1) * Q0(j0,j1), given that a graphical representation of tensor circuits traditionally applies tensor operators (gates) from left to right. In this way, we conveniently ensure the standard row-following initialization of the tensor operator (gate) when using the C-language array initialization syntax. In the above example, tensor operator (gate) G has four modes and acts on two state modes.
Note
For the purpose of quantum circuit definition, our current convention conveniently allows initialization of a 2-qubit CNOT gate (tensor operator) with a C array with elements precisely following the canonical textbook (row-following) definition of the CNOT gate:
\[\begin{split} \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 0 \end{pmatrix} \end{split}\]Note
In case the tensor operator elements change their value while still residing at the same storage location, one must still call
cutensornetStateUpdateTensorOperatorto register such a change with the same pointer (storage location).Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The pointer to the tensor operator elements is owned by the user and it must stay valid for the whole lifetime of the tensor network state, unless explicitly replaced by another pointer via
cutensornetStateUpdateTensorOperator.- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [inout] Tensor network state.
numStateModes – [in] Number of state modes the tensor operator acts on.
stateModes – [in] Pointer to the state modes the tensor operator acts on.
tensorData – [in] Elements of the tensor operator (must be of the same data type as the elements of the state tensor).
tensorModeStrides – [in] Strides of the tensor operator data layout (note that the tensor operator has twice more modes than the number of state modes it acts on). Passing NULL will assume the default generalized columnwise layout.
immutable – [in] Whether or not the tensor operator data may change during the lifetime of the tensor network state. Any data change must be registered via a call to
cutensornetStateUpdateTensorOperator.adjoint – [in] Whether or not the tensor operator is applied as an adjoint (ket and bra modes reversed, with all tensor elements complex conjugated).
unitary – [in] Whether or not the tensor operator is unitary with respect to the first and second halves of its modes.
tensorId – [out] Unique integer id (for later identification of the tensor operator).
cutensornetStateApplyTensorOperator#
- cutensornetStatus_t cutensornetStateApplyTensorOperator(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- int32_t numStateModes,
- const int32_t *stateModes,
- void *tensorData,
- const int64_t *tensorModeStrides,
- const int32_t immutable,
- const int32_t adjoint,
- const int32_t unitary,
- int64_t *tensorId
Applies a tensor operator to the tensor network state.
A tensor operator acts on a specified subset of the tensor state modes, where the number of state modes acted upon defines its rank. A tensor operator is represented by a tensor with twice more modes than the number of state modes it acts on, where the first half of the tensor operator modes is contracted with the state modes of the input state tensor while the second half of the tensor operator modes forms the output state tensor modes. Since the default tensor storage strides follow the generalized columnwise layout, the action of a rank-2 tensor operator G on a rank-2 state tensor Q0 can be expressed symbolically as: Q1(i1,i0) = Q0(j1,j0) * G(j1,j0,i1,i0), which is simply the reversed form of the standard notation: Q1(i0,i1) = G(i0,i1,j0,j1) * Q0(j0,j1), given that a graphical representation of tensor circuits traditionally applies tensor operators (gates) from left to right. In this way, we conveniently ensure the standard row-following initialization of the tensor operator (gate) when using the C-language array initialization syntax. In the above example, tensor operator (gate) G has four modes and acts on two state modes.
Concretely, for
stateModes = {q0, q1}, the tensor operator has2 * numStateModes = 4modes whose default (column-major) ordering is:(q1_ket, q0_ket, q1_bra, q0_bra)with strides(1, 2, 4, 8)for dimension-2 modes. That is, the mode ordering within each half (ket and bra) is reversed relative to the order given instateModes. WhentensorModeStridesis NULL, a C-contiguous (row-major) array whose rows and columns follow the standard textbook gate matrix layout will be interpreted correctly.Note
This mode ordering convention differs from
cutensornetNetworkOperatorAppendProduct, which uses forward ordering within each half. The same raw data buffer passed to both APIs with NULL strides will be interpreted differently for multi-mode operators. ExplicittensorModeStridescan be used to reconcile the two conventions.Note
For the purpose of quantum circuit definition, our current convention conveniently allows initialization of a 2-qubit CNOT gate (tensor operator) with a C array with elements precisely following the canonical textbook (row-following) definition of the CNOT gate:
\[\begin{split} \begin{pmatrix} 1 & 0 & 0 & 0 \\ 0 & 1 & 0 & 0 \\ 0 & 0 & 0 & 1 \\ 0 & 0 & 1 & 0 \end{pmatrix} \end{split}\]Note
In case the tensor operator elements change their value while still residing at the same storage location, one must still call
cutensornetStateUpdateTensorOperatorto register such a change with the same pointer (storage location).Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The pointer to the tensor operator elements is owned by the user and it must stay valid for the whole lifetime of the tensor network state, unless explicitly replaced by another pointer via
cutensornetStateUpdateTensorOperator.- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [inout] Tensor network state.
numStateModes – [in] Number of state modes the tensor operator acts on.
stateModes – [in] Pointer to the state modes the tensor operator acts on.
tensorData – [in] Elements of the tensor operator (must be of the same data type as the elements of the state tensor).
tensorModeStrides – [in] Strides of the tensor operator data layout (note that the tensor operator has twice more modes than the number of state modes it acts on). Passing NULL will assume the default generalized columnwise storage layout.
immutable – [in] Whether or not the tensor operator data may change during the lifetime of the tensor network state. Any data change must be registered via a call to
cutensornetStateUpdateTensorOperator.adjoint – [in] Whether or not the tensor operator is applied as an adjoint (ket and bra modes reversed, with all tensor elements complex conjugated).
unitary – [in] Whether or not the tensor operator is unitary with respect to the first and second halves of its modes.
tensorId – [out] Unique integer id (for later identification of the tensor operator).
cutensornetStateApplyTensorOperatorWithGradient#
- cutensornetStatus_t cutensornetStateApplyTensorOperatorWithGradient(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- int32_t numStateModes,
- const int32_t *stateModes,
- void *tensorData,
- const int64_t *tensorModeStrides,
- const int32_t immutable,
- const int32_t adjoint,
- const int32_t unitary,
- void *gradientData,
- const int64_t *gradientModeStrides,
- int64_t *tensorId
Applies a tensor operator to the tensor network state and registers it for gradient computation.
This function combines applying a tensor operator with registering it for gradient computation.
The gradient will have the same shape as the tensor operator (i.e., twice more modes than the number of state modes it acts on). The gradient output will be written to the provided
gradientDatabuffer (with layout given by gradientModeStrides) when cutensornetExpectationComputeWithGradientsBackward() is called.Note
This function must be called before cutensornetExpectationPrepare() for the gradient to be included.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [inout] Tensor network state.
numStateModes – [in] Number of state modes the tensor operator acts on.
stateModes – [in] Pointer to the state modes the tensor operator acts on.
tensorData – [in] Elements of the tensor operator (must be of the same data type as the elements of the state tensor).
tensorModeStrides – [in] Strides of the tensor operator data layout (note that the tensor operator has twice more modes than the number of state modes it acts on). Passing NULL will assume the default generalized columnwise storage layout.
immutable – [in] Whether or not the tensor operator data may change during the lifetime of the tensor network state. Any data change must be registered via a call to
cutensornetStateUpdateTensorOperator.adjoint – [in] Whether or not the tensor operator is applied as an adjoint (ket and bra modes reversed, with all tensor elements complex conjugated).
unitary – [in] Whether or not the tensor operator is unitary with respect to the first and second halves of its modes.
gradientData – [out] Device-accessible pointer where the gradient will be written when cutensornetExpectationComputeWithGradientsBackward() is called. Must be pre-allocated with sufficient size to hold the gradient tensor (same shape as tensor operator).
gradientModeStrides – [in] Strides of the gradient tensor data layout. Passing NULL will assume the default generalized columnwise storage layout.
tensorId – [out] Unique integer id (for later identification of the tensor operator).
cutensornetStateApplyDiagonalTensorOperator#
- cutensornetStatus_t cutensornetStateApplyDiagonalTensorOperator(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- int32_t numStateModes,
- const int32_t *stateModes,
- void *tensorData,
- const int64_t *tensorModeStrides,
- const int32_t immutable,
- const int32_t adjoint,
- const int32_t unitary,
- int64_t *tensorId
Applies a diagonal tensor operator to the tensor network state.
A diagonal tensor operator is a tensor in which all off-diagonal elements are zero. In a tensor network, this operator acts multiplicatively only on the diagonal entries of the tensor state modes it covers: for n state modes, it is fully characterized by a rank-n tensor containing the diagonal values. For example, a diagonal tensor operator acting on qubit 0 and qubit 1 stores diagonal elements for each possible joint basis state (i,j), NOT distinct “input” and “output” mode pairs. Thus, the tensor operator’s modes are (i, j), not (i1, j1, i2, j2). Since the default tensor storage strides follow the generalized columnwise layout, the action of a rank-2 diagonal tensor operator G on a rank-2 state tensor Q0 can be expressed symbolically as: Q1(j,i) = Q0(j,i) * G(j,i), which is simply the reversed form of the standard notation: Q1(i,j) = G(i,j) * Q0(i,j), given that a graphical representation of tensor circuits traditionally applies tensor operators (gates) from left to right. In this way, we conveniently ensure the standard row-following initialization of the tensor operator (gate) when using the C-language array initialization syntax. In the above example, tensor operator (gate) G has two modes and acts on two state modes.
