Examples#
In this section, we show how to contract a tensor network using cuTensorNet. First, we describe how to compile sample code. Then, we present an example code used to perform common steps in cuTensorNet. In the example, we perform the following tensor contraction:
We construct the code step by step, each step adding code at the end. The steps are separated by succinct multi-line comment blocks.
It is recommended that the reader refers to Overview and cuTENSOR documentation for familiarity with the nomenclature and cuTENSOR operations.
Compiling code#
Assuming cuQuantum has been extracted in CUQUANTUM_ROOT and cuTENSOR in CUTENSOR_ROOT, we update the library path as follows:
export LD_LIBRARY_PATH=${CUQUANTUM_ROOT}/lib:${CUTENSOR_ROOT}/lib:${LD_LIBRARY_PATH}
Depending on your CUDA Toolkit, you might have to choose a different library version (e.g., ${CUTENSOR_ROOT}/lib/13.0).
The serial sample code discussed below (tensornet_example.cu) can be compiled via the following command:
nvcc tensornet_example.cu -I${CUQUANTUM_ROOT}/include -L${CUQUANTUM_ROOT}/lib -L${CUTENSOR_ROOT}/lib -lcutensornet -lcutensor -o tensornet_example
For static linking against the cuTensorNet library, use the following command (note that libmetis_static.a needs to be explicitly linked against,
assuming it is installed through the NVIDIA CUDA Toolkit and accessible through $LIBRARY_PATH):
nvcc tensornet_example.cu -I${CUQUANTUM_ROOT}/include ${CUQUANTUM_ROOT}/lib/libcutensornet_static.a -L${CUTENSOR_DIR}/lib -lcutensor libmetis_static.a -o tensornet_example
In order to build parallel (MPI) versions of the examples (tensornet_example_mpi_auto.cu and tensornet_example_mpi.cu),
one will need to have an MPI library installed (e.g., recent Open MPI, MVAPICH, or MPICH).
In particular, the automatic parallel example requires CUDA-aware MPI, see Code example (automatic slice-based distributed parallelization) below.
In this case, one will need to add -I${MPI_PATH}/include and -L${MPI_PATH}/lib -lmpi to the build command:
nvcc tensornet_example_mpi_auto.cu -I${CUQUANTUM_ROOT}/include -I${MPI_PATH}/include -L${CUQUANTUM_ROOT}/lib -L${CUTENSOR_ROOT}/lib -lcutensornet -lcutensor -L${MPI_PATH}/lib -lmpi -o tensornet_example_mpi_auto
nvcc tensornet_example_mpi.cu -I${CUQUANTUM_ROOT}/include -I${MPI_PATH}/include -L${CUQUANTUM_ROOT}/lib -L${CUTENSOR_ROOT}/lib -lcutensornet -lcutensor -L${MPI_PATH}/lib -lmpi -o tensornet_example_mpi
Warning
When running tensornet_example_mpi_auto.cu without CUDA-aware MPI, the program will crash.
Note
Depending on the source of the cuQuantum package, you may need to replace lib above by lib64.
Code example (serial)#
The following code example illustrates the common steps necessary to use cuTensorNet and also introduces typical tensor network operations. The full sample code can be found in the NVIDIA/cuQuantum repository (here).
Headers and data types#
8#include <stdlib.h>
9#include <stdio.h>
10
11#include <unordered_map>
12#include <vector>
13#include <cassert>
14
15#include <cuda_runtime.h>
16#include <cutensornet.h>
17
18#define HANDLE_ERROR(x) \
19 do { \
20 const auto err = x; \
21 if (err != CUTENSORNET_STATUS_SUCCESS) \
22 { \
23 printf("Error: %s in line %d\n", cutensornetGetErrorString(err), __LINE__); \
24 fflush(stdout); \
25 exit(EXIT_FAILURE); \
26 } \
27 } while (0)
28
29#define HANDLE_CUDA_ERROR(x) \
30 do { \
31 const auto err = x; \
32 if (err != cudaSuccess) \
33 { \
34 printf("CUDA Error: %s in line %d\n", cudaGetErrorString(err), __LINE__); \
35 fflush(stdout); \
36 exit(EXIT_FAILURE); \
37 } \
38 } while (0)
39
40// Usage: DEV_ATTR(cudaDevAttrClockRate, deviceId)
41#define DEV_ATTR(ENUMCONST, DID) \
42 ({ int v; \
43 HANDLE_CUDA_ERROR(cudaDeviceGetAttribute(&v, ENUMCONST, DID)); \
44 v; })
45
46
47struct GPUTimer
48{
49 GPUTimer(cudaStream_t stream) : stream_(stream)
50 {
51 HANDLE_CUDA_ERROR(cudaEventCreate(&start_));
52 HANDLE_CUDA_ERROR(cudaEventCreate(&stop_));
53 }
54
55 ~GPUTimer()
56 {
57 HANDLE_CUDA_ERROR(cudaEventDestroy(start_));
58 HANDLE_CUDA_ERROR(cudaEventDestroy(stop_));
59 }
60
61 void start() { HANDLE_CUDA_ERROR(cudaEventRecord(start_, stream_)); }
62
63 float seconds()
64 {
65 HANDLE_CUDA_ERROR(cudaEventRecord(stop_, stream_));
66 HANDLE_CUDA_ERROR(cudaEventSynchronize(stop_));
67 float time;
68 HANDLE_CUDA_ERROR(cudaEventElapsedTime(&time, start_, stop_));
69 return time * 1e-3;
70 }
71
72private:
73 cudaEvent_t start_, stop_;
74 cudaStream_t stream_;
75};
76
77int main()
78{
79 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
80
81 bool verbose = true;
82
83 // Check cuTensorNet version
84 const size_t cuTensornetVersion = cutensornetGetVersion();
85 if (verbose) printf("cuTensorNet version: %ld\n", cuTensornetVersion);
86
87 // Set GPU device
88 int numDevices{0};
89 HANDLE_CUDA_ERROR(cudaGetDeviceCount(&numDevices));
90 const int deviceId = 0;
91 HANDLE_CUDA_ERROR(cudaSetDevice(deviceId));
92 cudaDeviceProp prop;
93 HANDLE_CUDA_ERROR(cudaGetDeviceProperties(&prop, deviceId));
94
95 if (verbose)
96 {
97 printf("===== device info ======\n");
98 printf("GPU-local-id:%d\n", deviceId);
99 printf("GPU-name:%s\n", prop.name);
100 printf("GPU-clock:%d\n", DEV_ATTR(cudaDevAttrClockRate, deviceId));
101 printf("GPU-memoryClock:%d\n", DEV_ATTR(cudaDevAttrMemoryClockRate, deviceId));
102 printf("GPU-nSM:%d\n", prop.multiProcessorCount);
103 printf("GPU-major:%d\n", prop.major);
104 printf("GPU-minor:%d\n", prop.minor);
105 printf("========================\n");
106 }
107
108 typedef float floatType;
109 cudaDataType_t typeData = CUDA_R_32F;
110 cutensornetComputeType_t typeCompute = CUTENSORNET_COMPUTE_32F;
111
112 if (verbose) printf("Included headers and defined data types\n");
Define tensor network and tensor sizes#
Next, we define the topology of the tensor network (i.e., the modes of the tensors, their extents, and their connectivity).
116 /**************************************************************************************
117 * Computing: R_{k,l} = A_{a,b,c,d,e,f} B_{b,g,h,e,i,j} C_{m,a,g,f,i,k} D_{l,c,h,d,j,m}
118 **************************************************************************************/
119
120 constexpr int32_t numInputs = 4;
121
122 // Create vectors of tensor modes
123 std::vector<std::vector<int32_t>> tensorModes{ // for input tensors & output tensor
124 // input tensors
125 {'a', 'b', 'c', 'd', 'e', 'f'}, // tensor A
126 {'b', 'g', 'h', 'e', 'i', 'j'}, // tensor B
127 {'m', 'a', 'g', 'f', 'i', 'k'}, // tensor C
128 {'l', 'c', 'h', 'd', 'j', 'm'}, // tensor D
129 // output tensor
130 {'k', 'l'}, // tensor R
131 };
132
133 // Set mode extents
134 int64_t sameExtent = 16; // setting same extent for simplicity. In principle extents can differ.
135 std::unordered_map<int32_t, int64_t> extent;
136 for (auto& vec : tensorModes)
137 {
138 for (auto& mode : vec)
139 {
140 extent[mode] = sameExtent;
141 }
142 }
143
144 // Create a vector of extents for each tensor
145 std::vector<std::vector<int64_t>> tensorExtents; // for input tensors & output tensor
146 tensorExtents.resize(numInputs + 1); // hold inputs + output tensors
147 for (int32_t t = 0; t < numInputs + 1; ++t)
148 {
149 for (auto& mode : tensorModes[t]) tensorExtents[t].push_back(extent[mode]);
150 }
151
152 if (verbose) printf("Defined tensor network, modes, and extents\n");
Allocate memory and initialize data#
Next, we allocate memory for the tensor network operands and initialize them to random values.
155 /*****************
156 * Allocating data
157 *****************/
158
159 std::vector<size_t> tensorElements(numInputs + 1); // for input tensors & output tensor
160 std::vector<size_t> tensorSizes(numInputs + 1); // for input tensors & output tensor
161 size_t totalSize = 0;
162 for (int32_t t = 0; t < numInputs + 1; ++t)
163 {
164 size_t numElements = 1;
165 for (auto& mode : tensorModes[t]) numElements *= extent[mode];
166 tensorElements[t] = numElements;
167
168 tensorSizes[t] = sizeof(floatType) * numElements;
169 totalSize += tensorSizes[t];
170 }
171
172 if (verbose) printf("Total GPU memory used for tensor storage: %.2f GiB\n", (totalSize) / 1024. / 1024. / 1024);
173
174 void* tensorData_d[numInputs + 1]; // for input tensors & output tensor
175 for (int32_t t = 0; t < numInputs + 1; ++t)
176 {
177 HANDLE_CUDA_ERROR(cudaMalloc((void**)&tensorData_d[t], tensorSizes[t]));
178 }
179
180 floatType* tensorData_h[numInputs + 1]; // for input tensors & output tensor
181 for (int32_t t = 0; t < numInputs + 1; ++t)
182 {
183 tensorData_h[t] = (floatType*)malloc(tensorSizes[t]);
184 if (tensorData_h[t] == NULL)
185 {
186 printf("Error: Host memory allocation failed!\n");
187 return -1;
188 }
189 }
190
191 /*****************
192 * Initialize data
193 *****************/
194
195 // init output tensor to all 0s
196 memset(tensorData_h[numInputs], 0, tensorSizes[numInputs]);
197 // init input tensors to random values
198 for (int32_t t = 0; t < numInputs; ++t)
199 {
200 for (size_t e = 0; e < tensorElements[t]; ++e) tensorData_h[t][e] = ((floatType)rand()) / RAND_MAX;
201 }
202 // copy input data to device buffers
203 for (int32_t t = 0; t < numInputs; ++t)
204 {
205 HANDLE_CUDA_ERROR(cudaMemcpy(tensorData_d[t], tensorData_h[t], tensorSizes[t], cudaMemcpyHostToDevice));
206 }
cuTensorNet handle and network descriptor#
Next, we initialize the cuTensorNet library via cutensornetCreate().
Note that the created library context will be associated with the currently active GPU.
We create the network descriptor, and append the input tensors with the desired tensor modes and extents, as well as the data type.
We can, optionaly, set the output tensor modes (if skipped, the output modes will be inferred).
Also, we can, optionaly, set the compute mode on the network (if skipped, a default compute type, corresponding to the data type, will be used.
Refer to cutensornetCreateNetwork()).
209 /*************
210 * cuTensorNet
211 *************/
212
213 cudaStream_t stream;
214 HANDLE_CUDA_ERROR(cudaStreamCreate(&stream));
215
216 cutensornetHandle_t handle;
217 HANDLE_ERROR(cutensornetCreate(&handle));
218
219 if (verbose) printf("Allocated GPU memory for data, initialized data, and created library handle\n");
220
221 /****************
222 * Create Network
223 ****************/
224
225 // Set up tensor network
226 cutensornetNetworkDescriptor_t networkDesc;
227 HANDLE_ERROR(cutensornetCreateNetwork(handle, &networkDesc));
228
229 int64_t tensorIDs[numInputs]; // for input tensors
230 // attach the input tensors to the network
231 for (int32_t t = 0; t < numInputs; ++t)
232 {
233 HANDLE_ERROR(cutensornetNetworkAppendTensor(handle,
234 networkDesc,
235 tensorModes[t].size(),
236 tensorExtents[t].data(),
237 tensorModes[t].data(),
238 NULL,
239 typeData,
240 &tensorIDs[t]));
241 }
242
243 // set the output tensor
244 HANDLE_ERROR(cutensornetNetworkSetOutputTensor(handle,
245 networkDesc,
246 tensorModes[numInputs].size(),
247 tensorModes[numInputs].data(),
248 typeData));
249
250 // set the network compute type
251 HANDLE_ERROR(cutensornetNetworkSetAttribute(handle,
252 networkDesc,
253 CUTENSORNET_NETWORK_COMPUTE_TYPE,
254 &typeCompute,
255 sizeof(typeCompute)));
256 if (verbose) printf("Initialized the cuTensorNet library and created a tensor network descriptor\n");
Optimal contraction order and slicing#
At this stage, we can deploy the cuTensorNet optimizer to find an optimized contraction path and slicing combination.
We choose a limit for the workspace needed to perform the contraction based on the available memory resources, and provide it
to the optimizer as a constraint. We then create an optimizer configuration object of type cutensornetContractionOptimizerConfig_t
to specify various optimizer options and provide it to the optimizer, which is invoked via cutensornetContractionOptimize().
The results from the optimizer will be returned in an optimizer info object of type cutensornetContractionOptimizerInfo_t.
259 /******************************************************
260 * Choose workspace limit based on available resources.
261 ******************************************************/
262
263 size_t freeMem, totalMem;
264 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeMem, &totalMem));
265 uint64_t workspaceLimit = (uint64_t)((double)freeMem * 0.9);
266 if (verbose) printf("Workspace limit = %lu\n", workspaceLimit);
267
268 /*******************************
269 * Find "optimal" contraction order and slicing
270 *******************************/
271
272 cutensornetContractionOptimizerConfig_t optimizerConfig;
273 HANDLE_ERROR(cutensornetCreateContractionOptimizerConfig(handle, &optimizerConfig));
274
275 // Set the desired number of hyper-samples (defaults to 0)
276 int32_t num_hypersamples = 8;
277 HANDLE_ERROR(cutensornetContractionOptimizerConfigSetAttribute(handle,
278 optimizerConfig,
279 CUTENSORNET_CONTRACTION_OPTIMIZER_CONFIG_HYPER_NUM_SAMPLES,
280 &num_hypersamples,
281 sizeof(num_hypersamples)));
282
283 // Create contraction optimizer info and find an optimized contraction path
284 cutensornetContractionOptimizerInfo_t optimizerInfo;
285 HANDLE_ERROR(cutensornetCreateContractionOptimizerInfo(handle, networkDesc, &optimizerInfo));
286
287 HANDLE_ERROR(cutensornetContractionOptimize(handle,
288 networkDesc,
289 optimizerConfig,
290 workspaceLimit,
291 optimizerInfo));
292
293 // Query the number of slices the tensor network execution will be split into
294 int64_t numSlices = 0;
295 HANDLE_ERROR(cutensornetContractionOptimizerInfoGetAttribute(handle,
296 optimizerInfo,
297 CUTENSORNET_CONTRACTION_OPTIMIZER_INFO_NUM_SLICES,
298 &numSlices,
299 sizeof(numSlices)));
300 assert(numSlices > 0);
301
302 if (verbose) printf("Found an optimized contraction path using cuTensorNet optimizer\n");
It is also possible to bypass the cuTensorNet optimizer and import a pre-determined contraction path, as well as slicing information,
directly to the optimizer info object via cutensornetContractionOptimizerInfoSetAttribute(),
then attach it to the network via cutensornetNetworkSetOptimizerInfo().
Create workspace descriptor and allocate workspace memory#
Next, we create a workspace descriptor, compute the workspace sizes, and query the minimum workspace size needed to contract the network. We then allocate device memory for the workspace and set this in the workspace descriptor. The workspace descriptor will be provided to the contraction preparation and computation calls.
305 /*******************************
306 * Create workspace descriptor, allocate workspace, and set it.
307 *******************************/
308
309 cutensornetWorkspaceDescriptor_t workDesc;
310 HANDLE_ERROR(cutensornetCreateWorkspaceDescriptor(handle, &workDesc));
311
312 int64_t requiredWorkspaceSize = 0;
313 HANDLE_ERROR(cutensornetWorkspaceComputeContractionSizes(handle,
314 networkDesc,
315 optimizerInfo,
316 workDesc));
317
318 HANDLE_ERROR(cutensornetWorkspaceGetMemorySize(handle,
319 workDesc,
320 CUTENSORNET_WORKSIZE_PREF_MIN,
321 CUTENSORNET_MEMSPACE_DEVICE,
322 CUTENSORNET_WORKSPACE_SCRATCH,
323 &requiredWorkspaceSize));
324
325 void* work = nullptr;
326 HANDLE_CUDA_ERROR(cudaMalloc(&work, requiredWorkspaceSize));
327
328 HANDLE_ERROR(cutensornetWorkspaceSetMemory(handle,
329 workDesc,
330 CUTENSORNET_MEMSPACE_DEVICE,
331 CUTENSORNET_WORKSPACE_SCRATCH,
332 work,
333 requiredWorkspaceSize));
334
335 if (verbose) printf("Allocated and set up the GPU workspace\n");
Contraction preparation and auto-tuning#
We prepare the tensor network contraction, via cutensornetNetworkPrepareContraction(),
and set tensor’s data buffers and strides via cutensornetNetworkSetInputTensorMemory() and cutensornetNetworkSetOutputTensorMemory().
Optionally, we can auto-tune the contraction, via cutensornetNetworkAutotuneContraction(),
such that cuTENSOR selects the best kernel for each pairwise contraction.
This prepared network contraction can be reused for many (possibly different) data inputs, avoiding
the cost of initializing it redundantly.
338 /**************************
339 * Prepare the contraction.
340 **************************/
341
342 HANDLE_ERROR(cutensornetNetworkPrepareContraction(handle,
343 networkDesc,
344 workDesc));
345
346 // set tensor's data buffers and strides
347 for (int32_t t = 0; t < numInputs; ++t)
348 {
349 HANDLE_ERROR(cutensornetNetworkSetInputTensorMemory(handle,
350 networkDesc,
351 tensorIDs[t],
352 tensorData_d[t],
353 NULL));
354 }
355 HANDLE_ERROR(cutensornetNetworkSetOutputTensorMemory(handle,
356 networkDesc,
357 tensorData_d[numInputs],
358 NULL));
359 /****************************************************************
360 * Optional: Auto-tune the contraction to pick the fastest kernel
361 * for each pairwise tensor contraction.
362 ****************************************************************/
363 cutensornetNetworkAutotunePreference_t autotunePref;
364 HANDLE_ERROR(cutensornetCreateNetworkAutotunePreference(handle,
365 &autotunePref));
366
367 const int numAutotuningIterations = 5; // may be 0
368 HANDLE_ERROR(cutensornetNetworkAutotunePreferenceSetAttribute(handle,
369 autotunePref,
370 CUTENSORNET_NETWORK_AUTOTUNE_MAX_ITERATIONS,
371 &numAutotuningIterations,
372 sizeof(numAutotuningIterations)));
373
374 // Modify the network again to find the best pair-wise contractions
375 HANDLE_ERROR(cutensornetNetworkAutotuneContraction(handle,
376 networkDesc,
377 workDesc,
378 autotunePref,
379 stream));
380
381 HANDLE_ERROR(cutensornetDestroyNetworkAutotunePreference(autotunePref));
382
383 if (verbose) printf("Prepared the network contraction for cuTensorNet and optionally auto-tuned it\n");
Tensor network contraction execution#
Finally, we contract the tensor network as many times as needed, via cutensornetNetworkContract(),
possibly with different input each time (reset the data buffers and strides via cutensornetNetworkSetInputTensorMemory()).
Tensor network slices, captured as a cutensornetSliceGroup_t object, are computed using the same prepared network contraction.
For convenience, NULL can be provided to the cutensornetNetworkContract() function instead of a slice group when
the goal is to contract all the slices in the network. We also clean up and free allocated resources.
386 /****************************************
387 * Execute the tensor network contraction
388 ****************************************/
389
390 // Create a cutensornetSliceGroup_t object from a range of slice IDs
391 cutensornetSliceGroup_t sliceGroup{};
392 HANDLE_ERROR(cutensornetCreateSliceGroupFromIDRange(handle, 0, numSlices, 1, &sliceGroup));
393
394 GPUTimer timer{stream};
395 double minTimeCUTENSORNET = 1e100;
396 const int numRuns = 3; // number of repeats to get stable performance results
397 for (int i = 0; i < numRuns; ++i)
398 {
399 // reset the output tensor data
400 HANDLE_CUDA_ERROR(cudaMemcpy(tensorData_d[numInputs], tensorData_h[numInputs], tensorSizes[numInputs], cudaMemcpyHostToDevice));
401 HANDLE_CUDA_ERROR(cudaDeviceSynchronize());
402
403 /*
404 * Contract all slices of the tensor network
405 */
406 timer.start();
407
408 int32_t accumulateOutput = 0; // output tensor data will be overwritten
409 HANDLE_ERROR(cutensornetNetworkContract(handle,
410 networkDesc,
411 accumulateOutput,
412 workDesc,
413 sliceGroup, // alternatively, NULL can also be used to contract over all slices instead of specifying a sliceGroup object
414 stream));
415
416 // Synchronize and measure best timing
417 auto time = timer.seconds();
418 minTimeCUTENSORNET = (time > minTimeCUTENSORNET) ? minTimeCUTENSORNET : time;
419 }
420
421 if (verbose) printf("Contracted the tensor network, each slice used the same prepared contraction\n");
422
423 // Print the 1-norm of the output tensor (verification)
424 HANDLE_CUDA_ERROR(cudaStreamSynchronize(stream));
425 // restore the output tensor on Host
426 HANDLE_CUDA_ERROR(cudaMemcpy(tensorData_h[numInputs], tensorData_d[numInputs], tensorSizes[numInputs], cudaMemcpyDeviceToHost));
427 double norm1 = 0.0;
428 for (int64_t i = 0; i < tensorElements[numInputs]; ++i)
429 {
430 norm1 += std::abs(tensorData_h[numInputs][i]);
431 }
432 if (verbose) printf("Computed the 1-norm of the output tensor: %e\n", norm1);
433
434 /*************************/
435
436 // Query the total Flop count for the tensor network contraction
437 double flops{0.0};
438 HANDLE_ERROR(cutensornetContractionOptimizerInfoGetAttribute(handle,
439 optimizerInfo,
440 CUTENSORNET_CONTRACTION_OPTIMIZER_INFO_FLOP_COUNT,
441 &flops,
442 sizeof(flops)));
443
444 if (verbose)
445 {
446 printf("Number of tensor network slices = %ld\n", numSlices);
447 printf("Tensor network contraction time (ms) = %.3f\n", minTimeCUTENSORNET * 1000.f);
448 }
449
450 // Sphinx: #9
451 /****************
452 * Free resources
453 ****************/
454
455 // Free cuTensorNet resources
456 HANDLE_ERROR(cutensornetDestroySliceGroup(sliceGroup));
457 HANDLE_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
458 HANDLE_ERROR(cutensornetDestroyContractionOptimizerInfo(optimizerInfo));
459 HANDLE_ERROR(cutensornetDestroyContractionOptimizerConfig(optimizerConfig));
460 HANDLE_ERROR(cutensornetDestroyNetwork(networkDesc));
461 HANDLE_ERROR(cutensornetDestroy(handle));
462
463 HANDLE_CUDA_ERROR(cudaStreamDestroy(stream));
464
465 // Free Host and GPU memory resources
466 for (int32_t t = 0; t < numInputs + 1; ++t)
467 {
468 if (tensorData_h[t]) free(tensorData_h[t]);
469 if (tensorData_d[t]) cudaFree(tensorData_d[t]);
470 }
471 if (work) cudaFree(work);
472
473 if (verbose) printf("Freed resources and exited\n");
474
475 return 0;
476}
Recall that the full sample code can be found in the NVIDIA/cuQuantum repository (here).
Code example (automatic slice-based distributed parallelization)#
It is straightforward to adapt Code example (Serial) and enable automatic parallel execution across multiple/many GPU devices (across multiple/many nodes). We will illustrate this with an example using the Message Passing Interface (MPI) as the communication layer. Below we show the minor additions that need to be made in order to enable distributed parallel execution without making any changes to the original serial source code. The full MPI-automatic sample code can be found in the NVIDIA/cuQuantum repository. To enable automatic parallelism, cuTensorNet requires that
the environment variable
$CUTENSORNET_COMM_LIBis set to the path to the wrapper shared librarylibcutensornet_distributed_interface_mpi.so, andthe executable is linked to a CUDA-aware MPI library
The detailed instruction for setting these up is given in the installation guide above.
First, in addition to the headers and definitions mentioned in `Headers and data types`_, we include the MPI header and define a macro to handle MPI errors. We also need to initialize the MPI service and assign a unique GPU device to each MPI process that will later be associated with the cuTensorNet library handle created inside the MPI process.
20#include <mpi.h>
48#define HANDLE_MPI_ERROR(x) \
49 do { \
50 const auto err = x; \
51 if (err != MPI_SUCCESS) \
52 { \
53 char error[MPI_MAX_ERROR_STRING]; \
54 int len; \
55 MPI_Error_string(err, error, &len); \
56 printf("MPI Error: %s in line %d\n", error, __LINE__); \
57 fflush(stdout); \
58 MPI_Abort(MPI_COMM_WORLD, err); \
59 } \
60 } while (0)
The MPI service initialization must precede the first cutensornetCreate() call
which creates a cuTensorNet library handle. An attempt to call cutensornetCreate()
before initializing the MPI service will result in an error.
106 // Initialize MPI
107 HANDLE_MPI_ERROR(MPI_Init(&argc, &argv));
108 int rank{-1};
109 HANDLE_MPI_ERROR(MPI_Comm_rank(MPI_COMM_WORLD, &rank));
110 int numProcs{0};
111 HANDLE_MPI_ERROR(MPI_Comm_size(MPI_COMM_WORLD, &numProcs));
If multiple GPU devices located on the same node are visible to an MPI process,
we need to pick an exclusive GPU device for each MPI process. If the mpirun (or mpiexec)
command provided by your MPI library implementation sets up an environment variable
that shows the rank of the respective MPI process during its invocation, you can use
that environment variable to set CUDA_VISIBLE_DEVICES to point to a specific single
GPU device assigned to the MPI process exclusively (for example, Open MPI provides
${OMPI_COMM_WORLD_LOCAL_RANK} for this purpose). Otherwise, the GPU device can be
set manually, as shown below.
129 // Set GPU device based on ranks and nodes
130 int numDevices{0};
131 HANDLE_CUDA_ERROR(cudaGetDeviceCount(&numDevices));
132 const int deviceId = rank % numDevices; // we assume that the processes are mapped to nodes in contiguous chunks
133 HANDLE_CUDA_ERROR(cudaSetDevice(deviceId));
134 cudaDeviceProp prop;
135 HANDLE_CUDA_ERROR(cudaGetDeviceProperties(&prop, deviceId));
Next we define the tensor network as described in `Define tensor network and tensor sizes`_. In a one GPU device per process model, the tensor network, including operands and result data, is replicated on each process. The root process initializes the input data and broadcasts it to the other processes.
243 /*******************
244 * Initialize data
245 *******************/
246
247 // init output tensor to all 0s
248 memset(tensorData_h[numInputs], 0, tensorSizes[numInputs]);
249 if (rank == 0)
250 {
251 // init input tensors to random values
252 for (int32_t t = 0; t < numInputs; ++t)
253 {
254 for (uint64_t i = 0; i < tensorElements[t]; ++i) tensorData_h[t][i] = ((floatType)rand()) / RAND_MAX;
255 }
256 }
257
258 // Broadcast input data to all ranks
259 for (int32_t t = 0; t < numInputs; ++t)
260 {
261 HANDLE_MPI_ERROR(MPI_Bcast(tensorData_h[t], tensorElements[t], floatTypeMPI, 0, MPI_COMM_WORLD));
262 }
263
264 // copy input data to device buffers
265 for (int32_t t = 0; t < numInputs; ++t)
266 {
267 HANDLE_CUDA_ERROR(cudaMemcpy(tensorData_d[t], tensorData_h[t], tensorSizes[t], cudaMemcpyHostToDevice));
268 }
Once the MPI service has been initialized and the cuTensorNet library handle has been created
afterwards, one can activate the distributed parallel execution by calling cutensornetDistributedResetConfiguration().
Per standard practice, the user’s code needs to create a duplicate MPI communicator via MPI_Comm_dup.
Then, the duplicate MPI communicator is associated with the cuTensorNet library handle
by passing the pointer to the duplicate MPI communicator together with its size (in bytes)
to the cutensornetDistributedResetConfiguration() call. The MPI communicator will be stored
inside the cuTensorNet library handle such that all subsequent calls to the
tensor network contraction path finder and tensor network contraction executor will be
parallelized across all participating MPI processes (each MPI process is associated with its own GPU).
333 /*******************************
334 * Activate distributed (parallel) execution prior to
335 * calling contraction path finder and contraction executor
336 *******************************/
337 // HANDLE_ERROR( cutensornetDistributedResetConfiguration(handle, NULL, 0) ); // resets back to serial execution
338 MPI_Comm cutnComm;
339 HANDLE_MPI_ERROR(MPI_Comm_dup(MPI_COMM_WORLD, &cutnComm)); // duplicate MPI communicator
340 HANDLE_ERROR(cutensornetDistributedResetConfiguration(handle, &cutnComm, sizeof(cutnComm)));
341 if (verbose) printf("Reset distributed MPI configuration\n");
Note
cutensornetDistributedResetConfiguration() is a collective call that must be executed
by all participating MPI processes.
The API of this distributed parallelization model makes it straightforward to run source codes
written for serial execution on multiple GPUs/nodes. Essentially, all MPI processes will
execute exactly the same (serial) source code while automatically performing distributed parallelization
inside the tensor network contraction path finder and tensor network contraction executor calls.
The parallelization of the tensor network contraction path finder will only occur when the number
of requested hyper-samples is larger than zero. However, regardless of that, activation of the
distributed parallelization must precede the invocation of the tensor network contraction path finder.
That is, the tensor network contraction path finder and tensor network contraction execution invocations
must be done strictly after activating the distributed parallelization via cutensornetDistributedResetConfiguration().
When the distributed configuration is set to a parallel mode, the user is normally expected to invoke
tensor network contraction execution by calling the cutensornetNetworkContract() function which is provided
with the full range of tensor network slices that will be automatically distributed across all MPI processes.
Since the size of the tensor network must be sufficiently large to get a benefit of acceleration from
distributed execution, smaller tensor networks (those which consist of only a single slice)
can still be processed without distributed parallelization, which can be achieved by calling
cutensornetDistributedResetConfiguration() with a NULL argument in place of the MPI communicator
pointer (as before, this should be done prior to calling the tensor network contraction path finder).
That is, the switch between distributed parallelization and redundant serial execution can be done
on a per-tensor-network basis. Users can decide which (larger) tensor networks to process
in a parallel manner and which (smaller ones) to process in a serial manner redundantly,
by resetting the distributed configuration appropriately. In both cases, all MPI processes
will produce the same output tensor (result) at the end of the tensor network execution.
Note
In the current version of the cuTensorNet library, the parallel tensor network contraction
execution triggered by the cutensornetNetworkContract() call will block the provided CUDA stream as well
as the calling CPU thread until the execution has completed on all MPI processes. This is a temporary
limitation that will be lifted in future versions of the cuTensorNet library, where the call to
cutensornetNetworkContract() will be fully asynchronous, similar to the serial execution case.
Additionally, for an explicit synchronization of all MPI processes (barrier) one can make
a collective call to cutensornetDistributedSynchronize().
Before termination, the MPI service needs to be finalized.
552 // Shut down MPI service
553 HANDLE_MPI_ERROR(MPI_Finalize());
The complete MPI-automatic sample can be found in the NVIDIA/cuQuantum repository.
Code example (manual slice-based distributed parallelization)#
For advanced users, it is also possible (but more involved) to adapt Code example (Serial) to explicitly parallelize execution of the tensor network contraction operation on multiple GPU devices. Here we will also use MPI as the communication layer. For brevity, we will show only the changes that need to be made on top of the serial example. The full MPI-manual sample code can be found in the NVIDIA/cuQuantum repository. Note that this sample does NOT require CUDA-aware MPI.
First, in addition to the headers and definitions mentioned in `Headers and data types`_, we need to include the MPI header and define a macro to handle MPI errors. We also need to initialize the MPI service and associate each MPI process with its own GPU device, as explained previously.
20#include <mpi.h>
48#define HANDLE_MPI_ERROR(x) \
49 do { \
50 const auto err = x; \
51 if (err != MPI_SUCCESS) \
52 { \
53 char error[MPI_MAX_ERROR_STRING]; \
54 int len; \
55 MPI_Error_string(err, error, &len); \
56 printf("MPI Error: %s in line %d\n", error, __LINE__); \
57 fflush(stdout); \
58 MPI_Abort(MPI_COMM_WORLD, err); \
59 } \
60 } while (0)
106 // Initialize MPI
107 HANDLE_MPI_ERROR(MPI_Init(&argc, &argv));
108 int rank{-1};
109 HANDLE_MPI_ERROR(MPI_Comm_rank(MPI_COMM_WORLD, &rank));
110 int numProcs{0};
111 HANDLE_MPI_ERROR(MPI_Comm_size(MPI_COMM_WORLD, &numProcs));
129 // Set GPU device based on ranks and nodes
130 int numDevices{0};
131 HANDLE_CUDA_ERROR(cudaGetDeviceCount(&numDevices));
132 const int deviceId = rank % numDevices; // we assume that the processes are mapped to nodes in contiguous chunks
133 HANDLE_CUDA_ERROR(cudaSetDevice(deviceId));
134 cudaDeviceProp prop;
135 HANDLE_CUDA_ERROR(cudaGetDeviceProperties(&prop, deviceId));
Next, we define the tensor network as described in `Define tensor network and tensor sizes`_. In a one GPU device per process model, the tensor network, including operands and result data, is replicated on each process. The root process initializes the input data and broadcasts it to the other processes.
243 /*******************
244 * Initialize data
245 *******************/
246
247 // init output tensor to all 0s
248 memset(tensorData_h[numInputs], 0, tensorSizes[numInputs]);
249 if (rank == 0)
250 {
251 // init input tensors to random values
252 for (int32_t t = 0; t < numInputs; ++t)
253 {
254 for (uint64_t i = 0; i < tensorElements[t]; ++i) tensorData_h[t][i] = ((floatType)rand()) / RAND_MAX;
255 }
256 }
257
258 // Broadcast input data to all ranks
259 for (int32_t t = 0; t < numInputs; ++t)
260 {
261 HANDLE_MPI_ERROR(MPI_Bcast(tensorData_h[t], tensorElements[t], floatTypeMPI, 0, MPI_COMM_WORLD));
262 }
263
264 // copy input data to device buffers
265 for (int32_t t = 0; t < numInputs; ++t)
266 {
267 HANDLE_CUDA_ERROR(cudaMemcpy(tensorData_d[t], tensorData_h[t], tensorSizes[t], cudaMemcpyHostToDevice));
268 }
Then we create the library handle and tensor network descriptor on each process, as described in cuTensorNet handle and network descriptor.
Next, we find the optimal contraction path and slicing combination for our tensor network.
We will run the cuTensorNet optimizer on all processes and determine which process has the best path
in terms of the FLOP count. We will then pack the optimizer info object on this process, broadcast the packed buffer,
and unpack it on all other processes. Each process now has the same optimizer info object, which we use to calculate
the share of slices for each process. Because the optimizer info object is modified as a result of unifiying the optimizer across processes,
we need to update the network with the modified optimizer info object via cutensornetNetworkSetOptimizerInfo().
353 // Compute the path on all ranks so that we can choose the path with the lowest cost. Note that since this is a tiny
354 // example with 4 operands, all processes will compute the same globally optimal path. This is not the case for large
355 // tensor networks. For large networks, hyper-optimization does become beneficial.
356
357 // Enforce tensor network slicing (for parallelization)
358 const int32_t min_slices = numProcs;
359 HANDLE_ERROR(cutensornetContractionOptimizerConfigSetAttribute(handle,
360 optimizerConfig,
361 CUTENSORNET_CONTRACTION_OPTIMIZER_CONFIG_SLICER_MIN_SLICES,
362 &min_slices,
363 sizeof(min_slices)));
364
365 // Find an optimized tensor network contraction path on each MPI process
366 HANDLE_ERROR(cutensornetContractionOptimize(handle,
367 networkDesc,
368 optimizerConfig,
369 workspaceLimit,
370 optimizerInfo));
371
372 // Query the obtained Flop count
373 double flops{-1.};
374 HANDLE_ERROR(cutensornetContractionOptimizerInfoGetAttribute(handle,
375 optimizerInfo,
376 CUTENSORNET_CONTRACTION_OPTIMIZER_INFO_FLOP_COUNT,
377 &flops,
378 sizeof(flops)));
379
380 // Choose the contraction path with the lowest Flop cost
381 struct
382 {
383 double value;
384 int rank;
385 } in{flops, rank}, out;
386
387 HANDLE_MPI_ERROR(MPI_Allreduce(&in, &out, 1, MPI_DOUBLE_INT, MPI_MINLOC, MPI_COMM_WORLD));
388 const int sender = out.rank;
389 flops = out.value;
390
391 if (verbose) printf("Process %d has the path with the lowest FLOP count %lf\n", sender, flops);
392
393 // Get the buffer size for optimizerInfo and broadcast it
394 size_t bufSize{0};
395 if (rank == sender)
396 {
397 HANDLE_ERROR(cutensornetContractionOptimizerInfoGetPackedSize(handle, optimizerInfo, &bufSize));
398 }
399 HANDLE_MPI_ERROR(MPI_Bcast(&bufSize, 1, MPI_INT64_T, sender, MPI_COMM_WORLD));
400
401 // Allocate a buffer
402 std::vector<char> buffer(bufSize);
403
404 // Pack optimizerInfo on sender and broadcast it
405 if (rank == sender)
406 {
407 HANDLE_ERROR(cutensornetContractionOptimizerInfoPackData(handle, optimizerInfo, buffer.data(), bufSize));
408 }
409 HANDLE_MPI_ERROR(MPI_Bcast(buffer.data(), bufSize, MPI_CHAR, sender, MPI_COMM_WORLD));
410
411 // Unpack optimizerInfo from the buffer
412 if (rank != sender)
413 {
414 HANDLE_ERROR(
415 cutensornetUpdateContractionOptimizerInfoFromPackedData(handle, buffer.data(), bufSize, optimizerInfo));
416 }
417
418 // Update the network with the modified optimizer info
419 HANDLE_ERROR(cutensornetNetworkSetOptimizerInfo(handle, networkDesc, optimizerInfo));
420
421 // Query the number of slices the tensor network execution will be split into
422 int64_t numSlices = 0;
423 HANDLE_ERROR(cutensornetContractionOptimizerInfoGetAttribute(handle,
424 optimizerInfo,
425 CUTENSORNET_CONTRACTION_OPTIMIZER_INFO_NUM_SLICES,
426 &numSlices,
427 sizeof(numSlices)));
428 assert(numSlices > 0);
429
430 // Calculate each process's share of the slices
431 int64_t procChunk = numSlices / numProcs;
432 int extra = numSlices % numProcs;
433 int procSliceBegin = rank * procChunk + std::min(rank, extra);
434 int procSliceEnd = (rank == numProcs - 1) ? numSlices : (rank + 1) * procChunk + std::min(rank + 1, extra);
We now create the workspace descriptor and allocate memory as described in `Create workspace descriptor and allocate workspace memory`_, and create the `Contraction preparation and auto-tuning`_ of the tensor network.
Next, on each process, we create a slice group (see cutensornetSliceGroup_t) that corresponds to its share of the tensor network slices.
We then provide this slice group object to the cutensornetNetworkContract() function to get a partial contraction result on each process.
525 // Create a cutensornetSliceGroup_t object from a range of slice IDs
526 cutensornetSliceGroup_t sliceGroup{};
527 HANDLE_ERROR(cutensornetCreateSliceGroupFromIDRange(handle, procSliceBegin, procSliceEnd, 1, &sliceGroup));
548 HANDLE_ERROR(cutensornetNetworkContract(handle,
549 networkDesc,
550 accumulateOutput,
551 workDesc,
552 sliceGroup,
553 stream));
Finally, we sum up the partial contributions to obtain the result of the tensor network contraction.
559 // Perform Allreduce operation on the output tensor
560 HANDLE_CUDA_ERROR(cudaStreamSynchronize(stream));
561 // restore the output tensor on Host
562 HANDLE_CUDA_ERROR(cudaMemcpy(tensorData_h[numInputs], tensorData_d[numInputs], tensorSizes[numInputs], cudaMemcpyDeviceToHost));
563 HANDLE_MPI_ERROR(MPI_Allreduce(MPI_IN_PLACE, tensorData_h[numInputs], tensorElements[numInputs], floatTypeMPI, MPI_SUM, MPI_COMM_WORLD));
Before termination, the MPI service needs to be finalized.
624 // Shut down MPI service
625 HANDLE_MPI_ERROR(MPI_Finalize());
The complete MPI-manual sample can be found in the NVIDIA/cuQuantum repository.
Code example (tensorQR)#
The following code example illustrates how to integrate cuTensorNet functionalities to perform tensor QR operation. The full code can be found in the NVIDIA/cuQuantum repository (here).
Define QR decomposition#
We first define the QR decomposition to perform with the data type, modes partition, and the extents.
103 /**********************************************
104 * Tensor QR: T_{i,j,m,n} -> Q_{i,x,m} R_{n,x,j}
105 ***********************************************/
106
107 typedef float floatType;
108 cudaDataType_t typeData = CUDA_R_32F;
109
110 // Create vector of modes
111 int32_t sharedMode = 'x';
112
113 std::vector<int32_t> modesT{'i','j','m','n'}; // input
114 std::vector<int32_t> modesQ{'i', sharedMode,'m'};
115 std::vector<int32_t> modesR{'n', sharedMode,'j'}; // QR output
116
117 // Extents
118 std::unordered_map<int32_t, int64_t> extentMap;
119 extentMap['i'] = 16;
120 extentMap['j'] = 16;
121 extentMap['m'] = 16;
122 extentMap['n'] = 16;
123
124 int64_t rowExtent = computeCombinedExtent(extentMap, modesQ);
125 int64_t colExtent = computeCombinedExtent(extentMap, modesR);
126
127 // cuTensorNet tensor QR operates in reduced mode expecting k = min(m, n)
128 extentMap[sharedMode] = rowExtent <= colExtent? rowExtent: colExtent;
129
130 // Create a vector of extents for each tensor
131 std::vector<int64_t> extentT;
132 for (auto mode : modesT)
133 extentT.push_back(extentMap[mode]);
134 std::vector<int64_t> extentQ;
135 for (auto mode : modesQ)
136 extentQ.push_back(extentMap[mode]);
137 std::vector<int64_t> extentR;
138 for (auto mode : modesR)
139 extentR.push_back(extentMap[mode]);
Note
cutensornetTensorQR() operates in reduced mode, expecting the shared extent for the output to be the minimum of
the combined row extent and the combined column extent.
Allocate memory and initialize data#
Next, we allocate memory for the input and output tensor operands. The input operand is initialized to random values.
142 /***********************************
143 * Allocating data on host and device
144 ************************************/
145
146 size_t elementsT = 1;
147 for (auto mode : modesT)
148 elementsT *= extentMap[mode];
149 size_t elementsQ = 1;
150 for (auto mode : modesQ)
151 elementsQ *= extentMap[mode];
152 size_t elementsR = 1;
153 for (auto mode : modesR)
154 elementsR *= extentMap[mode];
155
156 size_t sizeT = sizeof(floatType) * elementsT;
157 size_t sizeQ = sizeof(floatType) * elementsQ;
158 size_t sizeR = sizeof(floatType) * elementsR;
159
160 printf("Total memory: %.2f GiB\n", (sizeT + sizeQ + sizeR)/1024./1024./1024);
161
162 floatType *T = (floatType*) malloc(sizeT);
163 floatType *Q = (floatType*) malloc(sizeQ);
164 floatType *R = (floatType*) malloc(sizeR);
165
166 if (T == NULL || Q==NULL || R==NULL )
167 {
168 printf("Error: Host allocation of input T or output Q/R.\n");
169 return -1;
170 }
171
172 void* D_T;
173 void* D_Q;
174 void* D_R;
175
176 HANDLE_CUDA_ERROR( cudaMalloc((void**) &D_T, sizeT) );
177 HANDLE_CUDA_ERROR( cudaMalloc((void**) &D_Q, sizeQ) );
178 HANDLE_CUDA_ERROR( cudaMalloc((void**) &D_R, sizeR) );
179
180 /****************
181 * Initialize data
182 *****************/
183
184 for (uint64_t i = 0; i < elementsT; i++)
185 T[i] = ((floatType) rand())/RAND_MAX;
186
187 HANDLE_CUDA_ERROR( cudaMemcpy(D_T, T, sizeT, cudaMemcpyHostToDevice) );
188 printf("Allocate memory for data, and initialize data.\n");
Initialize cuTensorNet and create tensor descriptors#
Then we initialize the library handle of cuTensorNet and create cutensorTensorDescriptor_t for input and output tensors.
191 /******************
192 * cuTensorNet
193 *******************/
194
195 cudaStream_t stream;
196 HANDLE_CUDA_ERROR( cudaStreamCreate(&stream) );
197
198 cutensornetHandle_t handle;
199 HANDLE_ERROR( cutensornetCreate(&handle) );
200
201 /***************************
202 * Create tensor descriptors
203 ****************************/
204
205 cutensornetTensorDescriptor_t descTensorIn;
206 cutensornetTensorDescriptor_t descTensorQ;
207 cutensornetTensorDescriptor_t descTensorR;
208
209 const int32_t numModesIn = modesT.size();
210 const int32_t numModesQ = modesQ.size();
211 const int32_t numModesR = modesR.size();
212
213 const int64_t* strides = NULL; // assuming fortran layout for all tensors
214
215 HANDLE_ERROR( cutensornetCreateTensorDescriptor(handle, numModesIn, extentT.data(), strides, modesT.data(), typeData, &descTensorIn) );
216 HANDLE_ERROR( cutensornetCreateTensorDescriptor(handle, numModesQ, extentQ.data(), strides, modesQ.data(), typeData, &descTensorQ) );
217 HANDLE_ERROR( cutensornetCreateTensorDescriptor(handle, numModesR, extentR.data(), strides, modesR.data(), typeData, &descTensorR) );
218
219 printf("Initialize the cuTensorNet library and create all tensor descriptors.\n");
Query and allocate required workspace#
Once all tensor descriptors are created, we can query the required workspace size with cutensornetWorkspaceComputeQRSizes().
222 /********************************************
223 * Query and allocate required workspace sizes
224 *********************************************/
225
226 cutensornetWorkspaceDescriptor_t workDesc;
227 HANDLE_ERROR( cutensornetCreateWorkspaceDescriptor(handle, &workDesc) );
228 HANDLE_ERROR( cutensornetWorkspaceComputeQRSizes(handle, descTensorIn, descTensorQ, descTensorR, workDesc) );
229 int64_t hostWorkspaceSize, deviceWorkspaceSize;
230
231 // for tensor QR, it does not matter which cutensornetWorksizePref_t we pick
232 HANDLE_ERROR( cutensornetWorkspaceGetMemorySize(handle,
233 workDesc,
234 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
235 CUTENSORNET_MEMSPACE_DEVICE,
236 CUTENSORNET_WORKSPACE_SCRATCH,
237 &deviceWorkspaceSize) );
238 HANDLE_ERROR( cutensornetWorkspaceGetMemorySize(handle,
239 workDesc,
240 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
241 CUTENSORNET_MEMSPACE_HOST,
242 CUTENSORNET_WORKSPACE_SCRATCH,
243 &hostWorkspaceSize) );
244
245 void *devWork = nullptr, *hostWork = nullptr;
246 if (deviceWorkspaceSize > 0) {
247 HANDLE_CUDA_ERROR( cudaMalloc(&devWork, deviceWorkspaceSize) );
248 }
249 if (hostWorkspaceSize > 0) {
250 hostWork = malloc(hostWorkspaceSize);
251 }
252 HANDLE_ERROR( cutensornetWorkspaceSetMemory(handle,
253 workDesc,
254 CUTENSORNET_MEMSPACE_DEVICE,
255 CUTENSORNET_WORKSPACE_SCRATCH,
256 devWork,
257 deviceWorkspaceSize) );
258 HANDLE_ERROR( cutensornetWorkspaceSetMemory(handle,
259 workDesc,
260 CUTENSORNET_MEMSPACE_HOST,
261 CUTENSORNET_WORKSPACE_SCRATCH,
262 hostWork,
263 hostWorkspaceSize) );
Execution#
At this stage, we can perform the QR decomposition by calling cutensornetTensorQR().
266 /**********
267 * Execution
268 ***********/
269
270 GPUTimer timer{stream};
271 double minTimeCUTENSOR = 1e100;
272 const int numRuns = 3; // to get stable perf results
273 for (int i=0; i < numRuns; ++i)
274 {
275 // restore output
276 cudaMemsetAsync(D_Q, 0, sizeQ, stream);
277 cudaMemsetAsync(D_R, 0, sizeR, stream);
278 cudaDeviceSynchronize();
279
280 timer.start();
281 HANDLE_ERROR( cutensornetTensorQR(handle,
282 descTensorIn, D_T,
283 descTensorQ, D_Q,
284 descTensorR, D_R,
285 workDesc,
286 stream) );
287 // Synchronize and measure timing
288 auto time = timer.seconds();
289 minTimeCUTENSOR = (minTimeCUTENSOR < time) ? minTimeCUTENSOR : time;
290 }
291
292 printf("Performing QR\n");
293
294 HANDLE_CUDA_ERROR( cudaMemcpyAsync(Q, D_Q, sizeQ, cudaMemcpyDeviceToHost) );
295 HANDLE_CUDA_ERROR( cudaMemcpyAsync(R, D_R, sizeR, cudaMemcpyDeviceToHost) );
296
297 cudaDeviceSynchronize(); // device synchronization.
298 printf("%.2f ms\n", minTimeCUTENSOR * 1000.f);
Free resources#
After the computation, we need to free up all resources.
301 /***************
302 * Free resources
303 ****************/
304
305 HANDLE_ERROR( cutensornetDestroyTensorDescriptor(descTensorIn) );
306 HANDLE_ERROR( cutensornetDestroyTensorDescriptor(descTensorQ) );
307 HANDLE_ERROR( cutensornetDestroyTensorDescriptor(descTensorR) );
308 HANDLE_ERROR( cutensornetDestroyWorkspaceDescriptor(workDesc) );
309 HANDLE_ERROR( cutensornetDestroy(handle) );
310
311 if (T) free(T);
312 if (Q) free(Q);
313 if (R) free(R);
314 if (D_T) cudaFree(D_T);
315 if (D_Q) cudaFree(D_Q);
316 if (D_R) cudaFree(D_R);
317 if (devWork) cudaFree(devWork);
318 if (hostWork) free(hostWork);
319
320 printf("Free resource and exit.\n");
321
322 return 0;
323}
Code example (tensorSVD)#
Performing tensor SVD using cuTensorNet adopts a very similar workflow as QR example. Here, we highlight the notable differences between the two APIs. The full code can be found in the NVIDIA/cuQuantum repository (here).
Define SVD decomposition#
As with QR decomposition, we first define the SVD decomposition to perform with the data type, modes partition, and the extents.
103 /******************************************************
104 * Tensor SVD: T_{i,j,m,n} -> U_{i,x,m} S_{x} V_{n,x,j}
105 *******************************************************/
106
107 typedef float floatType;
108 cudaDataType_t typeData = CUDA_R_32F;
109
110 // Create vector of modes
111 int32_t sharedMode = 'x';
112
113 std::vector<int32_t> modesT{'i','j','m','n'}; // input
114 std::vector<int32_t> modesU{'i', sharedMode,'m'};
115 std::vector<int32_t> modesV{'n', sharedMode,'j'}; // SVD output
116
117 // Extents
118 std::unordered_map<int32_t, int64_t> extentMap;
119 extentMap['i'] = 16;
120 extentMap['j'] = 16;
121 extentMap['m'] = 16;
122 extentMap['n'] = 16;
123
124 int64_t rowExtent = computeCombinedExtent(extentMap, modesU);
125 int64_t colExtent = computeCombinedExtent(extentMap, modesV);
126 // cuTensorNet tensor SVD operates in reduced mode expecting k <= min(m, n)
127 int64_t fullSharedExtent = rowExtent <= colExtent? rowExtent: colExtent;
128 const int64_t maxExtent = fullSharedExtent / 2; //fix extent truncation with half of the singular values trimmed out
129 extentMap[sharedMode] = maxExtent;
130
131 // Create a vector of extents for each tensor
132 std::vector<int64_t> extentT;
133 for (auto mode : modesT)
134 extentT.push_back(extentMap[mode]);
135 std::vector<int64_t> extentU;
136 for (auto mode : modesU)
137 extentU.push_back(extentMap[mode]);
138 std::vector<int64_t> extentV;
139 for (auto mode : modesV)
140 extentV.push_back(extentMap[mode]);
Note
To perform fixed extent truncation, we directly set maxExtent to half of the full extent corresponding to exact SVD.
Setup SVD truncation parameters#
Once the SVD decomposition is defined, we can follow the same workflow as QR example for data allocation and tensor descriptor initialization.
Before querying workspace, we can choose different SVD options in cutensornetTensorSVDConfig_t.
Meanwhile, we can create cutensornetTensorSVDInfo_t to keep track of runtime truncation information.
227 /**********************************************
228 * Setup SVD algorithm and truncation parameters
229 ***********************************************/
230
231 cutensornetTensorSVDConfig_t svdConfig;
232 HANDLE_ERROR( cutensornetCreateTensorSVDConfig(handle, &svdConfig) );
233
234 // set up truncation parameters
235 double absCutoff = 1e-2;
236 HANDLE_ERROR( cutensornetTensorSVDConfigSetAttribute(handle,
237 svdConfig,
238 CUTENSORNET_TENSOR_SVD_CONFIG_ABS_CUTOFF,
239 &absCutoff,
240 sizeof(absCutoff)) );
241 double relCutoff = 4e-2;
242 HANDLE_ERROR( cutensornetTensorSVDConfigSetAttribute(handle,
243 svdConfig,
244 CUTENSORNET_TENSOR_SVD_CONFIG_REL_CUTOFF,
245 &relCutoff,
246 sizeof(relCutoff)) );
247
248 // optional: choose gesvdj algorithm with customized parameters. Default is gesvd.
249 cutensornetTensorSVDAlgo_t svdAlgo = CUTENSORNET_TENSOR_SVD_ALGO_GESVDJ;
250 HANDLE_ERROR( cutensornetTensorSVDConfigSetAttribute(handle,
251 svdConfig,
252 CUTENSORNET_TENSOR_SVD_CONFIG_ALGO,
253 &svdAlgo,
254 sizeof(svdAlgo)) );
255 cutensornetGesvdjParams_t gesvdjParams{/*tol=*/1e-12, /*maxSweeps=*/80};
256 HANDLE_ERROR( cutensornetTensorSVDConfigSetAttribute(handle,
257 svdConfig,
258 CUTENSORNET_TENSOR_SVD_CONFIG_ALGO_PARAMS,
259 &gesvdjParams,
260 sizeof(gesvdjParams)) );
261 printf("Set up SVDConfig to use GESVDJ algorithm with truncation\n");
262
263 /********************************************************
264 * Create SVDInfo to record runtime SVD truncation details
265 *********************************************************/
266
267 cutensornetTensorSVDInfo_t svdInfo;
268 HANDLE_ERROR( cutensornetCreateTensorSVDInfo(handle, &svdInfo)) ;
Execution#
Next, we can query and allocate the workspace with cutensornetWorkspaceComputeSVDSizes(), which is very similar to its QR counterpart.
At this stage, we can perform the SVD decomposition by calling cutensornetTensorSVD().
314 /**********
315 * Execution
316 ***********/
317
318 GPUTimer timer{stream};
319 double minTimeCUTENSOR = 1e100;
320 const int numRuns = 3; // to get stable perf results
321 for (int i=0; i < numRuns; ++i)
322 {
323 // restore output
324 cudaMemsetAsync(D_U, 0, sizeU, stream);
325 cudaMemsetAsync(D_S, 0, sizeS, stream);
326 cudaMemsetAsync(D_V, 0, sizeV, stream);
327 cudaDeviceSynchronize();
328
329 // With value-based truncation, `cutensornetTensorSVD` can potentially update the shared extent in descTensorU/V.
330 // We here restore descTensorU/V to the original problem.
331 HANDLE_ERROR( cutensornetDestroyTensorDescriptor(descTensorU) );
332 HANDLE_ERROR( cutensornetDestroyTensorDescriptor(descTensorV) );
333 HANDLE_ERROR( cutensornetCreateTensorDescriptor(handle, numModesU, extentU.data(), strides, modesU.data(), typeData, &descTensorU) );
334 HANDLE_ERROR( cutensornetCreateTensorDescriptor(handle, numModesV, extentV.data(), strides, modesV.data(), typeData, &descTensorV) );
335
336 timer.start();
337 HANDLE_ERROR( cutensornetTensorSVD(handle,
338 descTensorIn, D_T,
339 descTensorU, D_U,
340 D_S,
341 descTensorV, D_V,
342 svdConfig,
343 svdInfo,
344 workDesc,
345 stream) );
346 // Synchronize and measure timing
347 auto time = timer.seconds();
348 minTimeCUTENSOR = (minTimeCUTENSOR < time) ? minTimeCUTENSOR : time;
349 }
350
351 printf("Performing SVD\n");
352
353 HANDLE_CUDA_ERROR( cudaMemcpyAsync(U, D_U, sizeU, cudaMemcpyDeviceToHost) );
354 HANDLE_CUDA_ERROR( cudaMemcpyAsync(S, D_S, sizeS, cudaMemcpyDeviceToHost) );
355 HANDLE_CUDA_ERROR( cudaMemcpyAsync(V, D_V, sizeV, cudaMemcpyDeviceToHost) );
Note
Since we turned on weighted truncation options in this example, we need to restore the tensor descriptors for U and V if we wish to perform the same computation multiple times.
After the computation, we still need to free up all resources.
Code example (GateSplit)#
Performing gate split operation using cuTensorNet adopts a very similar workflow as QR example and SVD example. Here, we here highlight the notable differences between the two APIs. The full code can be found in the NVIDIA/cuQuantum repository (here).
Define tensor operands#
As with QR/SVD decomposition, we first define all the tensor operands by specifying the data type, modes partition, and the extents. In this process, we choose to perform fixed extent truncation to a size of 16.
90 /************************************************************************************
91 * Gate Split: A_{i,j,k,l} B_{k,o,p,q} G_{m,n,l,o}-> A'_{i,j,x,m} S_{x} B'_{x,n,p,q}
92 *************************************************************************************/
93 typedef float floatType;
94 cudaDataType_t typeData = CUDA_R_32F;
95 cutensornetComputeType_t typeCompute = CUTENSORNET_COMPUTE_32F;
96
97 // Create vector of modes
98 std::vector<int32_t> modesAIn{'i','j','k','l'};
99 std::vector<int32_t> modesBIn{'k','o','p','q'};
100 std::vector<int32_t> modesGIn{'m','n','l','o'}; // input, G is the gate operator
101
102 std::vector<int32_t> modesAOut{'i','j','x','m'};
103 std::vector<int32_t> modesBOut{'x','n','p','q'}; // SVD output
104
105 // Extents
106 std::unordered_map<int32_t, int64_t> extent;
107 extent['i'] = 16;
108 extent['j'] = 16;
109 extent['k'] = 16;
110 extent['l'] = 2;
111 extent['m'] = 2;
112 extent['n'] = 2;
113 extent['o'] = 2;
114 extent['p'] = 16;
115 extent['q'] = 16;
116
117 const int64_t maxExtent = 16; //truncate to a maximal extent of 16
118 extent['x'] = maxExtent;
119
120 // Create a vector of extents for each tensor
121 std::vector<int64_t> extentAIn;
122 for (auto mode : modesAIn)
123 extentAIn.push_back(extent[mode]);
124 std::vector<int64_t> extentBIn;
125 for (auto mode : modesBIn)
126 extentBIn.push_back(extent[mode]);
127 std::vector<int64_t> extentGIn;
128 for (auto mode : modesGIn)
129 extentGIn.push_back(extent[mode]);
130 std::vector<int64_t> extentAOut;
131 for (auto mode : modesAOut)
132 extentAOut.push_back(extent[mode]);
133 std::vector<int64_t> extentBOut;
134 for (auto mode : modesBOut)
135 extentBOut.push_back(extent[mode]);
136
Execution#
Similar to SVD example, we can specify the SVD options in cutensornetTensorSVDConfig_t.
Workspace size query can be achieved by calling cutensornetWorkspaceComputeGateSplitSizes() with the provided cutensornetGateSplitAlgo_t.
Finally, we can execute the gate split computation by calling cutensornetGateSplit().
305 /**********************
306 * Execution
307 **********************/
308
309 GPUTimer timer{stream};
310 double minTimeCUTENSOR = 1e100;
311 const int numRuns = 3; // to get stable perf results
312 for (int i=0; i < numRuns; ++i)
313 {
314 // restore output
315 cudaMemsetAsync(D_AOut, 0, sizeAOut, stream);
316 cudaMemsetAsync(D_S, 0, sizeS, stream);
317 cudaMemsetAsync(D_BOut, 0, sizeBOut, stream);
318
319 // With value-based truncation, `cutensornetGateSplit` can potentially update the shared extent in descTensorA/BOut.
320 // We here restore descTensorA/BOut to the original problem.
321 HANDLE_ERROR( cutensornetDestroyTensorDescriptor(descTensorAOut) );
322 HANDLE_ERROR( cutensornetDestroyTensorDescriptor(descTensorBOut) );
323 HANDLE_ERROR( cutensornetCreateTensorDescriptor(handle, numModesAOut, extentAOut.data(), strides, modesAOut.data(), typeData, &descTensorAOut) );
324 HANDLE_ERROR( cutensornetCreateTensorDescriptor(handle, numModesBOut, extentBOut.data(), strides, modesBOut.data(), typeData, &descTensorBOut) );
325
326 cudaDeviceSynchronize();
327 timer.start();
328 HANDLE_ERROR( cutensornetGateSplit(handle,
329 descTensorAIn, D_AIn,
330 descTensorBIn, D_BIn,
331 descTensorGIn, D_GIn,
332 descTensorAOut, D_AOut,
333 D_S,
334 descTensorBOut, D_BOut,
335 gateAlgo,
336 svdConfig, typeCompute, svdInfo,
337 workDesc, stream) );
338 // Synchronize and measure timing
339 auto time = timer.seconds();
340 minTimeCUTENSOR = (minTimeCUTENSOR < time) ? minTimeCUTENSOR : time;
341 }
342
343 printf("Performing Gate Split\n");
Note
Like in cutensornetTensorSVD(), since we turned on weighted truncation options in this example, the tensor descriptors for outputs A and B need to be
restored if we wish to perform the same computation multiple times.
After the computation, we always need to free up all resources.
Code example (MPS factorization)#
The following code example illustrates how to integrate cuTensorNet functionalities to perform basic MPS simulation.
The workflow is encapsulated in an MPSHelper class. The full code can be found in
the NVIDIA/cuQuantum repository (here).
Define MPSHelper class#
We first define an MPSHelper class to keep track of the modes and extents of all physical and virtual bonds.
The simulation settings are also stored in this class. Once out of scope, all resource owned by this class will be freed.
81class MPSHelper
82{
83 public:
84 /**
85 * \brief Construct an MPSHelper object for gate splitting algorithm.
86 * i j k
87 * -------A-------B------- i j k
88 * p| |q -------> -------A`-------B`-------
89 * GGGGGGGGG r| |s
90 * r| |s
91 * \param[in] numSites The number of sites in the MPS
92 * \param[in] physExtent The extent for the physical mode where the gate tensors are acted on.
93 * \param[in] maxVirtualExtent The maximal extent allowed for the virtual mode shared between adjacent MPS tensors.
94 * \param[in] initialVirtualExtents A vector of size \p numSites-1 where the ith element denotes the extent of the shared mode for site i and site i+1 in the beginning of the simulation.
95 * \param[in] typeData The data type for all tensors and gates
96 * \param[in] typeCompute The compute type for all gate splitting process
97 */
98 MPSHelper(int32_t numSites,
99 int64_t physExtent,
100 int64_t maxVirtualExtent,
101 const std::vector<int64_t>& initialVirtualExtents,
102 cudaDataType_t typeData,
103 cutensornetComputeType_t typeCompute);
104
105 /**
106 * \brief Initialize the MPS metadata and cutensornet library.
107 */
108 cutensornetStatus_t initialize();
109
110 /**
111 * \brief Compute the maximal number of elements for each site.
112 */
113 std::vector<size_t> getMaxTensorElements() const;
114
115 /**
116 * \brief Update the SVD truncation setting.
117 * \param[in] absCutoff The cutoff value for absolute singular value truncation.
118 * \param[in] relCutoff The cutoff value for relative singular value truncation.
119 * \param[in] renorm The option for renormalization of the truncated singular values.
120 * \param[in] partition The option for partitioning of the singular values.
121 */
122 cutensornetStatus_t setSVDConfig(double absCutoff,
123 double relCutoff,
124 cutensornetTensorSVDNormalization_t renorm,
125 cutensornetTensorSVDPartition_t partition);
126
127 /**
128 * \brief Update the algorithm to use for the gating process.
129 * \param[in] gateAlgo The gate algorithm to use for MPS simulation.
130 */
131 void setGateAlgorithm(cutensornetGateSplitAlgo_t gateAlgo) {gateAlgo_ = gateAlgo;}
132
133 /**
134 * \brief Compute the maximal workspace needed for MPS gating algorithm.
135 * \param[out] workspaceSize The required workspace size on the device.
136 */
137 cutensornetStatus_t computeMaxWorkspaceSizes(int64_t* workspaceSize);
138
139 /**
140 * \brief Compute the maximal workspace needed for MPS gating algorithm.
141 * \param[in] work Pointer to the allocated workspace.
142 * \param[in] workspaceSize The required workspace size on the device.
143 */
144 cutensornetStatus_t setWorkspace(void* work, int64_t workspaceSize);
145
146 /**
147 * \brief In-place execution of the apply gate algorithm on \p siteA and \p siteB.
148 * \param[in] siteA The first site where the gate is applied to.
149 * \param[in] siteB The second site where the gate is applied to. Must be adjacent to \p siteA.
150 * \param[in,out] dataInA The data for the MPS tensor at \p siteA. The input will be overwritten with output mps tensor data.
151 * \param[in,out] dataInB The data for the MPS tensor at \p siteB. The input will be overwritten with output mps tensor data.
152 * \param[in] dataInG The input data for the gate tensor.
153 * \param[in] verbose Whether to print out the runtime information regarding truncation.
154 * \param[in] stream The CUDA stream on which the computation is performed.
155 */
156 cutensornetStatus_t applyGate(uint32_t siteA,
157 uint32_t siteB,
158 void* dataInA,
159 void* dataInB,
160 const void* dataInG,
161 bool verbose,
162 cudaStream_t stream);
163
164 /**
165 * \brief Free all the tensor descriptors in mpsHelper.
166 */
167 ~MPSHelper()
168 {
169 if (inited_)
170 {
171 for (auto& descTensor: descTensors_)
172 {
173 cutensornetDestroyTensorDescriptor(descTensor);
174 }
175 cutensornetDestroy(handle_);
176 cutensornetDestroyWorkspaceDescriptor(workDesc_);
177 }
178 if (svdConfig_ != nullptr)
179 {
180 cutensornetDestroyTensorSVDConfig(svdConfig_);
181 }
182 if (svdInfo_ != nullptr)
183 {
184 cutensornetDestroyTensorSVDInfo(svdInfo_);
185 }
186 }
187
188 private:
189 int32_t numSites_; ///< Number of sites in the MPS
190 int64_t physExtent_; ///< Extent for the physical index
191 int64_t maxVirtualExtent_{0}; ///< The maximal extent allowed for the virtual dimension
192 cudaDataType_t typeData_;
193 cutensornetComputeType_t typeCompute_;
194
195 bool inited_{false};
196 std::vector<int32_t> physModes_; ///< A vector of length \p numSites_ storing the physical mode of each site.
197 std::vector<int32_t> virtualModes_; ///< A vector of length \p numSites_+1; For site i, virtualModes_[i] and virtualModes_[i+1] represents the left and right virtual mode.
198 std::vector<int64_t> extentsPerSite_; ///< A vector of length \p numSites_+1; For site i, extentsPerSite_[i] and extentsPerSite_[i+1] represents the left and right virtual extent.
199
200 cutensornetHandle_t handle_{nullptr};
201 std::vector<cutensornetTensorDescriptor_t> descTensors_; /// A vector of length \p numSites_ storing the cutensornetTensorDescriptor_t for each site
202 cutensornetWorkspaceDescriptor_t workDesc_{nullptr};
203 cutensornetTensorSVDConfig_t svdConfig_{nullptr};
204 cutensornetTensorSVDInfo_t svdInfo_{nullptr};
205 cutensornetGateSplitAlgo_t gateAlgo_{CUTENSORNET_GATE_SPLIT_ALGO_DIRECT};
206 int32_t nextMode_{0}; /// The next mode label to use for labelling site tensors and gates.
207};
Note
For full definition of all the methods, please refer to the sample here.
Setup MPS simulation setting#
Next, in the main function, we need to choose the simulation setting for the MPS simulation (i.e., the number of sites, the initial extents, and the data type).
564 /***********************************
565 * Step 1: basic MPS setup
566 ************************************/
567
568 // setup the simulation setting for the MPS
569 typedef std::complex<double> complexType;
570 cudaDataType_t typeData = CUDA_C_64F;
571 cutensornetComputeType_t typeCompute = CUTENSORNET_COMPUTE_64F;
572 int32_t numSites = 16;
573 int64_t physExtent = 2;
574 int64_t maxVirtualExtent = 12;
575 const std::vector<int64_t> initialVirtualExtents(numSites-1, 1); // starting MPS with shared extent of 1;
576
577 // initialize an MPSHelper to dynamically update tensor metadats
578 MPSHelper mpsHelper(numSites, physExtent, maxVirtualExtent, initialVirtualExtents, typeData, typeCompute);
579 HANDLE_ERROR( mpsHelper.initialize() );
The MPS metadata and all cuTensorNet library objects will be managed by the MPSHelper while the data pointers are explicitly
managed in the main function.