Note
For the purpose of quantum circuit definition, our current convention conveniently allows initialization of a 2-qubit CZ gate (diagonal tensor operator) with a C array with diagonal elements precisely following the canonical textbook (row-following) definition of the CZ gate:
\[ \begin{pmatrix} 1 & 1 & 1 & -1 \end{pmatrix} \]Note
In case the diagonal tensor operator elements change their value while still residing at the same storage location, one must still call
cutensornetStateUpdateTensorOperatorto register such a change with the same pointer (storage location).Warning
The pointer to the diagonal tensor operator elements is owned by the user and it must stay valid for the whole lifetime of the tensor network state, unless explicitly replaced by another pointer via
cutensornetStateUpdateTensorOperator.- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [inout] Tensor network state.
numStateModes – [in] Number of state modes the diagonal tensor operator acts on.
stateModes – [in] Pointer to the state modes the diagonal tensor operator acts on.
tensorData – [in] Elements of the diagonal tensor operator (must be of the same data type as the elements of the state tensor).
tensorModeStrides – [in] Strides of the diagonal tensor operator data layout corresponding to the state modes. Passing NULL will assume the default generalized columnwise storage layout.
immutable – [in] Whether or not the diagonal tensor operator data may change during the lifetime of the tensor network state. Any data change must be registered via a call to
cutensornetStateUpdateTensorOperator.adjoint – [in] Whether or not the diagonal tensor operator is applied as its adjoint (ket and bra modes reversed, with all tensor elements complex conjugated). Note that for a diagonal tensor operator, adjoint is equivalent to complex conjugation.
unitary – [in] Whether or not the diagonal tensor operator is unitary with respect to its ket and bra. For diagonal tensor operators, this corresponds to whether the imaginary component of all its entries is zero.
tensorId – [out] Unique integer id (for later identification of the diagonal tensor operator).
cutensornetStateApplyControlledTensorOperator#
- cutensornetStatus_t cutensornetStateApplyControlledTensorOperator(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- int32_t numControlModes,
- const int32_t *stateControlModes,
- const int64_t *stateControlValues,
- int32_t numTargetModes,
- const int32_t *stateTargetModes,
- void *tensorData,
- const int64_t *tensorModeStrides,
- const int32_t immutable,
- const int32_t adjoint,
- const int32_t unitary,
- int64_t *tensorId
Applies a controlled tensor operator to the tensor network state.
This API function performs the same operation as
cutensornetStateApplyTensorOperatorexcept that the tensor operator is specified via the control-target representation typical for multi-qubit quantum gates. Namely, only the target tensor of the full controlled tensor operator needs to be provided here (the number of modes in the provided target tensor is twice the number of the target state modes it acts on). The full tensor operator representation will be automatically generated from the target tensor and the list of control state modes/values.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [inout] Tensor network state.
numControlModes – Number of control state modes used by the tensor operator.
stateControlModes – Controlling state modes used by the tensor operator.
stateControlValues – Control values for the controlling state modes. A control value is the sequential integer id of the qudit basis component which activates the action of the target tensor operator. If NULL, all control values are assumed to be set to the max id (last qudit basis component), which will be 1 for qubits.
numTargetModes – Number of target state modes acted on by the tensor operator.
stateTargetModes – Target state modes acted on by the tensor operator.
tensorData – [in] Elements of the target tensor of the controlled tensor operator (must be of the same data type as the elements of the state tensor).
tensorModeStrides – [in] Strides of the tensor operator data layout (note that the tensor operator has twice more modes than the number of the target state modes it acts on). Passing NULL will assume the default generalized columnwise storage layout.
immutable – [in] Whether or not the tensor operator data may change during the lifetime of the tensor network state. Any data change must be registered via a call to
cutensornetStateUpdateTensorOperator.adjoint – [in] Whether or not the tensor operator is applied as an adjoint (ket and bra modes reversed, with all tensor elements complex conjugated).
unitary – [in] Whether or not the controlled tensor operator is unitary with respect to the first and second halves of its modes.
tensorId – [out] Unique integer id (for later identification of the tensor operator).
cutensornetStateApplyUnitaryChannel#
- cutensornetStatus_t cutensornetStateApplyUnitaryChannel(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- int32_t numStateModes,
- const int32_t *stateModes,
- int32_t numTensors,
- void *tensorData[],
- const int64_t *tensorModeStrides,
- const double probabilities[],
- int64_t *channelId
Applies a tensor channel consisting of one or more unitary tensor operators to the tensor network state.
A tensor channel is a completely positive trace-preserving linear map represented by one or more tensor operators. A unitary tensor channel solely consists of unitary tensor operators. All constituting tensor operators have twice more modes than the number of state modes they act on, as usually.
Note
The storage layout of all constituting tensor operators must be the same, represented by a single
tensorModeStridesargument.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [inout] Tensor network state.
numStateModes – [in] Number of state modes the tensor channel acts on.
stateModes – [in] Pointer to the state modes the tensor channel acts on.
numTensors – [in] Number of constituting tensor operators defining the tensor channel.
tensorData – [in] Elements of the tensor operators constituting the tensor channel (must be of the same data type as the elements of the state tensor).
tensorModeStrides – [in] Strides of the tensor data storage layout (note that the supplied tensors have twice more modes than the number of state modes they act on). Passing NULL will assume the default generalized columnwise storage layout.
probabilities – [in] Probabilities associated with the individual tensor operators.
channelId – [out] Unique integer id (for later identification of the tensor channel).
- Returns:
cutensornetStatus_t
cutensornetStateApplyGeneralChannel#
- cutensornetStatus_t cutensornetStateApplyGeneralChannel(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- int32_t numStateModes,
- const int32_t *stateModes,
- int32_t numTensors,
- void *tensorData[],
- const int64_t *tensorModeStrides,
- int64_t *channelId
Applies a tensor channel consisting of one or more gneral Kraus operators to the tensor network state.
A tensor channel is a completely positive trace-preserving linear map represented by one or more tensor operators. All constituting tensor operators have twice more modes than the number of state modes they act on, as usually. For a general Kraus operator \(K_i\), the action of the noise channel on state \(\rho\) is simulated as applying the operator \(\frac{1}{\sqrt{p_i}} K_i\) with probability \(p_i = \text{Tr}(K_i \rho K_i^\dagger)\), preserving the norm of the state.
Note
This API requires the input channel in
tensorDatato be trace-preserving. Supplying a non-trace-preserving channel may lead to unexpected results.The storage layout of all constituting tensor operators must be the same, represented by a single
tensorModeStridesargument.As of cuTensorNet v2.7.0, this API only supports MPS simulation with
CUTENSORNET_STATE_CONFIG_MPS_GAUGE_OPTIONset toCUTENSORNET_STATE_MPS_GAUGE_FREE(default). Contraction based tensor network simulation and MPS simulation withCUTENSORNET_STATE_MPS_GAUGE_SIMPLEare not supported.For MPS simulation, the number of state modes must be either 1 or 2.
The
channelIdcannot be used to update the channel usingcutensornetStateUpdateTensorOperator.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [inout] Tensor network state.
numStateModes – [in] Number of state modes the tensor channel acts on.
stateModes – [in] Pointer to the state modes the tensor channel acts on.
numTensors – [in] Number of constituting tensor operators defining the tensor channel.
tensorData – [in] Elements of the tensor operators constituting the tensor channel (must be of the same data type as the elements of the state tensor).
tensorModeStrides – [in] Strides of the tensor data storage layout (note that the supplied tensors have twice more modes than the number of state modes they act on). Passing NULL will assume the default generalized columnwise storage layout.
channelId – [out] Unique integer id (for later identification of the tensor channel).
- Returns:
cutensornetStatus_t
cutensornetStateApplyNetworkOperator#
- cutensornetStatus_t cutensornetStateApplyNetworkOperator(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- const cutensornetNetworkOperator_t tensorNetworkOperator,
- const int32_t immutable,
- const int32_t adjoint,
- const int32_t unitary,
- int64_t *operatorId
Applies a tensor network operator to a tensor network state.
Note
Currently the applied tensor network operators are restricted to those containing only one component (either a tensor product or an MPO).
Note
The returned unique integer id (operatorId) defines the beginning of a contiguous range of unique integer ids associated with the tensors constituting the sole component of the tensor network operator: [operatorId..(operatorId + N - 1)], where N is the number of tensors constituting the sole component of the tensor network operator. The tensor ids from this contiguous range can then be used for registering updates on the corresponding tensors via
cutensornetStateUpdateTensorOperator.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
In the current release, only immutable tensor network operators are supported. This restriction may be lifted in future.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [inout] Tensor network state.
tensorNetworkOperator – [in] Tensor network operator containg only a single component.
immutable – [in] Whether or not the tensor network operator data may change during the lifetime of the tensor network state.
adjoint – [in] Whether or not the tensor network operator is applied as an adjoint.
unitary – [in] Whether or not the tensor network operator is unitary with respect to the first and second halves of its modes.
operatorId – [out] Unique integer id (for later identification of the tensor network operator).
cutensornetStateUpdateTensor#
- cutensornetStatus_t cutensornetStateUpdateTensor(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- int64_t tensorId,
- void *tensorData,
- int32_t unitary
Registers an external update of the elements of the specified tensor operator that was previously applied to the tensor network state.
Note
The provided pointer to the tensor elements location may or may not coincide with the originally used pointer. However, the originally provided strides of the tensor operator data layout are assumed applicable to the updated tensor operator data location, that is, one cannot change the storage strides during the tensor operator data update.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The pointer to the tensor operator elements is owned by the user and it must stay valid for the whole lifetime of the tensor network state, unless explicitly replaced by another pointer via
cutensornetStateUpdateTensorOperator.- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [in] Tensor network state.
tensorId – [in] Tensor id assigned during the
cutensornetStateApplyTensorOperatorcall.tensorData – [in] Pointer to the updated elements of the tensor operator (tensor operator elements must be of the same type as the state tensor).
unitary – [in] Whether or not the tensor operator is unitary with respect to the first and second halves of its modes. This parameter is not applicable to the tensors that are part of a matrix product operator (MPO).
cutensornetStateUpdateTensorOperator#
- cutensornetStatus_t cutensornetStateUpdateTensorOperator(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- int64_t tensorId,
- void *tensorData,
- int32_t unitary
Registers an external update of the elements of the specified tensor operator that was previously applied to the tensor network state.
Note
The provided pointer to the tensor elements location may or may not coincide with the originally used pointer. However, the originally provided strides of the tensor operator data layout are assumed applicable to the updated tensor operator data location, that is, one cannot change the storage strides during the tensor operator data update.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The pointer to the tensor operator elements is owned by the user and it must stay valid for the whole lifetime of the tensor network state, unless explicitly replaced by another pointer via
cutensornetStateUpdateTensorOperator.- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [in] Tensor network state.
tensorId – [in] Tensor id assigned during the
cutensornetStateApplyTensorOperatorcall.tensorData – [in] Pointer to the updated elements of the tensor operator (tensor operator elements must be of the same type as the state tensor).
unitary – [in] Whether or not the tensor operator is unitary with respect to the first and second halves of its modes. This parameter is not applicable to the tensors that are part of a matrix product operator (MPO).
cutensornetStateUpdateTensorOperatorGradient#
- cutensornetStatus_t cutensornetStateUpdateTensorOperatorGradient(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- int64_t tensorId,
- void *gradientData
Updates the gradient output buffer for a tensor operator that was previously applied with gradient.
Use this to change the device-accessible buffer where the gradient for the given tensor operator will be written when cutensornetExpectationComputeWithGradientsBackward() is called. The storage layout (strides) remains as originally specified in cutensornetStateApplyTensorOperatorWithGradient().