Allocate memory and initialize data#
Next, we allocate memory for the MPS operands and four 2-qubit gate tensors.
The largest tensor size for each MPS tensor can be queried through the MPSHelper class.
The MPS tensors are initialized to a state corresponding to |00..000> and the gate tensors are filled with random values.
582 /***********************************
583 * Step 2: data allocation
584 ************************************/
585
586 // query largest tensor sizes for the MPS
587 const std::vector<size_t> maxElementsPerSite = mpsHelper.getMaxTensorElements();
588 std::vector<void*> tensors_h;
589 std::vector<void*> tensors_d;
590 for (int32_t i=0; i<numSites; i++)
591 {
592 size_t maxSize = sizeof(complexType) * maxElementsPerSite.at(i);
593 void* data_h = malloc(maxSize);
594 memset(data_h, 0, maxSize);
595 // initialize state to |0000..0000>
596 *(complexType*)(data_h) = complexType(1,0);
597 void* data_d;
598 HANDLE_CUDA_ERROR( cudaMalloc(&data_d, maxSize) );
599 // data transfer from host to device
600 HANDLE_CUDA_ERROR( cudaMemcpy(data_d, data_h, maxSize, cudaMemcpyHostToDevice) );
601 tensors_h.push_back(data_h);
602 tensors_d.push_back(data_d);
603 }
604
605 // initialize 4 random gate tensors on host and copy them to device
606 const int32_t numRandomGates = 4;
607 const int64_t numGateElements = physExtent * physExtent * physExtent * physExtent; // shape (2, 2, 2, 2)
608 size_t gateSize = sizeof(complexType) * numGateElements;
609 complexType* gates_h[numRandomGates];
610 void* gates_d[numRandomGates];
611
612 for (int i=0; i<numRandomGates; i++)
613 {
614 gates_h[i] = (complexType*) malloc(gateSize);
615 HANDLE_CUDA_ERROR( cudaMalloc((void**) &gates_d[i], gateSize) );
616 for (int j=0; j<numGateElements; j++)
617 {
618 gates_h[i][j] = complexType(((float) rand())/RAND_MAX, ((float) rand())/RAND_MAX);
619 }
620 HANDLE_CUDA_ERROR( cudaMemcpy(gates_d[i], gates_h[i], gateSize, cudaMemcpyHostToDevice) );
621 }
622
Setup gate split options#
Then we setup the SVD truncation parameters and the algorithm cutensornetGateSplitAlgo_t to use for the gate split process.
624 /*****************************************
625 * Step 3: setup options for gate operation
626 ******************************************/
627
628 double absCutoff = 1e-2;
629 double relCutoff = 1e-2;
630 cutensornetTensorSVDNormalization_t renorm = CUTENSORNET_TENSOR_SVD_NORMALIZATION_L2; // renormalize the L2 norm of truncated singular values to 1.
631 cutensornetTensorSVDPartition_t partition = CUTENSORNET_TENSOR_SVD_PARTITION_UV_EQUAL; // equally partition the singular values onto U and V;
632 HANDLE_ERROR( mpsHelper.setSVDConfig(absCutoff, relCutoff, renorm, partition));
633
634 cutensornetGateSplitAlgo_t gateAlgo = CUTENSORNET_GATE_SPLIT_ALGO_REDUCED;
635 mpsHelper.setGateAlgorithm(gateAlgo);
Query and allocate required workspace#
Once all simulation settings are set, we can query the required workspace size. Inside the MPSHelper, the required workspace size is estimated on the largest tensor sizes involved in the simulation.
638 /********************************************
639 * Step 4: workspace size query and allocation
640 *********************************************/
641
642 int64_t workspaceSize;
643 HANDLE_ERROR( mpsHelper.computeMaxWorkspaceSizes(&workspaceSize) );
644
645 void *work = nullptr;
646 std::cout << "Maximal workspace size required: " << workspaceSize << std::endl;
647 HANDLE_CUDA_ERROR( cudaMalloc(&work, workspaceSize) );
648
649 HANDLE_ERROR( mpsHelper.setWorkspace(work, workspaceSize));
650
Execution#
At this stage, we can execute the simulation by iterating over all the gate tensors.
All the metadata of the MPS will be managed and updated inside the MPSHelper.
652 /***********************************
653 * Step 5: execution
654 ************************************/
655
656 cudaStream_t stream;
657 HANDLE_CUDA_ERROR( cudaStreamCreate(&stream) );
658 uint32_t numLayers = 10; // 10 layers of gate
659 for (uint32_t i=0; i<numLayers; i++)
660 {
661 uint32_t start_site = i % 2;
662 std::cout << "Cycle " << i << ":" << std::endl;
663 bool verbose = (i == numLayers - 1);
664 for (uint32_t j=start_site; j<numSites-1; j=j+2)
665 {
666 uint32_t gateIdx = rand() % numRandomGates; // pick a random gate tensor
667 std::cout << "apply gate " << gateIdx << " on " << j << " and " << j+1<< std::endl;
668 void *dataA = tensors_d[j];
669 void *dataB = tensors_d[j+1];
670 void *dataG = gates_d[gateIdx];
671 HANDLE_ERROR( mpsHelper.applyGate(j, j+1, dataA, dataB, dataG, verbose, stream) );
672 }
673 }
674
675 HANDLE_CUDA_ERROR( cudaStreamSynchronize(stream) );
Free resources#
After the simulation, we free up all the data pointers allocated in the main function.
678 /***********************************
679 * Step 6: free resources
680 ************************************/
681
682 std::cout << "Free all resources" << std::endl;
683
684 for (int i=0; i<numRandomGates; i++)
685 {
686 free(gates_h[i]);
687 HANDLE_CUDA_ERROR( cudaFree(gates_d[i]) );
688 }
689
690 for (int32_t i=0; i<numSites; i++)
691 {
692 free(tensors_h.at(i));
693 HANDLE_CUDA_ERROR( cudaFree(tensors_d.at(i)) );
694 }
695
696 HANDLE_CUDA_ERROR( cudaFree(work) );
697 // The MPSHelper destructor will free all internal resources when out of scope
698 return 0;
699}
All cuTensorNet library objects owned by the MPSHelper will be freed once out of scope.
Code example (intermediate tensor reuse)#
Caching/Reusing constant intermediate tensors#
The following code example illustrates how to activate caching of constant intermediate tensors in order to greatly accelerate the repeated execution of a tensor network contraction where only some of the input tensors change their values in each iteration. The full code can be found in the NVIDIA/cuQuantum repository (here).
Headers and data types#
8#include <stdlib.h>
9#include <stdio.h>
10
11#include <unordered_map>
12#include <vector>
13#include <cassert>
14
15#include <cuda_runtime.h>
16#include <cutensornet.h>
17
18#define HANDLE_ERROR(x) \
19 do { \
20 const auto err = x; \
21 if (err != CUTENSORNET_STATUS_SUCCESS) \
22 { \
23 printf("Error: %s in line %d\n", cutensornetGetErrorString(err), __LINE__); \
24 fflush(stdout); \
25 exit(EXIT_FAILURE); \
26 } \
27 } while (0)
28
29#define HANDLE_CUDA_ERROR(x) \
30 do { \
31 const auto err = x; \
32 if (err != cudaSuccess) \
33 { \
34 printf("CUDA Error: %s in line %d\n", cudaGetErrorString(err), __LINE__); \
35 fflush(stdout); \
36 exit(EXIT_FAILURE); \
37 } \
38 } while (0)
39
40// Usage: DEV_ATTR(cudaDevAttrClockRate, deviceId)
41#define DEV_ATTR(ENUMCONST, DID) \
42 ({ int v; \
43 HANDLE_CUDA_ERROR(cudaDeviceGetAttribute(&v, ENUMCONST, DID)); \
44 v; })
45
46struct GPUTimer
47{
48 GPUTimer(cudaStream_t stream) : stream_(stream)
49 {
50 HANDLE_CUDA_ERROR(cudaEventCreate(&start_));
51 HANDLE_CUDA_ERROR(cudaEventCreate(&stop_));
52 }
53
54 ~GPUTimer()
55 {
56 HANDLE_CUDA_ERROR(cudaEventDestroy(start_));
57 HANDLE_CUDA_ERROR(cudaEventDestroy(stop_));
58 }
59
60 void start() { HANDLE_CUDA_ERROR(cudaEventRecord(start_, stream_)); }
61
62 float seconds()
63 {
64 HANDLE_CUDA_ERROR(cudaEventRecord(stop_, stream_));
65 HANDLE_CUDA_ERROR(cudaEventSynchronize(stop_));
66 float time;
67 HANDLE_CUDA_ERROR(cudaEventElapsedTime(&time, start_, stop_));
68 return time * 1e-3;
69 }
70
71private:
72 cudaEvent_t start_, stop_;
73 cudaStream_t stream_;
74};
75
76int main()
77{
78 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
79
80 bool verbose = true;
81
82 // Check cuTensorNet version
83 const size_t cuTensornetVersion = cutensornetGetVersion();
84 if (verbose) printf("cuTensorNet version: %ld\n", cuTensornetVersion);
85
86 // Set GPU device
87 int numDevices{0};
88 HANDLE_CUDA_ERROR(cudaGetDeviceCount(&numDevices));
89 const int deviceId = 0;
90 HANDLE_CUDA_ERROR(cudaSetDevice(deviceId));
91 cudaDeviceProp prop;
92 HANDLE_CUDA_ERROR(cudaGetDeviceProperties(&prop, deviceId));
93
94 if (verbose)
95 {
96 printf("===== device info ======\n");
97 printf("GPU-local-id:%d\n", deviceId);
98 printf("GPU-name:%s\n", prop.name);
99 printf("GPU-clock:%d\n", DEV_ATTR(cudaDevAttrClockRate, deviceId));
100 printf("GPU-memoryClock:%d\n", DEV_ATTR(cudaDevAttrMemoryClockRate, deviceId));
101 printf("GPU-nSM:%d\n", prop.multiProcessorCount);
102 printf("GPU-major:%d\n", prop.major);
103 printf("GPU-minor:%d\n", prop.minor);
104 printf("========================\n");
105 }
106
107 typedef float floatType;
108 cudaDataType_t typeData = CUDA_R_32F;
109 cutensornetComputeType_t typeCompute = CUTENSORNET_COMPUTE_32F;
110
111 if (verbose) printf("Included headers and defined data types\n");
Define tensor network and tensor sizes#
Next, we define the structure of the tensor network (i.e., the modes of the tensors, their extents, and their connectivity).
115 /**********************
116 * Computing: O_{a,m} = A_{a,b,c,d} B_{b,c,d,e} C_{e,f,g,h} D_{g,h,i,j} E_{i,j,k,l} F_{k,l,m}
117 * We will execute the contraction a few times assuming all input tensors being constant except F.
118 **********************/
119
120 constexpr int32_t numInputs = 6;
121
122 // Create vectors of tensor modes
123 std::vector<std::vector<int32_t>> tensorModes{ // for input tensors & output tensor
124 // input tensors
125 {'a', 'b', 'c', 'd'}, // tensor A
126 {'b', 'c', 'd', 'e'}, // tensor B
127 {'e', 'f', 'g', 'h'}, // tensor C
128 {'g', 'h', 'i', 'j'}, // tensor D
129 {'i', 'j', 'k', 'l'}, // tensor E
130 {'k', 'l', 'm'}, // tensor F
131 // output tensor
132 {'a', 'm'}}; // tensor O
133
134 // Set mode extents
135 int64_t sameExtent = 36; // setting same extent for simplicity. In principle extents can differ.
136 std::unordered_map<int32_t, int64_t> extent;
137 for (auto& vec : tensorModes)
138 {
139 for (auto& mode : vec)
140 {
141 extent[mode] = sameExtent;
142 }
143 }
144
145 // Create a vector of extents for each tensor
146 std::vector<std::vector<int64_t>> tensorExtents;
147 tensorExtents.resize(numInputs + 1); // hold inputs + output tensors
148 for (int32_t t = 0; t < numInputs + 1; ++t)
149 {
150 for (auto& mode : tensorModes[t]) tensorExtents[t].push_back(extent[mode]);
151 }
152
153 if (verbose) printf("Defined tensor network, modes, and extents\n");
Allocate memory, initialize data, initialize cuTensorNet handle#
Next, we allocate memory for the tensor network operands and initialize them to random values.
Then, we initialize the cuTensorNet library via cutensornetCreate().
156 /**********************
157 * Allocating data
158 **********************/
159
160 std::vector<size_t> tensorElements(numInputs + 1); // hold inputs + output tensors
161 std::vector<size_t> tensorSizes(numInputs + 1); // hold inputs + output tensors
162 std::vector<std::vector<int64_t>> tensorStrides(numInputs + 1); // hold inputs + output tensors
163 size_t totalSize = 0;
164 for (int32_t t = 0; t < numInputs + 1; ++t)
165 {
166 size_t numElements = 1;
167 for (auto& mode : tensorModes[t])
168 {
169 tensorStrides[t].push_back(numElements);
170 numElements *= extent[mode];
171 }
172 tensorElements[t] = numElements;
173
174 tensorSizes[t] = sizeof(floatType) * numElements;
175 totalSize += tensorSizes[t];
176 }
177 if (verbose) printf("Total GPU memory used for tensor storage: %.2f GiB\n", (totalSize) / 1024. / 1024. / 1024);
178
179 void* tensorData_d[numInputs + 1]; // for input tensors & output tensor
180 for (int32_t t = 0; t < numInputs + 1; ++t)
181 {
182 HANDLE_CUDA_ERROR(cudaMalloc((void**)&tensorData_d[t], tensorSizes[t]));
183 }
184
185 floatType* tensorData_h[numInputs + 1]; // for input tensors & output tensor
186 for (int32_t t = 0; t < numInputs + 1; ++t)
187 {
188 tensorData_h[t] = (floatType*)malloc(tensorSizes[t]);
189 if (tensorData_h[t] == NULL)
190 {
191 printf("Error: Host memory allocation failed!\n");
192 return -1;
193 }
194 }
195
196 /*******************
197 * Initialize data
198 *******************/
199
200 // init output tensor to all 0s
201 memset(tensorData_h[numInputs], 0, tensorSizes[numInputs]);
202 // init input tensors to random values
203 for (int32_t t = 0; t < numInputs; ++t)
204 {
205 for (size_t e = 0; e < tensorElements[t]; ++e) tensorData_h[t][e] = ((floatType)rand()) / RAND_MAX;
206 }
207 // copy input data to device buffers
208 for (int32_t t = 0; t < numInputs; ++t)
209 {
210 HANDLE_CUDA_ERROR(cudaMemcpy(tensorData_d[t], tensorData_h[t], tensorSizes[t], cudaMemcpyHostToDevice));
211 }
212
213 /*************************
214 * cuTensorNet
215 *************************/
216
217 cudaStream_t stream;
218 HANDLE_CUDA_ERROR(cudaStreamCreate(&stream));
219
220 cutensornetHandle_t handle;
221 HANDLE_ERROR(cutensornetCreate(&handle));
222
223 if (verbose) printf("Allocated GPU memory for data, initialized data, and created library handle\n");
Mark constant tensors and create the network descriptor#
Next, we specify which input tensors are constant, and create the network descriptor with the desired tensor modes, extents, strides, and qualifiers (e.g., constant) as well as the data and compute types. Note that the created library context will be associated with the currently active GPU.
226 /*******************************
227 * Set constant input tensors
228 *******************************/
229
230 // specify which input tensors are constant
231 std::vector<cutensornetTensorQualifiers_t> qualifiersIn(numInputs, cutensornetTensorQualifiers_t{0, 0, 0});
232 for (int i = 0; i < numInputs; ++i)
233 {
234 qualifiersIn[i].isConstant = i < (numInputs - 1) ? 1 : 0;
235 }
236
237 /*******************************
238 * Create Network
239 *******************************/
240
241 // Set up tensor network
242 cutensornetNetworkDescriptor_t networkDesc;
243 HANDLE_ERROR(cutensornetCreateNetwork(handle, &networkDesc));
244
245 int64_t tensorIDs[numInputs]; // for input tensors
246 // attach the input tensors to the network
247 for (int32_t t = 0; t < numInputs; ++t)
248 {
249 HANDLE_ERROR(cutensornetNetworkAppendTensor(handle,
250 networkDesc,
251 tensorModes[t].size(),
252 tensorExtents[t].data(),
253 tensorModes[t].data(),
254 &qualifiersIn[t],
255 typeData,
256 &tensorIDs[t]));
257 }
258
259 // set the output tensor
260 HANDLE_ERROR(cutensornetNetworkSetOutputTensor(handle,
261 networkDesc,
262 tensorModes[numInputs].size(),
263 tensorModes[numInputs].data(),
264 typeData));
265
266 // set the network compute type
267 HANDLE_ERROR(cutensornetNetworkSetAttribute(handle,
268 networkDesc,
269 CUTENSORNET_NETWORK_COMPUTE_TYPE,
270 &typeCompute,
271 sizeof(typeCompute)));
272 if (verbose) printf("Initialized the cuTensorNet library and created a tensor network\n");
Contraction order and slicing#
In this example, we illustrate using a predetermined contraction path and
setting it into the optimizer info object via cutensornetContractionOptimizerInfoSetAttribute().
We also attach the constructed optimizer info object to the network via cutensornetNetworkSetOptimizerInfo()
275 /*******************************
276 * Choose workspace limit based on available resources.
277 *******************************/
278
279 size_t freeMem, totalMem;
280 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeMem, &totalMem));
281 uint64_t workspaceLimit = (uint64_t)((double)freeMem * 0.9);
282 if (verbose) printf("Workspace limit = %lu\n", workspaceLimit);
283
284 /*******************************
285 * Set contraction order
286 *******************************/
287
288 // Create contraction optimizer info
289 cutensornetContractionOptimizerInfo_t optimizerInfo;
290 HANDLE_ERROR(cutensornetCreateContractionOptimizerInfo(handle, networkDesc, &optimizerInfo));
291
292 // set a predetermined contraction path
293 std::vector<int32_t> path{0, 1, 0, 4, 0, 3, 0, 2, 0, 1};
294 const auto numContractions = numInputs - 1;
295 cutensornetContractionPath_t contPath;
296 contPath.data = reinterpret_cast<cutensornetNodePair_t*>(const_cast<int32_t*>(path.data()));
297 contPath.numContractions = numContractions;
298
299 // provide user-specified contPath
300 HANDLE_ERROR(cutensornetContractionOptimizerInfoSetAttribute(handle,
301 optimizerInfo,
302 CUTENSORNET_CONTRACTION_OPTIMIZER_INFO_PATH,
303 &contPath,
304 sizeof(contPath)));
305
306 // Attach the optimizer info to the network
307 HANDLE_ERROR(cutensornetNetworkSetOptimizerInfo(handle,
308 networkDesc,
309 optimizerInfo));
310 int64_t numSlices = 1;
311
312 if (verbose) printf("Set predetermined contraction path into cuTensorNet optimizer\n");
Create workspace descriptor and allocate workspace memory#
Next, we create a workspace descriptor, compute the workspace sizes, and query the minimum workspace size needed
to contract the network.
To activate intermediate tensor reuse, we need to provide CACHE workspace that will be used across multiple network contractions.
Thus, we query sizes and allocate device memory for both kinds of workspaces
(CUTENSORNET_WORKSPACE_SCRATCH, and CUTENSORNET_WORKSPACE_CACHE) and set these in the workspace descriptor.
The workspace descriptor will be provided to the contraction preparing and computing APIs.
315 /*******************************
316 * Create workspace descriptor, allocate workspace, and set it.
317 *******************************/
318
319 cutensornetWorkspaceDescriptor_t workDesc;
320 HANDLE_ERROR(cutensornetCreateWorkspaceDescriptor(handle, &workDesc));
321
322 // set SCRATCH workspace, which will be used during each network contraction operation, not needed afterwords
323 int64_t requiredWorkspaceSizeScratch = 0;
324 HANDLE_ERROR(cutensornetWorkspaceComputeContractionSizes(handle, networkDesc, optimizerInfo, workDesc));
325
326 HANDLE_ERROR(cutensornetWorkspaceGetMemorySize(handle,
327 workDesc,
328 CUTENSORNET_WORKSIZE_PREF_MIN,
329 CUTENSORNET_MEMSPACE_DEVICE,
330 CUTENSORNET_WORKSPACE_SCRATCH,
331 &requiredWorkspaceSizeScratch));
332
333 void* workScratch = nullptr;
334 HANDLE_CUDA_ERROR(cudaMalloc(&workScratch, requiredWorkspaceSizeScratch));
335
336 HANDLE_ERROR(cutensornetWorkspaceSetMemory(handle,
337 workDesc,
338 CUTENSORNET_MEMSPACE_DEVICE,
339 CUTENSORNET_WORKSPACE_SCRATCH,
340 workScratch,
341 requiredWorkspaceSizeScratch));
342
343 // set CACHE workspace, which will be used across network contraction operations
344 int64_t requiredWorkspaceSizeCache = 0;
345 HANDLE_ERROR(cutensornetWorkspaceGetMemorySize(handle,
346 workDesc,
347 CUTENSORNET_WORKSIZE_PREF_MIN,
348 CUTENSORNET_MEMSPACE_DEVICE,
349 CUTENSORNET_WORKSPACE_CACHE,
350 &requiredWorkspaceSizeCache));
351
352 void* workCache = nullptr;
353 HANDLE_CUDA_ERROR(cudaMalloc(&workCache, requiredWorkspaceSizeCache));
354
355 HANDLE_ERROR(cutensornetWorkspaceSetMemory(handle,
356 workDesc,
357 CUTENSORNET_MEMSPACE_DEVICE,
358 CUTENSORNET_WORKSPACE_CACHE,
359 workCache,
360 requiredWorkspaceSizeCache));
361
362 if (verbose) printf("Allocated and set up the GPU workspace\n");
Note that, it is possible to skip the steps of creating a workspace descriptor and explicitly handling workspace memory by setting a device memory handler, in which case cuTensorNet will implicitly handle workspace memory by allocating/deallocating memory from the provided memory pool. See Memory management API for details.
Contraction preparation and auto-tuning#
We prepare the tensor network contraction, via cutensornetNetworkPrepareContraction(),
and set tensor’s data buffers and strides via cutensornetNetworkSetInputTensorMemory() and cutensornetNetworkSetOutputTensorMemory().
Optionally, we can auto-tune the contraction, via cutensornetNetworkAutotuneContraction(),
such that cuTENSOR selects the best kernel for each pairwise contraction.
This prepared network contraction can be reused for many (possibly different) data inputs, avoiding
the cost of initializing it redundantly.
365 /*******************************
366 * Prepare the contraction.
367 *******************************/
368
369 HANDLE_ERROR(cutensornetNetworkPrepareContraction(handle,
370 networkDesc,
371 workDesc));
372
373 // set tensor's data buffers and strides
374 for (int32_t t = 0; t < numInputs; ++t)
375 {
376 HANDLE_ERROR(cutensornetNetworkSetInputTensorMemory(handle,
377 networkDesc,
378 tensorIDs[t],
379 tensorData_d[t],
380 NULL));
381 }
382 HANDLE_ERROR(cutensornetNetworkSetOutputTensorMemory(handle,
383 networkDesc,
384 tensorData_d[numInputs],
385 NULL));
386 /*******************************
387 * Optional: Auto-tune the contraction to pick the fastest kernel
388 * for each pairwise tensor contraction.
389 *******************************/
390 cutensornetNetworkAutotunePreference_t autotunePref;
391 HANDLE_ERROR(cutensornetCreateNetworkAutotunePreference(handle,
392 &autotunePref));
393
394 const int numAutotuningIterations = 5; // may be 0
395 HANDLE_ERROR(cutensornetNetworkAutotunePreferenceSetAttribute(handle,
396 autotunePref,
397 CUTENSORNET_NETWORK_AUTOTUNE_MAX_ITERATIONS,
398 &numAutotuningIterations,
399 sizeof(numAutotuningIterations)));
400
401 // Modify the network again to find the best pair-wise contractions
402 HANDLE_ERROR(cutensornetNetworkAutotuneContraction(handle,
403 networkDesc,
404 workDesc,
405 autotunePref,
406 stream));
407
408 HANDLE_ERROR(cutensornetDestroyNetworkAutotunePreference(autotunePref));
409
410 if (verbose) printf("Prepared the network contraction for cuTensorNet and optionally auto-tuned it\n");
Tensor network contraction execution#
Finally, we contract the tensor network as many times as needed, possibly with different input each time. Note that the first network contraction call will utilize the provided CACHE workspace to store the constant intermediate tensors. Subsequent network contractions will use the cached data to greatly reduce the computation times.
413 /**********************
414 * Execute the tensor network contraction
415 **********************/
416
417 // Create a cutensornetSliceGroup_t object from a range of slice IDs
418 cutensornetSliceGroup_t sliceGroup{};
419 HANDLE_ERROR(cutensornetCreateSliceGroupFromIDRange(handle, 0, numSlices, 1, &sliceGroup));
420
421 GPUTimer timer{stream};
422 double minTimeCUTENSORNET = 1e100;
423 double firstTimeCUTENSORNET = 1e100;
424 const int numRuns = 3; // number of repeats to get stable performance results
425 for (int i = 0; i < numRuns; ++i)
426 {
427 // restore the output tensor on GPU
428 HANDLE_CUDA_ERROR(cudaMemcpy(tensorData_d[numInputs], tensorData_h[numInputs], tensorSizes[numInputs], cudaMemcpyHostToDevice));
429 HANDLE_CUDA_ERROR(cudaDeviceSynchronize());
430
431 /*
432 * Contract all slices of the tensor network
433 */
434 timer.start();
435
436 int32_t accumulateOutput = 0; // output tensor data will be overwritten
437 HANDLE_ERROR(cutensornetNetworkContract(handle,
438 networkDesc,
439 accumulateOutput,
440 workDesc,
441 sliceGroup, // alternatively, NULL can also be used to contract over
442 // all slices instead of specifying a sliceGroup object
443 stream));
444
445 // Synchronize and measure best timing
446 auto time = timer.seconds();
447 if (i == 0) firstTimeCUTENSORNET = time;
448 minTimeCUTENSORNET = (time > minTimeCUTENSORNET) ? minTimeCUTENSORNET : time;
449 }
450
451 if (verbose) printf("Contracted the tensor network, each slice used the same prepared contraction\n");
452
453 // Print the 1-norm of the output tensor (verification)
454 HANDLE_CUDA_ERROR(cudaStreamSynchronize(stream));
455 // restore the output tensor on Host
456 HANDLE_CUDA_ERROR(cudaMemcpy(tensorData_h[numInputs], tensorData_d[numInputs], tensorSizes[numInputs], cudaMemcpyDeviceToHost));
457 double norm1 = 0.0;
458 for (int64_t i = 0; i < tensorElements[numInputs]; ++i)
459 {
460 norm1 += std::abs(tensorData_h[numInputs][i]);
461 }
462 if (verbose) printf("Computed the 1-norm of the output tensor: %e\n", norm1);
463
464 /*************************/
465
466 // Query the total Flop count for the tensor network contraction
467 double flops{0.0};
468 HANDLE_ERROR(cutensornetContractionOptimizerInfoGetAttribute(handle,
469 optimizerInfo,
470 CUTENSORNET_CONTRACTION_OPTIMIZER_INFO_FLOP_COUNT,
471 &flops,
472 sizeof(flops)));
473
474 if (verbose)
475 {
476 printf("Number of tensor network slices = %ld\n", numSlices);
477 printf("Network contraction flop cost = %e\n", flops);
478 printf("Tensor network contraction time (ms):\n");
479 printf("\tfirst run (intermediate tensors get cached) = %.3f\n", firstTimeCUTENSORNET * 1000.f);
480 printf("\tsubsequent run (cache reused) = %.3f\n", minTimeCUTENSORNET * 1000.f);
481 }
Free resources#
After the computation, we need to free up all resources.
484 /***************
485 * Free resources
486 ****************/
487
488 // Free cuTensorNet resources
489 HANDLE_ERROR(cutensornetDestroySliceGroup(sliceGroup));
490 HANDLE_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
491 HANDLE_ERROR(cutensornetDestroyContractionOptimizerInfo(optimizerInfo));
492 HANDLE_ERROR(cutensornetDestroyNetwork(networkDesc));
493 HANDLE_ERROR(cutensornetDestroy(handle));
494
495 HANDLE_CUDA_ERROR(cudaStreamDestroy(stream));
496
497 // Free Host and GPU memory resources
498 for (int32_t t = 0; t < numInputs + 1; ++t)
499 {
500 if (tensorData_h[t]) free(tensorData_h[t]);
501 if (tensorData_d[t]) cudaFree(tensorData_d[t]);
502 }
503 // Free GPU memory resources
504 if (workScratch) cudaFree(workScratch);
505 if (workCache) cudaFree(workCache);
506 if (verbose) printf("Freed resources and exited\n");
507
508 return 0;
509}
Code example (gradients computation)#
Computing gradients via backward propagation#
The following code example illustrates how to compute the gradients of a tensor network w.r.t. user-selected input tensors via backward propagation. The full code can be found in the NVIDIA/cuQuantum repository (here).
This example uses the network-centric API introduced in cuTensorNet v2.9.0. Key functions include cutensornetCreateNetwork, cutensornetNetworkAppendTensor, cutensornetNetworkSetOutputTensor, cutensornetNetworkPrepareContraction, cutensornetNetworkContract, cutensornetNetworkSetAdjointTensorMemory, cutensornetNetworkSetGradientTensorMemory, cutensornetNetworkPrepareGradientsBackward, and cutensornetNetworkComputeGradientsBackward.
Headers and data types#
8#include <stdlib.h>
9#include <stdio.h>
10
11#include <algorithm>
12#include <unordered_map>
13#include <vector>
14#include <cassert>
15
16#include <cuda_runtime.h>
17#include <cutensornet.h>
18
19#define HANDLE_ERROR(x) \
20 do { \
21 const auto err = x; \
22 if (err != CUTENSORNET_STATUS_SUCCESS) \
23 { \
24 printf("Error: %s in line %d\n", cutensornetGetErrorString(err), __LINE__); \
25 fflush(stdout); \
26 exit(EXIT_FAILURE); \
27 } \
28 } while (0)
29
30#define HANDLE_CUDA_ERROR(x) \
31 do { \
32 const auto err = x; \
33 if (err != cudaSuccess) \
34 { \
35 printf("CUDA Error: %s in line %d\n", cudaGetErrorString(err), __LINE__); \
36 fflush(stdout); \
37 exit(EXIT_FAILURE); \
38 } \
39 } while (0)
40
41// Usage: DEV_ATTR(cudaDevAttrClockRate, deviceId)
42#define DEV_ATTR(ENUMCONST, DID) \
43 ({ int v; \
44 HANDLE_CUDA_ERROR(cudaDeviceGetAttribute(&v, ENUMCONST, DID)); \
45 v; })
46
47struct GPUTimer
48{
49 GPUTimer(cudaStream_t stream) : stream_(stream)
50 {
51 HANDLE_CUDA_ERROR(cudaEventCreate(&start_));
52 HANDLE_CUDA_ERROR(cudaEventCreate(&stop_));
53 }
54
55 ~GPUTimer()
56 {
57 HANDLE_CUDA_ERROR(cudaEventDestroy(start_));
58 HANDLE_CUDA_ERROR(cudaEventDestroy(stop_));
59 }
60
61 void start() { HANDLE_CUDA_ERROR(cudaEventRecord(start_, stream_)); }
62
63 float seconds()
64 {
65 HANDLE_CUDA_ERROR(cudaEventRecord(stop_, stream_));
66 HANDLE_CUDA_ERROR(cudaEventSynchronize(stop_));
67 float time;
68 HANDLE_CUDA_ERROR(cudaEventElapsedTime(&time, start_, stop_));
69 return time * 1e-3;
70 }
71
72private:
73 cudaEvent_t start_, stop_;
74 cudaStream_t stream_;
75};
76
77int main()
78{
79 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
80
81 bool verbose = true;
82
83 // Check cuTensorNet version
84 const size_t cuTensornetVersion = cutensornetGetVersion();
85 if (verbose) printf("cuTensorNet version: %ld\n", cuTensornetVersion);
86
87 // Set GPU device
88 int numDevices{0};
89 HANDLE_CUDA_ERROR(cudaGetDeviceCount(&numDevices));
90 const int deviceId = 0;
91 HANDLE_CUDA_ERROR(cudaSetDevice(deviceId));
92 cudaDeviceProp prop;
93 HANDLE_CUDA_ERROR(cudaGetDeviceProperties(&prop, deviceId));
94
95 if (verbose)
96 {
97 printf("===== device info ======\n");
98 printf("GPU-local-id:%d\n", deviceId);
99 printf("GPU-name:%s\n", prop.name);
100 printf("GPU-clock:%d\n", DEV_ATTR(cudaDevAttrClockRate, deviceId));
101 printf("GPU-memoryClock:%d\n", DEV_ATTR(cudaDevAttrMemoryClockRate, deviceId));
102 printf("GPU-nSM:%d\n", prop.multiProcessorCount);
103 printf("GPU-major:%d\n", prop.major);
104 printf("GPU-minor:%d\n", prop.minor);
105 printf("========================\n");
106 }
107
108 typedef float floatType;
109 cudaDataType_t typeData = CUDA_R_32F;
110 cutensornetComputeType_t typeCompute = CUTENSORNET_COMPUTE_32F;
111
112 if (verbose) printf("Included headers and defined data types\n");
Define tensor network and tensor sizes#
Next, we define the structure of the tensor network (i.e., the modes of the tensors, their extents, and their connectivity), and specify the input tensor IDs whose gradients will be computed.
See also the network definition APIs cutensornetCreateNetwork, cutensornetNetworkAppendTensor, and cutensornetNetworkSetOutputTensor.
116 /**********************
117 * Computing: O_{a,m} = A_{a,b,c,d} B_{b,c,d,e} C_{e,g,h} D_{g,h,i,j} E_{i,j,k,l} F_{k,l,m}
118 * We will execute the contraction and compute the gradients of input tensors A, B, C
119 **********************/
120
121 constexpr int32_t numInputs = 6;
122 std::vector<int32_t> gradInputIDs = {0, 1, 2};
123
124 // Create vectors of tensor modes
125 std::vector<std::vector<int32_t>> tensorModes{
126 {'a', 'b', 'c', 'd'}, // tensor A
127 {'b', 'c', 'd', 'e'}, // tensor B
128 {'e', 'g', 'h'}, // tensor C
129 {'g', 'h', 'i', 'j'}, // tensor D
130 {'i', 'j', 'k', 'l'}, // tensor E
131 {'k', 'l', 'm'}, // tensor F
132 {'a', 'm'} // tensor O
133 };
134
135 // Set mode extents
136 int64_t sameExtent = 36; // setting same extent for simplicity. In principle extents can differ.
137 std::unordered_map<int32_t, int64_t> extent;
138 for (auto& vec : tensorModes)
139 {
140 for (auto& mode : vec)
141 {
142 extent[mode] = sameExtent;
143 }
144 }
145
146 // Create a vector of extents for each tensor
147 std::vector<std::vector<int64_t>> tensorExtents; // for input tensors & output tensor
148 tensorExtents.resize(numInputs + 1); // hold inputs + output tensors
149 for (int32_t t = 0; t < numInputs + 1; ++t)
150 {
151 for (auto& mode : tensorModes[t]) tensorExtents[t].push_back(extent[mode]);
152 }
153
154 if (verbose) printf("Defined tensor network, modes, and extents\n");
Allocate memory, initialize data, initialize cuTensorNet handle#
Next, we allocate memory for the tensor network operands and initialize them to random values.
We also allocate memory for the gradient tensors corresponding to the selected input tensors for gradient computation,
as well as the activation tensor which we initialize to ones.
Then, we initialize the cuTensorNet library via cutensornetCreate().
Note that the created library context will be associated with the currently active GPU.
157 /**********************
158 * Allocating data
159 **********************/
160
161 std::vector<size_t> tensorElements(numInputs + 1); // for input tensors & output tensor
162 std::vector<size_t> tensorSizes(numInputs + 1); // for input tensors & output tensor
163 size_t totalSize = 0;
164 for (int32_t t = 0; t < numInputs + 1; ++t)
165 {
166 size_t numElements = 1;
167 for (auto& mode : tensorModes[t]) numElements *= extent[mode];
168 tensorElements[t] = numElements;
169
170 tensorSizes[t] = sizeof(floatType) * numElements;
171 totalSize += tensorSizes[t];
172 }
173
174 if (verbose) printf("Total GPU memory used for tensor storage: %.2f GiB\n", (totalSize) / 1024. / 1024. / 1024);
175
176 void* tensorData_d[numInputs + 1]; // for input tensors & output tensor
177 for (int32_t t = 0; t < numInputs + 1; ++t)
178 {
179 HANDLE_CUDA_ERROR(cudaMalloc((void**)&tensorData_d[t], tensorSizes[t]));
180 }
181 void* adjoint_d; // hold data of the adjoint/activation tensor
182 HANDLE_CUDA_ERROR(cudaMalloc((void**)&adjoint_d, tensorSizes[numInputs]));
183
184 floatType* tensorData_h[numInputs + 1]; // for input tensors & output tensor
185 for (int32_t t = 0; t < numInputs + 1; ++t)
186 {
187 tensorData_h[t] = (floatType*)malloc(tensorSizes[t]);
188 if (tensorData_h[t] == NULL)
189 {
190 printf("Error: Host memory allocation failed!\n");
191 return -1;
192 }
193 }
194 floatType* adjoint_h = (floatType*)malloc(tensorSizes[numInputs]);
195 if (adjoint_h == NULL)
196 {
197 printf("Error: Host memory allocation failed!\n");
198 return -1;
199 }
200
201 void* gradients_d[numInputs] = {nullptr};
202 for (auto i : gradInputIDs)
203 {
204 HANDLE_CUDA_ERROR(cudaMalloc((void**)&gradients_d[i], tensorSizes[i]));
205 }
206 void* gradients_h[numInputs] = {nullptr};
207 for (auto i : gradInputIDs)
208 {
209 gradients_h[i] = (floatType*)malloc(tensorSizes[i]);
210 if (gradients_h[i] == NULL)
211 {
212 printf("Error: Host memory allocation failed!\n");
213 return -1;
214 }
215 }
216
217 /*******************
218 * Initialize data
219 *******************/
220
221 // set output tensor data to all 0s
222 memset(tensorData_h[numInputs], 0, tensorSizes[numInputs]);
223 // init input tensors data to random values
224 for (int32_t t = 0; t < numInputs; ++t)
225 {
226 for (size_t e = 0; e < tensorElements[t]; ++e) tensorData_h[t][e] = ((floatType)rand()) / RAND_MAX;
227 }
228 // set activation tensor to all 1s
229 for (size_t e = 0; e < tensorElements[numInputs]; ++e) adjoint_h[e] = (floatType)1.0;
230
231 // copy tensors' data to device buffers
232 for (int32_t t = 0; t < numInputs; ++t)
233 {
234 HANDLE_CUDA_ERROR(cudaMemcpy(tensorData_d[t], tensorData_h[t], tensorSizes[t], cudaMemcpyHostToDevice));
235 }
236 HANDLE_CUDA_ERROR(cudaMemcpy(adjoint_d, adjoint_h, tensorSizes[numInputs], cudaMemcpyHostToDevice));
237
238 /*************************
239 * cuTensorNet
240 *************************/
241
242 cudaStream_t stream;
243 HANDLE_CUDA_ERROR(cudaStreamCreate(&stream));
244
245 cutensornetHandle_t handle;
246 HANDLE_ERROR(cutensornetCreate(&handle));
247
248 if (verbose) printf("Allocated GPU memory for data, initialized data, and created library handle\n");
Construct the network#
We create the network descriptor, and append the input tensors with the desired tensor modes and extents, as well as the data type. We can, optional, set the output tensor modes (if skipped, the output modes will be inferred). To compute gradients with respect to specific input tensors, those tensors must be tagged (e.g., specified) using tensor qualifiers.
251 /*******************************
252 * Create Network
253 *******************************/
254
255 // Set up tensor network
256 cutensornetNetworkDescriptor_t networkDesc;
257 HANDLE_ERROR(cutensornetCreateNetwork(handle, &networkDesc));
258
259 int64_t tensorIDs[numInputs]; // for input tensors
260 // attach the input tensors to the network
261 for (int32_t t = 0; t < numInputs; ++t)
262 {
263 cutensornetTensorQualifiers_t qualifiers{0, 0, 0};
264 qualifiers.requiresGradient = gradInputIDs.end() != std::find(gradInputIDs.begin(), gradInputIDs.end(), t);
265 HANDLE_ERROR(cutensornetNetworkAppendTensor(handle,
266 networkDesc,
267 tensorModes[t].size(),
268 tensorExtents[t].data(),
269 tensorModes[t].data(),
270 &qualifiers,
271 typeData,
272 &tensorIDs[t]));
273 }
274
275 // set output tensor of the network
276 HANDLE_ERROR(cutensornetNetworkSetOutputTensor(handle,
277 networkDesc,
278 tensorModes[numInputs].size(),
279 tensorModes[numInputs].data(),
280 typeData));
281
282 // set the network compute type
283 HANDLE_ERROR(cutensornetNetworkSetAttribute(handle,
284 networkDesc,
285 CUTENSORNET_NETWORK_COMPUTE_TYPE,
286 &typeCompute,
287 sizeof(typeCompute)));
288
289 if (verbose) printf("Initialized the cuTensorNet library and created a tensor network\n");
Contraction order#
In this example, we illustrate using a predetermined contraction path and
setting it into the optimizer info object via cutensornetContractionOptimizerInfoSetAttribute().
We also attach the constructed optimizer info object to the network via cutensornetNetworkSetOptimizerInfo()
292 /*******************************
293 * Choose workspace limit based on available resources.
294 *******************************/
295
296 size_t freeMem, totalMem;
297 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeMem, &totalMem));
298 uint64_t workspaceLimit = (uint64_t)((double)freeMem * 0.9);
299 if (verbose) printf("Workspace limit = %lu\n", workspaceLimit);
300
301 /*******************************
302 * Set contraction order
303 *******************************/
304
305 // Create contraction optimizer info
306 cutensornetContractionOptimizerInfo_t optimizerInfo;
307 HANDLE_ERROR(cutensornetCreateContractionOptimizerInfo(handle, networkDesc, &optimizerInfo));
308
309 // set a predetermined contraction path
310 std::vector<int32_t> path{0, 1, 0, 4, 0, 3, 0, 2, 0, 1};
311 const auto numContractions = numInputs - 1;
312 cutensornetContractionPath_t contPath;
313 contPath.data = reinterpret_cast<cutensornetNodePair_t*>(const_cast<int32_t*>(path.data()));
314 contPath.numContractions = numContractions;
315
316 // provide user-specified contPath
317 HANDLE_ERROR(cutensornetContractionOptimizerInfoSetAttribute(handle,
318 optimizerInfo,
319 CUTENSORNET_CONTRACTION_OPTIMIZER_INFO_PATH,
320 &contPath,
321 sizeof(contPath)));
322
323 // Attach the optimizer info to the network
324 HANDLE_ERROR(cutensornetNetworkSetOptimizerInfo(handle,
325 networkDesc,
326 optimizerInfo));
327 int64_t numSlices = 1;
328
329 if (verbose) printf("Set predetermined contraction path into cuTensorNet optimizer\n");
Create workspace descriptor and allocate workspace memory#
Next, we create a workspace descriptor, compute the workspace sizes, and query the minimum workspace size needed
to contract the network.
To enable gradient computation, we need to provide CACHE workspace that will be used to store intermediate tensors’ data
necessary for the backward propagation call to consume.
Thus, we query sizes and allocate device memory for both kinds of workspaces
(CUTENSORNET_WORKSPACE_SCRATCH, and CUTENSORNET_WORKSPACE_CACHE) and set these in the workspace descriptor.
The workspace descriptor will be provided to the contraction preparation, contraction computation, and gradient computation APIs.
See also cutensornetWorkspaceSetMemory, cutensornetWorkspaceGetMemorySize, and cutensornetWorkspacePurgeCache.
332 /*******************************
333 * Create workspace descriptor, allocate workspace, and set it.
334 *******************************/
335
336 cutensornetWorkspaceDescriptor_t workDesc;
337 HANDLE_ERROR(cutensornetCreateWorkspaceDescriptor(handle, &workDesc));
338
339 // set SCRATCH workspace, which will be used during each network contraction operation, not needed afterwords
340 int64_t requiredWorkspaceSizeScratch = 0;
341 HANDLE_ERROR(cutensornetWorkspaceComputeContractionSizes(handle, networkDesc, optimizerInfo, workDesc));
342
343 HANDLE_ERROR(cutensornetWorkspaceGetMemorySize(handle,
344 workDesc,
345 CUTENSORNET_WORKSIZE_PREF_MIN,
346 CUTENSORNET_MEMSPACE_DEVICE,
347 CUTENSORNET_WORKSPACE_SCRATCH,
348 &requiredWorkspaceSizeScratch));
349
350 void* workScratch = nullptr;
351 HANDLE_CUDA_ERROR(cudaMalloc(&workScratch, requiredWorkspaceSizeScratch));
352
353 HANDLE_ERROR(cutensornetWorkspaceSetMemory(handle,
354 workDesc,
355 CUTENSORNET_MEMSPACE_DEVICE,
356 CUTENSORNET_WORKSPACE_SCRATCH,
357 workScratch,
358 requiredWorkspaceSizeScratch));
359
360 // set CACHE workspace, which will be used across network contraction operations
361 int64_t requiredWorkspaceSizeCache = 0;
362 HANDLE_ERROR(cutensornetWorkspaceGetMemorySize(handle,
363 workDesc,
364 CUTENSORNET_WORKSIZE_PREF_MIN,
365 CUTENSORNET_MEMSPACE_DEVICE,
366 CUTENSORNET_WORKSPACE_CACHE,
367 &requiredWorkspaceSizeCache));
368
369 void* workCache = nullptr;
370 HANDLE_CUDA_ERROR(cudaMalloc(&workCache, requiredWorkspaceSizeCache));
371
372 HANDLE_ERROR(cutensornetWorkspaceSetMemory(handle,
373 workDesc,
374 CUTENSORNET_MEMSPACE_DEVICE,
375 CUTENSORNET_WORKSPACE_CACHE,
376 workCache,
377 requiredWorkspaceSizeCache));
378
379 if (verbose) printf("Allocated and set up the GPU workspace\n");
Contraction preparation and auto-tuning#
We prepare the tensor network contraction, via cutensornetNetworkPrepareContraction().
Optionally, we can auto-tune the contraction, via cutensornetNetworkAutotuneContraction(),
such that cuTENSOR selects the best kernel for each pairwise contraction.
This prepared network contraction can be reused for many (possibly different) data inputs, avoiding
the cost of re-initializing it redundantly.
In the network-centric flow, see also cutensornetNetworkAutotuneContraction.
Input and output buffers are attached using cutensornetNetworkSetInputTensorMemory, and cutensornetNetworkSetOutputTensorMemory.
382 /**********************************
383 * Prepare the network contraction.
384 **********************************/
385
386 // set tensor's data buffers and strides
387 for (int32_t t = 0; t < numInputs; ++t)
388 {
389 HANDLE_ERROR(cutensornetNetworkSetInputTensorMemory(handle,
390 networkDesc,
391 tensorIDs[t],
392 tensorData_d[t],
393 NULL));
394 }
395 HANDLE_ERROR(cutensornetNetworkSetOutputTensorMemory(handle,
396 networkDesc,
397 tensorData_d[numInputs],
398 NULL));
399
400 HANDLE_ERROR(cutensornetNetworkPrepareContraction(handle,
401 networkDesc,
402 workDesc));
403
404 /*******************************
405 * Optional: Auto-tune the network's contraction to pick the fastest kernel
406 * for each pairwise tensor contraction.
407 *******************************/
408 cutensornetNetworkAutotunePreference_t autotunePref;
409 HANDLE_ERROR(cutensornetCreateNetworkAutotunePreference(handle, &autotunePref));
410
411 const int numAutotuningIterations = 5; // may be 0
412 HANDLE_ERROR(cutensornetNetworkAutotunePreferenceSetAttribute(handle,
413 autotunePref,
414 CUTENSORNET_NETWORK_AUTOTUNE_MAX_ITERATIONS,
415 &numAutotuningIterations,
416 sizeof(numAutotuningIterations)));
417
418 // Autotune the network to find the best pair-wise contractions
419 HANDLE_ERROR(cutensornetNetworkAutotuneContraction(handle,
420 networkDesc,
421 workDesc,
422 autotunePref,
423 stream));
424
425 HANDLE_ERROR(cutensornetDestroyNetworkAutotunePreference(autotunePref));
426
427 if (verbose) printf("Prepared the network contraction for cuTensorNet and optionally auto-tuned it\n");
Tensor network contraction execution and gradient computation#
Finally, we contract the tensor network via cutensornetNetworkContract().
After contracting the network (which will store intermediate tensors’ data in the CACHE memory),
we prepare the gradient computation via cutensornetNetworkPrepareGradientsBackward()
and compute the required gradients through backward propagation via cutensornetNetworkComputeGradientsBackward().
We must purge the CACHE memory for each data set to allow the network contraction call to store the correct intermediate data in the CACHE memory.
Gradient and adjoint/activation buffers are attached using cutensornetNetworkSetGradientTensorMemory, and cutensornetNetworkSetAdjointTensorMemory.
See also cutensornetNetworkPrepareGradientsBackward, cutensornetNetworkComputeGradientsBackward, and cutensornetWorkspacePurgeCache.
430 /**********************
431 * Execute the tensor network contraction
432 **********************/
433
434 // Create a cutensornetSliceGroup_t object from a range of slice IDs
435 cutensornetSliceGroup_t sliceGroup{};
436 HANDLE_ERROR(cutensornetCreateSliceGroupFromIDRange(handle, 0, numSlices, 1, &sliceGroup));
437
438 GPUTimer timer{stream};
439 // restore the output tensor on GPU
440 HANDLE_CUDA_ERROR(cudaMemcpy(tensorData_d[numInputs], tensorData_h[numInputs], tensorSizes[numInputs], cudaMemcpyHostToDevice));
441 HANDLE_CUDA_ERROR(cudaDeviceSynchronize());
442
443 /*
444 * Contract all slices of the tensor network
445 */
446 timer.start();
447
448 int32_t accumulateOutput = 0; // output tensor data will be overwritten
449 HANDLE_ERROR(cutensornetNetworkContract(handle,
450 networkDesc,
451 accumulateOutput,
452 workDesc,
453 sliceGroup, // alternatively, NULL can also be used to contract over all slices instead of specifying a sliceGroup object
454 stream));
455
456 // Synchronize and measure timing
457 auto time = timer.seconds();
458
459 /**********************
460 * Prepare the tensor network gradient computation
461 **********************/
462
463 HANDLE_ERROR(cutensornetNetworkSetAdjointTensorMemory(handle, networkDesc, adjoint_d, NULL));
464
465 for (auto gid : gradInputIDs) // for only those tensors that require the gradient
466 {
467 HANDLE_ERROR(cutensornetNetworkSetGradientTensorMemory(handle,
468 networkDesc,
469 gid,
470 gradients_d[gid], NULL));
471 }
472
473 HANDLE_ERROR(cutensornetNetworkPrepareGradientsBackward(handle, networkDesc, workDesc));
474
475 /**********************
476 * Execute the tensor network gradient computation
477 **********************/
478 timer.start();
479
480 HANDLE_ERROR(cutensornetNetworkComputeGradientsBackward(handle,
481 networkDesc,
482 accumulateOutput,
483 workDesc,
484 sliceGroup, // alternatively, NULL can also be used to contract over all slices instead of specifying a sliceGroup object
485 stream));
486 // Synchronize and measure timing
487 time += timer.seconds();
488
489 if (verbose) printf("Contracted the tensor network and computed gradients\n");
490
491 // restore the output tensor on Host
492 HANDLE_CUDA_ERROR(cudaMemcpy(tensorData_h[numInputs], tensorData_d[numInputs], tensorSizes[numInputs], cudaMemcpyDeviceToHost));
493
494 for (auto i : gradInputIDs)
495 {
496 HANDLE_CUDA_ERROR(cudaMemcpy(gradients_h[i], gradients_d[i], tensorSizes[i], cudaMemcpyDeviceToHost));
497 }
498
499 /*************************/
500
501 if (verbose)
502 {
503 printf("Tensor network contraction and back-propagation time (ms): = %.3f\n", time * 1000.f);
504 }
Free resources#
After the computation, we need to free up all resources.
507 /***************
508 * Free resources
509 ****************/
510
511 // Free cuTensorNet resources
512 HANDLE_ERROR(cutensornetDestroySliceGroup(sliceGroup));
513 HANDLE_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
514 HANDLE_ERROR(cutensornetDestroyContractionOptimizerInfo(optimizerInfo));
515 HANDLE_ERROR(cutensornetDestroyNetwork(networkDesc));
516 HANDLE_ERROR(cutensornetDestroy(handle));
517
518 HANDLE_CUDA_ERROR(cudaStreamDestroy(stream));
519
520 // Free Host memory resources
521 for (int i = 0; i < numInputs; ++i)
522 {
523 if (tensorData_h[i]) free(tensorData_h[i]);
524 if (gradients_h[i]) free(gradients_h[i]);
525 }
526 if (tensorData_h[numInputs]) free(tensorData_h[numInputs]);
527 if (adjoint_h) free(adjoint_h);
528
529 // Free GPU memory resources
530 if (workScratch) cudaFree(workScratch);
531 if (workCache) cudaFree(workCache);
532 if (adjoint_d) cudaFree(adjoint_d);
533 for (int i = 0; i < numInputs; ++i)
534 {
535 if (tensorData_d[i]) cudaFree(tensorData_d[i]);
536 if (gradients_d[i]) cudaFree(gradients_d[i]);
537 }
538 if (tensorData_d[numInputs]) cudaFree(tensorData_d[numInputs]);
539 if (verbose) printf("Freed resources and exited\n");
540
541 return 0;
542}
Code example (amplitudes slice)#
Computing tensor network state amplitudes#
The following code example illustrates how to define a tensor network state and then compute a slice of amplitudes of the tensor network state. The full code can be found in the NVIDIA/cuQuantum repository (here).
Headers and error handling#
7#include <cstdlib>
8#include <cstdio>
9#include <cassert>
10#include <complex>
11#include <vector>
12#include <bitset>
13#include <iostream>
14
15#include <cuda_runtime.h>
16#include <cutensornet.h>
17
18
19#define HANDLE_CUDA_ERROR(x) \
20{ const auto err = x; \
21 if( err != cudaSuccess ) \
22 { printf("CUDA error %s in line %d\n", cudaGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
23};
24
25#define HANDLE_CUTN_ERROR(x) \
26{ const auto err = x; \
27 if( err != CUTENSORNET_STATUS_SUCCESS ) \
28 { printf("cuTensorNet error %s in line %d\n", cutensornetGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
29};
30
31
32int main()
33{
34 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
35
36 constexpr std::size_t fp64size = sizeof(double);
Define the tensor network state and the desired slice of state amplitudes#
Let’s define a tensor network state corresponding to a 6-qubit quantum circuit and request a slice of state amplitudes where qubits 0 and 1 are fixed at value 1.
40 // Quantum state configuration
41 constexpr int32_t numQubits = 6; // number of qubits
42 const std::vector<int64_t> qubitDims(numQubits,2); // qubit dimensions
43 const std::vector<int32_t> fixedModes({0,1}); // fixed modes in the output amplitude tensor (must be in acsending order)
44 const std::vector<int64_t> fixedValues({1,1}); // values of the fixed modes in the output amplitude tensor
45 const int32_t numFixedModes = fixedModes.size(); // number of fixed modes in the output amplitude tensor
46 std::cout << "Quantum circuit: " << numQubits << " qubits\n";
Initialize the cuTensorNet library handle#
50 // Initialize the cuTensorNet library
51 HANDLE_CUDA_ERROR(cudaSetDevice(0));
52 cutensornetHandle_t cutnHandle;
53 HANDLE_CUTN_ERROR(cutensornetCreate(&cutnHandle));
54 std::cout << "Initialized cuTensorNet library on GPU 0\n";
Define quantum gates on GPU#
58 // Define necessary quantum gate tensors in Host memory
59 const double invsq2 = 1.0 / std::sqrt(2.0);
60 // Hadamard gate
61 const std::vector<std::complex<double>> h_gateH {{invsq2, 0.0}, {invsq2, 0.0},
62 {invsq2, 0.0}, {-invsq2, 0.0}};
63 // CX gate
64 const std::vector<std::complex<double>> h_gateCX {{1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
65 {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
66 {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0},
67 {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}};
68
69 // Copy quantum gates to Device memory
70 void *d_gateH{nullptr}, *d_gateCX{nullptr};
71 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateH, 4 * (2 * fp64size)));
72 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateCX, 16 * (2 * fp64size)));
73 std::cout << "Allocated quantum gate memory on GPU\n";
74 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateH, h_gateH.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
75 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateCX, h_gateCX.data(), 16 * (2 * fp64size), cudaMemcpyHostToDevice));
76 std::cout << "Copied quantum gates to GPU memory\n";
Allocate the amplitudes slice tensor on GPU#
Here we allocate GPU memory for the requested amplitudes slice tensor.
80 // Allocate Device memory for the specified slice of the quantum circuit amplitudes tensor
81 void *d_amp{nullptr};
82 std::size_t ampSize = 1;
83 for(const auto & qubitDim: qubitDims) ampSize *= qubitDim; // all state modes (full size)
84 for(const auto & fixedMode: fixedModes) ampSize /= qubitDims[fixedMode]; // fixed state modes reduce the slice size
85 HANDLE_CUDA_ERROR(cudaMalloc(&d_amp, ampSize * (2 * fp64size)));
86 std::cout << "Allocated memory for the specified slice of the quantum circuit amplitude tensor of size "
87 << ampSize << " elements\n";
Allocate the scratch buffer on GPU#
91 // Query the free memory on Device
92 std::size_t freeSize{0}, totalSize{0};
93 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeSize, &totalSize));
94 const std::size_t scratchSize = (freeSize - (freeSize % 4096)) / 2; // use half of available memory with alignment
95 void *d_scratch{nullptr};
96 HANDLE_CUDA_ERROR(cudaMalloc(&d_scratch, scratchSize));
97 std::cout << "Allocated " << scratchSize << " bytes of scratch memory on GPU\n";
Create a pure tensor network state#
Now let’s create a pure tensor network state for a 6-qubit quantum circuit.
101 // Create the initial quantum state
102 cutensornetState_t quantumState;
103 HANDLE_CUTN_ERROR(cutensornetCreateState(cutnHandle, CUTENSORNET_STATE_PURITY_PURE, numQubits, qubitDims.data(),
104 CUDA_C_64F, &quantumState));
105 std::cout << "Created the initial quantum state\n";
Apply quantum gates#
Let’s construct the GHZ quantum circuit by applying the corresponding quantum gates.
109 // Construct the final quantum circuit state (apply quantum gates) for the GHZ circuit
110 int64_t id;
111 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 1, std::vector<int32_t>{{0}}.data(),
112 d_gateH, nullptr, 1, 0, 1, &id));
113 for(int32_t i = 1; i < numQubits; ++i) {
114 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 2, std::vector<int32_t>{{i-1,i}}.data(),
115 d_gateCX, nullptr, 1, 0, 1, &id));
116 }
117 std::cout << "Applied quantum gates\n";
Create the state amplitudes accessor#
Once the quantum circuit has been constructed, let’s create the amplitudes accessor object that will compute the requested slice of state amplitudes.
121 // Specify the quantum circuit amplitudes accessor
122 cutensornetStateAccessor_t accessor;
123 HANDLE_CUTN_ERROR(cutensornetCreateAccessor(cutnHandle, quantumState, numFixedModes, fixedModes.data(),
124 nullptr, &accessor)); // using default strides
125 std::cout << "Created the specified quantum circuit amplitudes accessor\n";
Configure the state amplitudes accessor#
Now we can configure the state amplitudes accessor object by setting the number of hyper-samples to be used by the tensor network contraction path finder.
129 // Configure the computation of the slice of the specified quantum circuit amplitudes tensor
130 const int32_t numHyperSamples = 8; // desired number of hyper samples used in the tensor network contraction path finder
131 HANDLE_CUTN_ERROR(cutensornetAccessorConfigure(cutnHandle, accessor,
132 CUTENSORNET_ACCESSOR_CONFIG_NUM_HYPER_SAMPLES, &numHyperSamples, sizeof(numHyperSamples)));
Prepare the computation of the amplitudes slice tensor#
Let’s create a workspace descriptor and prepare the computation of the amplitudes slice tensor.
136 // Prepare the computation of the specified slice of the quantum circuit amplitudes tensor
137 cutensornetWorkspaceDescriptor_t workDesc;
138 HANDLE_CUTN_ERROR(cutensornetCreateWorkspaceDescriptor(cutnHandle, &workDesc));
139 std::cout << "Created the workspace descriptor\n";
140 HANDLE_CUTN_ERROR(cutensornetAccessorPrepare(cutnHandle, accessor, scratchSize, workDesc, 0x0));
141 std::cout << "Prepared the computation of the specified slice of the quantum circuit amplitudes tensor\n";
142 double flops {0.0};
143 HANDLE_CUTN_ERROR(cutensornetAccessorGetInfo(cutnHandle, accessor,
144 CUTENSORNET_ACCESSOR_INFO_FLOPS, &flops, sizeof(flops)));
145 std::cout << "Total flop count = " << (flops/1e9) << " GFlop\n";
Set up the workspace#
Now we can set up the required workspace buffer.
149 // Attach the workspace buffer
150 int64_t worksize {0};
151 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
152 workDesc,
153 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
154 CUTENSORNET_MEMSPACE_DEVICE,
155 CUTENSORNET_WORKSPACE_SCRATCH,
156 &worksize));
157 std::cout << "Required scratch GPU workspace size (bytes) = " << worksize << std::endl;
158 if(worksize <= scratchSize) {
159 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
160 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
161 }else{
162 std::cout << "ERROR: Insufficient workspace size on Device!\n";
163 std::abort();
164 }
165 std::cout << "Set the workspace buffer\n";
Compute the specified slice of state amplitudes#
Once everything has been set up, we compute the requested slice of state amplitudes, copy it back to Host memory, and print it.
169 // Compute the specified slice of the quantum circuit amplitudes tensor
170 std::complex<double> stateNorm2{0.0,0.0};
171 HANDLE_CUTN_ERROR(cutensornetAccessorCompute(cutnHandle, accessor, fixedValues.data(),
172 workDesc, d_amp, static_cast<void*>(&stateNorm2), 0x0));
173 std::cout << "Computed the specified slice of the quantum circuit amplitudes tensor\n";
174 std::vector<std::complex<double>> h_amp(ampSize);
175 HANDLE_CUDA_ERROR(cudaMemcpy(h_amp.data(), d_amp, ampSize * (2 * fp64size), cudaMemcpyDeviceToHost));
176 std::cout << "Amplitudes slice for " << (numQubits - numFixedModes) << " qubits:\n";
177 for(std::size_t i = 0; i < ampSize; ++i) {
178 std::cout << " " << h_amp[i] << std::endl;
179 }
180 std::cout << "Squared 2-norm of the state = (" << stateNorm2.real() << ", " << stateNorm2.imag() << ")\n";
Free resources#
184 // Destroy the workspace descriptor
185 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
186 std::cout << "Destroyed the workspace descriptor\n";
187
188 // Destroy the quantum circuit amplitudes accessor
189 HANDLE_CUTN_ERROR(cutensornetDestroyAccessor(accessor));
190 std::cout << "Destroyed the quantum circuit amplitudes accessor\n";
191
192 // Destroy the quantum circuit state
193 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
194 std::cout << "Destroyed the quantum circuit state\n";
195
196 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
197 HANDLE_CUDA_ERROR(cudaFree(d_amp));
198 HANDLE_CUDA_ERROR(cudaFree(d_gateCX));
199 HANDLE_CUDA_ERROR(cudaFree(d_gateH));
200 std::cout << "Freed memory on GPU\n";
201
202 // Finalize the cuTensorNet library
203 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
204 std::cout << "Finalized the cuTensorNet library\n";
205
206 return 0;
207}
Code example (expectation value)#
Computing tensor network state expectation value#
The following code example illustrates how to define a tensor network state, a tensor network operator, and then compute the expectation value of the tensor network operator over the tensor network state. The full code can be found in the NVIDIA/cuQuantum repository (here).
Headers and error handling#
7#include <cstdlib>
8#include <cstdio>
9#include <cassert>
10#include <complex>
11#include <vector>
12#include <bitset>
13#include <iostream>
14
15#include <cuda_runtime.h>
16#include <cutensornet.h>
17
18
19#define HANDLE_CUDA_ERROR(x) \
20{ const auto err = x; \
21 if( err != cudaSuccess ) \
22 { printf("CUDA error %s in line %d\n", cudaGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
23};
24
25#define HANDLE_CUTN_ERROR(x) \
26{ const auto err = x; \
27 if( err != CUTENSORNET_STATUS_SUCCESS ) \
28 { printf("cuTensorNet error %s in line %d\n", cutensornetGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
29};
30
31
32int main()
33{
34 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
35
36 constexpr std::size_t fp64size = sizeof(double);
Define the tensor network state#
Let’s define a tensor network state corresponding to a 16-qubit quantum circuit.
40 // Quantum state configuration
41 constexpr int32_t numQubits = 16; // number of qubits
42 const std::vector<int64_t> qubitDims(numQubits,2); // qubit dimensions
43 std::cout << "Quantum circuit: " << numQubits << " qubits\n";
Initialize the cuTensorNet library handle#
47 // Initialize the cuTensorNet library
48 HANDLE_CUDA_ERROR(cudaSetDevice(0));
49 cutensornetHandle_t cutnHandle;
50 HANDLE_CUTN_ERROR(cutensornetCreate(&cutnHandle));
51 std::cout << "Initialized cuTensorNet library on GPU 0\n";
Define quantum gates on GPU#
55 // Define necessary quantum gate tensors in Host memory
56 const double invsq2 = 1.0 / std::sqrt(2.0);
57 // Hadamard gate
58 const std::vector<std::complex<double>> h_gateH {{invsq2, 0.0}, {invsq2, 0.0},
59 {invsq2, 0.0}, {-invsq2, 0.0}};
60 // Pauli X gate
61 const std::vector<std::complex<double>> h_gateX {{0.0, 0.0}, {1.0, 0.0},
62 {1.0, 0.0}, {0.0, 0.0}};
63 // Pauli Y gate
64 const std::vector<std::complex<double>> h_gateY {{0.0, 0.0}, {0.0, -1.0},
65 {0.0, 1.0}, {0.0, 0.0}};
66 // Pauli Z gate
67 const std::vector<std::complex<double>> h_gateZ {{1.0, 0.0}, {0.0, 0.0},
68 {0.0, 0.0}, {-1.0, 0.0}};
69 // CX gate
70 const std::vector<std::complex<double>> h_gateCX {{1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
71 {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
72 {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0},
73 {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}};
74
75 // Copy quantum gates to Device memory
76 void *d_gateH{nullptr}, *d_gateX{nullptr}, *d_gateY{nullptr}, *d_gateZ{nullptr}, *d_gateCX{nullptr};
77 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateH, 4 * (2 * fp64size)));
78 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateX, 4 * (2 * fp64size)));
79 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateY, 4 * (2 * fp64size)));
80 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateZ, 4 * (2 * fp64size)));
81 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateCX, 16 * (2 * fp64size)));
82 std::cout << "Allocated quantum gate memory on GPU\n";
83 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateH, h_gateH.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
84 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateX, h_gateX.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
85 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateY, h_gateY.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
86 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateZ, h_gateZ.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
87 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateCX, h_gateCX.data(), 16 * (2 * fp64size), cudaMemcpyHostToDevice));
88 std::cout << "Copied quantum gates to GPU memory\n";
Allocate the scratch buffer on GPU#
92 // Query the free memory on Device
93 std::size_t freeSize{0}, totalSize{0};
94 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeSize, &totalSize));
95 const std::size_t scratchSize = (freeSize - (freeSize % 4096)) / 2; // use half of available memory with alignment
96 void *d_scratch{nullptr};
97 HANDLE_CUDA_ERROR(cudaMalloc(&d_scratch, scratchSize));
98 std::cout << "Allocated " << scratchSize << " bytes of scratch memory on GPU\n";
Create a pure tensor network state#
Now let’s create a pure tensor network state for a 16-qubit quantum circuit.
102 // Create the initial quantum state
103 cutensornetState_t quantumState;
104 HANDLE_CUTN_ERROR(cutensornetCreateState(cutnHandle, CUTENSORNET_STATE_PURITY_PURE, numQubits, qubitDims.data(),
105 CUDA_C_64F, &quantumState));
106 std::cout << "Created the initial quantum state\n";
Apply quantum gates#
Let’s construct the GHZ quantum circuit by applying the corresponding quantum gates.
110 // Construct the final quantum circuit state (apply quantum gates) for the GHZ circuit
111 int64_t id;
112 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 1, std::vector<int32_t>{{0}}.data(),
113 d_gateH, nullptr, 1, 0, 1, &id));
114 for(int32_t i = 1; i < numQubits; ++i) {
115 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 2, std::vector<int32_t>{{i-1,i}}.data(),
116 d_gateCX, nullptr, 1, 0, 1, &id));
117 }
118 std::cout << "Applied quantum gates\n";
Construct a tensor network operator#
Now let’s create an empty tensor network operator for 16-qubit states and then append three components to it, where each component is a direct product of Pauli matrices scaled by some complex coefficient (like in the Jordan-Wigner representation).