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [inout] Tensor network state.
tensorId – [in] Tensor id assigned during the cutensornetStateApplyTensorOperatorWithGradient() call.
gradientData – [out] Device-accessible pointer for gradient output.
cutensornetStateConfigure#
- cutensornetStatus_t cutensornetStateConfigure(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- cutensornetStateAttributes_t attribute,
- const void *attributeValue,
- size_t attributeSize
Configures computation of the full tensor network state, either in the exact or a factorized form.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [inout] Tensor network state.
attribute – [in] Configuration attribute.
attributeValue – [in] Pointer to the configuration attribute value (type-erased).
attributeSize – [in] The size of the configuration attribute value.
cutensornetStatePrepare#
- cutensornetStatus_t cutensornetStatePrepare(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- size_t maxWorkspaceSizeDevice,
- cutensornetWorkspaceDescriptor_t workDesc,
- cudaStream_t cudaStream
Prepares computation of the full tensor network state, either in the exact or a factorized form.
Note
The cudaStream argument is unused in the current release (can be set to 0x0).
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [in] Tensor network state.
maxWorkspaceSizeDevice – [in] Upper limit on the amount of available GPU scratch memory (bytes).
workDesc – [out] Workspace descriptor (the required scratch/cache memory sizes will be set).
cudaStream – [in] CUDA stream.
cutensornetStateGetInfo#
- cutensornetStatus_t cutensornetStateGetInfo(
- const cutensornetHandle_t handle,
- const cutensornetState_t tensorNetworkState,
- cutensornetStateAttributes_t attribute,
- void *attributeValue,
- size_t attributeSize
Retrieves an attribute related to computation of the full tensor network state, either in the exact or a factorized form.
Note
The Flop count INFO attribute may not always be available, in which case the returned value will be zero.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [in] Tensor network state.
attribute – [in] Information attribute.
attributeValue – [out] Pointer to the information attribute value (type-erased).
attributeSize – [in] The size of the information attribute value.
cutensornetStateCompute#
- cutensornetStatus_t cutensornetStateCompute(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- cutensornetWorkspaceDescriptor_t workDesc,
- int64_t *extentsOut[],
- int64_t *stridesOut[],
- void *stateTensorsOut[],
- cudaStream_t cudaStream
Performs the actual computation of the full tensor network state, either in the exact or a factorized form.
Note
The length of
extentsOut,stridesOut, andstateTensorsOutshould correspond to the final target state MPS representation. For instance, if the final target state is factorized as an MPS with open boundary conditions,stateTensorsOutis expected to be an array ofnumStateModespointers and the buffer sizes for allstateTensorsOut[i]are expected to be consistent with the target extents specified in the cutensornetStateFinalizeMPS() call prior to the state computation. If no factorization is requested for the tensor network state, the shape and strides of a single full output state tensor, which is computed in this API call, will be returned.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The provided workspace descriptor
workDescmust have the Device Scratch buffer set explicitly since user-provided memory pools are not supported in the current release. Additionally, the attached workspace buffer must be 256-byte aligned in the current release.- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [in] Tensor network state.
workDesc – [in] Workspace descriptor (the required scratch/cache memory buffers must be set by the user).
extentsOut – [out] If not NULL, will hold the extents of all tensors defining the output state representation. Optionally, it can be NULL if this data is not needed.
stridesOut – [out] If not NULL, will hold the strides for all tensors defining the output state representation. Optionally, it can be NULL if this data is not needed.
stateTensorsOut – [inout] An array of pointers to GPU storage for all tensors defining the output state representation.
cudaStream – [in] CUDA stream.
cutensornetGetOutputStateDetails#
- cutensornetStatus_t cutensornetGetOutputStateDetails(
- const cutensornetHandle_t handle,
- const cutensornetState_t tensorNetworkState,
- int32_t *numTensorsOut,
- int32_t numModesOut[],
- int64_t *extentsOut[],
- int64_t *stridesOut[]
Queries the number of tensors, number of modes, extents, and strides for each of the final output state tensors.
Note
If all information regarding the output tensors is needed by the user, this function should be called three times: the first time to retrieve
numTensorsOutfor allocatingnumModesOut, the second time to retrievenumModesOutfor allocatingextentsOutandstridesOut, and the last time to retrieveextentsOutandstridesOut.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
To retrieve
numTensorsOutandnumModesOut, it is not necessary to first compute the final target state via the cutensornetStateCompute() call. However, to obtainextentsOutandstridesOut, cutensornetStateCompute() may need to be called first to compute the output state factorization in case the output state is forced to be factorized (e.g., MPS-factorized).- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [in] Tensor network state.
numTensorsOut – [out] On return, will hold the number of output state tensors (argument cannot be NULL).
numModesOut – [out] If not NULL, will hold the number of modes for each output state tensor. Optionally, can be NULL.
extentsOut – [out] If not NULL, will hold mode extents for each output state tensor. Optionally, can be NULL.
stridesOut – [out] If not NULL, will hold strides for each output state tensor. Optionally, can be NULL.
cutensornetStateInitializeMPS#
- cutensornetStatus_t cutensornetStateInitializeMPS(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- cutensornetBoundaryCondition_t boundaryCondition,
- const int64_t *const extentsIn[],
- const int64_t *const stridesIn[],
- void *stateTensorsIn[]
Imposes a user-defined MPS (Matrix Product State) factorization on the initial tensor network state with the given shape and data.
Note
This API function may be called at any time during the lifetime of the tensor network state to modify its initial state. If not called, the initial state will stay in the default vacuum state.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [inout] Tensor network state.
boundaryCondition – [in] The boundary condition of the chosen MPS representation.
extentsIn – [in] Array of size
nStateModesspecifying the extents of all tensors defining the initial MPS representation.extents[i]is expected to be consistent with the mode order (shared mode between (i-1)th and i-th MPS tensor, state mode of the i-th MPS tensor, shared mode between i-th and the (i+1)th MPS tensor). For the open boundary condition, the modes of the first tensor get reduced to (state mode, shared mode with the second site) while the modes of the last tensor become (shared mode with the second to the last site, state mode).stridesIn – [in] Array of size
nStateModesspecifying the strides of all tensors in the chosen MPS representation. Similar toextentsIn,stridesInis also expected to be consistent with the mode order of each MPS tensor. If NULL, the default generalized column-major strides will be assumed.stateTensorsIn – [in] Array of size
nStateModesspecifying the data for all tensors defining the chosen MPS representation. If NULL, the initial MPS-factorized state will represent the vacuum state.
cutensornetStateFinalizeMPS#
- cutensornetStatus_t cutensornetStateFinalizeMPS(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- cutensornetBoundaryCondition_t boundaryCondition,
- const int64_t *const extentsOut[],
- const int64_t *const stridesOut[]
Imposes a user-defined MPS (Matrix Product State) factorization on the final tensor network state with the given shape.
By calling this API function, only the desired target tensor network state representation (MPS representation) is specified without actual computation. Tensors constituting the original tensor network state may still be updated with new data after this API function call. The actual MPS factorization of the tensor network state will be computed after calling
cutensornetStatePrepareandcutensornetStateComputeAPI functions, following thiscutensornetStateFinalizeMPScall.Note
The current MPS factorization feature is provided as a preview, with more optimizations and enhanced functionality coming up in future releases. In the current release, the primary goal of this feature is to facilitate implementation of the MPS compression of tensor network states via a convenient high-level interface, targeting a broader community of users interested in adding MPS algorithms to their simulators.
Note
extentsOutcan be used to specify the extent truncation for the shared bond between adjacent MPS tensors.Note
As of cuTensorNet v2.7.0, this API does not support MPS simulation when the number of state modes is equal to 1. Please use contraction based tensor network method for the simulation.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The current cuTensorNet library release supports MPS factorization of tensor network states with two-dimensional state modes only (qubits only, using the quantum computing language).
Warning
In the current release, the MPS factorization does not benefit from distributed execution.
Warning
If value-based SVD truncation is specified in CUTENSORNET_STATE_MPS_SVD_CONFIG,
extentsOutandstridesOutmay not be respected during execution (e.g., in cutensornetStateCompute()). In such cases, users can query runtime values ofextentsOutandstridesOutin cutensornetStateCompute() by providing valid pointers.Warning
As of current version, if
tensorNetworkStatehas different extents on different modes, exact MPS factorization can not be computed if there are operators acting on two non-adjacent modes.- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [inout] Tensor network state.
boundaryCondition – [in] The boundary condition of the target MPS representation.
extentsOut – [in] Array of size
nStateModesspecifying the maximal extents of all tensors defining the target MPS representation.extentsOut[i]is expected to be consistent with the mode order (shared mode between (i-1)th and i-th MPS tensor, state mode of the i-th MPS tensor, shared mode between i-th and (i+1)th MPS tensor). For the open boundary condition, the modes for the first tensor get reduced to (state mode, shared mode with the second site) while the modes for the last tensor become (shared mode with the second last site, state mode).stridesOut – [in] Array of size
nStateModesspecifying the strides of all tensors defining the target MPS representation. Similar toextentsOut,stridesOutis also expected to be consistent with the mode order of each MPS tensor. If NULL, the default generalized column-major strides will be assumed.
cutensornetStateCaptureMPS#
- cutensornetStatus_t cutensornetStateCaptureMPS(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState
Resets the tensor network state to the MPS state previously computed via
cutensornetStateComputeBy calling this API function, all tensor operators and tensor network operators that have been applied to the state will be deleted. The new initial state will be reset to the previously computed MPS state specified via a
cutensornetStateFinalizeMPScall and computed via acutensornetStateComputecall. The MPS simulation settings that have been specified viacutensornetStateConfigureandcutensornetStateFinalizeMPSwill remain.Note
This hepler API is equivalent to creating a
cutensornetState_twith the previous output MPS state as the initial MPS state while maintaining the same MPS simulation settings and extents/strides of the output MPS tensors.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The deleted tensor operators and tensor network operators will no longer be accessible via their integer Ids. The subsequent tensor operators and tensor network operators will have new unique integer Ids which will not overlap with the old ones.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [inout] Tensor network state.
cutensornetCreateNetworkOperator#
- cutensornetStatus_t cutensornetCreateNetworkOperator(
- const cutensornetHandle_t handle,
- int32_t numStateModes,
- const int64_t stateModeExtents[],
- cudaDataType_t dataType,
- cutensornetNetworkOperator_t *tensorNetworkOperator
Creates an uninitialized tensor network operator of a given shape defined by the number of state modes and their extents.
A tensor network operator is an operator that maps tensor network states from the primary direct-product space back to the same tensor space. The shape of the tensor network operator is defined by the number of state modes and their extents, which should match the definition of the tensor network states the operator will be acting on. Note that formally the declared tensor network operator will have twice more modes than the number of defining state modes, the first half corresponding to the primary direct-product space it acts on while the second half corresponding to the same primary direct-product space where the resulting tensor network state lives.
Note
This API defines an abstract uninitialized tensor network operator. Users may later initialize it using some concrete structure by appending components to it.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
numStateModes – [in] The number of state modes the operator acts on.
stateModeExtents – [in] An array of size
numStateModesspecifying the extent of each state mode acted on.dataType – [in] Data type of the operator.
tensorNetworkOperator – [out] Tensor network operator (empty at this point).
cutensornetNetworkOperatorAppendProduct#
- cutensornetStatus_t cutensornetNetworkOperatorAppendProduct(
- const cutensornetHandle_t handle,
- cutensornetNetworkOperator_t tensorNetworkOperator,
- cuDoubleComplex coefficient,
- int32_t numTensors,
- const int32_t numStateModes[],
- const int32_t *stateModes[],
- const int64_t *tensorModeStrides[],
- const void *tensorData[],
- int64_t *componentId
Appends a tensor product operator component to the tensor network operator.
A tensor product operator component is defined as a tensor product of one or more tensor operators acting on disjoint subsets of state modes. Note that each tensor operator (tensor factor) in the specified tensor product has twice more modes than the number of state modes it acts on. Specifically, the first half of tensor operator modes will be contracted with the state modes. A typical example would be a tensor product of Pauli matrices in which each Pauli matrix acts on a specific mode of the tensor network state. This API function is used for defining a tensor network operator as a sum over tensor operator products with complex coefficients.
For a tensor factor with
stateModes = {q0, q1}, the tensor has2 * numStateModes = 4modes whose default (column-major) ordering is:(q0_ket, q1_ket, q0_bra, q1_bra)with strides(1, 2, 4, 8)for dimension-2 modes.Note
This mode ordering convention differs from
cutensornetStateApplyTensorOperator, which uses reversed ordering within each half. The same raw data buffer passed to both APIs with NULL strides will be interpreted differently for multi-mode operators. ExplicittensorModeStridescan be used to reconcile the two conventions. For single-mode operators (e.g., Pauli matrices), the two conventions are equivalent.Note
All user-provided tensors used to define a tensor network operator must stay alive during the entire lifetime of the tensor network operator.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkOperator – [inout] Tensor network operator.
coefficient – [in] Complex coefficient associated with the appended operator component.
numTensors – [in] Number of tensor factors in the tensor product.
numStateModes – [in] Number of state modes each appended tensor factor acts on.
stateModes – [in] Modes each appended tensor factor acts on (length =
numStateModes).tensorModeStrides – [in] Tensor mode strides for each tensor factor (length =
numStateModes* 2). If NULL, the default generalized column-major strides will be used.tensorData – [in] Tensor data stored in GPU memory for each tensor factor.
componentId – [out] Unique sequential integer identifier of the appended tensor network operator component.
cutensornetNetworkOperatorAppendMPO#
- cutensornetStatus_t cutensornetNetworkOperatorAppendMPO(
- const cutensornetHandle_t handle,
- cutensornetNetworkOperator_t tensorNetworkOperator,
- cuDoubleComplex coefficient,
- int32_t numStateModes,
- const int32_t stateModes[],
- const int64_t *tensorModeExtents[],
- const int64_t *tensorModeStrides[],
- const void *tensorData[],
- cutensornetBoundaryCondition_t boundaryCondition,
- int64_t *componentId
Appends a Matrix Product Operator (MPO) component to the tensor network operator.
The modes of the MPO tensors follow the standard cuTensorNet convention (each internal MPO tensor has four modes): Mode 0: (i-1)th - (i)th connection; Mode 1: (i)th site open mode acting on the ket state mode; Mode 2: (i)th - (i+1)th connection; Mode 3: (i)th site open mode acting on the bra state mode; When the open boundary condition is requested, the first MPO tensor will have mode 0 removed while the last MPO tensor will have mode 2 removed, both having only three modes (in order).
Note
All user-provided MPO tensors used to define a tensor network operator must stay alive during the entire lifetime of the tensor network operator.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkOperator – [inout] Tensor network operator.
coefficient – [in] Complex coefficient associated with the appended operator component.
numStateModes – [in] Number of state modes the MPO acts on (number of tensors in the MPO).
stateModes – [in] State modes the MPO acts on.
tensorModeExtents – [in] Tensor mode extents for each MPO tensor.
tensorModeStrides – [in] Storage strides for each MPO tensor or NULL (default generalized column-wise strides).
tensorData – [in] Tensor data stored in GPU memory for each MPO tensor factor.
boundaryCondition – [in] MPO boundary condition.
componentId – [out] Unique sequential integer identifier of the appended tensor network operator component.
cutensornetDestroyNetworkOperator#
- cutensornetStatus_t cutensornetDestroyNetworkOperator(
- cutensornetNetworkOperator_t tensorNetworkOperator
Frees all resources owned by the tensor network operator.
- Parameters:
tensorNetworkOperator – [inout] Tensor network operator.
cutensornetCreateAccessor#
- cutensornetStatus_t cutensornetCreateAccessor(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- int32_t numProjectedModes,
- const int32_t *projectedModes,
- const int64_t *amplitudesTensorStrides,
- cutensornetStateAccessor_t *tensorNetworkAccessor
Creates a tensor network state amplitudes accessor.
The state amplitudes accessor allows the user to extract single state amplitudes (elements of the state tensor), slices of state amplitudes (slices of the state tensor) as well as the full state tensor. The choice of a specific slices is accomplished by specifying the projected modes of the tensor network state, that is, a subset of the tensor network state modes that will be projected to specific basis vectors during the computation. The rest of the tensor state modes (open modes) in their respective relative order will define the shape of the resulting state amplitudes tensor requested by the user.
Note
The provided tensor network state must stay alive during the lifetime of the state amplitudes accessor. Additionally, applying a tensor operator to the tensor network state after it was used to create the state amplitudes accessor will invalidate the state amplitudes accessor. On the other hand, simply updating tensor operator data via cutensornetStateUpdateTensorOperator() is allowed.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [in] Defined tensor network state.
numProjectedModes – [in] Number of projected state modes (tensor network state modes projected to specific basis vectors).
projectedModes – [in] Projected state modes (may be NULL when none or all modes are projected).
amplitudesTensorStrides – [in] Mode strides for the resulting amplitudes tensor. If NULL, the default generalized column-major strides will be assumed.
tensorNetworkAccessor – [out] Tensor network state amplitudes accessor.
cutensornetDestroyAccessor#
- cutensornetStatus_t cutensornetDestroyAccessor(
- cutensornetStateAccessor_t tensorNetworkAccessor
Destroyes the tensor network state amplitudes accessor.
- Parameters:
tensorNetworkAccessor – [inout] Tensor network state amplitudes accessor.
cutensornetAccessorConfigure#
- cutensornetStatus_t cutensornetAccessorConfigure(
- const cutensornetHandle_t handle,
- cutensornetStateAccessor_t tensorNetworkAccessor,
- cutensornetAccessorAttributes_t attribute,
- const void *attributeValue,
- size_t attributeSize
Configures computation of the requested tensor network state amplitudes tensor.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkAccessor – [inout] Tensor network state amplitudes accessor.
attribute – [in] Configuration attribute.
attributeValue – [in] Pointer to the configuration attribute value (type-erased).
attributeSize – [in] The size of the configuration attribute value.
cutensornetAccessorPrepare#
- cutensornetStatus_t cutensornetAccessorPrepare(
- const cutensornetHandle_t handle,
- cutensornetStateAccessor_t tensorNetworkAccessor,
- size_t maxWorkspaceSizeDevice,
- cutensornetWorkspaceDescriptor_t workDesc,
- cudaStream_t cudaStream
Prepares computation of the requested tensor network state amplitudes tensor.
Note
The cudaStream argument is unused in the current release (can be set to 0x0).
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkAccessor – [in] Tensor network state amplitudes accessor.
maxWorkspaceSizeDevice – [in] Upper limit on the amount of available GPU scratch memory (bytes).
workDesc – [out] Workspace descriptor (the required scratch/cache memory sizes will be set).
cudaStream – [in] CUDA stream.
cutensornetAccessorGetInfo#
- cutensornetStatus_t cutensornetAccessorGetInfo(
- const cutensornetHandle_t handle,
- const cutensornetStateAccessor_t tensorNetworkAccessor,
- cutensornetAccessorAttributes_t attribute,
- void *attributeValue,
- size_t attributeSize
Retrieves an attribute related to computation of the requested tensor network state amplitudes tensor.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkAccessor – [in] Tensor network state amplitudes accessor.
attribute – [in] Information attribute.
attributeValue – [out] Pointer to the information attribute value (type-erased).
attributeSize – [in] The size of the information attribute value.
cutensornetAccessorCompute#
- cutensornetStatus_t cutensornetAccessorCompute(
- const cutensornetHandle_t handle,
- cutensornetStateAccessor_t tensorNetworkAccessor,
- const int64_t *projectedModeValues,
- cutensornetWorkspaceDescriptor_t workDesc,
- void *amplitudesTensor,
- void *stateNorm,
- cudaStream_t cudaStream
Computes the amplitudes of the tensor network state.
Note
The computed amplitudes are not normalized automatically in cases when the tensor circuit state is not guaranteed to have a unity norm. In such cases, the squared state norm is returned as a separate parameter.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The provided workspace descriptor
workDescmust have the Device Scratch buffer set explicitly since user-provided memory pools are not supported in the current release. Additionally, the attached workspace buffer must be 256-byte aligned in the current release.Warning
In the current release, the execution of this API function will synchronize the provided CUDA stream. This restriction may be released in the future.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkAccessor – [in] Tensor network state amplitudes accessor.
projectedModeValues – [in] The values of the projected state modes or NULL pointer if there are no projected modes.
workDesc – [in] Workspace descriptor (the required scratch/cache memory buffers must be set by the user).
amplitudesTensor – [inout] Storage for the computed tensor network state amplitudes tensor.
stateNorm – [out] The squared 2-norm of the underlying tensor circuit state (Host pointer). The returned scalar will have the same numerical data type as the tensor circuit state. Providing a NULL pointer will ignore norm calculation.
cudaStream – [in] CUDA stream.
cutensornetCreateExpectation#
- cutensornetStatus_t cutensornetCreateExpectation(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- cutensornetNetworkOperator_t tensorNetworkOperator,
- cutensornetStateExpectation_t *tensorNetworkExpectation
Creates a representation of the tensor network state expectation value.