122 // Create an empty tensor network operator
123 cutensornetNetworkOperator_t hamiltonian;
124 HANDLE_CUTN_ERROR(cutensornetCreateNetworkOperator(cutnHandle, numQubits, qubitDims.data(), CUDA_C_64F, &hamiltonian));
125 // Append component (0.5 * Z1 * Z2) to the tensor network operator
126 {
127 const int32_t numModes[] = {1, 1}; // Z1 acts on 1 mode, Z2 acts on 1 mode
128 const int32_t modesZ1[] = {1}; // state modes Z1 acts on
129 const int32_t modesZ2[] = {2}; // state modes Z2 acts on
130 const int32_t * stateModes[] = {modesZ1, modesZ2}; // state modes (Z1 * Z2) acts on
131 const void * gateData[] = {d_gateZ, d_gateZ}; // GPU pointers to gate data
132 HANDLE_CUTN_ERROR(cutensornetNetworkOperatorAppendProduct(cutnHandle, hamiltonian, cuDoubleComplex{0.5,0.0},
133 2, numModes, stateModes, NULL, gateData, &id));
134 }
135 // Append component (0.25 * Y3) to the tensor network operator
136 {
137 const int32_t numModes[] = {1}; // Y3 acts on 1 mode
138 const int32_t modesY3[] = {3}; // state modes Y3 acts on
139 const int32_t * stateModes[] = {modesY3}; // state modes (Y3) acts on
140 const void * gateData[] = {d_gateY}; // GPU pointers to gate data
141 HANDLE_CUTN_ERROR(cutensornetNetworkOperatorAppendProduct(cutnHandle, hamiltonian, cuDoubleComplex{0.25,0.0},
142 1, numModes, stateModes, NULL, gateData, &id));
143 }
144 // Append component (0.13 * Y0 X2 Z3) to the tensor network operator
145 {
146 const int32_t numModes[] = {1, 1, 1}; // Y0 acts on 1 mode, X2 acts on 1 mode, Z3 acts on 1 mode
147 const int32_t modesY0[] = {0}; // state modes Y0 acts on
148 const int32_t modesX2[] = {2}; // state modes X2 acts on
149 const int32_t modesZ3[] = {3}; // state modes Z3 acts on
150 const int32_t * stateModes[] = {modesY0, modesX2, modesZ3}; // state modes (Y0 * X2 * Z3) acts on
151 const void * gateData[] = {d_gateY, d_gateX, d_gateZ}; // GPU pointers to gate data
152 HANDLE_CUTN_ERROR(cutensornetNetworkOperatorAppendProduct(cutnHandle, hamiltonian, cuDoubleComplex{0.13,0.0},
153 3, numModes, stateModes, NULL, gateData, &id));
154 }
155 std::cout << "Constructed a tensor network operator: (0.5 * Z1 * Z2) + (0.25 * Y3) + (0.13 * Y0 * X2 * Z3)" << std::endl;
Create the expectation value object#
Once the quantum circuit and the tensor network operator have been constructed, let’s create the expectation value object that will compute the expectation value of the specified tensor network operator over the final state of the specified quantum circuit.
159 // Specify the quantum circuit expectation value
160 cutensornetStateExpectation_t expectation;
161 HANDLE_CUTN_ERROR(cutensornetCreateExpectation(cutnHandle, quantumState, hamiltonian, &expectation));
162 std::cout << "Created the specified quantum circuit expectation value\n";
Configure the expectation value calculation#
Now we can configure the expectation value object by setting the number of hyper-samples to be used by the tensor network contraction path finder.
166 // Configure the computation of the specified quantum circuit expectation value
167 const int32_t numHyperSamples = 8; // desired number of hyper samples used in the tensor network contraction path finder
168 HANDLE_CUTN_ERROR(cutensornetExpectationConfigure(cutnHandle, expectation,
169 CUTENSORNET_EXPECTATION_CONFIG_NUM_HYPER_SAMPLES, &numHyperSamples, sizeof(numHyperSamples)));
Prepare the expectation value calculation#
Let’s create a workspace descriptor and prepare the computation of the desired expectation value.
173 // Prepare the specified quantum circuit expectation value for computation
174 cutensornetWorkspaceDescriptor_t workDesc;
175 HANDLE_CUTN_ERROR(cutensornetCreateWorkspaceDescriptor(cutnHandle, &workDesc));
176 std::cout << "Created the workspace descriptor\n";
177 HANDLE_CUTN_ERROR(cutensornetExpectationPrepare(cutnHandle, expectation, scratchSize, workDesc, 0x0));
178 std::cout << "Prepared the specified quantum circuit expectation value\n";
179 double flops {0.0};
180 HANDLE_CUTN_ERROR(cutensornetExpectationGetInfo(cutnHandle, expectation,
181 CUTENSORNET_EXPECTATION_INFO_FLOPS, &flops, sizeof(flops)));
182 std::cout << "Total flop count = " << (flops/1e9) << " GFlop\n";
Set up the workspace#
Now we can set up the required workspace buffer.
186 // Attach the workspace buffer
187 int64_t worksize {0};
188 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
189 workDesc,
190 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
191 CUTENSORNET_MEMSPACE_DEVICE,
192 CUTENSORNET_WORKSPACE_SCRATCH,
193 &worksize));
194 std::cout << "Required scratch GPU workspace size (bytes) = " << worksize << std::endl;
195 if(worksize <= scratchSize) {
196 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
197 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
198 }else{
199 std::cout << "ERROR: Insufficient workspace size on Device!\n";
200 std::abort();
201 }
202 std::cout << "Set the workspace buffer\n";
Compute the requested expectation value#
Once everything has been set up, we compute the requested expectation value and print it. Note that the returned expectation value is not normalized. The 2-norm of the tensor network state is returned as a separate argument.
206 // Compute the specified quantum circuit expectation value
207 std::complex<double> expectVal{0.0,0.0}, stateNorm2{0.0,0.0};
208 HANDLE_CUTN_ERROR(cutensornetExpectationCompute(cutnHandle, expectation, workDesc,
209 static_cast<void*>(&expectVal), static_cast<void*>(&stateNorm2), 0x0));
210 std::cout << "Computed the specified quantum circuit expectation value\n";
211 expectVal /= stateNorm2;
212 std::cout << "Expectation value = (" << expectVal.real() << ", " << expectVal.imag() << ")\n";
213 std::cout << "Squared 2-norm of the state = (" << stateNorm2.real() << ", " << stateNorm2.imag() << ")\n";
Free resources#
217 // Destroy the workspace descriptor
218 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
219 std::cout << "Destroyed the workspace descriptor\n";
220
221 // Destroy the quantum circuit expectation value
222 HANDLE_CUTN_ERROR(cutensornetDestroyExpectation(expectation));
223 std::cout << "Destroyed the quantum circuit state expectation value\n";
224
225 // Destroy the tensor network operator
226 HANDLE_CUTN_ERROR(cutensornetDestroyNetworkOperator(hamiltonian));
227 std::cout << "Destroyed the tensor network operator\n";
228
229 // Destroy the quantum circuit state
230 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
231 std::cout << "Destroyed the quantum circuit state\n";
232
233 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
234 HANDLE_CUDA_ERROR(cudaFree(d_gateCX));
235 HANDLE_CUDA_ERROR(cudaFree(d_gateZ));
236 HANDLE_CUDA_ERROR(cudaFree(d_gateY));
237 HANDLE_CUDA_ERROR(cudaFree(d_gateX));
238 HANDLE_CUDA_ERROR(cudaFree(d_gateH));
239 std::cout << "Freed memory on GPU\n";
240
241 // Finalize the cuTensorNet library
242 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
243 std::cout << "Finalized the cuTensorNet library\n";
244
245 return 0;
246}
Code example (marginal distribution)#
Computing tensor network state marginal distribution tensor#
The following code example illustrates how to define a tensor network state and then compute the tensor network state marginal distribution tensor. The full code can be found in the NVIDIA/cuQuantum repository (here).
Headers and error handling#
7#include <cstdlib>
8#include <cstdio>
9#include <cassert>
10#include <complex>
11#include <vector>
12#include <bitset>
13#include <iostream>
14
15#include <cuda_runtime.h>
16#include <cutensornet.h>
17
18
19#define HANDLE_CUDA_ERROR(x) \
20{ const auto err = x; \
21 if( err != cudaSuccess ) \
22 { printf("CUDA error %s in line %d\n", cudaGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
23};
24
25#define HANDLE_CUTN_ERROR(x) \
26{ const auto err = x; \
27 if( err != CUTENSORNET_STATUS_SUCCESS ) \
28 { printf("cuTensorNet error %s in line %d\n", cutensornetGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
29};
30
31
32int main()
33{
34 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
35
36 constexpr std::size_t fp64size = sizeof(double);
Define the tensor network state and the desired marginal distribution tensor#
Let’s define a tensor network state corresponding to a 16-qubit quantum circuit and request the marginal distribution tensor for qubits 0 and 1.
40 // Quantum state configuration
41 constexpr int32_t numQubits = 16; // number of qubits
42 const std::vector<int64_t> qubitDims(numQubits,2); // qubit dimensions
43 const std::vector<int32_t> marginalModes({0,1}); // open qubits defining the marginal (must be in acsending order)
44 const int32_t numMarginalModes = marginalModes.size(); // rank of the marginal (reduced density matrix)
45 std::cout << "Quantum circuit: " << numQubits << " qubits\n";
Initialize the cuTensorNet library handle#
49 // Initialize the cuTensorNet library
50 HANDLE_CUDA_ERROR(cudaSetDevice(0));
51 cutensornetHandle_t cutnHandle;
52 HANDLE_CUTN_ERROR(cutensornetCreate(&cutnHandle));
53 std::cout << "Initialized cuTensorNet library on GPU 0\n";
Define quantum gates on GPU#
57 // Define necessary quantum gate tensors in Host memory
58 const double invsq2 = 1.0 / std::sqrt(2.0);
59 // Hadamard gate
60 const std::vector<std::complex<double>> h_gateH {{invsq2, 0.0}, {invsq2, 0.0},
61 {invsq2, 0.0}, {-invsq2, 0.0}};
62 // CX gate
63 const std::vector<std::complex<double>> h_gateCX {{1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
64 {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
65 {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0},
66 {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}};
67
68 // Copy quantum gates to Device memory
69 void *d_gateH{nullptr}, *d_gateCX{nullptr};
70 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateH, 4 * (2 * fp64size)));
71 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateCX, 16 * (2 * fp64size)));
72 std::cout << "Allocated quantum gate memory on GPU\n";
73 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateH, h_gateH.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
74 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateCX, h_gateCX.data(), 16 * (2 * fp64size), cudaMemcpyHostToDevice));
75 std::cout << "Copied quantum gates to GPU memory\n";
Allocate the marginal distribution tensor on GPU#
Here we allocate the marginal distribution tensor, that is, the reduced density matrix for qubits 0 and 1 on GPU.
79 // Allocate Device memory for the specified quantum circuit reduced density matrix (marginal)
80 void *d_rdm{nullptr};
81 std::size_t rdmDim = 1;
82 for(const auto & mode: marginalModes) rdmDim *= qubitDims[mode];
83 const std::size_t rdmSize = rdmDim * rdmDim;
84 HANDLE_CUDA_ERROR(cudaMalloc(&d_rdm, rdmSize * (2 * fp64size)));
85 std::cout << "Allocated memory for the specified quantum circuit reduced density matrix (marginal) of size "
86 << rdmSize << " elements\n";
Allocate the scratch buffer on GPU#
90 // Query the free memory on Device
91 std::size_t freeSize{0}, totalSize{0};
92 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeSize, &totalSize));
93 const std::size_t scratchSize = (freeSize - (freeSize % 4096)) / 2; // use half of available memory with alignment
94 void *d_scratch{nullptr};
95 HANDLE_CUDA_ERROR(cudaMalloc(&d_scratch, scratchSize));
96 std::cout << "Allocated " << scratchSize << " bytes of scratch memory on GPU\n";
Create a pure tensor network state#
Now let’s create a pure tensor network state for a 16-qubit quantum circuit.
100 // Create the initial quantum state
101 cutensornetState_t quantumState;
102 HANDLE_CUTN_ERROR(cutensornetCreateState(cutnHandle, CUTENSORNET_STATE_PURITY_PURE, numQubits, qubitDims.data(),
103 CUDA_C_64F, &quantumState));
104 std::cout << "Created the initial quantum state\n";
Apply quantum gates#
Let’s construct the GHZ quantum circuit by applying the corresponding quantum gates.
108 // Construct the final quantum circuit state (apply quantum gates) for the GHZ circuit
109 int64_t id;
110 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 1, std::vector<int32_t>{{0}}.data(),
111 d_gateH, nullptr, 1, 0, 1, &id));
112 for(int32_t i = 1; i < numQubits; ++i) {
113 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 2, std::vector<int32_t>{{i-1,i}}.data(),
114 d_gateCX, nullptr, 1, 0, 1, &id));
115 }
116 std::cout << "Applied quantum gates\n";
Create the marginal distribution object#
Once the quantum circuit has been constructed, let’s create the marginal distribution object that will compute the marginal distribution tensor (reduced density matrix) for qubits 0 and 1.
120 // Specify the quantum circuit reduced density matrix (marginal)
121 cutensornetStateMarginal_t marginal;
122 HANDLE_CUTN_ERROR(cutensornetCreateMarginal(cutnHandle, quantumState, numMarginalModes, marginalModes.data(),
123 0, nullptr, std::vector<int64_t>{{1,2,4,8}}.data(), &marginal)); // using explicit strides
124 std::cout << "Created the specified quantum circuit reduced densitry matrix (marginal)\n";
Configure the marginal distribution object#
Now we can configure the marginal distribution object by setting the number of hyper-samples to be used by the tensor network contraction path finder.
128 // Configure the computation of the specified quantum circuit reduced density matrix (marginal)
129 const int32_t numHyperSamples = 8; // desired number of hyper samples used in the tensor network contraction path finder
130 HANDLE_CUTN_ERROR(cutensornetMarginalConfigure(cutnHandle, marginal,
131 CUTENSORNET_MARGINAL_CONFIG_NUM_HYPER_SAMPLES, &numHyperSamples, sizeof(numHyperSamples)));
Prepare the computation of the marginal distribution tensor#
Let’s create a workspace descriptor and prepare the computation of the marginal distribution tensor.
135 // Prepare the computation of the specified quantum circuit reduced densitry matrix (marginal)
136 cutensornetWorkspaceDescriptor_t workDesc;
137 HANDLE_CUTN_ERROR(cutensornetCreateWorkspaceDescriptor(cutnHandle, &workDesc));
138 std::cout << "Created the workspace descriptor\n";
139 HANDLE_CUTN_ERROR(cutensornetMarginalPrepare(cutnHandle, marginal, scratchSize, workDesc, 0x0));
140 std::cout << "Prepared the computation of the specified quantum circuit reduced density matrix (marginal)\n";
141 double flops {0.0};
142 HANDLE_CUTN_ERROR(cutensornetMarginalGetInfo(cutnHandle, marginal,
143 CUTENSORNET_MARGINAL_INFO_FLOPS, &flops, sizeof(flops)));
144 std::cout << "Total flop count = " << (flops/1e9) << " GFlop\n";
Set up the workspace#
Now we can set up the required workspace buffer.
148 // Attach the workspace buffer
149 int64_t worksize {0};
150 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
151 workDesc,
152 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
153 CUTENSORNET_MEMSPACE_DEVICE,
154 CUTENSORNET_WORKSPACE_SCRATCH,
155 &worksize));
156 std::cout << "Required scratch GPU workspace size (bytes) = " << worksize << std::endl;
157 if(worksize <= scratchSize) {
158 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
159 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
160 }else{
161 std::cout << "ERROR: Insufficient workspace size on Device!\n";
162 std::abort();
163 }
164 std::cout << "Set the workspace buffer\n";
Compute the marginal distribution tensor#
Once everything has been set up, we compute the requested marginal distribution tensor (reduced density matrix) for qubits 0 and 1, copy it back to Host memory, and print it.
168 // Compute the specified quantum circuit reduced densitry matrix (marginal)
169 HANDLE_CUTN_ERROR(cutensornetMarginalCompute(cutnHandle, marginal, nullptr, workDesc, d_rdm, 0x0));
170 std::cout << "Computed the specified quantum circuit reduced density matrix (marginal)\n";
171 std::vector<std::complex<double>> h_rdm(rdmSize);
172 HANDLE_CUDA_ERROR(cudaMemcpy(h_rdm.data(), d_rdm, rdmSize * (2 * fp64size), cudaMemcpyDeviceToHost));
173 std::cout << "Reduced density matrix for " << numMarginalModes << " qubits:\n";
174 for(std::size_t i = 0; i < rdmDim; ++i) {
175 for(std::size_t j = 0; j < rdmDim; ++j) {
176 std::cout << " " << h_rdm[i + j * rdmDim];
177 }
178 std::cout << std::endl;
179 }
Free resources#
183 // Destroy the workspace descriptor
184 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
185 std::cout << "Destroyed the workspace descriptor\n";
186
187 // Destroy the quantum circuit reduced density matrix
188 HANDLE_CUTN_ERROR(cutensornetDestroyMarginal(marginal));
189 std::cout << "Destroyed the quantum circuit state reduced density matrix (marginal)\n";
190
191 // Destroy the quantum circuit state
192 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
193 std::cout << "Destroyed the quantum circuit state\n";
194
195 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
196 HANDLE_CUDA_ERROR(cudaFree(d_rdm));
197 HANDLE_CUDA_ERROR(cudaFree(d_gateCX));
198 HANDLE_CUDA_ERROR(cudaFree(d_gateH));
199 std::cout << "Freed memory on GPU\n";
200
201 // Finalize the cuTensorNet library
202 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
203 std::cout << "Finalized the cuTensorNet library\n";
204
205 return 0;
206}
Code example (tensor network sampling)#
Sampling the tensor network state#
The following code example illustrates how to sample the tensor network state (e.g., sampling the final quantum circuit state). The full code can be found in the NVIDIA/cuQuantum repository (here).
Headers and error handling#
7#include <cstdlib>
8#include <cstdio>
9#include <cassert>
10#include <complex>
11#include <vector>
12#include <iostream>
13
14#include <cuda_runtime.h>
15#include <cutensornet.h>
16
17#define HANDLE_CUDA_ERROR(x) \
18{ const auto err = x; \
19 if( err != cudaSuccess ) \
20 { printf("CUDA error %s in line %d\n", cudaGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
21};
22
23#define HANDLE_CUTN_ERROR(x) \
24{ const auto err = x; \
25 if( err != CUTENSORNET_STATUS_SUCCESS ) \
26 { printf("cuTensorNet error %s in line %d\n", cutensornetGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
27};
28
29
30int main()
31{
32 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
33
34 constexpr std::size_t fp64size = sizeof(double);
Define the tensor network state and the desired number of output samples to generate#
Let’s define a tensor network state corresponding to a 16-qubit quantum circuit and request to produce 100 output samples for the full qubit register.
38 // Quantum state configuration
39 const int64_t numSamples = 100;
40 const int32_t numQubits = 16;
41 const std::vector<int64_t> qubitDims(numQubits, 2); // qubit size
42 std::cout << "Quantum circuit: " << numQubits << " qubits; " << numSamples << " samples\n";
Initialize the cuTensorNet library handle#
46 // Initialize the cuTensorNet library
47 HANDLE_CUDA_ERROR(cudaSetDevice(0));
48 cutensornetHandle_t cutnHandle;
49 HANDLE_CUTN_ERROR(cutensornetCreate(&cutnHandle));
50 std::cout << "Initialized cuTensorNet library on GPU 0\n";
Define quantum gates on GPU#
54 // Define necessary quantum gate tensors in Host memory
55 const double invsq2 = 1.0 / std::sqrt(2.0);
56 // Hadamard gate
57 const std::vector<std::complex<double>> h_gateH {{invsq2, 0.0}, {invsq2, 0.0},
58 {invsq2, 0.0}, {-invsq2, 0.0}};
59 // CX gate
60 const std::vector<std::complex<double>> h_gateCX {{1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
61 {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
62 {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0},
63 {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}};
64
65 // Copy quantum gates to Device memory
66 void *d_gateH{nullptr}, *d_gateCX{nullptr};
67 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateH, 4 * (2 * fp64size)));
68 std::cout << "H gate buffer allocated on GPU: " << d_gateH << std::endl; //debug
69 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateCX, 16 * (2 * fp64size)));
70 std::cout << "CX gate buffer allocated on GPU: " << d_gateCX << std::endl; //debug
71 std::cout << "Allocated quantum gate memory on GPU\n";
72 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateH, h_gateH.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
73 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateCX, h_gateCX.data(), 16 * (2 * fp64size), cudaMemcpyHostToDevice));
74 std::cout << "Copied quantum gates to GPU memory\n";
Create a pure tensor network state#
Now let’s create a pure tensor network state for a 16-qubit quantum circuit.
78 // Create the initial quantum state
79 cutensornetState_t quantumState;
80 HANDLE_CUTN_ERROR(cutensornetCreateState(cutnHandle, CUTENSORNET_STATE_PURITY_PURE, numQubits, qubitDims.data(),
81 CUDA_C_64F, &quantumState));
82 std::cout << "Created the initial quantum state\n";
Apply quantum gates#
Let’s construct the GHZ quantum circuit by applying the corresponding quantum gates.
86 // Construct the quantum circuit state (apply quantum gates)
87 int64_t id;
88 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 1, std::vector<int32_t>{{0}}.data(),
89 d_gateH, nullptr, 1, 0, 1, &id));
90 for(int32_t i = 1; i < numQubits; ++i) {
91 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 2, std::vector<int32_t>{{i-1,i}}.data(),
92 d_gateCX, nullptr, 1, 0, 1, &id));
93 }
94 std::cout << "Applied quantum gates\n";
Create the tensor network state sampler#
Once the quantum circuit has been constructed, let’s create the tensor network state sampler for the full qubit register (all qubits).
98 // Create the quantum circuit sampler
99 cutensornetStateSampler_t sampler;
100 HANDLE_CUTN_ERROR(cutensornetCreateSampler(cutnHandle, quantumState, numQubits, nullptr, &sampler));
101 std::cout << "Created the quantum circuit sampler\n";
Configure the tensor network state sampler#
Now we can configure the tensor network state sampler by setting the number of hyper-samples to be used by the tensor network contraction path finder.
105 // Configure the quantum circuit sampler
106 const int32_t numHyperSamples = 8; // desired number of hyper samples used in the tensor network contraction path finder
107 HANDLE_CUTN_ERROR(cutensornetSamplerConfigure(cutnHandle, sampler,
108 CUTENSORNET_SAMPLER_CONFIG_NUM_HYPER_SAMPLES, &numHyperSamples, sizeof(numHyperSamples)));
109 const int32_t rndSeed = 13; // explicit random seed to get the same results each run
110 HANDLE_CUTN_ERROR(cutensornetSamplerConfigure(cutnHandle, sampler,
111 CUTENSORNET_SAMPLER_CONFIG_DETERMINISTIC, &rndSeed, sizeof(rndSeed)));
Prepare the tensor network state sampler#
Let’s create a workspace descriptor and prepare the tensor network state sampler.
115 // Query the free memory on Device
116 std::size_t freeSize {0}, totalSize {0};
117 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeSize, &totalSize));
118 const std::size_t workSizeAvailable = (freeSize - (freeSize % 4096)) / 2; // use half of available memory with alignment
119
120 // Prepare the quantum circuit sampler
121 cutensornetWorkspaceDescriptor_t workDesc;
122 HANDLE_CUTN_ERROR(cutensornetCreateWorkspaceDescriptor(cutnHandle, &workDesc));
123 HANDLE_CUTN_ERROR(cutensornetSamplerPrepare(cutnHandle, sampler, workSizeAvailable, workDesc, 0x0));
124 std::cout << "Prepared the quantum circuit state sampler\n";
125 double flops {0.0};
126 HANDLE_CUTN_ERROR(cutensornetSamplerGetInfo(cutnHandle, sampler,
127 CUTENSORNET_SAMPLER_INFO_FLOPS, &flops, sizeof(flops)));
128 std::cout << "Total flop count per sample = " << (flops/1e9) << " GFlop\n";
Allocate the workspace buffer on GPU and setup the workspace#
Allocate the required scratch workspace buffer, and provide extra buffer for cache workspace.
132 // Attach the workspace buffer
133 int64_t worksize {0};
134 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
135 workDesc,
136 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
137 CUTENSORNET_MEMSPACE_DEVICE,
138 CUTENSORNET_WORKSPACE_SCRATCH,
139 &worksize));
140 assert(worksize > 0);
141
142 void *d_scratch {nullptr};
143 if(worksize <= workSizeAvailable) {
144 HANDLE_CUDA_ERROR(cudaMalloc(&d_scratch, worksize));
145 std::cout << "Allocated " << worksize << " bytes of scratch memory on GPU: "
146 << "[" << d_scratch << ":" << (void*)(((char*)(d_scratch)) + worksize) << ")\n";
147
148 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
149 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
150 }else{
151 std::cout << "ERROR: Insufficient workspace size on Device!\n";
152 std::abort();
153 }
154
155 int64_t reqCacheSize {0};
156 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
157 workDesc,
158 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
159 CUTENSORNET_MEMSPACE_DEVICE,
160 CUTENSORNET_WORKSPACE_CACHE,
161 &reqCacheSize));
162
163 //query the free size again
164 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeSize, &totalSize));
165 // grab the minimum of [required size, or 90% of the free memory (to avoid oversubscribing)]
166 const std::size_t cacheSizeAvailable = std::min(static_cast<size_t>(reqCacheSize), size_t(freeSize * 0.9) - (size_t(freeSize * 0.9) % 4096));
167 void *d_cache {nullptr};
168 HANDLE_CUDA_ERROR(cudaMalloc(&d_cache, cacheSizeAvailable));
169 std::cout << "Allocated " << cacheSizeAvailable << " bytes of cache memory on GPU: "
170 << "[" << d_cache << ":" << (void*)(((char*)(d_cache)) + cacheSizeAvailable) << ")\n";
171 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle,
172 workDesc,
173 CUTENSORNET_MEMSPACE_DEVICE,
174 CUTENSORNET_WORKSPACE_CACHE,
175 d_cache,
176 cacheSizeAvailable));
177 std::cout << "Set the workspace buffer\n";
Perform sampling of the final quantum circuit state#
Once everything had been set up, we perform sampling of the quantum circuit state and print the output samples.
181 // Sample the quantum circuit state
182 std::vector<int64_t> samples(numQubits * numSamples); // samples[SampleId][QubitId] reside in Host memory
183 HANDLE_CUTN_ERROR(cutensornetSamplerSample(cutnHandle, sampler, numSamples, workDesc, samples.data(), 0));
184 std::cout << "Performed quantum circuit state sampling\n";
185 std::cout << "Bit-string samples:\n";
186 for(int64_t i = 0; i < numSamples; ++i) {
187 for(int64_t j = 0; j < numQubits; ++j) std::cout << " " << samples[i * numQubits + j];
188 std::cout << std::endl;
189 }
Free resources#
193 // Destroy the workspace descriptor
194 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
195 std::cout << "Destroyed the workspace descriptor\n";
196
197 // Destroy the quantum circuit sampler
198 HANDLE_CUTN_ERROR(cutensornetDestroySampler(sampler));
199 std::cout << "Destroyed the quantum circuit state sampler\n";
200
201 // Destroy the quantum circuit state
202 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
203 std::cout << "Destroyed the quantum circuit state\n";
204
205 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
206 HANDLE_CUDA_ERROR(cudaFree(d_cache));
207 HANDLE_CUDA_ERROR(cudaFree(d_gateCX));
208 HANDLE_CUDA_ERROR(cudaFree(d_gateH));
209 std::cout << "Freed memory on GPU\n";
210
211 // Finalize the cuTensorNet library
212 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
213 std::cout << "Finalized the cuTensorNet library\n";
214
215 return 0;
216}
Code example (MPS amplitudes slice using simple update)#
Computing Matrix Product State (MPS) Amplitudes#
The following code example illustrates how to define a tensor network state, factorize it as a Matrix Product State (MPS), and then compute a slice of amplitudes of the factorized MPS state. The full code can be found in the NVIDIA/cuQuantum repository (here).
Headers and error handling#
7#include <cstdlib>
8#include <cstdio>
9#include <cassert>
10#include <complex>
11#include <vector>
12#include <bitset>
13#include <iostream>
14
15#include <cuda_runtime.h>
16#include <cutensornet.h>
17
18
19#define HANDLE_CUDA_ERROR(x) \
20{ const auto err = x; \
21 if( err != cudaSuccess ) \
22 { printf("CUDA error %s in line %d\n", cudaGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
23};
24
25#define HANDLE_CUTN_ERROR(x) \
26{ const auto err = x; \
27 if( err != CUTENSORNET_STATUS_SUCCESS ) \
28 { printf("cuTensorNet error %s in line %d\n", cutensornetGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
29};
30
31
32int main()
33{
34 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
35
36 constexpr std::size_t fp64size = sizeof(double);
Define the tensor network state and the desired slice of state amplitudes#
Let’s define a tensor network state corresponding to a 6-qubit quantum circuit and request a slice of state amplitudes where qubits 0 and 1 are fixed at value 1.
40 // Quantum state configuration
41 constexpr int32_t numQubits = 6; // number of qubits
42 const std::vector<int64_t> qubitDims(numQubits,2); // qubit dimensions
43 const std::vector<int32_t> fixedModes({0,1}); // fixed modes in the output amplitude tensor (must be in acsending order)
44 const std::vector<int64_t> fixedValues({1,1}); // values of the fixed modes in the output amplitude tensor
45 const int32_t numFixedModes = fixedModes.size(); // number of fixed modes in the output amplitude tensor
46 std::cout << "Quantum circuit: " << numQubits << " qubits\n";
Initialize the cuTensorNet library handle#
50 // Initialize the cuTensorNet library
51 HANDLE_CUDA_ERROR(cudaSetDevice(0));
52 cutensornetHandle_t cutnHandle;
53 HANDLE_CUTN_ERROR(cutensornetCreate(&cutnHandle));
54 std::cout << "Initialized cuTensorNet library on GPU 0\n";
Define quantum gates on GPU#
58 // Define necessary quantum gate tensors in Host memory
59 const double invsq2 = 1.0 / std::sqrt(2.0);
60 // Hadamard gate
61 const std::vector<std::complex<double>> h_gateH {{invsq2, 0.0}, {invsq2, 0.0},
62 {invsq2, 0.0}, {-invsq2, 0.0}};
63 // CX gate
64 const std::vector<std::complex<double>> h_gateCX {{1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
65 {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
66 {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0},
67 {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}};
68
69 // Copy quantum gates to Device memory
70 void *d_gateH{nullptr}, *d_gateCX{nullptr};
71 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateH, 4 * (2 * fp64size)));
72 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateCX, 16 * (2 * fp64size)));
73 std::cout << "Allocated quantum gate memory on GPU\n";
74 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateH, h_gateH.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
75 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateCX, h_gateCX.data(), 16 * (2 * fp64size), cudaMemcpyHostToDevice));
76 std::cout << "Copied quantum gates to GPU memory\n";
Allocate MPS tensors#
Here we set the shapes of MPS tensors and allocate GPU memory for their storage.
80 // Determine the MPS representation and allocate buffers for the MPS tensors
81 const int64_t maxExtent = 2; // GHZ state can be exactly represented with max bond dimension of 2
82 std::vector<std::vector<int64_t>> extents;
83 std::vector<int64_t*> extentsPtr(numQubits);
84 std::vector<void*> d_mpsTensors(numQubits, nullptr);
85 for (int32_t i = 0; i < numQubits; i++) {
86 if (i == 0) { // left boundary MPS tensor
87 extents.push_back({2, maxExtent});
88 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * 2 * fp64size));
89 }
90 else if (i == numQubits-1) { // right boundary MPS tensor
91 extents.push_back({maxExtent, 2});
92 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * 2 * fp64size));
93 }
94 else { // middle MPS tensors
95 extents.push_back({maxExtent, 2, maxExtent});
96 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * maxExtent * 2 * fp64size));
97 }
98 extentsPtr[i] = extents[i].data();
99 }
Allocate the amplitudes slice tensor on GPU#
Here we allocate GPU memory for the requested amplitudes slice tensor.
103 // Allocate Device memory for the specified slice of the quantum circuit amplitudes tensor
104 void *d_amp{nullptr};
105 std::size_t ampSize = 1;
106 for(const auto & qubitDim: qubitDims) ampSize *= qubitDim; // all state modes (full size)
107 for(const auto & fixedMode: fixedModes) ampSize /= qubitDims[fixedMode]; // fixed state modes reduce the slice size
108 HANDLE_CUDA_ERROR(cudaMalloc(&d_amp, ampSize * (2 * fp64size)));
109 std::cout << "Allocated memory for the specified slice of the quantum circuit amplitude tensor of size "
110 << ampSize << " elements\n";
Allocate the scratch buffer on GPU#
114 // Query the free memory on Device
115 std::size_t freeSize{0}, totalSize{0};
116 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeSize, &totalSize));
117 const std::size_t scratchSize = (freeSize - (freeSize % 4096)) / 2; // use half of available memory with alignment
118 void *d_scratch{nullptr};
119 HANDLE_CUDA_ERROR(cudaMalloc(&d_scratch, scratchSize));
120 std::cout << "Allocated " << scratchSize << " bytes of scratch memory on GPU\n";
Create a pure tensor network state#
Now let’s create a pure tensor network state for a 6-qubit quantum circuit.
124 // Create the initial quantum state
125 cutensornetState_t quantumState;
126 HANDLE_CUTN_ERROR(cutensornetCreateState(cutnHandle, CUTENSORNET_STATE_PURITY_PURE, numQubits, qubitDims.data(),
127 CUDA_C_64F, &quantumState));
128 std::cout << "Created the initial quantum state\n";
Apply quantum gates#
Let’s construct the GHZ quantum circuit by applying the corresponding quantum gates.
132 // Construct the final quantum circuit state (apply quantum gates) for the GHZ circuit
133 int64_t id;
134 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 1, std::vector<int32_t>{{0}}.data(),
135 d_gateH, nullptr, 1, 0, 1, &id));
136 for(int32_t i = 1; i < numQubits; ++i) {
137 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 2, std::vector<int32_t>{{i-1,i}}.data(),
138 d_gateCX, nullptr, 1, 0, 1, &id));
139 }
140 std::cout << "Applied quantum gates\n";
Request MPS factorization for the final quantum circuit state#
Here we express our intent to factorize the final quantum circuit state using MPS factorization. The provided shapes of the MPS tensors refer to their maximal size limit during the MPS renormalization procedure. The actually computed shapes of the final MPS tensors may be smaller. No computation is done here yet.
144 // Specify the final target MPS representation (use default fortran strides)
145 HANDLE_CUTN_ERROR(cutensornetStateFinalizeMPS(cutnHandle, quantumState,
146 CUTENSORNET_BOUNDARY_CONDITION_OPEN, extentsPtr.data(), /*strides=*/nullptr));
147 std::cout << "Requested the final MPS factorization of the quantum circuit state\n";
Configure MPS factorization procedure#
After expressing our intent to perform MPS factorization of the final
quantum circuit state, we can also configure the MPS factorization
procedure by resetting different options, for example, the SVD algorithm.
Starting with cuTensorNet v2.7.0, the MPS gauge option can now be enabled.
By setting it to CUTENSORNET_STATE_MPS_GAUGE_SIMPLE, the simple update algorithm
is utilized to enhance the accuracy of the MPS factorization.
151 // Optional, set up the SVD method for MPS truncation.
152 cutensornetTensorSVDAlgo_t algo = CUTENSORNET_TENSOR_SVD_ALGO_GESVDJ;
153 HANDLE_CUTN_ERROR(cutensornetStateConfigure(cutnHandle, quantumState,
154 CUTENSORNET_STATE_CONFIG_MPS_SVD_ALGO, &algo, sizeof(algo)));
155 // Set up simple update gauge option for MPS simulation, this is optional but recommended
156 cutensornetStateMPSGaugeOption_t gauge_option = CUTENSORNET_STATE_MPS_GAUGE_SIMPLE;
157 HANDLE_CUTN_ERROR(cutensornetStateConfigure(cutnHandle, quantumState,
158 CUTENSORNET_STATE_CONFIG_MPS_GAUGE_OPTION, &gauge_option, sizeof(gauge_option)));
159 std::cout << "Configured the MPS factorization computation\n";
Prepare the computation of MPS factorization#
Let’s create a workspace descriptor and prepare the computation of MPS factorization.