The tensor network state expectation value is the expectation value of the given tensor network operator with respect to the given tensor network state. Note that the computed expectation value is unnormalized, with the norm of the tensor network state returned separately (optionally).
Note
The provided tensor network state must stay alive during the lifetime of the tensor network state expectation value. Additionally, applying a tensor operator to the tensor network state after it was used to create the tensor network state expectation value will invalidate the tensor network state expectation value. On the other hand, simply updating tensor operator data via cutensornetStateUpdateTensorOperator() is allowed.
Note
The provided tensor network operator must stay alive during the lifetime of the tensor network state expectation value. Additionally, appending new components to the tensor network operator after it was used to create the tensor network state expectation value will invalidate the tensor network state expectation value. On the other hand, simply updating the tensor data inside the tensor network operator is allowed.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [in] Defined tensor network state.
tensorNetworkOperator – [in] Defined tensor network operator.
tensorNetworkExpectation – [out] Tensor network expectation value representation.
cutensornetDestroyExpectation#
- cutensornetStatus_t cutensornetDestroyExpectation(
- cutensornetStateExpectation_t tensorNetworkExpectation
Destroyes the tensor network state expectation value representation.
- Parameters:
tensorNetworkExpectation – [inout] Tensor network state expectation value representation.
cutensornetExpectationConfigure#
- cutensornetStatus_t cutensornetExpectationConfigure(
- const cutensornetHandle_t handle,
- cutensornetStateExpectation_t tensorNetworkExpectation,
- cutensornetExpectationAttributes_t attribute,
- const void *attributeValue,
- size_t attributeSize
Configures computation of the requested tensor network state expectation value.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkExpectation – [inout] Tensor network state expectation value representation.
attribute – [in] Configuration attribute.
attributeValue – [in] Pointer to the configuration attribute value (type-erased).
attributeSize – [in] The size of the configuration attribute value.
cutensornetExpectationPrepare#
- cutensornetStatus_t cutensornetExpectationPrepare(
- const cutensornetHandle_t handle,
- cutensornetStateExpectation_t tensorNetworkExpectation,
- size_t maxWorkspaceSizeDevice,
- cutensornetWorkspaceDescriptor_t workDesc,
- cudaStream_t cudaStream
Prepares computation of the requested tensor network state expectation value.
Note
The cudaStream argument is unused in the current release (can be set to 0x0).
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkExpectation – [in] Tensor network state expectation value representation.
maxWorkspaceSizeDevice – [in] Upper limit on the amount of available GPU scratch memory (bytes).
workDesc – [out] Workspace descriptor (the required scratch/cache memory sizes will be set).
cudaStream – [in] CUDA stream.
cutensornetExpectationGetInfo#
- cutensornetStatus_t cutensornetExpectationGetInfo(
- const cutensornetHandle_t handle,
- const cutensornetStateExpectation_t tensorNetworkExpectation,
- cutensornetExpectationAttributes_t attribute,
- void *attributeValue,
- size_t attributeSize
Retrieves an attribute related to computation of the requested tensor network state expectation value.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkExpectation – [in] Tensor network state expectation value representation.
attribute – [in] Information attribute.
attributeValue – [out] Pointer to the information attribute value (type-erased).
attributeSize – [in] The size of the information attribute value.
cutensornetExpectationCompute#
- cutensornetStatus_t cutensornetExpectationCompute(
- const cutensornetHandle_t handle,
- cutensornetStateExpectation_t tensorNetworkExpectation,
- cutensornetWorkspaceDescriptor_t workDesc,
- void *expectationValue,
- void *stateNorm,
- cudaStream_t cudaStream
Computes an (unnormalized) expectation value of a given tensor network operator over a given tensor network state.
Note
The computed expectation value is not normalized automatically in cases when the tensor network state is not guaranteed to have a unity norm. In such cases, the squared state norm is returned as a separate parameter. The true tensor network state expectation value can then be obtained by dividing the returned unnormalized expectation value by the returned squared state norm.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The provided workspace descriptor
workDescmust have the Device Scratch buffer set explicitly since user-provided memory pools are not supported in the current release. Additionally, the attached workspace buffer must be 256-byte aligned in the current release.Warning
In the current release, the execution of this API function will synchronize the provided CUDA stream. This restriction may be released in the future.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkExpectation – [in] Tensor network state expectation value representation.
workDesc – [in] Workspace descriptor (the required scratch/cache memory buffers must be set by the user).
expectationValue – [out] Computed unnormalized tensor network state expectation value (Host pointer). The returned scalar will have the same numerical data type as the tensor circuit state.
stateNorm – [out] The squared 2-norm of the underlying tensor circuit state (Host pointer). The returned scalar will have the same numerical data type as the tensor circuit state. Providing a NULL pointer will ignore norm calculation.
cudaStream – [in] CUDA stream.
cutensornetExpectationComputeWithGradientsBackward#
- cutensornetStatus_t cutensornetExpectationComputeWithGradientsBackward(
- const cutensornetHandle_t handle,
- cutensornetStateExpectation_t tensorNetworkExpectation,
- int32_t accumulateGradients,
- const void *expectationValueAdjoint,
- const void *stateNormAdjoint,
- cutensornetWorkspaceDescriptor_t workDesc,
- void *expectationValue,
- void *stateNorm,
- cudaStream_t cudaStream
Computes the tensor network state expectation value and its gradients together.
Computes the expectation value \( E = \langle\psi|H|\psi\rangle \) and its gradients \( \partial E / \partial A_j \) for all tensor operators \( A_j \) applied via
cutensornetStateApplyTensorOperatorWithGradient.Gradients have the same shape as the corresponding tensor operators and are written to the device buffers specified when
cutensornetStateApplyTensorOperatorWithGradientwas called.Requires SCRATCH workspace to be set. Use
cutensornetWorkspaceGetMemorySizewith CUTENSORNET_WORKSPACE_SCRATCH to query the required scratch workspace size after prepare.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
In the current release,
stateNormandstateNormAdjointmust be NULL; otherwise CUTENSORNET_STATUS_NOT_SUPPORTED is returned.Warning
In the current release, gradient computation is only supported when all gates in the circuit are unitary. If any gate is non-unitary,
cutensornetExpectationPrepareor this function returns CUTENSORNET_STATUS_NOT_SUPPORTED.Warning
In the current release, gradient computation is not supported in distributed execution.
Warning
Requires at least one tensor operator to be applied via
cutensornetStateApplyTensorOperatorWithGradientbefore callingcutensornetExpectationPrepare.- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkExpectation – [in] Tensor network state expectation value representation.
accumulateGradients – [in] If non-zero, add to existing gradient values; otherwise overwrite.
expectationValueAdjoint – [in] Upstream gradient scalar for chain rule computation (host-accessible pointer, same type as state). Set to 1 for direct gradient \( \partial E / \partial A_j \).
stateNormAdjoint – [in] Upstream gradient for state norm in chain rule (host-accessible pointer, same type as state).
workDesc – [in] The workspace descriptor with SCRATCH workspace set.
expectationValue – [out] Computed expectation value (host-accessible pointer, same type as state).
stateNorm – [out] Host-accessible pointer to store the squared 2-norm of the state.
cudaStream – [in] The CUDA stream on which the computation is performed.
cutensornetCreateMarginal#
- cutensornetStatus_t cutensornetCreateMarginal(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- int32_t numMarginalModes,
- const int32_t *marginalModes,
- int32_t numProjectedModes,
- const int32_t *projectedModes,
- const int64_t *marginalTensorStrides,
- cutensornetStateMarginal_t *tensorNetworkMarginal
Creates a representation of the specified marginal tensor for a given tensor network state.
The tensor network state marginal tensor is formed by a direct product of the tensor network state with its dual (conjugated) state, followed by a trace over all state modes except the explicitly specified so-called open state modes. The order of the specified open state modes will be respected when computing the tensor network state marginal tensor. Additionally, prior to tracing, some of the state modes can optionally be projected to specific individual basis states of those modes, thus forming the so-called projected modes which will not be involved in tracing. Note that the resulting marginal tensor will have twice more modes than the number of the specified open modes, first half coming from the primary direct-product space while the second half symmetrically coming from the dual (conjugate) space.
Note
In the quantum domain, the marginal tensor is known as the reduced density matrix. For example, in quantum circuit simulations, the reduced density matrix is specified by the state modes which are kept intact and the remaining state modes which are traced over. Additionally, prior to tracing, one can project certain qudit modes to specific individual basis states of those modes, resulting in a projected reduced density matrix.
Note
The provided tensor network state must stay alive during the lifetime of the tensor network state marginal. Additionally, applying a tensor operator to the tensor network state after it was used to create the tensor network state marginal will invalidate the tensor network state marginal. On the other hand, simply updating tensor operator data via cutensornetStateUpdateTensorOperator() is allowed.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [in] Tensor network state.
numMarginalModes – [in] Number of open state modes defining the marginal tensor.
marginalModes – [in] Pointer to the open state modes defining the marginal tensor.
numProjectedModes – [in] Number of projected state modes.
projectedModes – [in] Pointer to the projected state modes.
marginalTensorStrides – [in] Storage strides for the marginal tensor (number of tensor modes is twice the number of the defining open modes). If NULL, the defaul generalized column-major strides will be assumed.
tensorNetworkMarginal – [out] Tensor network state marginal.
cutensornetDestroyMarginal#
- cutensornetStatus_t cutensornetDestroyMarginal(
- cutensornetStateMarginal_t tensorNetworkMarginal
Destroys the tensor network state marginal.
- Parameters:
tensorNetworkMarginal – [in] Tensor network state marginal representation.
cutensornetMarginalConfigure#
- cutensornetStatus_t cutensornetMarginalConfigure(
- const cutensornetHandle_t handle,
- cutensornetStateMarginal_t tensorNetworkMarginal,
- cutensornetMarginalAttributes_t attribute,
- const void *attributeValue,
- size_t attributeSize
Configures computation of the requested tensor network state marginal tensor.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkMarginal – [inout] Tensor network state marginal representation.
attribute – [in] Configuration attribute.
attributeValue – [in] Pointer to the configuration attribute value (type-erased).
attributeSize – [in] The size of the configuration attribute value.
cutensornetMarginalPrepare#
- cutensornetStatus_t cutensornetMarginalPrepare(
- const cutensornetHandle_t handle,
- cutensornetStateMarginal_t tensorNetworkMarginal,
- size_t maxWorkspaceSizeDevice,
- cutensornetWorkspaceDescriptor_t workDesc,
- cudaStream_t cudaStream
Prepares computation of the requested tensor network state marginal tensor.
Note
The cudaStream argument is unused in the current release (can be set to 0x0).
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkMarginal – [in] Tensor network state marginal representation.
maxWorkspaceSizeDevice – [in] Upper limit on the amount of available GPU scratch memory (bytes).
workDesc – [out] Workspace descriptor (the required scratch/cache memory sizes will be set).
cudaStream – [in] CUDA stream.
cutensornetMarginalGetInfo#
- cutensornetStatus_t cutensornetMarginalGetInfo(
- const cutensornetHandle_t handle,
- const cutensornetStateMarginal_t tensorNetworkMarginal,
- cutensornetMarginalAttributes_t attribute,
- void *attributeValue,
- size_t attributeSize
Retrieves an attribute related to computation of the requested tensor network state marginal tensor.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkMarginal – [in] Tensor network state marginal representation.
attribute – [in] Information attribute.
attributeValue – [out] Pointer to the information attribute value (type-erased).
attributeSize – [in] The size of the information attribute value.
cutensornetMarginalCompute#
- cutensornetStatus_t cutensornetMarginalCompute(
- const cutensornetHandle_t handle,
- cutensornetStateMarginal_t tensorNetworkMarginal,
- const int64_t *projectedModeValues,
- cutensornetWorkspaceDescriptor_t workDesc,
- void *marginalTensor,
- cudaStream_t cudaStream
Computes the requested tensor network state marginal tensor.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The provided workspace descriptor
workDescmust have the Device Scratch buffer set explicitly since user-provided memory pools are not supported in the current release. Additionally, the attached workspace buffer must be 256-byte aligned in the current release.Warning
In the current release, the execution of this API function will synchronize the provided CUDA stream. This restriction may be released in the future.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkMarginal – [in] Tensor network state marginal representation.
projectedModeValues – [in] Pointer to the values of the projected modes. Each integer value corresponds to a basis state of the given (projected) state mode.
workDesc – [in] Workspace descriptor (the required scratch/cache memory buffers must be set by the user).
marginalTensor – [out] Pointer to the GPU storage of the marginal tensor which will be computed in this call.
cudaStream – [in] CUDA stream.
cutensornetCreateSampler#
- cutensornetStatus_t cutensornetCreateSampler(
- const cutensornetHandle_t handle,
- cutensornetState_t tensorNetworkState,
- int32_t numModesToSample,
- const int32_t *modesToSample,
- cutensornetStateSampler_t *tensorNetworkSampler
Creates a tensor network state sampler.
A tensor network state sampler produces samples from the state tensor with the probability equal to the squared absolute value of the corresponding element of the state tensor. One can also choose any subset of tensor network state modes to sample only from the subspace spanned by them. The order of specified state modes will be respected when producing the output samples.
Note
For the purpose of quantum circuit simulations, the tensor network state sampler can generate bit-strings (or qudit-strings) from the output state of the defined quantum circuit (i.e., the tensor network defined by gate applications).
Note
The provided tensor network state must stay alive during the lifetime of the tensor network state sampler. Additionally, applying a tensor operator to the tensor network state after it was used to create the tensor network state sampler will invalidate the tensor network state sampler. On the other hand, simply updating tensor operator data via cutensornetStateUpdateTensorOperator() is allowed.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkState – [in] Tensor network state.
numModesToSample – [in] Number of the tensor network state modes to sample from.
modesToSample – [in] Pointer to the state modes to sample from (can be NULL when all modes are requested).
tensorNetworkSampler – [out] Tensor network sampler.
cutensornetDestroySampler#
- cutensornetStatus_t cutensornetDestroySampler(
- cutensornetStateSampler_t tensorNetworkSampler
Destroys the tensor network state sampler.
- Parameters:
tensorNetworkSampler – [in] Tensor network state sampler.
cutensornetSamplerConfigure#
- cutensornetStatus_t cutensornetSamplerConfigure(
- const cutensornetHandle_t handle,
- cutensornetStateSampler_t tensorNetworkSampler,
- cutensornetSamplerAttributes_t attribute,
- const void *attributeValue,
- size_t attributeSize
Configures the tensor network state sampler.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkSampler – [inout] Tensor network state sampler.
attribute – [in] Configuration attribute.
attributeValue – [in] Pointer to the configuration attribute value (type-erased).
attributeSize – [in] The size of the configuration attribute value.
cutensornetSamplerPrepare#
- cutensornetStatus_t cutensornetSamplerPrepare(
- const cutensornetHandle_t handle,
- cutensornetStateSampler_t tensorNetworkSampler,
- size_t maxWorkspaceSizeDevice,
- cutensornetWorkspaceDescriptor_t workDesc,
- cudaStream_t cudaStream
Prepares the tensor network state sampler.
Note
The cudaStream argument is unused in the current release (can be set to 0x0).
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkSampler – [in] Tensor network state sampler.
maxWorkspaceSizeDevice – [in] Upper limit on the amount of available GPU scratch memory (bytes).
workDesc – [out] Workspace descriptor (the required scratch/cache memory sizes will be set).
cudaStream – [in] CUDA stream.
cutensornetSamplerGetInfo#
- cutensornetStatus_t cutensornetSamplerGetInfo(
- const cutensornetHandle_t handle,
- const cutensornetStateSampler_t tensorNetworkSampler,
- cutensornetSamplerAttributes_t attribute,
- void *attributeValue,
- size_t attributeSize
Retrieves an attribute related to tensor network state sampling.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkSampler – [in] Tensor network state sampler.
attribute – [in] Information attribute.
attributeValue – [out] Pointer to the information attribute value (type-erased).
attributeSize – [in] The size of the information attribute value.
cutensornetSamplerSample#
- cutensornetStatus_t cutensornetSamplerSample(
- const cutensornetHandle_t handle,
- cutensornetStateSampler_t tensorNetworkSampler,
- int64_t numShots,
- cutensornetWorkspaceDescriptor_t workDesc,
- int64_t *samples,
- cudaStream_t cudaStream
Performs sampling of the tensor network state, that is, generates the requested number of samples.
Note
The pseudo-random number generator used internally is initialized with a random default seed, thus generally resulting in a different set of samples generated upon each repeated execution. In future, the ability to reset the seed to a user-defined value may be provided, to ensure generation of exactly the same set of samples upon rerunning the application repeatedly (this could be useful for debugging).
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
The provided workspace descriptor
workDescmust have the Device Scratch buffer set explicitly since user-provided memory pools are not supported in the current release. Additionally, the attached workspace buffer must be 256-byte aligned in the current release.Warning
In the current release, the execution of this API function will synchronize the provided CUDA stream. This restriction may be released in the future.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkSampler – [in] Tensor network state sampler.
numShots – [in] Number of samples to generate.
workDesc – [in] Workspace descriptor (the required scratch/cache memory buffers must be set by the user).
samples – [out] Host memory pointer where the generated state tensor samples will be stored at. The samples will be stored as samples[SampleId][ModeId] in C notation and the originally specified order of the tensor network state modes to sample from will be respected.
cudaStream – [in] CUDA stream.
State projection MPS API#
cutensornetCreateStateProjectionMPS#
- cutensornetStatus_t cutensornetCreateStateProjectionMPS(
- const cutensornetHandle_t handle,
- int32_t numStates,
- const cutensornetState_t tensorNetworkStates[],
- const cuDoubleComplex coeffs[],
- int32_t symmetric,
- int32_t numEnvs,
- const cutensornetMPSEnvBounds_t specEnvs[],
- cutensornetBoundaryCondition_t boundaryCondition,
- int32_t numTensors,
- const int32_t quditsPerTensor[],
- const int64_t *extentsOut[],
- const int64_t *stridesOut[],
- void *dualTensorsDataOut[],
- const cutensornetMPSEnvBounds_t *orthoSpec,
- cutensornetStateProjectionMPS_t *tensorNetworkProjection
Creates an accumulative matrix product state (MPS) projection of a set of tensor network states.
A tensor network state MPS projection allows to project a weighted sum of tensor network states into subspaces of an MPS. This API enables, for example, to variationally determine a compressed MPS representation of the weighted sum of tensor network states. The projection is computed by accumulating the contraction of each tensor network state with the dual (conjugated) tensors of the MPS, with the exception of a set of adjacent MPS tensors which are absent from the network to be contracted, referred to as environment in the following.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
numStates – [in] Number of tensor network states for which the MPS projection is computed. Currently only a single tensor network state is supported.
tensorNetworkStates – [in] Tensor network states.
coeffs – [in] CPU accessible pointer to scalar coefficients for each tensor network state. If the tensor network states are of real datatype, the complex component of the coefficients will be ignored. A nullptr for this argument will be interpreted as unit coefficient for all network states.
symmetric – [in] Whether or not the initial state of all tensor network states is defined by the values of the dual MPS tensors (in case of a symmetric MPS functional).
numEnvs – [in] Number of requested environments.
specEnvs – [in] Specification of each requested environment. Environments are specified by providing the qudit indices to the left and right of the excluded MPS tensors. Note that currently only 0-site and 1-site environments are supported.
boundaryCondition – [in] Boundary condition of the MPS. Currently only open boundary condition MPS are supported.
numTensors – [in] Number of tensors contained in the MPS. Currently, numTensors must be equal to the number of qudits in the MPS.
quditsPerTensor – [in] Number of consecutive qudits in each MPS tensor. Currently, quditsPerTensor must be equal to 1. A nullptr for this argument will be interpreted as a single qudit per tensor.
extentsOut – [in] Maximum mode extents of all dual MPS output tensors, passed as array of length number of qudits, holding pointer to integer arrays. For pure states all extent arrays are of length 3, with the exception of open boundary condition MPS for which the first and last extent arrays are of length 2.
stridesOut – [in] Strides of all dual MPS output tensors, passed as array of length number of qudits, holding pointer to integer arrays. For pure states all stride arrays are of length 3, with the exception of open boundary condition MPS for which the first and last stride array are of length 2.
dualTensorsDataOut – [inout] GPU-accessible pointers for storing dual MPS tensors. May be nullptr to defer data pointer assignment until cutensornetStateProjectionMPSUpdateDualTensors() is called. Individual elements dualTensorsDataOut[i] may also be nullptr to defer assignment for specific tensors. Note that the MPS tensors residing in these data buffers are not conjugated, and will be conjugated on-the-fly during the environment contraction. cutensornetStateProjectionMPSExtractTensor() and cutensornetStateProjectionMPSInsertTensor() have side effects on the provided data.
orthoSpec – [in] Specification of the orthogonality conditions on the provided MPS tensors. A nullptr for this argument will default to an orthogonality region spanning the whole MPS. The orthoSpec must span at least one site (upperBound - lowerBound >= 2).
tensorNetworkProjection – [out] MPS projection of a set of tensor network states.