163 // Prepare the MPS computation and attach workspace
164 cutensornetWorkspaceDescriptor_t workDesc;
165 HANDLE_CUTN_ERROR(cutensornetCreateWorkspaceDescriptor(cutnHandle, &workDesc));
166 std::cout << "Created the workspace descriptor\n";
167 HANDLE_CUTN_ERROR(cutensornetStatePrepare(cutnHandle, quantumState, scratchSize, workDesc, 0x0));
168 std::cout << "Prepared the computation of the quantum circuit state\n";
169 double flops {0.0};
170 HANDLE_CUTN_ERROR(cutensornetStateGetInfo(cutnHandle, quantumState,
171 CUTENSORNET_STATE_INFO_FLOPS, &flops, sizeof(flops)));
172 if(flops > 0.0) {
173 std::cout << "Total flop count = " << (flops/1e9) << " GFlop\n";
174 }else if(flops < 0.0) {
175 std::cout << "ERROR: Negative Flop count!\n";
176 std::abort();
177 }
178
179 int64_t worksize {0};
180 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
181 workDesc,
182 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
183 CUTENSORNET_MEMSPACE_DEVICE,
184 CUTENSORNET_WORKSPACE_SCRATCH,
185 &worksize));
186 std::cout << "Scratch GPU workspace size (bytes) for MPS computation = " << worksize << std::endl;
187 if(worksize <= scratchSize) {
188 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
189 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
190 }else{
191 std::cout << "ERROR: Insufficient workspace size on Device!\n";
192 std::abort();
193 }
194 std::cout << "Set the workspace buffer for the MPS factorization computation\n";
Compute MPS factorization#
Once the MPS factorization procedure has been configured and prepared, let’s compute the MPS factorization of the final quantum circuit state.
198 // Execute MPS computation
199 HANDLE_CUTN_ERROR(cutensornetStateCompute(cutnHandle, quantumState,
200 workDesc, extentsPtr.data(), /*strides=*/nullptr, d_mpsTensors.data(), 0));
201 std::cout << "Computed the MPS factorization\n";
Create the state amplitudes accessor#
Once the factorized MPS representation of the final quantum circuit state has been computed, let’s create the amplitudes accessor object that will compute the requested slice of state amplitudes.
205 // Specify the quantum circuit amplitudes accessor
206 cutensornetStateAccessor_t accessor;
207 HANDLE_CUTN_ERROR(cutensornetCreateAccessor(cutnHandle, quantumState, numFixedModes, fixedModes.data(),
208 nullptr, &accessor)); // using default strides
209 std::cout << "Created the specified quantum circuit amplitudes accessor\n";
Configure the state amplitudes accessor#
Now we can configure the state amplitudes accessor object by setting the number of hyper-samples to be used by the tensor network contraction path finder.
213 // Configure the computation of the slice of the specified quantum circuit amplitudes tensor
214 const int32_t numHyperSamples = 8; // desired number of hyper samples used in the tensor network contraction path finder
215 HANDLE_CUTN_ERROR(cutensornetAccessorConfigure(cutnHandle, accessor,
216 CUTENSORNET_ACCESSOR_CONFIG_NUM_HYPER_SAMPLES, &numHyperSamples, sizeof(numHyperSamples)));
Prepare the computation of the amplitudes slice tensor#
Let’s prepare the computation of the amplitudes slice tensor.
220 // Prepare the computation of the specified slice of the quantum circuit amplitudes tensor
221 HANDLE_CUTN_ERROR(cutensornetAccessorPrepare(cutnHandle, accessor, scratchSize, workDesc, 0x0));
222 std::cout << "Prepared the computation of the specified slice of the quantum circuit amplitudes tensor\n";
223 flops = 0.0;
224 HANDLE_CUTN_ERROR(cutensornetAccessorGetInfo(cutnHandle, accessor,
225 CUTENSORNET_ACCESSOR_INFO_FLOPS, &flops, sizeof(flops)));
226 std::cout << "Total flop count = " << (flops/1e9) << " GFlop\n";
227 if(flops <= 0.0) {
228 std::cout << "ERROR: Invalid Flop count!\n";
229 std::abort();
230 }
Set up the workspace#
Now we can set up the required workspace buffer.
234 // Attach the workspace buffer
235 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
236 workDesc,
237 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
238 CUTENSORNET_MEMSPACE_DEVICE,
239 CUTENSORNET_WORKSPACE_SCRATCH,
240 &worksize));
241 std::cout << "Required scratch GPU workspace size (bytes) = " << worksize << std::endl;
242 if(worksize <= scratchSize) {
243 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
244 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
245 }else{
246 std::cout << "ERROR: Insufficient workspace size on Device!\n";
247 std::abort();
248 }
249 std::cout << "Set the workspace buffer\n";
Compute the specified slice of state amplitudes#
Once everything has been set up, we compute the requested slice of state amplitudes, copy it back to Host memory, and print it.
253 // Compute the specified slice of the quantum circuit amplitudes tensor
254 std::complex<double> stateNorm2{0.0,0.0};
255 HANDLE_CUTN_ERROR(cutensornetAccessorCompute(cutnHandle, accessor, fixedValues.data(),
256 workDesc, d_amp, static_cast<void*>(&stateNorm2), 0x0));
257 std::cout << "Computed the specified slice of the quantum circuit amplitudes tensor\n";
258 std::vector<std::complex<double>> h_amp(ampSize);
259 HANDLE_CUDA_ERROR(cudaMemcpy(h_amp.data(), d_amp, ampSize * (2 * fp64size), cudaMemcpyDeviceToHost));
260 std::cout << "Amplitudes slice for " << (numQubits - numFixedModes) << " qubits:\n";
261 for(std::size_t i = 0; i < ampSize; ++i) {
262 std::cout << " " << h_amp[i] << std::endl;
263 }
264 std::cout << "Squared 2-norm of the state = (" << stateNorm2.real() << ", " << stateNorm2.imag() << ")\n";
Free resources#
268 // Destroy the workspace descriptor
269 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
270 std::cout << "Destroyed the workspace descriptor\n";
271
272 // Destroy the quantum circuit amplitudes accessor
273 HANDLE_CUTN_ERROR(cutensornetDestroyAccessor(accessor));
274 std::cout << "Destroyed the quantum circuit amplitudes accessor\n";
275
276 // Destroy the quantum circuit state
277 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
278 std::cout << "Destroyed the quantum circuit state\n";
279
280 for (int32_t i = 0; i < numQubits; i++) {
281 HANDLE_CUDA_ERROR(cudaFree(d_mpsTensors[i]));
282 }
283 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
284 HANDLE_CUDA_ERROR(cudaFree(d_amp));
285 HANDLE_CUDA_ERROR(cudaFree(d_gateCX));
286 HANDLE_CUDA_ERROR(cudaFree(d_gateH));
287 std::cout << "Freed memory on GPU\n";
288
289 // Finalize the cuTensorNet library
290 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
291 std::cout << "Finalized the cuTensorNet library\n";
292
293 return 0;
294}
Code example (MPS expectation value)#
Computing Matrix Product State expectation value#
The following code example illustrates how to define a tensor network state and then compute its Matrix Product State (MPS) factorization, followed by computing the expectation value of a tensor network operator over the MPS-factorized state. The full code can be found in the NVIDIA/cuQuantum repository (here).
Headers and error handling#
7#include <cstdlib>
8#include <cstdio>
9#include <cassert>
10#include <complex>
11#include <vector>
12#include <bitset>
13#include <iostream>
14
15#include <cuda_runtime.h>
16#include <cutensornet.h>
17
18
19#define HANDLE_CUDA_ERROR(x) \
20{ const auto err = x; \
21 if( err != cudaSuccess ) \
22 { printf("CUDA error %s in line %d\n", cudaGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
23};
24
25#define HANDLE_CUTN_ERROR(x) \
26{ const auto err = x; \
27 if( err != CUTENSORNET_STATUS_SUCCESS ) \
28 { printf("cuTensorNet error %s in line %d\n", cutensornetGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
29};
30
31
32int main()
33{
34 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
35
36 constexpr std::size_t fp64size = sizeof(double);
Define the tensor network state#
Let’s define a tensor network state corresponding to a 16-qubit quantum circuit.
40 // Quantum state configuration
41 constexpr int32_t numQubits = 16; // number of qubits
42 const std::vector<int64_t> qubitDims(numQubits,2); // qubit dimensions
43 std::cout << "Quantum circuit: " << numQubits << " qubits\n";
Initialize the cuTensorNet library handle#
47 // Initialize the cuTensorNet library
48 HANDLE_CUDA_ERROR(cudaSetDevice(0));
49 cutensornetHandle_t cutnHandle;
50 HANDLE_CUTN_ERROR(cutensornetCreate(&cutnHandle));
51 std::cout << "Initialized cuTensorNet library on GPU 0\n";
Define quantum gates on GPU#
55 // Define necessary quantum gate tensors in Host memory
56 const double invsq2 = 1.0 / std::sqrt(2.0);
57 // Hadamard gate
58 const std::vector<std::complex<double>> h_gateH {{invsq2, 0.0}, {invsq2, 0.0},
59 {invsq2, 0.0}, {-invsq2, 0.0}};
60 // Pauli X gate
61 const std::vector<std::complex<double>> h_gateX {{0.0, 0.0}, {1.0, 0.0},
62 {1.0, 0.0}, {0.0, 0.0}};
63 // Pauli Y gate
64 const std::vector<std::complex<double>> h_gateY {{0.0, 0.0}, {0.0, -1.0},
65 {0.0, 1.0}, {0.0, 0.0}};
66 // Pauli Z gate
67 const std::vector<std::complex<double>> h_gateZ {{1.0, 0.0}, {0.0, 0.0},
68 {0.0, 0.0}, {-1.0, 0.0}};
69 // CX gate
70 const std::vector<std::complex<double>> h_gateCX {{1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
71 {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
72 {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0},
73 {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}};
74
75 // Copy quantum gates to Device memory
76 void *d_gateH{nullptr}, *d_gateX{nullptr}, *d_gateY{nullptr}, *d_gateZ{nullptr}, *d_gateCX{nullptr};
77 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateH, 4 * (2 * fp64size)));
78 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateX, 4 * (2 * fp64size)));
79 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateY, 4 * (2 * fp64size)));
80 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateZ, 4 * (2 * fp64size)));
81 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateCX, 16 * (2 * fp64size)));
82 std::cout << "Allocated quantum gate memory on GPU\n";
83 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateH, h_gateH.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
84 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateX, h_gateX.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
85 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateY, h_gateY.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
86 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateZ, h_gateZ.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
87 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateCX, h_gateCX.data(), 16 * (2 * fp64size), cudaMemcpyHostToDevice));
88 std::cout << "Copied quantum gates to GPU memory\n";
Allocate MPS tensors#
Here we set the shapes of MPS tensors and allocate GPU memory for their storage.
92 // Determine the MPS representation and allocate buffers for the MPS tensors
93 const int64_t maxExtent = 2; // GHZ state can be exactly represented with max bond dimension of 2
94 std::vector<std::vector<int64_t>> extents;
95 std::vector<int64_t*> extentsPtr(numQubits);
96 std::vector<void*> d_mpsTensors(numQubits, nullptr);
97 for (int32_t i = 0; i < numQubits; i++) {
98 if (i == 0) { // left boundary MPS tensor
99 extents.push_back({2, maxExtent});
100 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * 2 * fp64size));
101 }
102 else if (i == numQubits-1) { // right boundary MPS tensor
103 extents.push_back({maxExtent, 2});
104 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * 2 * fp64size));
105 }
106 else { // middle MPS tensors
107 extents.push_back({maxExtent, 2, maxExtent});
108 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * maxExtent * 2 * fp64size));
109 }
110 extentsPtr[i] = extents[i].data();
111 }
Allocate the scratch buffer on GPU#
115 // Query the free memory on Device
116 std::size_t freeSize{0}, totalSize{0};
117 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeSize, &totalSize));
118 const std::size_t scratchSize = (freeSize - (freeSize % 4096)) / 2; // use half of available memory with alignment
119 void *d_scratch{nullptr};
120 HANDLE_CUDA_ERROR(cudaMalloc(&d_scratch, scratchSize));
121 std::cout << "Allocated " << scratchSize << " bytes of scratch memory on GPU\n";
Create a pure tensor network state#
Now let’s create a pure tensor network state for a 16-qubit quantum circuit.
125 // Create the initial quantum state
126 cutensornetState_t quantumState;
127 HANDLE_CUTN_ERROR(cutensornetCreateState(cutnHandle, CUTENSORNET_STATE_PURITY_PURE, numQubits, qubitDims.data(),
128 CUDA_C_64F, &quantumState));
129 std::cout << "Created the initial quantum state\n";
Apply quantum gates#
Let’s construct the GHZ quantum circuit by applying the corresponding quantum gates.
133 // Construct the final quantum circuit state (apply quantum gates) for the GHZ circuit
134 int64_t id;
135 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 1, std::vector<int32_t>{{0}}.data(),
136 d_gateH, nullptr, 1, 0, 1, &id));
137 for(int32_t i = 1; i < numQubits; ++i) {
138 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 2, std::vector<int32_t>{{i-1,i}}.data(),
139 d_gateCX, nullptr, 1, 0, 1, &id));
140 }
141 std::cout << "Applied quantum gates\n";
Request MPS factorization for the final quantum circuit state#
Here we express our intent to factorize the final quantum circuit state using MPS factorization. The provided shapes of the MPS tensors refer to their maximal size limit during the MPS renormalization procedure. The actually computed shapes of the final MPS tensors may be smaller. No computation is done here yet.
145 // Specify the final target MPS representation (use default fortran strides)
146 HANDLE_CUTN_ERROR(cutensornetStateFinalizeMPS(cutnHandle, quantumState,
147 CUTENSORNET_BOUNDARY_CONDITION_OPEN, extentsPtr.data(), /*strides=*/nullptr ));
Configure MPS factorization procedure#
After expressing our intent to perform MPS factorization of the final quantum circuit state, we can also configure the MPS factorization procedure by resetting different options, for example, the SVD algorithm.
151 // Optional, set up the SVD method for truncation.
152 cutensornetTensorSVDAlgo_t algo = CUTENSORNET_TENSOR_SVD_ALGO_GESVDJ;
153 HANDLE_CUTN_ERROR(cutensornetStateConfigure(cutnHandle, quantumState,
154 CUTENSORNET_STATE_CONFIG_MPS_SVD_ALGO, &algo, sizeof(algo)));
155 std::cout << "Configured the MPS computation\n";
Prepare the computation of MPS factorization#
Let’s create a workspace descriptor and prepare the computation of MPS factorization.
159 // Prepare the MPS computation and attach workspace
160 cutensornetWorkspaceDescriptor_t workDesc;
161 HANDLE_CUTN_ERROR(cutensornetCreateWorkspaceDescriptor(cutnHandle, &workDesc));
162 std::cout << "Created the workspace descriptor\n";
163 HANDLE_CUTN_ERROR(cutensornetStatePrepare(cutnHandle, quantumState, scratchSize, workDesc, 0x0));
164 std::cout << "Prepared the computation of the quantum circuit state\n";
165 double flops {0.0};
166 HANDLE_CUTN_ERROR(cutensornetStateGetInfo(cutnHandle, quantumState,
167 CUTENSORNET_STATE_INFO_FLOPS, &flops, sizeof(flops)));
168 if(flops > 0.0) {
169 std::cout << "Total flop count = " << (flops/1e9) << " GFlop\n";
170 }else if(flops < 0.0) {
171 std::cout << "ERROR: Negative Flop count!\n";
172 std::abort();
173 }
174
175 int64_t worksize {0};
176 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
177 workDesc,
178 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
179 CUTENSORNET_MEMSPACE_DEVICE,
180 CUTENSORNET_WORKSPACE_SCRATCH,
181 &worksize));
182 std::cout << "Scratch GPU workspace size (bytes) for MPS computation = " << worksize << std::endl;
183 if(worksize <= scratchSize) {
184 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
185 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
186 }else{
187 std::cout << "ERROR: Insufficient workspace size on Device!\n";
188 std::abort();
189 }
190 std::cout << "Set the workspace buffer for MPS computation\n";
Compute MPS factorization#
Once the MPS factorization procedure has been configured and prepared, let’s compute the MPS factorization of the final quantum circuit state.
194 // Execute MPS computation
195 HANDLE_CUTN_ERROR(cutensornetStateCompute(cutnHandle, quantumState,
196 workDesc, extentsPtr.data(), /*strides=*/nullptr, d_mpsTensors.data(), 0));
Construct a tensor network operator#
Now let’s create an empty tensor network operator for 16-qubit states and then append three components to it, where each component is a direct product of Pauli matrices scaled by some complex coefficient (like in the Jordan-Wigner representation).
200 // Create an empty tensor network operator
201 cutensornetNetworkOperator_t hamiltonian;
202 HANDLE_CUTN_ERROR(cutensornetCreateNetworkOperator(cutnHandle, numQubits, qubitDims.data(), CUDA_C_64F, &hamiltonian));
203 // Append component (0.5 * Z1 * Z2) to the tensor network operator
204 {
205 const int32_t numModes[] = {1, 1}; // Z1 acts on 1 mode, Z2 acts on 1 mode
206 const int32_t modesZ1[] = {1}; // state modes Z1 acts on
207 const int32_t modesZ2[] = {2}; // state modes Z2 acts on
208 const int32_t * stateModes[] = {modesZ1, modesZ2}; // state modes (Z1 * Z2) acts on
209 const void * gateData[] = {d_gateZ, d_gateZ}; // GPU pointers to gate data
210 HANDLE_CUTN_ERROR(cutensornetNetworkOperatorAppendProduct(cutnHandle, hamiltonian, cuDoubleComplex{0.5,0.0},
211 2, numModes, stateModes, NULL, gateData, &id));
212 }
213 // Append component (0.25 * Y3) to the tensor network operator
214 {
215 const int32_t numModes[] = {1}; // Y3 acts on 1 mode
216 const int32_t modesY3[] = {3}; // state modes Y3 acts on
217 const int32_t * stateModes[] = {modesY3}; // state modes (Y3) acts on
218 const void * gateData[] = {d_gateY}; // GPU pointers to gate data
219 HANDLE_CUTN_ERROR(cutensornetNetworkOperatorAppendProduct(cutnHandle, hamiltonian, cuDoubleComplex{0.25,0.0},
220 1, numModes, stateModes, NULL, gateData, &id));
221 }
222 // Append component (0.13 * Y0 X2 Z3) to the tensor network operator
223 {
224 const int32_t numModes[] = {1, 1, 1}; // Y0 acts on 1 mode, X2 acts on 1 mode, Z3 acts on 1 mode
225 const int32_t modesY0[] = {0}; // state modes Y0 acts on
226 const int32_t modesX2[] = {2}; // state modes X2 acts on
227 const int32_t modesZ3[] = {3}; // state modes Z3 acts on
228 const int32_t * stateModes[] = {modesY0, modesX2, modesZ3}; // state modes (Y0 * X2 * Z3) acts on
229 const void * gateData[] = {d_gateY, d_gateX, d_gateZ}; // GPU pointers to gate data
230 HANDLE_CUTN_ERROR(cutensornetNetworkOperatorAppendProduct(cutnHandle, hamiltonian, cuDoubleComplex{0.13,0.0},
231 3, numModes, stateModes, NULL, gateData, &id));
232 }
233 std::cout << "Constructed a tensor network operator: (0.5 * Z1 * Z2) + (0.25 * Y3) + (0.13 * Y0 * X2 * Z3)" << std::endl;
Create the expectation value object#
Once the quantum circuit and the tensor network operator have been constructed, and the final quantum circuit state has been factorized using the MPS representation, let’s create the expectation value object that will compute the expectation value of the specified tensor network operator over the final MPS-factorized state of the specified quantum circuit.
237 // Specify the quantum circuit expectation value
238 cutensornetStateExpectation_t expectation;
239 HANDLE_CUTN_ERROR(cutensornetCreateExpectation(cutnHandle, quantumState, hamiltonian, &expectation));
240 std::cout << "Created the specified quantum circuit expectation value\n";
Configure the expectation value calculation#
Now we can configure the expectation value object by setting the number of hyper-samples to be used by the tensor network contraction path finder.
244 // Configure the computation of the specified quantum circuit expectation value
245 const int32_t numHyperSamples = 8; // desired number of hyper samples used in the tensor network contraction path finder
246 HANDLE_CUTN_ERROR(cutensornetExpectationConfigure(cutnHandle, expectation,
247 CUTENSORNET_EXPECTATION_CONFIG_NUM_HYPER_SAMPLES, &numHyperSamples, sizeof(numHyperSamples)));
Prepare the expectation value calculation#
Let’s prepare the computation of the desired expectation value.
251 // Prepare the specified quantum circuit expectation value for computation
252 HANDLE_CUTN_ERROR(cutensornetExpectationPrepare(cutnHandle, expectation, scratchSize, workDesc, 0x0));
253 std::cout << "Prepared the specified quantum circuit expectation value\n";
254 flops = 0.0;
255 HANDLE_CUTN_ERROR(cutensornetExpectationGetInfo(cutnHandle, expectation,
256 CUTENSORNET_EXPECTATION_INFO_FLOPS, &flops, sizeof(flops)));
257 std::cout << "Total flop count = " << (flops/1e9) << " GFlop\n";
258 if(flops <= 0.0) {
259 std::cout << "ERROR: Invalid Flop count!\n";
260 std::abort();
261 }
Set up the workspace#
Now we can set up the required workspace buffer.
265 // Attach the workspace buffer
266 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
267 workDesc,
268 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
269 CUTENSORNET_MEMSPACE_DEVICE,
270 CUTENSORNET_WORKSPACE_SCRATCH,
271 &worksize));
272 std::cout << "Required scratch GPU workspace size (bytes) = " << worksize << std::endl;
273 if(worksize <= scratchSize) {
274 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
275 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
276 }else{
277 std::cout << "ERROR: Insufficient workspace size on Device!\n";
278 std::abort();
279 }
280 std::cout << "Set the workspace buffer\n";
Compute the requested expectation value#
Once everything has been set up, we compute the requested expectation value and print it. Note that the returned expectation value is not normalized. The 2-norm of the tensor network state is returned as a separate argument.
284 // Compute the specified quantum circuit expectation value
285 std::complex<double> expectVal{0.0,0.0}, stateNorm2{0.0,0.0};
286 HANDLE_CUTN_ERROR(cutensornetExpectationCompute(cutnHandle, expectation, workDesc,
287 static_cast<void*>(&expectVal), static_cast<void*>(&stateNorm2), 0x0));
288 std::cout << "Computed the specified quantum circuit expectation value\n";
289 expectVal /= stateNorm2;
290 std::cout << "Expectation value = (" << expectVal.real() << ", " << expectVal.imag() << ")\n";
291 std::cout << "Squared 2-norm of the state = (" << stateNorm2.real() << ", " << stateNorm2.imag() << ")\n";
Free resources#
295 // Destroy the workspace descriptor
296 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
297 std::cout << "Destroyed the workspace descriptor\n";
298
299 // Destroy the quantum circuit expectation value
300 HANDLE_CUTN_ERROR(cutensornetDestroyExpectation(expectation));
301 std::cout << "Destroyed the quantum circuit state expectation value\n";
302
303 // Destroy the tensor network operator
304 HANDLE_CUTN_ERROR(cutensornetDestroyNetworkOperator(hamiltonian));
305 std::cout << "Destroyed the tensor network operator\n";
306
307 // Destroy the quantum circuit state
308 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
309 std::cout << "Destroyed the quantum circuit state\n";
310
311 for (int32_t i = 0; i < numQubits; i++) {
312 HANDLE_CUDA_ERROR(cudaFree(d_mpsTensors[i]));
313 }
314 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
315 HANDLE_CUDA_ERROR(cudaFree(d_gateCX));
316 HANDLE_CUDA_ERROR(cudaFree(d_gateZ));
317 HANDLE_CUDA_ERROR(cudaFree(d_gateY));
318 HANDLE_CUDA_ERROR(cudaFree(d_gateX));
319 HANDLE_CUDA_ERROR(cudaFree(d_gateH));
320 std::cout << "Freed memory on GPU\n";
321
322 // Finalize the cuTensorNet library
323 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
324 std::cout << "Finalized the cuTensorNet library\n";
325
326 return 0;
327}
Code example (MPS marginal distribution)#
Computing Matrix Product State marginal distribution tensor#
The following code example illustrates how to define a tensor network state, compute its Matrix Product State (MPS) factorization, and then compute a marginal distribution tensor for the MPS-factorized state. The full code can be found in the NVIDIA/cuQuantum repository (here).
Headers and error handling#
7#include <cstdlib>
8#include <cstdio>
9#include <cassert>
10#include <complex>
11#include <vector>
12#include <bitset>
13#include <iostream>
14
15#include <cuda_runtime.h>
16#include <cutensornet.h>
17
18
19#define HANDLE_CUDA_ERROR(x) \
20{ const auto err = x; \
21 if( err != cudaSuccess ) \
22 { printf("CUDA error %s in line %d\n", cudaGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
23};
24
25#define HANDLE_CUTN_ERROR(x) \
26{ const auto err = x; \
27 if( err != CUTENSORNET_STATUS_SUCCESS ) \
28 { printf("cuTensorNet error %s in line %d\n", cutensornetGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
29};
30
31
32int main()
33{
34 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
35
36 constexpr std::size_t fp64size = sizeof(double);
Define the tensor network state and the desired marginal distribution tensor#
Let’s define a tensor network state corresponding to a 16-qubit quantum circuit and request the marginal distribution tensor for qubits 0 and 1.
40 // Quantum state configuration
41 constexpr int32_t numQubits = 16;
42 const std::vector<int64_t> qubitDims(numQubits,2); // qubit dimensions
43 constexpr int32_t numMarginalModes = 2; // rank of the marginal (reduced density matrix)
44 const std::vector<int32_t> marginalModes({0,1}); // open qubits (must be in acsending order)
45 std::cout << "Quantum circuit: " << numQubits << " qubits\n";
Initialize the cuTensorNet library handle#
49 // Initialize the cuTensorNet library
50 HANDLE_CUDA_ERROR(cudaSetDevice(0));
51 cutensornetHandle_t cutnHandle;
52 HANDLE_CUTN_ERROR(cutensornetCreate(&cutnHandle));
53 std::cout << "Initialized cuTensorNet library on GPU 0\n";
Define quantum gates on GPU#
57 // Define necessary quantum gate tensors in Host memory
58 const double invsq2 = 1.0 / std::sqrt(2.0);
59 // Hadamard gate
60 const std::vector<std::complex<double>> h_gateH {{invsq2, 0.0}, {invsq2, 0.0},
61 {invsq2, 0.0}, {-invsq2, 0.0}};
62 // CX gate
63 const std::vector<std::complex<double>> h_gateCX {{1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
64 {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
65 {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0},
66 {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}};
67
68 // Copy quantum gates to Device memory
69 void *d_gateH{nullptr}, *d_gateCX{nullptr};
70 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateH, 4 * (2 * fp64size)));
71 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateCX, 16 * (2 * fp64size)));
72 std::cout << "Allocated quantum gate memory on GPU\n";
73 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateH, h_gateH.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
74 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateCX, h_gateCX.data(), 16 * (2 * fp64size), cudaMemcpyHostToDevice));
75 std::cout << "Copied quantum gates to GPU memory\n";
Allocate MPS tensors#
Here we set the shapes of MPS tensors and allocate GPU memory for their storage.
79 // Determine the MPS representation and allocate buffers for the MPS tensors
80 const int64_t maxExtent = 2; // GHZ state can be exactly represented with max bond dimension of 2
81 std::vector<std::vector<int64_t>> extents;
82 std::vector<int64_t*> extentsPtr(numQubits);
83 std::vector<void*> d_mpsTensors(numQubits, nullptr);
84 for (int32_t i = 0; i < numQubits; i++) {
85 if (i == 0) { // left boundary MPS tensor
86 extents.push_back({2, maxExtent});
87 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * 2 * fp64size));
88 }
89 else if (i == numQubits-1) { // right boundary MPS tensor
90 extents.push_back({maxExtent, 2});
91 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * 2 * fp64size));
92 }
93 else { // middle MPS tensors
94 extents.push_back({maxExtent, 2, maxExtent});
95 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * maxExtent * 2 * fp64size));
96 }
97 extentsPtr[i] = extents[i].data();
98 }
Allocate the marginal distribution tensor on GPU#
Here we allocate the marginal distribution tensor, that is, the reduced density matrix for qubits 0 and 1, on GPU.
102 // Allocate the specified quantum circuit reduced density matrix (marginal) in Device memory
103 void *d_rdm{nullptr};
104 std::size_t rdmDim = 1;
105 for(const auto & mode: marginalModes) rdmDim *= qubitDims[mode];
106 const std::size_t rdmSize = rdmDim * rdmDim;
107 HANDLE_CUDA_ERROR(cudaMalloc(&d_rdm, rdmSize * (2 * fp64size)));
Allocate the scratch buffer on GPU#
111 // Query the free memory on Device
112 std::size_t freeSize{0}, totalSize{0};
113 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeSize, &totalSize));
114 const std::size_t scratchSize = (freeSize - (freeSize % 4096)) / 2; // use half of available memory with alignment
115 void *d_scratch{nullptr};
116 HANDLE_CUDA_ERROR(cudaMalloc(&d_scratch, scratchSize));
117 std::cout << "Allocated " << scratchSize << " bytes of scratch memory on GPU\n";
Create a pure tensor network state#
Now let’s create a pure tensor network state for a 16-qubit quantum circuit.
121 // Create the initial quantum state
122 cutensornetState_t quantumState;
123 HANDLE_CUTN_ERROR(cutensornetCreateState(cutnHandle, CUTENSORNET_STATE_PURITY_PURE, numQubits, qubitDims.data(),
124 CUDA_C_64F, &quantumState));
125 std::cout << "Created the initial quantum state\n";
Apply quantum gates#
Let’s construct the GHZ quantum circuit by applying the corresponding quantum gates.
129 // Construct the final quantum circuit state (apply quantum gates) for the GHZ circuit
130 int64_t id;
131 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 1, std::vector<int32_t>{{0}}.data(),
132 d_gateH, nullptr, 1, 0, 1, &id));
133 for(int32_t i = 1; i < numQubits; ++i) {
134 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 2, std::vector<int32_t>{{i-1,i}}.data(),
135 d_gateCX, nullptr, 1, 0, 1, &id));
136 }
137 std::cout << "Applied quantum gates\n";
Request MPS factorization for the final quantum circuit state#
Here we express our intent to factorize the final quantum circuit state using MPS factorization. The provided shapes of the MPS tensors refer to their maximal size limit during the MPS renormalization procedure. The actually computed shapes of the final MPS tensors may be smaller. No computation is done here yet.
141 // Specify the final target MPS representation (use default fortran strides)
142 HANDLE_CUTN_ERROR(cutensornetStateFinalizeMPS(cutnHandle, quantumState,
143 CUTENSORNET_BOUNDARY_CONDITION_OPEN, extentsPtr.data(), /*strides=*/nullptr));
144 std::cout << "Requested the final MPS factorization of the quantum circuit state\n";
Configure MPS factorization procedure#
After expressing our intent to perform MPS factorization of the final quantum circuit state, we can also configure the MPS factorization procedure by resetting different options, for example, the SVD algorithm.
148 // Optional, set up the SVD method for MPS truncation.
149 cutensornetTensorSVDAlgo_t algo = CUTENSORNET_TENSOR_SVD_ALGO_GESVDJ;
150 HANDLE_CUTN_ERROR(cutensornetStateConfigure(cutnHandle, quantumState,
151 CUTENSORNET_STATE_CONFIG_MPS_SVD_ALGO, &algo, sizeof(algo)));
152 std::cout << "Configured the MPS factorization computation\n";
Prepare the computation of MPS factorization#
Let’s create a workspace descriptor and prepare the computation of MPS factorization.
156 // Prepare the MPS computation and attach workspace
157 cutensornetWorkspaceDescriptor_t workDesc;
158 HANDLE_CUTN_ERROR(cutensornetCreateWorkspaceDescriptor(cutnHandle, &workDesc));
159 std::cout << "Created the workspace descriptor\n";
160 HANDLE_CUTN_ERROR(cutensornetStatePrepare(cutnHandle, quantumState, scratchSize, workDesc, 0x0));
161 std::cout << "Prepared the computation of the quantum circuit state\n";
162 double flops {0.0};
163 HANDLE_CUTN_ERROR(cutensornetStateGetInfo(cutnHandle, quantumState,
164 CUTENSORNET_STATE_INFO_FLOPS, &flops, sizeof(flops)));
165 if(flops > 0.0) {
166 std::cout << "Total flop count = " << (flops/1e9) << " GFlop\n";
167 }else if(flops < 0.0) {
168 std::cout << "ERROR: Negative Flop count!\n";
169 std::abort();
170 }
171
172 int64_t worksize {0};
173 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
174 workDesc,
175 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
176 CUTENSORNET_MEMSPACE_DEVICE,
177 CUTENSORNET_WORKSPACE_SCRATCH,
178 &worksize));
179 std::cout << "Scratch GPU workspace size (bytes) for MPS computation = " << worksize << std::endl;
180 if(worksize <= scratchSize) {
181 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
182 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
183 }else{
184 std::cout << "ERROR: Insufficient workspace size on Device!\n";
185 std::abort();
186 }
187 std::cout << "Set the workspace buffer for the MPS factorization computation\n";
Compute MPS factorization#
Once the MPS factorization procedure has been configured and prepared, let’s compute the MPS factorization of the final quantum circuit state.
191 // Execute MPS computation
192 HANDLE_CUTN_ERROR(cutensornetStateCompute(cutnHandle, quantumState,
193 workDesc, extentsPtr.data(), /*strides=*/nullptr, d_mpsTensors.data(), 0));
194 std::cout << "Computed the MPS factorization\n";
Create the marginal distribution object#
Once the quantum circuit has been constructed, let’s create the marginal distribution object that will compute the marginal distribution tensor (reduced density matrix) for qubits 0 and 1.
198 // Specify the desired reduced density matrix (marginal)
199 cutensornetStateMarginal_t marginal;
200 HANDLE_CUTN_ERROR(cutensornetCreateMarginal(cutnHandle, quantumState, numMarginalModes, marginalModes.data(),
201 0, nullptr, std::vector<int64_t>{{1,2,4,8}}.data(), &marginal)); // using explicit strides
202 std::cout << "Created the specified quantum circuit reduced densitry matrix (marginal)\n";
Configure the marginal distribution object#
Now we can configure the marginal distribution object by setting the number of hyper-samples to be used by the tensor network contraction path finder.
206 // Configure the computation of the specified quantum circuit reduced density matrix (marginal)
207 const int32_t numHyperSamples = 8; // desired number of hyper samples used in the tensor network contraction path finder
208 HANDLE_CUTN_ERROR(cutensornetMarginalConfigure(cutnHandle, marginal,
209 CUTENSORNET_MARGINAL_CONFIG_NUM_HYPER_SAMPLES, &numHyperSamples, sizeof(numHyperSamples)));
210 std::cout << "Configured the specified quantum circuit reduced density matrix (marginal) computation\n";
Prepare the computation of the marginal distribution tensor#
Let’s prepare the computation of the marginal distribution tensor.