- Returns:
cutensornetStatus_t
cutensornetStateProjectionMPSConfigure#
- cutensornetStatus_t cutensornetStateProjectionMPSConfigure(
- const cutensornetHandle_t handle,
- cutensornetStateProjectionMPS_t tensorNetworkProjection,
- cutensornetStateProjectionMPSAttributes_t attribute,
- const void *attributeValue,
- size_t attributeSize
Configures computation of the requested tensor network state MPS projection.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkProjection – [inout] Tensor network state MPS projection.
attribute – [in] Configuration attribute.
attributeValue – [in] Pointer to the configuration attribute value (type-erased).
attributeSize – [in] The size of the configuration attribute value.
- Returns:
cutensornetStatus_t
cutensornetStateProjectionMPSPrepare#
- cutensornetStatus_t cutensornetStateProjectionMPSPrepare(
- const cutensornetHandle_t handle,
- cutensornetStateProjectionMPS_t tensorNetworkProjection,
- size_t maxWorkspaceSizeDevice,
- cutensornetWorkspaceDescriptor_t workDesc,
- cudaStream_t cudaStream
Prepares computation of the requested tensor network state MPS projection.
Note
The cudaStream argument is unused in the current release (can be set to 0x0).
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkProjection – [in] Tensor network state MPS projection.
maxWorkspaceSizeDevice – [in] Upper limit on the amount of available GPU scratch memory (bytes).
workDesc – [out] Workspace descriptor (the required scratch/cache memory sizes will be set).
cudaStream – [in] CUDA stream.
- Returns:
cutensornetStatus_t
cutensornetStateProjectionMPSComputeTensorEnv#
- cutensornetStatus_t cutensornetStateProjectionMPSComputeTensorEnv(
- const cutensornetHandle_t handle,
- cutensornetStateProjectionMPS_t tensorNetworkProjection,
- const cutensornetMPSEnvBounds_t *envSpec,
- const int64_t stridesIn[],
- const void *envTensorDataIn,
- const int64_t stridesOut[],
- void *envTensorDataOut,
- int32_t applyInvMetric,
- int32_t reResolveChannels,
- cutensornetWorkspaceDescriptor_t workDesc,
- cudaStream_t cudaStream
Computes the projection for the specified environment.
This function may only be called during a compute cycle (between
cutensornetStateProjectionMPSExtractTensorandcutensornetStateProjectionMPSInsertTensor).Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkProjection – [inout] Tensor network state MPS projection.
envSpec – [in] Specification of the requested environment. Note that currently only 0-site and 1-site environments are supported.
stridesIn – [in] Strides of the provided MPS representation tensor for the specified environment. A nullptr for this argument will use default (column-major) strides. Required to be a nullptr if MPS projection is not symmetric.
envTensorDataIn – [in] Optional input value (GPU-accessible pointer) for tensor to replace part of the initial state in the environment. The extents of the tensor are identical to the output tensor extents and it will replace the MPS tensors in between the lower and upper bounds of specified environment. Required to be a nullptr if MPS projection is not symmetric.
stridesOut – [in] Strides of the output tensor environment for the specified environment. A nullptr for this argument will use default (column-major) strides.
envTensorDataOut – [out] Computed tensor environment for the specified contiguous subset of sites (GPU-accessible pointer). The provided buffer will be conjugated on-the-fly during the environment contraction.
applyInvMetric – [in] Whether or not to apply the inverse metric of the MPS state with respect to the environment to the computed tensor environment. Currently application of the inverse metric is not supported.
reResolveChannels – [in] Whether or not to reresolve the channels of the computed tensor environment on compute call. If true, the behaviour aligns with that of other State API properties computed on a State instance for which StateCompute has not yet been invoked. If false, the behaviour aligns with that of other State API properties computed on a State instance for which StateCompute has already been invoked.
workDesc – [inout] Allocated workspace descriptor.
cudaStream – [in] CUDA stream.
- Returns:
cutensornetStatus_t
cutensornetStateProjectionMPSGetTensorInfo#
- cutensornetStatus_t cutensornetStateProjectionMPSGetTensorInfo(
- const cutensornetHandle_t handle,
- const cutensornetStateProjectionMPS_t tensorNetworkProjection,
- const cutensornetMPSEnvBounds_t *envSpec,
- int64_t extents[],
- int64_t recommendedStrides[]
Queries the tensor dimension strides and extents for the MPS representation tensor for the specified contiguous 0-, 1-, or 2-site subset of sites.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkProjection – [in] Tensor network state MPS projection.
envSpec – [in] Specification of the environment for which the tensor metadata is requested. Note that currently only 0-site and 1-site environments are supported.
extents – [out] Mode extents of the environment MPS tensor. For pure states, the required length of the array is n+2 for an n-site environment specified by envSpec, except for environments which comprise the boundary for open boundary conditions, which are of length n+1. Note that currently only 0-site and 1-site environments are supported.
recommendedStrides – [out] Recommended strides of the environment MPS tensor, of the same length as the extents array. Using the recommended strides may offer performance benefits.
- Returns:
cutensornetStatus_t
cutensornetStateProjectionMPSExtractTensor#
- cutensornetStatus_t cutensornetStateProjectionMPSExtractTensor(
- const cutensornetHandle_t handle,
- cutensornetStateProjectionMPS_t tensorNetworkProjection,
- const cutensornetMPSEnvBounds_t *envSpec,
- const int64_t strides[],
- void *envTensorData,
- cutensornetWorkspaceDescriptor_t workDesc,
- cudaStream_t cudaStream
Extracts the MPS representation tensor for the specified contiguous 0-, 1-, or 2-site subset of sites.
After calling this function, the caller must call
cutensornetStateProjectionMPSInsertTensorbefore callingcutensornetStateProjectionMPSExtractTensororcutensornetStateProjectionMPSUpdateDualTensorsagain. Between extract and insert,cutensornetStateProjectionMPSComputeTensorEnvmay be called to compute the environment tensor.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkProjection – [inout] Tensor network state MPS projection.
envSpec – [in] Specification of environment. The environment has to have been requested during the creation of the tensor network state MPS projection. Note that currently only 0-site and 1-site environments are supported.
strides – [in] Strides of the externally provided MPS representation tensor for the specified environment. A nullptr for this argument will use default (column-major) strides.
envTensorData – [out] The computed tensor of the MPS representation for the specified environment will be written to this buffer with the provided strides. Extents of the provided buffer need to be queried using cutensornetStateProjectionMPSGetTensorInfo().
workDesc – [inout] Allocated workspace descriptor.
cudaStream – [in] CUDA stream.
- Returns:
cutensornetStatus_t
cutensornetStateProjectionMPSInsertTensor#
- cutensornetStatus_t cutensornetStateProjectionMPSInsertTensor(
- const cutensornetHandle_t handle,
- cutensornetStateProjectionMPS_t tensorNetworkProjection,
- const cutensornetMPSEnvBounds_t *envSpec,
- const cutensornetMPSEnvBounds_t *orthoSpec,
- const int64_t strides[],
- const void *envTensorData,
- cutensornetWorkspaceDescriptor_t workDesc,
- cudaStream_t cudaStream
Inserts the MPS representation tensor for the specified contiguous 0-, 1-, or 2-site subset of sites.
This function concludes a compute cycle initiated by
cutensornetStateProjectionMPSExtractTensor. After calling this function,cutensornetStateProjectionMPSExtractTensorandcutensornetStateProjectionMPSUpdateDualTensorsmay be called again.Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkProjection – [inout] Tensor network state MPS projection.
envSpec – [in] Specification of environment.
orthoSpec – [in] Specification of the orthogonality condition of the MPS after insertion. For insertion of a 1-site environment, this argument is currently required to be identical to envSpec. For insertion of a 0-site environment, the orthogonality center must be a 1-site region adjacent to the bond.
strides – [in] Strides of the externally provided MPS representation tensor for the specified environment. A nullptr for this argument will use default (column-major) strides.
envTensorData – [in] Externally provided MPS representation tensor for the specified environment. If the projection MPS is configured with two-site environments, extents may have changed after insertion of tensors and need to be queried using cutensornetStateProjectionMPSGetTensorInfo().
workDesc – [inout] Allocated workspace descriptor.
cudaStream – [in] CUDA stream.
- Returns:
cutensornetStatus_t
cutensornetStateProjectionMPSUpdateCoefficients#
- cutensornetStatus_t cutensornetStateProjectionMPSUpdateCoefficients(
- const cutensornetHandle_t handle,
- cutensornetStateProjectionMPS_t tensorNetworkProjection,
- int32_t numCoeffs,
- const cuDoubleComplex coeffs[]
Updates the coefficients of a tensor network state MPS projection.
Note
This routine may be called multiple times to change the coefficients over the lifetime of the projection object.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkProjection – [in] MPS projection of a set of tensor network states.
numCoeffs – [in] Number of scalar coefficients provided. Must be equal to numStates supplied to cutensornetCreateStateProjectionMPS().
coeffs – [in] CPU-accessible pointer to scalar coefficients for each tensor network state.
- Returns:
cutensornetStatus_t
cutensornetStateProjectionMPSUpdateDualTensors#
- cutensornetStatus_t cutensornetStateProjectionMPSUpdateDualTensors(
- const cutensornetHandle_t handle,
- cutensornetStateProjectionMPS_t tensorNetworkProjection,
- const int64_t *maxExtents[],
- const int64_t *validExtents[],
- const int64_t *strides[],
- void *dualTensorsData[],
- const cutensornetMPSEnvBounds_t *orthoSpec,
- cudaStream_t cudaStream
Updates the dual MPS tensor buffers used by the MPS projection.
This function cannot be called during a compute cycle (between
cutensornetStateProjectionMPSExtractTensorandcutensornetStateProjectionMPSInsertTensor).Note
Currently only matching extents are supported: both maxExtents and validExtents must equal the creation-time extents.
Note
Ensuring that orthoSpec correctly describes the orthogonality structure of the updated MPS tensors is the caller’s responsibility.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] cuTensorNet library handle.
tensorNetworkProjection – [inout] Tensor network state MPS projection.
maxExtents – [in] Extents describing the allocated buffer capacity for each dual MPS tensor, passed as array of length number MPS tensors (currently equal to number of qudits), holding pointers to integer arrays. May not be nullptr at the top level. Individual elements maxExtents[i] may be nullptr, meaning “buffer extents for site i match the creation-time extents”. Currently maxExtents must match the extents passed to
cutensornetCreateStateProjectionMPS; mismatches return CUTENSORNET_STATUS_NOT_SUPPORTED.validExtents – [in] Extents describing the valid data region within each buffer, passed as array of length number MPS tensors, holding pointers to integer arrays. May not be nullptr at the top level. Individual elements validExtents[i] may be nullptr, meaning “valid extents for site i match the creation-time extents”. Currently validExtents must match the creation-time extents; mismatches return CUTENSORNET_STATUS_NOT_SUPPORTED.
strides – [in] Strides of all dual MPS tensors, passed as array of length number MPS tensors, holding pointer to integer arrays. May be nullptr to use default (column-major) strides for all tensors. Individual elements strides[i] may also be nullptr to use default strides for tensor i. For pure states all stride arrays are of length 3, with the exception of open boundary condition MPS for which the first and last stride array are of length 2. Note that currently strides needs to match the strides passed to the
cutensornetCreateStateProjectionMPScall.dualTensorsData – [in] GPU-accessible pointers for all dual MPS tensor buffers. Individual elements dualTensorsData[i] may be nullptr to keep the existing data pointer for site i. If dualTensorsData[i] is nullptr and site i has no existing data pointer, CUTENSORNET_STATUS_INVALID_VALUE is returned.
orthoSpec – [in] Specification of the orthogonality condition of the MPS after the update.
cudaStream – [in] CUDA stream.
- Returns:
cutensornetStatus_t
cutensornetDestroyStateProjectionMPS#
- cutensornetStatus_t cutensornetDestroyStateProjectionMPS(
- cutensornetStateProjectionMPS_t tensorNetworkProjection
Destroys the tensor network state MPS projection.
- Parameters:
tensorNetworkProjection – [in] Tensor network state MPS projection.
Memory management API#
A stream-ordered memory allocator (or mempool for short) allocates/deallocates memory asynchronously from/to a mempool in a
stream-ordered fashion, meaning memory operations and computations enqueued on the streams have a well-defined inter- and intra-
stream dependency. There are several well-implemented stream-ordered mempools available, such as cudaMemPool_t that is built-in
at the CUDA driver level since CUDA 11.2 (so that all CUDA applications in the same process can easily share the same pool,
see here) and the RAPIDS
Memory Manager (RMM). For a detailed introduction, see the NVIDIA Developer Blog.
The new device memory handler APIs allow users to bind a stream-ordered mempool to the library handle, such that cuTensorNet can take care of most of the memory management for users. Below is an illustration of what can be done:
MyMemPool pool = MyMemPool(); // kept alive for the entire process in real apps
int my_alloc(void* ctx, void** ptr, size_t size, cudaStream_t stream) {
// assuming this is the memory allocation routine provided by my mempool
return reinterpret_cast<MyMemPool*>(ctx)->alloc(ptr, size, stream);
}
int my_dealloc(void* ctx, void* ptr, size_t size, cudaStream_t stream) {
// assuming this is the memory deallocation routine provided by my mempool
return reinterpret_cast<MyMemPool*>(ctx)->dealloc(ptr, size, stream);
}
// create a mem handler and fill in the required members for the library to use
cutensornetDeviceMemHandler_t handler;
handler.ctx = reinterpret_cast<void*>(&pool);
handler.device_alloc = my_alloc;
handler.device_free = my_dealloc;
memcpy(handler.name, std::string("my pool").c_str(), CUTENSORNET_ALLOCATOR_NAME_LEN);
// bind the handler to the library handle
cutensornetSetDeviceMemHandler(handle, &handler);
/* ... perform the network creation & optimization as usual ... */
// create a workspace descriptor
cutensornetWorkspaceDescriptor_t workDesc;
// (this step is optional and workDesc can be set to NULL if one just wants
// to use the "recommended" workspace size)
cutensornetCreateWorkspaceDescriptor(handle, &workDesc);
// User doesn’t compute the required sizes
// User doesn’t query the workspace size (but one can if desired)
// User doesn’t allocate memory!
// User sets workspacePtr=NULL for the corresponding memory space (device, in this case) to indicate the library should
// draw memory (of the "recommended" size, if the workspace size is set to 0 as shown below) from the user's pool;
// if a nonzero size is set, we would use the given size instead of the recommended one.
// (this step is also optional if workDesc has been set to NULL)
cutensornetWorkspaceSetMemory(handle, workDesc, CUTENSORNET_MEMSPACE_DEVICE, CUTENSORNET_WORKSPACE_SCRATCH, NULL, 0);
// create a contraction plan
cutensornetContractionPlan_t plan;
cutensornetCreateContractionPlan(handle, descNet, optimizerInfo, workDesc, &plan);
// autotune the plan with the workspace
cutensornetContractionAutotune(handle, plan, rawDataIn, rawDataOut, workDesc, pref, stream);
// perform actual contraction with the workspace
for (int sliceId=0; sliceId<num_slices; sliceId++) {
cutensornetContraction(
handle, plan, rawDataIn, rawDataOut, workDesc, sliceId, stream);
}
// clean up
cutensornetDestroyContractionPlan(plan);
cutensornetDestroyWorkspaceDescriptor(workDesc); // optional if workDesc has been set to NULL
// User doesn’t deallocate memory!
As shown above, several calls to the workspace-related APIs can be skipped. Moreover, allowing the library to share your memory pool not only can alleviate potential memory conflicts, but also enable possible optimizations.
Note
In the current release, only a device mempool can be bound.
cutensornetSetDeviceMemHandler#
- cutensornetStatus_t cutensornetSetDeviceMemHandler(
- cutensornetHandle_t handle,
- const cutensornetDeviceMemHandler_t *devMemHandler
Set the current device memory handler.
Once set, when cuTensorNet needs device memory in various API calls it will allocate from the user-provided memory pool and deallocate at completion. See cutensornetDeviceMemHandler_t and APIs that require cutensornetWorkspaceDescriptor_t for further detail.
The internal stream order is established using the user-provided stream passed to cutensornetContractionAutotune() and cutensornetContraction().
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
Warning
It is undefined behavior for the following scenarios:
the library handle is bound to a memory handler and subsequently to another handler
the library handle outlives the attached memory pool
the memory pool is not stream-ordered
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
devMemHandler – [in] the device memory handler that encapsulates the user’s mempool. The struct content is copied internally.
cutensornetGetDeviceMemHandler#
- cutensornetStatus_t cutensornetGetDeviceMemHandler(
- const cutensornetHandle_t handle,
- cutensornetDeviceMemHandler_t *devMemHandler
Get the current device memory handler.
Note
Requires an active CUDA capable device and a properly created cuTensorNet handle, returns CUTENSORNET_STATUS_NOT_INITIALIZED otherwise.
- Parameters:
handle – [in] Opaque handle holding cuTensorNet’s library context.
devMemHandler – [out] If previously set, the struct pointed to by
handleris filled in, otherwise CUTENSORNET_STATUS_NO_DEVICE_ALLOCATOR is returned.
Error management API#
cutensornetGetErrorString#
-
const char *cutensornetGetErrorString(cutensornetStatus_t error)#
Returns the description string for an error code.
Remark
non-blocking, no reentrant, and thread-safe
- Parameters:
error – [in] Error code to convert to string.
- Returns:
the error string
Logger API#
cutensornetLoggerSetCallback#
- cutensornetStatus_t cutensornetLoggerSetCallback(
- cutensornetLoggerCallback_t callback
This function sets the logging callback routine.
- Parameters:
callback – [in] Pointer to a callback function. Check cutensornetLoggerCallback_t.
cutensornetLoggerSetCallbackData#
- cutensornetStatus_t cutensornetLoggerSetCallbackData(
- cutensornetLoggerCallbackData_t callback,
- void *userData
This function sets the logging callback routine, along with user data.
- Parameters:
callback – [in] Pointer to a callback function. Check cutensornetLoggerCallbackData_t.
userData – [in] Pointer to user-provided data to be used by the callback.
cutensornetLoggerSetFile#
-
cutensornetStatus_t cutensornetLoggerSetFile(FILE *file)#
This function sets the logging output file.
- Parameters:
file – [in] An open file with write permission.
cutensornetLoggerOpenFile#
-
cutensornetStatus_t cutensornetLoggerOpenFile(const char *logFile)#
This function opens a logging output file in the given path.
- Parameters:
logFile – [in] Path to the logging output file.
cutensornetLoggerSetLevel#
-
cutensornetStatus_t cutensornetLoggerSetLevel(int32_t level)#
This function sets the value of the logging level.
- Parameters:
level – [in] Log level, should be one of the following:
Level
Summary
Long Description
“0”
Off
logging is disabled (default)
“1”
Errors
only errors will be logged
“2”
Performance Trace
API calls that launch CUDA kernels will log their parameters and important information
“3”
Performance Hints
hints that can potentially improve the application’s performance
“4”
Heuristics Trace
provides general information about the library execution, may contain details about heuristic status
“5”
API Trace
API Trace - API calls will log their parameter and important information
cutensornetLoggerSetMask#
-
cutensornetStatus_t cutensornetLoggerSetMask(int32_t mask)#
This function sets the value of the log mask.
Refer to cutensornetLoggerSetLevel() for details.
- Parameters:
mask – [in] Value of the logging mask. Masks are defined as a combination (bitwise OR) of the following masks:
Level
Description
“0”
Off
“1”
Errors
“2”
Performance Trace
“4”
Performance Hints
“8”
Heuristics Trace
“16”
API Trace
cutensornetLoggerForceDisable#
-
cutensornetStatus_t cutensornetLoggerForceDisable()#
This function disables logging for the entire run.
Versioning API#
cutensornetGetVersion#
-
size_t cutensornetGetVersion()#
Returns Version number of the cuTensorNet library.
cutensornetGetCudartVersion#
-
size_t cutensornetGetCudartVersion()#
Returns version number of the CUDA runtime that cuTensorNet was compiled against.
Can be compared against the CUDA runtime version from cudaRuntimeGetVersion().