214 // Prepare the specified quantum circuit reduced densitry matrix (marginal)
215 HANDLE_CUTN_ERROR(cutensornetMarginalPrepare(cutnHandle, marginal, scratchSize, workDesc, 0x0));
216 std::cout << "Prepared the specified quantum circuit reduced density matrix (marginal)\n";
217 flops = 0.0;
218 HANDLE_CUTN_ERROR(cutensornetMarginalGetInfo(cutnHandle, marginal,
219 CUTENSORNET_MARGINAL_INFO_FLOPS, &flops, sizeof(flops)));
220 std::cout << "Total flop count = " << (flops/1e9) << " GFlop\n";
221 if(flops <= 0.0) {
222 std::cout << "ERROR: Invalid Flop count!\n";
223 std::abort();
224 }
Set up the workspace#
Now we can set up the required workspace buffer.
228 // Attach the workspace buffer
229 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
230 workDesc,
231 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
232 CUTENSORNET_MEMSPACE_DEVICE,
233 CUTENSORNET_WORKSPACE_SCRATCH,
234 &worksize));
235 std::cout << "Required scratch GPU workspace size (bytes) for marginal computation = " << worksize << std::endl;
236 if(worksize <= scratchSize) {
237 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
238 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
239 }else{
240 std::cout << "ERROR: Insufficient workspace size on Device!\n";
241 std::abort();
242 }
243 std::cout << "Set the workspace buffer\n";
244
Compute the marginal distribution tensor#
Once everything has been set up, we compute the requested marginal distribution tensor (reduced density matrix) for qubits 0 and 1, copy it back to Host memory, and print it.
247 // Compute the specified quantum circuit reduced densitry matrix (marginal)
248 HANDLE_CUTN_ERROR(cutensornetMarginalCompute(cutnHandle, marginal, nullptr, workDesc, d_rdm, 0));
249 std::cout << "Computed the specified quantum circuit reduced density matrix (marginal)\n";
250 std::vector<std::complex<double>> h_rdm(rdmSize);
251 HANDLE_CUDA_ERROR(cudaMemcpy(h_rdm.data(), d_rdm, rdmSize * (2 * fp64size), cudaMemcpyDeviceToHost));
252 std::cout << "Reduced density matrix for " << numMarginalModes << " qubits:\n";
253 for(std::size_t i = 0; i < rdmDim; ++i) {
254 for(std::size_t j = 0; j < rdmDim; ++j) {
255 std::cout << " " << h_rdm[i + j * rdmDim];
256 }
257 std::cout << std::endl;
258 }
Free resources#
262 // Destroy the workspace descriptor
263 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
264 std::cout << "Destroyed the workspace descriptor\n";
265
266 // Destroy the quantum circuit reduced density matrix
267 HANDLE_CUTN_ERROR(cutensornetDestroyMarginal(marginal));
268 std::cout << "Destroyed the quantum circuit state reduced density matrix (marginal)\n";
269
270 // Destroy the quantum circuit state
271 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
272 std::cout << "Destroyed the quantum circuit state\n";
273
274 for (int32_t i = 0; i < numQubits; i++) {
275 HANDLE_CUDA_ERROR(cudaFree(d_mpsTensors[i]));
276 }
277 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
278 HANDLE_CUDA_ERROR(cudaFree(d_rdm));
279 HANDLE_CUDA_ERROR(cudaFree(d_gateCX));
280 HANDLE_CUDA_ERROR(cudaFree(d_gateH));
281 std::cout << "Freed memory on GPU\n";
282
283 // Finalize the cuTensorNet library
284 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
285 std::cout << "Finalized the cuTensorNet library\n";
286
287 return 0;
288}
Code example (MPS sampling)#
Sampling the Matrix Product State#
The following code example illustrates how to define a tensor network state for a given quantum circuit, then compute its Matrix Product State (MPS) factorization, and, finally, sample the MPS-factorized state. The full code can be found in the NVIDIA/cuQuantum repository (here).
Headers and error handling#
7#include <cstdlib>
8#include <cstdio>
9#include <cassert>
10#include <complex>
11#include <vector>
12#include <iostream>
13
14#include <cuda_runtime.h>
15#include <cutensornet.h>
16
17#define HANDLE_CUDA_ERROR(x) \
18{ const auto err = x; \
19 if( err != cudaSuccess ) \
20 { printf("CUDA error %s in line %d\n", cudaGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
21};
22
23#define HANDLE_CUTN_ERROR(x) \
24{ const auto err = x; \
25 if( err != CUTENSORNET_STATUS_SUCCESS ) \
26 { printf("cuTensorNet error %s in line %d\n", cutensornetGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
27};
28
29
30int main()
31{
32 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
33
34 constexpr std::size_t fp64size = sizeof(double);
Define the tensor network state and the desired number of output samples to generate#
Let’s define a tensor network state corresponding to a 16-qubit quantum circuit and request to produce 100 output samples for the full qubit register.
38 // Quantum state configuration
39 const int64_t numSamples = 100;
40 const int32_t numQubits = 16;
41 const std::vector<int64_t> qubitDims(numQubits, 2); // qubit size
42 std::cout << "Quantum circuit: " << numQubits << " qubits; " << numSamples << " samples\n";
Initialize the cuTensorNet library handle#
46 // Initialize the cuTensorNet library
47 HANDLE_CUDA_ERROR(cudaSetDevice(0));
48 cutensornetHandle_t cutnHandle;
49 HANDLE_CUTN_ERROR(cutensornetCreate(&cutnHandle));
50 std::cout << "Initialized cuTensorNet library on GPU 0\n";
Define quantum gates on GPU#
54 // Define necessary quantum gate tensors in Host memory
55 const double invsq2 = 1.0 / std::sqrt(2.0);
56 // Hadamard gate
57 const std::vector<std::complex<double>> h_gateH {{invsq2, 0.0}, {invsq2, 0.0},
58 {invsq2, 0.0}, {-invsq2, 0.0}};
59 // CX gate
60 const std::vector<std::complex<double>> h_gateCX {{1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
61 {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
62 {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0},
63 {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}};
64
65 // Copy quantum gates to Device memory
66 void *d_gateH{nullptr}, *d_gateCX{nullptr};
67 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateH, 4 * (2 * fp64size)));
68 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateCX, 16 * (2 * fp64size)));
69 std::cout << "Allocated GPU memory for quantum gates\n";
70 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateH, h_gateH.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
71 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateCX, h_gateCX.data(), 16 * (2 * fp64size), cudaMemcpyHostToDevice));
72 std::cout << "Copied quantum gates to GPU memory\n";
Allocate MPS tensors#
Here we set the shapes of MPS tensors and allocate GPU memory for their storage.
76 // Determine the MPS representation and allocate buffer for the MPS tensors
77 const int64_t maxExtent = 2; // GHZ state can be exactly represented with max bond dimension of 2
78 std::vector<std::vector<int64_t>> extents;
79 std::vector<int64_t*> extentsPtr(numQubits);
80 std::vector<void*> d_mpsTensors(numQubits, nullptr);
81 for (int32_t i = 0; i < numQubits; i++) {
82 if (i == 0) { // left boundary MPS tensor
83 extents.push_back({2, maxExtent});
84 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * 2 * fp64size));
85 }
86 else if (i == numQubits-1) { // right boundary MPS tensor
87 extents.push_back({maxExtent, 2});
88 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * 2 * fp64size));
89 }
90 else { // middle MPS tensors
91 extents.push_back({maxExtent, 2, maxExtent});
92 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * maxExtent * 2 * fp64size));
93 }
94 extentsPtr[i] = extents[i].data();
95 }
Allocate the scratch buffer on GPU#
99 // Query the free memory on Device
100 std::size_t freeSize {0}, totalSize {0};
101 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeSize, &totalSize));
102 const std::size_t scratchSize = (freeSize - (freeSize % 4096)) / 2; // use half of available memory with alignment
103 void *d_scratch {nullptr};
104 HANDLE_CUDA_ERROR(cudaMalloc(&d_scratch, scratchSize));
105 std::cout << "Allocated " << scratchSize << " bytes of scratch memory on GPU: "
106 << "[" << d_scratch << ":" << (void*)(((char*)(d_scratch)) + scratchSize) << ")\n";
Create a pure tensor network state#
Now let’s create a pure tensor network state for a 16-qubit quantum circuit.
110 // Create the initial quantum state
111 cutensornetState_t quantumState;
112 HANDLE_CUTN_ERROR(cutensornetCreateState(cutnHandle, CUTENSORNET_STATE_PURITY_PURE, numQubits, qubitDims.data(),
113 CUDA_C_64F, &quantumState));
114 std::cout << "Created the initial quantum state\n";
Apply quantum gates#
Let’s construct the GHZ quantum circuit by applying the corresponding quantum gates.
118 // Construct the quantum circuit state (apply quantum gates)
119 int64_t id;
120 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 1, std::vector<int32_t>{{0}}.data(),
121 d_gateH, nullptr, 1, 0, 1, &id));
122 for(int32_t i = 1; i < numQubits; ++i) {
123 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 2, std::vector<int32_t>{{i-1,i}}.data(),
124 d_gateCX, nullptr, 1, 0, 1, &id));
125 }
126 std::cout << "Applied quantum gates\n";
Request MPS factorization for the final quantum circuit state#
Here we express our intent to factorize the final quantum circuit state using MPS factorization. The provided shapes of the MPS tensors refer to their maximal size limit during the MPS renormalization procedure. The actually computed shapes of the final MPS tensors may be smaller. No computation is done here yet.
130 // Specify the final target MPS representation (use default fortran strides)
131 HANDLE_CUTN_ERROR(cutensornetStateFinalizeMPS(cutnHandle, quantumState,
132 CUTENSORNET_BOUNDARY_CONDITION_OPEN, extentsPtr.data(), /*strides=*/nullptr ));
Configure MPS factorization procedure#
After expressing our intent to perform MPS factorization of the final quantum circuit state, we can also configure the MPS factorization procedure by resetting different options, for example, the SVD algorithm.
136 // Optional, set up the SVD method for truncation.
137 cutensornetTensorSVDAlgo_t algo = CUTENSORNET_TENSOR_SVD_ALGO_GESVDJ;
138 HANDLE_CUTN_ERROR(cutensornetStateConfigure(cutnHandle, quantumState,
139 CUTENSORNET_STATE_CONFIG_MPS_SVD_ALGO, &algo, sizeof(algo)));
140 std::cout << "Configured the MPS computation\n";
Prepare the computation of MPS factorization#
Let’s create a workspace descriptor and prepare the computation of MPS factorization.
144 // Prepare the MPS computation and attach workspace
145 cutensornetWorkspaceDescriptor_t workDesc;
146 HANDLE_CUTN_ERROR(cutensornetCreateWorkspaceDescriptor(cutnHandle, &workDesc));
147 std::cout << "Created the workspace descriptor\n";
148 HANDLE_CUTN_ERROR(cutensornetStatePrepare(cutnHandle, quantumState, scratchSize, workDesc, 0x0));
149 std::cout << "Prepared the computation of the quantum circuit state\n";
150 double flops {0.0};
151 HANDLE_CUTN_ERROR(cutensornetStateGetInfo(cutnHandle, quantumState,
152 CUTENSORNET_STATE_INFO_FLOPS, &flops, sizeof(flops)));
153 if(flops > 0.0) {
154 std::cout << "Total flop count = " << (flops/1e9) << " GFlop\n";
155 }else if(flops < 0.0) {
156 std::cout << "ERROR: Negative Flop count!\n";
157 std::abort();
158 }
159
160 int64_t worksize {0};
161 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
162 workDesc,
163 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
164 CUTENSORNET_MEMSPACE_DEVICE,
165 CUTENSORNET_WORKSPACE_SCRATCH,
166 &worksize));
167 std::cout << "Scratch GPU workspace size (bytes) for MPS computation = " << worksize << std::endl;
168 if(worksize <= scratchSize) {
169 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
170 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
171 }else{
172 std::cout << "ERROR: Insufficient workspace size on Device!\n";
173 std::abort();
174 }
175 std::cout << "Set the workspace buffer for MPS computation\n";
Compute MPS factorization#
Once the MPS factorization procedure has been configured and prepared, let’s compute the MPS factorization of the final quantum circuit state.
179 // Execute MPS computation
180 HANDLE_CUTN_ERROR(cutensornetStateCompute(cutnHandle, quantumState,
181 workDesc, extentsPtr.data(), /*strides=*/nullptr, d_mpsTensors.data(), 0));
182 std::cout << "Computed MPS factorization\n";
Create the tensor network state sampler#
Once the quantum circuit has been constructed and factorized using the MPS representation, let’s create the tensor network state sampler for the full qubit register (all qubits).
186 // Create the quantum circuit sampler
187 cutensornetStateSampler_t sampler;
188 HANDLE_CUTN_ERROR(cutensornetCreateSampler(cutnHandle, quantumState, numQubits, nullptr, &sampler));
189 std::cout << "Created the quantum circuit sampler\n";
Configure the tensor network state sampler#
Now we can configure the tensor network state sampler by setting the number of hyper-samples to be used by the tensor network contraction path finder.
193 // Configure the quantum circuit sampler
194 const int32_t numHyperSamples = 8; // desired number of hyper samples used in the tensor network contraction path finder
195 HANDLE_CUTN_ERROR(cutensornetSamplerConfigure(cutnHandle, sampler,
196 CUTENSORNET_SAMPLER_CONFIG_NUM_HYPER_SAMPLES, &numHyperSamples, sizeof(numHyperSamples)));
197 std::cout << "Configured the quantum circuit sampler\n";
Prepare the tensor network state sampler#
Let’s prepare the tensor network state sampler.
201 // Prepare the quantum circuit sampler
202 HANDLE_CUTN_ERROR(cutensornetSamplerPrepare(cutnHandle, sampler, scratchSize, workDesc, 0x0));
203 std::cout << "Prepared the quantum circuit state sampler\n";
204 flops = 0.0;
205 HANDLE_CUTN_ERROR(cutensornetSamplerGetInfo(cutnHandle, sampler,
206 CUTENSORNET_SAMPLER_INFO_FLOPS, &flops, sizeof(flops)));
207 std::cout << "Total flop count per sample = " << (flops/1e9) << " GFlop\n";
208 if(flops <= 0.0) {
209 std::cout << "ERROR: Invalid Flop count!\n";
210 std::abort();
211 }
Set up the workspace#
Now we can set up the required workspace buffer.
215 // Attach the workspace buffer
216 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
217 workDesc,
218 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
219 CUTENSORNET_MEMSPACE_DEVICE,
220 CUTENSORNET_WORKSPACE_SCRATCH,
221 &worksize));
222 std::cout << "Scratch GPU workspace size (bytes) for MPS Sampling = " << worksize << std::endl;
223 assert(worksize > 0);
224 if(worksize <= scratchSize) {
225 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
226 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
227 }else{
228 std::cout << "ERROR: Insufficient workspace size on Device!\n";
229 std::abort();
230 }
231 std::cout << "Set the workspace buffer\n";
Perform sampling of the final quantum circuit state#
Once everything had been set up, we perform sampling of the quantum circuit state and print the output samples.
235 // Sample the quantum circuit state
236 std::vector<int64_t> samples(numQubits * numSamples); // samples[SampleId][QubitId] reside in Host memory
237 HANDLE_CUTN_ERROR(cutensornetSamplerSample(cutnHandle, sampler, numSamples, workDesc, samples.data(), 0));
238 std::cout << "Performed quantum circuit state sampling\n";
239 std::cout << "Bit-string samples:\n";
240 for(int64_t i = 0; i < numSamples; ++i) {
241 for(int64_t j = 0; j < numQubits; ++j) std::cout << " " << samples[i * numQubits + j];
242 std::cout << std::endl;
243 }
Free resources#
247 // Destroy the workspace descriptor
248 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
249 std::cout << "Destroyed the workspace descriptor\n";
250
251 // Destroy the quantum circuit sampler
252 HANDLE_CUTN_ERROR(cutensornetDestroySampler(sampler));
253 std::cout << "Destroyed the quantum circuit state sampler\n";
254
255 // Destroy the quantum circuit state
256 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
257 std::cout << "Destroyed the quantum circuit state\n";
258
259 for (int32_t i = 0; i < numQubits; i++) {
260 HANDLE_CUDA_ERROR(cudaFree(d_mpsTensors[i]));
261 }
262 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
263 HANDLE_CUDA_ERROR(cudaFree(d_gateCX));
264 HANDLE_CUDA_ERROR(cudaFree(d_gateH));
265 std::cout << "Freed memory on GPU\n";
266
267 // Finalize the cuTensorNet library
268 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
269 std::cout << "Finalized the cuTensorNet library\n";
270
271 return 0;
272}
Code example (MPS sampling QFT)#
Sampling the Matrix Product State (QFT Circuit)#
The following code example illustrates how to define a tensor network state for a given quantum circuit (QFT), then compute its Matrix Product State (MPS) factorization, and, finally, sample the MPS-factorized state. The full code can be found in the NVIDIA/cuQuantum repository (here).
Headers and error handling#
7#include <cstdlib>
8#include <cstdio>
9#include <cassert>
10#include <complex>
11#include <cmath>
12#include <vector>
13#include <iostream>
14
15#include <cuda_runtime.h>
16#include <cutensornet.h>
17
18#define HANDLE_CUDA_ERROR(x) \
19{ const auto err = x; \
20 if( err != cudaSuccess ) \
21 { printf("CUDA error %s in line %d\n", cudaGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
22};
23
24#define HANDLE_CUTN_ERROR(x) \
25{ const auto err = x; \
26 if( err != CUTENSORNET_STATUS_SUCCESS ) \
27 { printf("cuTensorNet error %s in line %d\n", cutensornetGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
28};
29
30
31int main()
32{
33 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
34
35 constexpr std::size_t fp64size = sizeof(double);
Define the tensor network state and the desired number of output samples to generate#
Let’s define a tensor network state for a quantum circuit with the given number of qubits and request to produce a given number of output samples for the full qubit register.
39 // Quantum state configuration
40 const int64_t numSamples = 128; // number of samples to generate
41 const int32_t numQubits = 16; // number of qubits
42 const std::vector<int64_t> qubitDims(numQubits, 2); // qubit dimensions
43 std::cout << "Quantum circuit: " << numQubits << " qubits; " << numSamples << " samples\n";
Initialize the cuTensorNet library handle#
47 // Initialize the cuTensorNet library
48 HANDLE_CUDA_ERROR(cudaSetDevice(0));
49 cutensornetHandle_t cutnHandle;
50 HANDLE_CUTN_ERROR(cutensornetCreate(&cutnHandle));
51 std::cout << "Initialized cuTensorNet library on GPU 0\n";
Define quantum gates in GPU memory#
55 // Define necessary quantum gate tensors in Host memory
56 const double invsq2 = 1.0 / std::sqrt(2.0);
57 const double pi = 3.14159265358979323846;
58 using GateData = std::vector<std::complex<double>>;
59 // CR(k) gate generator
60 auto cRGate = [&pi] (int32_t k) {
61 const double phi = pi * 2.0 / std::exp2(k);
62 const GateData cr {{1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
63 {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
64 {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0},
65 {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {std::cos(phi), std::sin(phi)}};
66 return cr;
67 };
68 // Hadamard gate
69 const GateData h_gateH {{invsq2, 0.0}, {invsq2, 0.0},
70 {invsq2, 0.0}, {-invsq2, 0.0}};
71 // CR(k) gates (controlled rotations)
72 std::vector<GateData> h_gateCR(numQubits);
73 for(int32_t k = 0; k < numQubits; ++k) {
74 h_gateCR[k] = cRGate(k+1);
75 }
76
77 // Copy quantum gates into Device memory
78 void *d_gateH {nullptr};
79 std::vector<void*> d_gateCR(numQubits, nullptr);
80 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateH, 4 * (2 * fp64size)));
81 for(int32_t k = 0; k < numQubits; ++k) {
82 HANDLE_CUDA_ERROR(cudaMalloc(&(d_gateCR[k]), 16 * (2 * fp64size)));
83 }
84 std::cout << "Allocated GPU memory for quantum gates\n";
85 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateH, h_gateH.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
86 for(int32_t k = 0; k < numQubits; ++k) {
87 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateCR[k], h_gateCR[k].data(), 16 * (2 * fp64size), cudaMemcpyHostToDevice));
88 }
89 std::cout << "Copied quantum gates into GPU memory\n";
Allocate MPS tensors in GPU memory#
Here we set the shapes of MPS tensors and allocate GPU memory for their storage.
93 // Define the MPS representation and allocate memory buffers for the MPS tensors
94 const int64_t maxExtent = 8; // max bond dimension (level of low-rank MPS approximation)
95 std::vector<std::vector<int64_t>> extents;
96 std::vector<int64_t*> extentsPtr(numQubits);
97 std::vector<void*> d_mpsTensors(numQubits, nullptr);
98 for (int32_t i = 0; i < numQubits; ++i) {
99 if (i == 0) { // left boundary MPS tensor
100 extents.push_back({2, maxExtent});
101 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * (2 * fp64size)));
102 }
103 else if (i == numQubits-1) { // right boundary MPS tensor
104 extents.push_back({maxExtent, 2});
105 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * (2 * fp64size)));
106 }
107 else { // middle MPS tensors
108 extents.push_back({maxExtent, 2, maxExtent});
109 HANDLE_CUDA_ERROR(cudaMalloc(&d_mpsTensors[i], 2 * maxExtent * maxExtent * (2 * fp64size)));
110 }
111 extentsPtr[i] = extents[i].data();
112 }
113 std::cout << "Allocated GPU memory for MPS tensors\n";
Allocate the scratch buffer on GPU#
117 // Query free memory on Device and allocate a scratch buffer
118 std::size_t freeSize {0}, totalSize {0};
119 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeSize, &totalSize));
120 const std::size_t scratchSize = (freeSize - (freeSize % 4096)) / 2; // use half of available memory with alignment
121 void *d_scratch {nullptr};
122 HANDLE_CUDA_ERROR(cudaMalloc(&d_scratch, scratchSize));
123 std::cout << "Allocated " << scratchSize << " bytes of scratch memory on GPU: "
124 << "[" << d_scratch << ":" << (void*)(((char*)(d_scratch)) + scratchSize) << ")\n";
Create a pure tensor network state#
Now let’s create a pure tensor network state for a quantum circuit with the given number of qubits.
128 // Create the initial quantum state
129 cutensornetState_t quantumState;
130 HANDLE_CUTN_ERROR(cutensornetCreateState(cutnHandle, CUTENSORNET_STATE_PURITY_PURE, numQubits, qubitDims.data(),
131 CUDA_C_64F, &quantumState));
132 std::cout << "Created the initial (vacuum) quantum state\n";
Apply quantum gates#
Let’s construct the QFT quantum circuit with no bit reversal by applying the corresponding quantum gates.
136 // Construct the QFT quantum circuit state (apply quantum gates)
137 // Example of a QFT circuit with 3 qubits (with no bit reversal):
138 // Q0--H--CR2--CR3-------------
139 // | |
140 // Q1-----o----|----H--CR2-----
141 // | |
142 // Q2----------o-------o----H--
143 int64_t id;
144 for(int32_t i = 0; i < numQubits; ++i) {
145 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 1, std::vector<int32_t>{{i}}.data(),
146 d_gateH, nullptr, 1, 0, 1, &id));
147 for(int32_t j = (i+1); j < numQubits; ++j) {
148 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 2, std::vector<int32_t>{{j,i}}.data(),
149 d_gateCR[j-i], nullptr, 1, 0, 1, &id));
150 }
151 }
152 std::cout << "Applied quantum gates\n";
Request MPS factorization for the final quantum circuit state#
Here we express our intent to factorize the final quantum circuit state using MPS factorization. The provided shapes (mode extents) of the MPS tensors refer to their maximal size limit during the MPS renormalization procedure. The actually computed shapes (mode extents) of the final MPS tensors may be smaller than their limits. Note that no computation is done here yet.
156 // Specify the target MPS representation (use default strides)
157 HANDLE_CUTN_ERROR(cutensornetStateFinalizeMPS(cutnHandle, quantumState,
158 CUTENSORNET_BOUNDARY_CONDITION_OPEN, extentsPtr.data(), /*strides=*/nullptr ));
159 std::cout << "Finalized the form of the MPS representation\n";
Configure MPS factorization procedure#
After expressing our intent to perform MPS factorization of the final quantum circuit state, we can also configure the MPS factorization procedure by resetting different options, for example, the SVD algorithm.
163 // Set up the SVD method for bonds truncation (optional)
164 cutensornetTensorSVDAlgo_t algo = CUTENSORNET_TENSOR_SVD_ALGO_GESVDJ;
165 HANDLE_CUTN_ERROR(cutensornetStateConfigure(cutnHandle, quantumState,
166 CUTENSORNET_STATE_MPS_SVD_CONFIG_ALGO, &algo, sizeof(algo)));
167 std::cout << "Configured the MPS computation\n";
Prepare the computation of MPS factorization#
Let’s create a workspace descriptor and prepare the computation of the MPS factorization of the final quantum circuit state.
171 // Prepare the MPS computation and attach a workspace buffer
172 cutensornetWorkspaceDescriptor_t workDesc;
173 HANDLE_CUTN_ERROR(cutensornetCreateWorkspaceDescriptor(cutnHandle, &workDesc));
174 std::cout << "Created the workspace descriptor\n";
175 HANDLE_CUTN_ERROR(cutensornetStatePrepare(cutnHandle, quantumState, scratchSize, workDesc, 0x0));
176 int64_t worksize {0};
177 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
178 workDesc,
179 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
180 CUTENSORNET_MEMSPACE_DEVICE,
181 CUTENSORNET_WORKSPACE_SCRATCH,
182 &worksize));
183 std::cout << "Scratch GPU workspace size (bytes) for MPS computation = " << worksize << std::endl;
184 if(worksize <= scratchSize) {
185 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
186 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
187 }else{
188 std::cout << "ERROR: Insufficient workspace size on Device!\n";
189 std::abort();
190 }
191 std::cout << "Set the workspace buffer for MPS computation\n";
Compute MPS factorization#
Once the MPS factorization procedure has been configured and prepared, let’s compute the MPS factorization of the final quantum circuit state.
195 // Compute the MPS factorization of the quantum circuit state
196 HANDLE_CUTN_ERROR(cutensornetStateCompute(cutnHandle, quantumState,
197 workDesc, extentsPtr.data(), /*strides=*/nullptr, d_mpsTensors.data(), 0));
198 std::cout << "Computed the MPS factorization of the quantum circuit state\n";
199
Create the tensor network state sampler#
Once the quantum circuit state has been constructed and factorized using the MPS representation, let’s create the tensor network state sampler for the full qubit register (all qubits).
202 // Create the quantum circuit sampler
203 cutensornetStateSampler_t sampler;
204 HANDLE_CUTN_ERROR(cutensornetCreateSampler(cutnHandle, quantumState, numQubits, nullptr, &sampler));
205 std::cout << "Created the quantum circuit sampler\n";
Configure the tensor network state sampler#
Optionally, we can configure the tensor network state sampler by setting the number of hyper-samples to be used by the tensor network contraction path finder.
209 // Configure the quantum circuit sampler
210 const int32_t numHyperSamples = 8; // desired number of hyper samples used in the tensor network contraction path finder
211 HANDLE_CUTN_ERROR(cutensornetSamplerConfigure(cutnHandle, sampler,
212 CUTENSORNET_SAMPLER_OPT_NUM_HYPER_SAMPLES, &numHyperSamples, sizeof(numHyperSamples)));
Prepare the tensor network state sampler#
Now let’s prepare the tensor network state sampler.
216 // Prepare the quantum circuit sampler
217 HANDLE_CUTN_ERROR(cutensornetSamplerPrepare(cutnHandle, sampler, scratchSize, workDesc, 0x0));
218 std::cout << "Prepared the quantum circuit state sampler\n";
Set up the workspace#
Now we can set up the required workspace buffer.
222 // Attach the workspace buffer
223 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
224 workDesc,
225 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
226 CUTENSORNET_MEMSPACE_DEVICE,
227 CUTENSORNET_WORKSPACE_SCRATCH,
228 &worksize));
229 std::cout << "Scratch GPU workspace size (bytes) for MPS Sampling = " << worksize << std::endl;
230 assert(worksize > 0);
231 if(worksize <= scratchSize) {
232 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
233 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
234 }else{
235 std::cout << "ERROR: Insufficient workspace size on Device!\n";
236 std::abort();
237 }
238 std::cout << "Set the workspace buffer\n";
Perform sampling of the final quantum circuit state#
Once everything had been set up, we perform sampling of the quantum circuit state and print the output samples.
242 // Sample the quantum circuit state
243 std::vector<int64_t> samples(numQubits * numSamples); // samples[SampleId][QubitId] reside in Host memory
244 HANDLE_CUTN_ERROR(cutensornetSamplerSample(cutnHandle, sampler, numSamples, workDesc, samples.data(), 0));
245 std::cout << "Performed quantum circuit state sampling\n";
246 std::cout << "Bit-string samples:\n";
247 for(int64_t i = 0; i < numSamples; ++i) {
248 for(int64_t j = 0; j < numQubits; ++j) std::cout << " " << samples[i * numQubits + j];
249 std::cout << std::endl;
250 }
Free resources#
254 // Destroy the workspace descriptor
255 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
256 std::cout << "Destroyed the workspace descriptor\n";
257
258 // Destroy the quantum circuit sampler
259 HANDLE_CUTN_ERROR(cutensornetDestroySampler(sampler));
260 std::cout << "Destroyed the quantum circuit state sampler\n";
261
262 // Destroy the quantum circuit state
263 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
264 std::cout << "Destroyed the quantum circuit state\n";
265
266 // Free GPU buffers
267 for (int32_t i = 0; i < numQubits; i++) {
268 HANDLE_CUDA_ERROR(cudaFree(d_mpsTensors[i]));
269 }
270 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
271 for(auto ptr: d_gateCR) HANDLE_CUDA_ERROR(cudaFree(ptr));
272 HANDLE_CUDA_ERROR(cudaFree(d_gateH));
273 std::cout << "Freed memory on GPU\n";
274
275 // Finalize the cuTensorNet library
276 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
277 std::cout << "Finalized the cuTensorNet library\n";
278
279 return 0;
280}
Code example (Projection MPS Circuit DMRG)#
Projection MPS Circuit DMRG#
The following code example illustrates how to use the state projection MPS API to perform circuit simulation using DMRG optimization, following the method described by [Ayral et al., 2023]. The full code can be found in the NVIDIA/cuQuantum repository (here).
Headers, error handling, and helper functions#
7#include <cstdlib>
8#include <cstdio>
9#include <cassert>
10#include <complex>
11#include <cmath>
12#include <vector>
13#include <limits>
14#include <iostream>
15
16#include <cuda_runtime.h>
17#include <cutensornet.h>
18#include <cublas_v2.h>
19
20#define HANDLE_CUDA_ERROR(x) \
21 { \
22 const auto err = x; \
23 if (err != cudaSuccess) \
24 { \
25 printf("CUDA error %s in line %d\n", cudaGetErrorString(err), __LINE__); \
26 fflush(stdout); \
27 std::abort(); \
28 } \
29 };
30
31#define HANDLE_CUTN_ERROR(x) \
32 { \
33 const auto err = x; \
34 if (err != CUTENSORNET_STATUS_SUCCESS) \
35 { \
36 printf("cuTensorNet error %s in line %d\n", cutensornetGetErrorString(err), __LINE__); \
37 fflush(stdout); \
38 std::abort(); \
39 } \
40 };
41
42#define HANDLE_CUBLAS_ERROR(x) \
43 { \
44 const auto err = x; \
45 if (err != CUBLAS_STATUS_SUCCESS) \
46 { \
47 printf("cuBLAS error (status code %d) in line %d\n", static_cast<int>(err), __LINE__); \
48 fflush(stdout); \
49 std::abort(); \
50 } \
51 };
52
53// Helper function to compute maximum bond extents
54std::vector<int64_t> getMaxBondExtents(const std::vector<int64_t>& stateModeExtents, int64_t maxdim = -1)
55{
56 const int32_t numQubits = stateModeExtents.size();
57 std::vector<int64_t> cumprodLeft(numQubits), cumprodRight(numQubits);
58
59 // Compute cumulative products from left and right
60 cumprodLeft[0] = stateModeExtents[0];
61 for (int32_t i = 1; i < numQubits; ++i)
62 {
63 cumprodLeft[i] = cumprodLeft[i - 1] * stateModeExtents[i];
64 }
65
66 cumprodRight[numQubits - 1] = stateModeExtents[numQubits - 1];
67 for (int32_t i = numQubits - 2; i >= 0; --i)
68 {
69 cumprodRight[i] = cumprodRight[i + 1] * stateModeExtents[i];
70 }
71
72 std::vector<int64_t> maxBondExtents(numQubits - 1);
73 for (int32_t i = 0; i < numQubits - 1; ++i)
74 {
75 int64_t minVal = std::min(cumprodLeft[i], cumprodRight[i + 1]);
76 maxBondExtents[i] = (maxdim > 0) ? std::min(minVal, maxdim) : minVal;
77 }
78
79 return maxBondExtents;
80}
81
82int main()
83{
84 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
85
86 constexpr std::size_t fp64size = sizeof(double);
Define the tensor network state and quantum circuit configuration#
Let’s define a tensor network state corresponding to a 16-qubit QFT quantum circuit.
90 // Quantum state configuration
91 const int32_t numQubits = 16;
92 const std::vector<int64_t> qubitDims(numQubits, 2);
93 std::cout << "DMRG quantum circuit with " << numQubits << " qubits\n";
Initialize the cuTensorNet library handle#
97 // Initialize the cuTensorNet library
98 HANDLE_CUDA_ERROR(cudaSetDevice(0));
99 cutensornetHandle_t cutnHandle;
100 HANDLE_CUTN_ERROR(cutensornetCreate(&cutnHandle));
101 std::cout << "Initialized cuTensorNet library on GPU 0\n";
102
103 cublasHandle_t cublasHandle;
104 HANDLE_CUBLAS_ERROR(cublasCreate(&cublasHandle));
105
Define quantum gates on GPU#
108 // Define necessary quantum gate tensors in Host memory
109 const double invsq2 = 1.0 / std::sqrt(2.0);
110 const double pi = 3.14159265358979323846;
111 using GateData = std::vector<std::complex<double>>;
112
113 // CR(k) gate generator
114 auto cRGate = [&pi](int32_t k)
115 {
116 const double phi = pi / std::pow(2.0, k);
117 const GateData cr{{1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
118 {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
119 {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0},
120 {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {std::cos(phi), std::sin(phi)}};
121 return cr;
122 };
123
124 // Hadamard gate
125 const GateData h_gateH{{invsq2, 0.0}, {invsq2, 0.0}, {invsq2, 0.0}, {-invsq2, 0.0}};
126
127 // CR(k) gates (controlled rotations)
128 std::vector<GateData> h_gateCR(numQubits);
129 for (int32_t k = 0; k < numQubits; ++k)
130 {
131 h_gateCR[k] = cRGate(k + 1);
132 }
133
134 // Copy quantum gates into Device memory
135 void* d_gateH{nullptr};
136 std::vector<void*> d_gateCR(numQubits, nullptr);
137 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateH, 4 * (2 * fp64size)));
138 for (int32_t k = 0; k < numQubits; ++k)
139 {
140 HANDLE_CUDA_ERROR(cudaMalloc(&(d_gateCR[k]), 16 * (2 * fp64size)));
141 }
142
143 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateH, h_gateH.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
144 for (int32_t k = 0; k < numQubits; ++k)
145 {
146 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateCR[k], h_gateCR[k].data(), 16 * (2 * fp64size), cudaMemcpyHostToDevice));
147 }
148 std::cout << "Copied quantum gates into GPU memory\n";
Create initial quantum state and apply gates#
Here we query the available GPU memory and allocate a scratch buffer for computations, followed by creating the pure quantum state and then applying the quantum gates.
152 // Query free memory on Device and allocate a scratch buffer
153 std::size_t freeSize{0}, totalSize{0};
154 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeSize, &totalSize));
155 const std::size_t scratchSize = (freeSize - (freeSize % 4096)) / 2;
156 void* d_scratch{nullptr};
157 HANDLE_CUDA_ERROR(cudaMalloc(&d_scratch, scratchSize));
158 std::cout << "Allocated " << scratchSize << " bytes of scratch memory on GPU\n";
159
160 // Create the initial quantum state
161 cutensornetState_t quantumState;
162 HANDLE_CUTN_ERROR(cutensornetCreateState(cutnHandle, CUTENSORNET_STATE_PURITY_PURE, numQubits, qubitDims.data(),
163 CUDA_C_64F, &quantumState));
164 std::cout << "Created the initial quantum state\n";
165
166 // Construct the quantum circuit state (apply quantum gates)
167 int64_t id;
168 for (int32_t i = 0; i < numQubits; ++i)
169 {
170 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(
171 cutnHandle, quantumState, 1, std::vector<int32_t>{{i}}.data(), d_gateH, nullptr, 1, 0, 1, &id));
172 for (int32_t j = (i + 1); j < numQubits; ++j)
173 {
174 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 2,
175 std::vector<int32_t>{{j, i}}.data(), d_gateCR[j - i],
176 nullptr, 1, 0, 1, &id));
177 }
178 }
179 std::cout << "Applied quantum gates\n";
Set up and specify the MPS representation of the output state#
Now let’s set up the MPS representation of the output state for our 16-qubit quantum circuit.
183 // Define the MPS representation and allocate memory buffers for the MPS tensors
184 const int64_t maxExtent = 8;
185 std::vector<int64_t> dimExtents(numQubits, 2);
186 std::vector<int64_t> maxBondExtents = getMaxBondExtents(dimExtents, maxExtent);
187
188 std::vector<std::vector<int64_t>> projMPSTensorExtents;
189 std::vector<const int64_t*> projMPSTensorExtentsPtr(numQubits);
190 std::vector<void*> d_projMPSTensors(numQubits, nullptr);
191 std::vector<int64_t> numElements(numQubits);
192 std::vector<void*> d_envTensorsExtract(numQubits, nullptr);
193 std::vector<void*> d_envTensorsInsert(numQubits, nullptr);
Initialize the MPS in the vacuum state#
For simplicity and reproducibility, we initialize the MPS as the vacuum state. This includes logic for the bond dimension, as we require the MPS to not have overcomplete bond dimensions.
198 for (int32_t i = 0; i < numQubits; ++i)
199 {
200 if (i == 0)
201 {
202 // left boundary MPS tensor
203 auto extent2 = std::min(maxBondExtents[i], maxExtent);
204 projMPSTensorExtents.push_back({2, extent2});
205 numElements[i] = 2 * extent2;
206 HANDLE_CUDA_ERROR(cudaMalloc(&d_projMPSTensors[i], numElements[i] * (2 * fp64size)));
207 //projMPSTensorStrides.push_back({1, 2});
208 }
209 else if (i == numQubits - 1)
210 {
211 // right boundary MPS tensor
212 auto extent1 = std::min(maxBondExtents[i - 1], maxExtent);
213 projMPSTensorExtents.push_back({extent1, 2});
214 numElements[i] = extent1 * 2;
215 HANDLE_CUDA_ERROR(cudaMalloc(&d_projMPSTensors[i], numElements[i] * (2 * fp64size)));
216 }
217 else
218 {
219 // middle MPS tensors
220 auto extent1 = std::min(maxBondExtents[i - 1], maxExtent);
221 auto extent3 = std::min(maxBondExtents[i], maxExtent);
222 projMPSTensorExtents.push_back({extent1, 2, extent3});
223 numElements[i] = extent1 * 2 * extent3;
224 HANDLE_CUDA_ERROR(cudaMalloc(&d_projMPSTensors[i], numElements[i] * (2 * fp64size)));
225 }
226 projMPSTensorExtentsPtr[i] = projMPSTensorExtents[i].data();
227
228 HANDLE_CUDA_ERROR(cudaMalloc(&d_envTensorsExtract[i], numElements[i] * (2 * fp64size)));
229 HANDLE_CUDA_ERROR(cudaMalloc(&d_envTensorsInsert[i], numElements[i] * (2 * fp64size)));
230 }
231
232 // Initialize the vacuum state
233 for (int32_t i = 0; i < numQubits; ++i)
234 {
235 std::vector<std::complex<double>> hostTensor(numElements[i]);
236 for (int64_t j = 0; j < numElements[i]; ++j)
237 {
238 hostTensor[j] = {0.0, 0.0};
239 }
240 hostTensor[0] = {1.0, 0.0};
241 HANDLE_CUDA_ERROR(
242 cudaMemcpy(d_projMPSTensors[i], hostTensor.data(), numElements[i] * (2 * fp64size), cudaMemcpyHostToDevice));
243 }
244 std::cout << "Allocated GPU memory for projection MPS tensors\n";
Define MPS representation and allocate projection MPS tensors#
Here we set up the MPS representation to be optimized by the projection MPS API and allocate GPU memory for the projection MPS tensors and environment tensors to be used over the course of the DMRG optimization.
248 // Prepare state projection MPS
249 std::vector<cutensornetState_t> states = {quantumState};
250 std::vector<cuDoubleComplex> coefficients = {{1.0, 0.0}};
251
252 // Environment specifications
253 std::vector<cutensornetMPSEnvBounds_t> envSpecs;
254 for (int32_t i = 0; i < numQubits; ++i)
255 {
256 cutensornetMPSEnvBounds_t spec;
257 spec.lowerBound = i - 1;
258 spec.upperBound = i + 1;
259 envSpecs.push_back(spec);
260 }
261
262 cutensornetMPSEnvBounds_t initialOrthoSpec;
263 initialOrthoSpec.lowerBound = -1;
264 initialOrthoSpec.upperBound = numQubits;
Create state projection MPS#
Now we create the cutensornetStateProjectionMPS_t object that will be used for DMRG optimization.
Many MPS optimization algorithms, including circuit DMRG, make use of the gauge degree of freedom of the MPS and enforce
orthogonality conditions on the MPS tensors, such that the optimized tensors constitute coefficients of the quantum state in a orthonormal basis defined by the other MPS tensors.
By default, the cutensornetStateProjectionMPSExtract API enforces these orthogonality conditions by performing orthogonalization of the MPS tensors towards the environment for which the extraction happens.
The following figure illustrates the main idea behind the state projection MPS API for the four-qubit case.
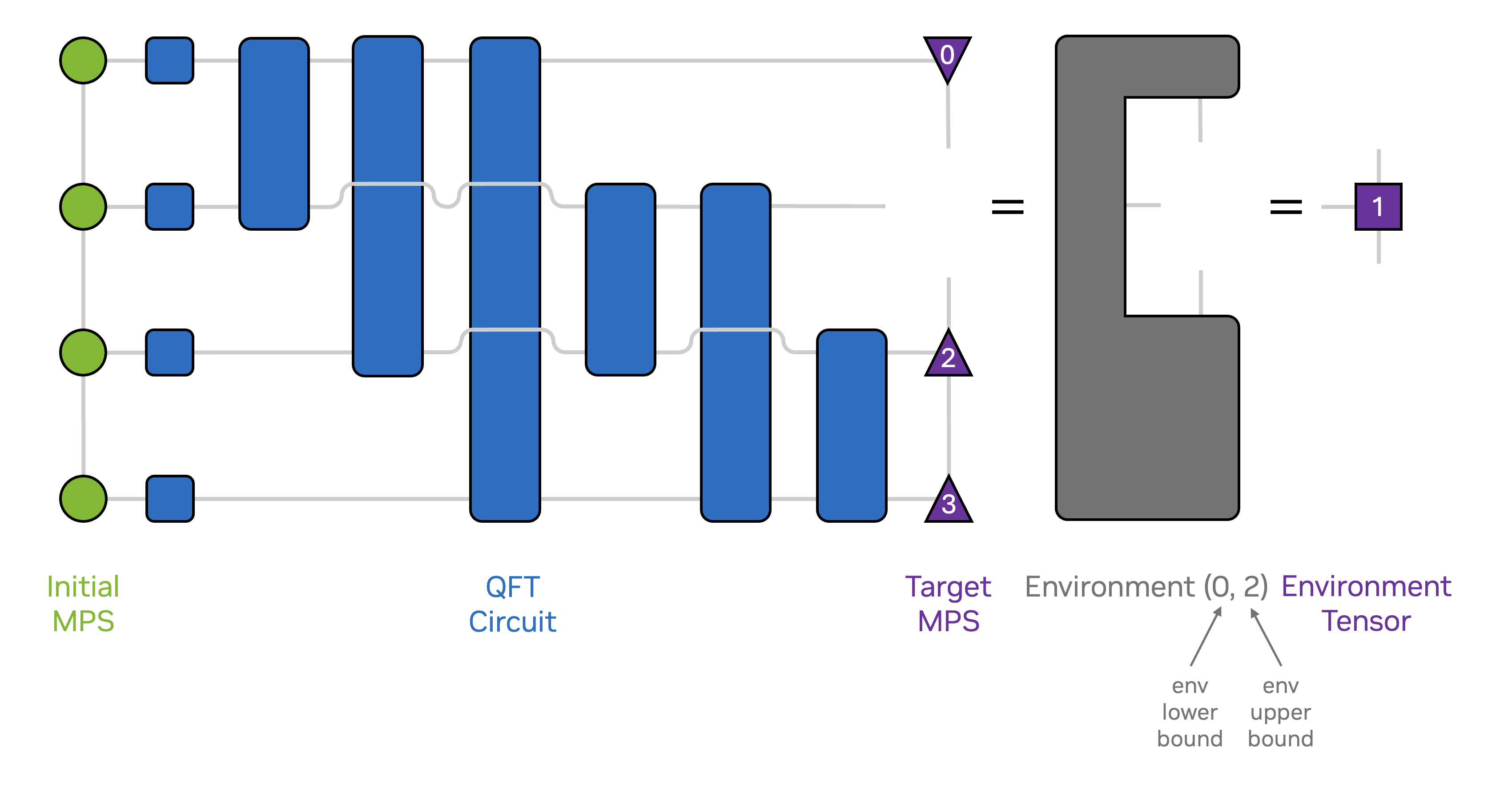
The environment network is the initial MPS (left) contracted with the circuit gates (middle) and the target MPS (right), where the tensor to be variationally optimized is removed from the network. Contracting this network results in a single-site tensor, which we will call the environment tensor. Note that we use the following convention for the indexing of the environment tensors: The single-site environment for tensor \(i\) is specified by the environment specification \((i-1, i+1)\).
268 // Create state projection MPS
269 cutensornetStateProjectionMPS_t projectionMps;
270 HANDLE_CUTN_ERROR(cutensornetCreateStateProjectionMPS(
271 cutnHandle, states.size(), states.data(), coefficients.data(), false, envSpecs.size(), envSpecs.data(),
272 CUTENSORNET_BOUNDARY_CONDITION_OPEN, numQubits, 0, projMPSTensorExtentsPtr.data(), 0,
273 d_projMPSTensors.data(), &initialOrthoSpec, &projectionMps));
274 std::cout << "Created state projection MPS\n";
275
276 // Prepare the state projection MPS computation
277 cutensornetWorkspaceDescriptor_t workDesc;
278 HANDLE_CUTN_ERROR(cutensornetCreateWorkspaceDescriptor(cutnHandle, &workDesc));
279 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSPrepare(cutnHandle, projectionMps, scratchSize, workDesc, 0x0));
280
281 int64_t worksize{0};
282 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle, workDesc, CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
283 CUTENSORNET_MEMSPACE_DEVICE, CUTENSORNET_WORKSPACE_SCRATCH,
284 &worksize));
285 std::cout << "Workspace size for MPS projection = " << worksize << " bytes\n";
286
287 if (worksize <= scratchSize)
288 {
289 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
290 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
291 }
292 else
293 {
294 std::cout << "ERROR: Insufficient workspace size on Device!\n";
295
296 // Cleanup
297 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
298 HANDLE_CUTN_ERROR(cutensornetDestroyStateProjectionMPS(projectionMps));
299 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
300
301 // Free GPU buffers
302 for (int32_t i = 0; i < numQubits; i++)
303 {
304 HANDLE_CUDA_ERROR(cudaFree(d_projMPSTensors[i]));
305 HANDLE_CUDA_ERROR(cudaFree(d_envTensorsExtract[i]));
306 HANDLE_CUDA_ERROR(cudaFree(d_envTensorsInsert[i]));
307 }
308 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
309 for (auto ptr : d_gateCR) HANDLE_CUDA_ERROR(cudaFree(ptr));
310 HANDLE_CUDA_ERROR(cudaFree(d_gateH));
311 std::cout << "Freed memory on GPU\n";
312
313 // Finalize the cuTensorNet library
314 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
315
316 std::abort();
317 }
Perform DMRG optimization#
Once the state projection MPS has been prepared, we perform DMRG optimization through forward and backward sweeps to optimize the MPS representation. For each tensor, we extract the site tensor, compute the corresponding environment tensor, and then insert the resulting tensor back into the MPS.
321 // DMRG iterations
322 const int32_t numIterations = 5;
323 std::cout << "Starting DMRG iterations\n";
324
325 for (int32_t iter = 0; iter < numIterations; ++iter)
326 {
327 std::cout << "DMRG iteration " << iter + 1 << "/" << numIterations << std::endl;
328
329 // Forward sweep
330 for (int32_t i = 0; i < numQubits; ++i)
331 {
332 // Environment bounds for site i
333 cutensornetMPSEnvBounds_t envBounds;
334 envBounds.lowerBound = i - 1;
335 envBounds.upperBound = i + 1;
336
337 // Extract site tensor
338 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSExtractTensor(
339 cutnHandle, projectionMps, &envBounds, nullptr, d_envTensorsExtract[i], workDesc, 0x0));
340
341 // Compute environment tensor
342 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSComputeTensorEnv(cutnHandle, projectionMps, &envBounds, 0, 0,
343 0, d_envTensorsInsert[i], 0,
344 0, workDesc, 0x0));
345
346 // Apply partial-fidelity scaling factor to the environment tensor
347 double f_tau_sqrt;
348 HANDLE_CUBLAS_ERROR(cublasDznrm2(cublasHandle, numElements[i],
349 static_cast<const cuDoubleComplex*>(d_envTensorsInsert[i]), 1,
350 &f_tau_sqrt));
351 HANDLE_CUDA_ERROR(cudaStreamSynchronize(0));
352
353 if (f_tau_sqrt < std::sqrt(std::numeric_limits<double>::epsilon()))
354 {
355 std::cout << "ERROR: Scaling factor is zero!\n";
356 std::abort();
357 }
358 cuDoubleComplex scaling_factor = {1.0 / f_tau_sqrt, 0.0};
359
360 HANDLE_CUBLAS_ERROR(cublasZscal(cublasHandle, numElements[i],
361 &scaling_factor,
362 static_cast<cuDoubleComplex*>(d_envTensorsInsert[i]), 1));
363
364 // Insert updated tensor
365 cutensornetMPSEnvBounds_t orthoSpec = envBounds;
366 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSInsertTensor(cutnHandle, projectionMps, &envBounds,
367 &orthoSpec, 0,
368 d_envTensorsInsert[i], workDesc, 0x0));
369 }
370
371 // Backward sweep
372 for (int32_t i = numQubits - 1; i >= 0; --i)
373 {
374 // Environment bounds for site i
375 cutensornetMPSEnvBounds_t envBounds;
376 envBounds.lowerBound = i - 1;
377 envBounds.upperBound = i + 1;
378
379 // Extract site tensor
380 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSExtractTensor(
381 cutnHandle, projectionMps, &envBounds, 0, d_envTensorsExtract[i], workDesc, 0x0));
382
383 // Compute environment tensor
384 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSComputeTensorEnv(cutnHandle, projectionMps, &envBounds, 0, 0,
385 0, d_envTensorsInsert[i], 0,
386 0, workDesc, 0x0));
387
388 // Apply partial-fidelity scaling factor to the environment tensor
389 double f_tau_sqrt;
390 HANDLE_CUBLAS_ERROR(cublasDznrm2(cublasHandle, numElements[i],
391 static_cast<const cuDoubleComplex*>(d_envTensorsInsert[i]), 1,
392 &f_tau_sqrt));
393 HANDLE_CUDA_ERROR(cudaStreamSynchronize(0));
394
395 if (f_tau_sqrt < std::sqrt(std::numeric_limits<double>::epsilon()))
396 {
397 std::cout << "ERROR: Scaling factor is zero!\n";
398 std::abort();
399 }
400 cuDoubleComplex scaling_factor = {1.0 / f_tau_sqrt, 0.0};
401
402 HANDLE_CUBLAS_ERROR(cublasZscal(cublasHandle, numElements[i],
403 &scaling_factor,
404 static_cast<cuDoubleComplex*>(d_envTensorsInsert[i]), 1));
405
406 // Insert updated tensor
407 cutensornetMPSEnvBounds_t orthoSpec = envBounds;
408 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSInsertTensor(cutnHandle, projectionMps, &envBounds,
409 &orthoSpec, 0,
410 d_envTensorsInsert[i], workDesc, 0x0));
411 }
412
413 std::cout << "Completed DMRG iteration " << iter + 1 << std::endl;
414 }
415
416 std::cout << "DMRG optimization completed\n";
Free resources#
420 // Cleanup
421 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
422 HANDLE_CUTN_ERROR(cutensornetDestroyStateProjectionMPS(projectionMps));
423 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
424
425 // Free GPU buffers
426 for (int32_t i = 0; i < numQubits; i++)
427 {
428 HANDLE_CUDA_ERROR(cudaFree(d_projMPSTensors[i]));
429 HANDLE_CUDA_ERROR(cudaFree(d_envTensorsExtract[i]));
430 HANDLE_CUDA_ERROR(cudaFree(d_envTensorsInsert[i]));
431 }
432 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
433 for (auto ptr : d_gateCR) HANDLE_CUDA_ERROR(cudaFree(ptr));
434 HANDLE_CUDA_ERROR(cudaFree(d_gateH));
435 std::cout << "Freed memory on GPU\n";
436
437 HANDLE_CUBLAS_ERROR(cublasDestroy(cublasHandle));
438
439 // Finalize the cuTensorNet library
440 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
441 std::cout << "Finalized the cuTensorNet library\n";
442
443 return 0;
444}
References#
Ayral, Thomas, Thibaud Louvet, Yiqing Zhou, Cyprien Lambert, E. Miles Stoudenmire, and Xavier Waintal. 2023. “Density-Matrix Renormalization Group Algorithm for Simulating Quantum Circuits with a Finite Fidelity.” PRX Quantum 4 (April): 020304. https://doi.org/10.1103/PRXQuantum.4.020304.
Code example (MPS sampling MPO)#
Sampling the Matrix Product State (circuit with Matrix Product Operators)#
The following code example illustrates how to define a tensor network state by a circuit with Matrix Product Operators (MPO), then compute its Matrix Product State (MPS) factorization, and, finally, sample the MPS-factorized state. The full code can be found in the NVIDIA/cuQuantum repository (here).
Headers and error handling#
7#include <cstdlib>
8#include <cstdio>
9#include <cmath>
10#include <cassert>
11#include <complex>
12#include <random>
13#include <functional>
14#include <vector>
15#include <iostream>
16
17#include <cuda_runtime.h>
18#include <cutensornet.h>
19
20#define HANDLE_CUDA_ERROR(x) \
21{ const auto err = x; \
22 if( err != cudaSuccess ) \
23 { printf("CUDA error %s in line %d\n", cudaGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
24};
25
26#define HANDLE_CUTN_ERROR(x) \
27{ const auto err = x; \
28 if( err != CUTENSORNET_STATUS_SUCCESS ) \
29 { printf("cuTensorNet error %s in line %d\n", cutensornetGetErrorString(err), __LINE__); fflush(stdout); std::abort(); } \
30};
31
32
33int main()
34{
35 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
36
37 constexpr std::size_t fp64size = sizeof(double);
38 constexpr cudaDataType_t dataType = CUDA_C_64F;
Define the tensor network state and the desired number of output samples to generate#
Let’s define all parameters of the tensor network state for a quantum circuit with the given number of qubits and request to produce a given number of output samples for the full qubit register. We also configure the maximal bond dimension for the MPS and MPO tensor network representations used in this example. For the MPO, we also define the number of sites (qubits) it acts on as well as the number of layers of the MPO.
42 // Quantum state configuration
43 const int64_t numSamples = 128; // number of samples to generate
44 const int32_t numQudits = 6; // number of qudits
45 const int64_t quditDim = 2; // dimension of all qudits
46 const std::vector<int64_t> quditDims(numQudits, quditDim); // qudit dimensions
47 const int64_t mpsBondDim = 8; // maximum MPS bond dimension
48 const int64_t mpoBondDim = 2; // maximum MPO bond dimension
49 const int32_t mpoNumLayers = 5; // number of MPO layers
50 constexpr int32_t mpoNumSites = 4; // number of MPO sites
51 std::cout << "Quantum circuit: " << numQudits << " qudits; " << numSamples << " samples\n";
52
53 /* Action of five alternating four-site MPO gates (operators)
54 on the 6-quqit quantum register (illustration):
55
56 Q----X---------X---------X----
57 | | |
58 Q----X---------X---------X----
59 | | |
60 Q----X----X----X----X----X----
61 | | | | |
62 Q----X----X----X----X----X----
63 | |
64 Q---------X---------X---------
65 | |
66 Q---------X---------X---------
67
68 |layer|
69 */
70 static_assert(mpoNumSites > 1, "Number of MPO sites must be larger than one!");
71
72 // Random number generator
73 std::default_random_engine generator;
74 std::uniform_real_distribution<double> distribution(-1.0, 1.0);
75 auto rnd = std::bind(distribution, generator);
Initialize the cuTensorNet library handle#
79 // Initialize the cuTensorNet library
80 HANDLE_CUDA_ERROR(cudaSetDevice(0));
81 cutensornetHandle_t cutnHandle;
82 HANDLE_CUTN_ERROR(cutensornetCreate(&cutnHandle));
83 std::cout << "Initialized cuTensorNet library on GPU 0\n";
Define and allocate MPO tensors#
Here we define the shapes of the MPO tensors, fill them in with random data on Host, and, finally, transfer them into Device memory.
87 /* MPO tensor mode numeration (open boundary condition):
88
89 2 3 2
90 | | |
91 X--1------0--X--2---- ... ----0--X
92 | | |
93 0 1 1
94
95 */
96 // Define shapes of the MPO tensors
97 using GateData = std::vector<std::complex<double>>;
98 using ModeExtents = std::vector<int64_t>;
99 std::vector<GateData> mpoTensors(mpoNumSites); // MPO tensors
100 std::vector<ModeExtents> mpoModeExtents(mpoNumSites); // mode extents for MPO tensors
101 int64_t upperBondDim = 1;
102 for(int tensId = 0; tensId < (mpoNumSites / 2); ++tensId) {
103 const auto leftBondDim = std::min(mpoBondDim, upperBondDim);
104 const auto rightBondDim = std::min(mpoBondDim, leftBondDim * (quditDim * quditDim));
105 if(tensId == 0) {
106 mpoModeExtents[tensId] = {quditDim, rightBondDim, quditDim};
107 }else{
108 mpoModeExtents[tensId] = {leftBondDim, quditDim, rightBondDim, quditDim};
109 }
110 upperBondDim = rightBondDim;
111 }
112 auto centralBondDim = upperBondDim;
113 if(mpoNumSites % 2 != 0) {
114 const int tensId = mpoNumSites / 2;
115 mpoModeExtents[tensId] = {centralBondDim, quditDim, centralBondDim, quditDim};
116 }
117 upperBondDim = 1;
118 for(int tensId = (mpoNumSites-1); tensId >= (mpoNumSites / 2) + (mpoNumSites % 2); --tensId) {
119 const auto rightBondDim = std::min(mpoBondDim, upperBondDim);
120 const auto leftBondDim = std::min(mpoBondDim, rightBondDim * (quditDim * quditDim));
121 if(tensId == (mpoNumSites-1)) {
122 mpoModeExtents[tensId] = {leftBondDim, quditDim, quditDim};
123 }else{
124 mpoModeExtents[tensId] = {leftBondDim, quditDim, rightBondDim, quditDim};
125 }
126 upperBondDim = leftBondDim;
127 }
128 // Fill in the MPO tensors with random data on Host
129 std::vector<const int64_t*> mpoModeExtentsPtr(mpoNumSites, nullptr);
130 for(int tensId = 0; tensId < mpoNumSites; ++tensId) {
131 mpoModeExtentsPtr[tensId] = mpoModeExtents[tensId].data();
132 const auto tensRank = mpoModeExtents[tensId].size();
133 int64_t tensVol = 1;
134 for(int i = 0; i < tensRank; ++i) {
135 tensVol *= mpoModeExtents[tensId][i];
136 }
137 mpoTensors[tensId].resize(tensVol);
138 for(int64_t i = 0; i < tensVol; ++i) {
139 mpoTensors[tensId][i] = std::complex<double>(rnd(), rnd());
140 }
141 }
142 // Allocate and copy MPO tensors into Device memory
143 std::vector<void*> d_mpoTensors(mpoNumSites, nullptr);
144 for(int tensId = 0; tensId < mpoNumSites; ++tensId) {
145 const auto tensRank = mpoModeExtents[tensId].size();
146 int64_t tensVol = 1;
147 for(int i = 0; i < tensRank; ++i) {
148 tensVol *= mpoModeExtents[tensId][i];
149 }
150 HANDLE_CUDA_ERROR(cudaMalloc(&(d_mpoTensors[tensId]),
151 std::size_t(tensVol) * (2 * fp64size)));
152 HANDLE_CUDA_ERROR(cudaMemcpy(d_mpoTensors[tensId], mpoTensors[tensId].data(),
153 std::size_t(tensVol) * (2 * fp64size), cudaMemcpyHostToDevice));
154 }
155 std::cout << "Allocated and defined MPO tensors in GPU memory\n";
Define and allocate MPS tensors#
Here we define the shapes of the MPS tensors and allocate Device memory for their storage.
159 // Define the MPS representation and allocate memory buffers for the MPS tensors
160 std::vector<ModeExtents> mpsModeExtents(numQudits);
161 std::vector<int64_t*> mpsModeExtentsPtr(numQudits, nullptr);
162 std::vector<void*> d_mpsTensors(numQudits, nullptr);
163 upperBondDim = 1;
164 for (int tensId = 0; tensId < (numQudits / 2); ++tensId) {
165 const auto leftBondDim = std::min(mpsBondDim, upperBondDim);
166 const auto rightBondDim = std::min(mpsBondDim, leftBondDim * quditDim);
167 if (tensId == 0) { // left boundary MPS tensor
168 mpsModeExtents[tensId] = {quditDim, rightBondDim};
169 HANDLE_CUDA_ERROR(cudaMalloc(&(d_mpsTensors[tensId]),
170 std::size_t(quditDim * rightBondDim) * (2 * fp64size)));
171 } else { // middle MPS tensors
172 mpsModeExtents[tensId] = {leftBondDim, quditDim, rightBondDim};
173 HANDLE_CUDA_ERROR(cudaMalloc(&(d_mpsTensors[tensId]),
174 std::size_t(leftBondDim * quditDim * rightBondDim) * (2 * fp64size)));
175 }
176 upperBondDim = rightBondDim;
177 mpsModeExtentsPtr[tensId] = mpsModeExtents[tensId].data();
178 }
179 centralBondDim = upperBondDim;
180 if(numQudits % 2 != 0) {
181 const int tensId = numQudits / 2;
182 mpsModeExtents[tensId] = {centralBondDim, quditDim, centralBondDim};
183 mpsModeExtentsPtr[tensId] = mpsModeExtents[tensId].data();
184 }
185 upperBondDim = 1;
186 for (int tensId = (numQudits-1); tensId >= (numQudits / 2) + (numQudits % 2); --tensId) {
187 const auto rightBondDim = std::min(mpsBondDim, upperBondDim);
188 const auto leftBondDim = std::min(mpsBondDim, rightBondDim * quditDim);
189 if (tensId == (numQudits-1)) { // right boundary MPS tensor
190 mpsModeExtents[tensId] = {leftBondDim, quditDim};
191 HANDLE_CUDA_ERROR(cudaMalloc(&(d_mpsTensors[tensId]),
192 std::size_t(leftBondDim * quditDim) * (2 * fp64size)));
193 } else { // middle MPS tensors
194 mpsModeExtents[tensId] = {leftBondDim, quditDim, rightBondDim};
195 HANDLE_CUDA_ERROR(cudaMalloc(&(d_mpsTensors[tensId]),
196 std::size_t(leftBondDim * quditDim * rightBondDim) * (2 * fp64size)));
197 }
198 upperBondDim = leftBondDim;
199 mpsModeExtentsPtr[tensId] = mpsModeExtents[tensId].data();
200 }
201 std::cout << "Allocated MPS tensors in GPU memory\n";
Allocate the scratch buffer on GPU#
205 // Query free memory on Device and allocate a scratch buffer
206 std::size_t freeSize {0}, totalSize {0};
207 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeSize, &totalSize));
208 const std::size_t scratchSize = (freeSize - (freeSize % 4096)) / 2; // use half of available memory with alignment
209 void *d_scratch {nullptr};
210 HANDLE_CUDA_ERROR(cudaMalloc(&d_scratch, scratchSize));
211 std::cout << "Allocated " << scratchSize << " bytes of scratch memory on GPU: "
212 << "[" << d_scratch << ":" << (void*)(((char*)(d_scratch)) + scratchSize) << ")\n";
Create a pure tensor network state#
Now let’s create a pure tensor network state for a quantum circuit with the given number of qubits (vacuum state).
216 // Create the initial quantum state
217 cutensornetState_t quantumState;
218 HANDLE_CUTN_ERROR(cutensornetCreateState(cutnHandle, CUTENSORNET_STATE_PURITY_PURE, numQudits, quditDims.data(),
219 dataType, &quantumState));
220 std::cout << "Created the initial (vacuum) quantum state\n";
Construct necessary MPO tensor network operators#
Let’s construct two MPO tensor network operators acting on different subsets of qubits.
224 // Construct the MPO tensor network operators
225 int64_t componentId;
226 cutensornetNetworkOperator_t tnOperator1;
227 HANDLE_CUTN_ERROR(cutensornetCreateNetworkOperator(cutnHandle, numQudits, quditDims.data(),
228 dataType, &tnOperator1));
229 HANDLE_CUTN_ERROR(cutensornetNetworkOperatorAppendMPO(cutnHandle, tnOperator1, make_cuDoubleComplex(1.0, 0.0),
230 mpoNumSites, std::vector<int32_t>({0,1,2,3}).data(),
231 mpoModeExtentsPtr.data(), /*strides=*/nullptr,
232 std::vector<const void*>(d_mpoTensors.cbegin(), d_mpoTensors.cend()).data(),
233 CUTENSORNET_BOUNDARY_CONDITION_OPEN, &componentId));
234 cutensornetNetworkOperator_t tnOperator2;
235 HANDLE_CUTN_ERROR(cutensornetCreateNetworkOperator(cutnHandle, numQudits, quditDims.data(),
236 dataType, &tnOperator2));
237 HANDLE_CUTN_ERROR(cutensornetNetworkOperatorAppendMPO(cutnHandle, tnOperator2, make_cuDoubleComplex(1.0, 0.0),
238 mpoNumSites, std::vector<int32_t>({2,3,4,5}).data(),
239 mpoModeExtentsPtr.data(), /*strides=*/nullptr,
240 std::vector<const void*>(d_mpoTensors.cbegin(), d_mpoTensors.cend()).data(),
241 CUTENSORNET_BOUNDARY_CONDITION_OPEN, &componentId));
242 std::cout << "Constructed two MPO tensor network operators\n";
Apply MPO tensor network operators to the quantum circuit state#
Let’s construct the target quantum circuit by applying MPO tensor network operators in an alternating fashion.
246 // Apply the MPO tensor network operators to the quantum state
247 for(int layer = 0; layer < mpoNumLayers; ++layer) {
248 int64_t operatorId;
249 if(layer % 2 == 0) {
250 HANDLE_CUTN_ERROR(cutensornetStateApplyNetworkOperator(cutnHandle, quantumState, tnOperator1,
251 1, 0, 0, &operatorId));
252 }else{
253 HANDLE_CUTN_ERROR(cutensornetStateApplyNetworkOperator(cutnHandle, quantumState, tnOperator2,
254 1, 0, 0, &operatorId));
255 }
256 }
257 std::cout << "Applied " << mpoNumLayers << " MPO gates to the quantum state\n";
Request MPS factorization for the final quantum circuit state#
Here we express our intent to factorize the final state of the quantum circuit using MPS factorization. The provided shapes (mode extents) of the MPS tensors represent maximum size limits during renormalization. Computed mode extents for the final MPS tensors are less than or equal to these limits. Note: that no computation is done here yet.
261 // Specify the target MPS representation (use default strides)
262 HANDLE_CUTN_ERROR(cutensornetStateFinalizeMPS(cutnHandle, quantumState,
263 CUTENSORNET_BOUNDARY_CONDITION_OPEN, mpsModeExtentsPtr.data(), /*strides=*/nullptr ));
264 std::cout << "Finalized the form of the desired MPS representation\n";
Configure MPS factorization procedure#
After expressing our intent to perform MPS factorization of the final quantum circuit state, we can also configure the MPS factorization +procedure by setting different options, for example, the SVD algorithm.
268 // Set up the SVD method for bonds truncation (optional)
269 cutensornetTensorSVDAlgo_t algo = CUTENSORNET_TENSOR_SVD_ALGO_GESVDJ;
270 HANDLE_CUTN_ERROR(cutensornetStateConfigure(cutnHandle, quantumState,
271 CUTENSORNET_STATE_MPS_SVD_CONFIG_ALGO, &algo, sizeof(algo)));
272 cutensornetStateMPOApplication_t mpsApplication = CUTENSORNET_STATE_MPO_APPLICATION_EXACT;
273 // Use exact MPS-MPO application as extent of 8 can faithfully represent a 6 qubit state (optional)
274 HANDLE_CUTN_ERROR(cutensornetStateConfigure(cutnHandle, quantumState,
275 CUTENSORNET_STATE_CONFIG_MPS_MPO_APPLICATION, &mpsApplication, sizeof(mpsApplication)));
276 std::cout << "Configured the MPS computation\n";
Prepare the computation of MPS factorization#
Let’s create a workspace descriptor and prepare the computation of the MPS factorization of the final quantum circuit state.
280 // Prepare the MPS computation and attach a workspace buffer
281 cutensornetWorkspaceDescriptor_t workDesc;
282 HANDLE_CUTN_ERROR(cutensornetCreateWorkspaceDescriptor(cutnHandle, &workDesc));
283 std::cout << "Created the workspace descriptor\n";
284 HANDLE_CUTN_ERROR(cutensornetStatePrepare(cutnHandle, quantumState, scratchSize, workDesc, 0x0));
285 int64_t worksize {0};
286 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
287 workDesc,
288 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
289 CUTENSORNET_MEMSPACE_DEVICE,
290 CUTENSORNET_WORKSPACE_SCRATCH,
291 &worksize));
292 std::cout << "Scratch GPU workspace size (bytes) for the MPS computation = " << worksize << std::endl;
293 if(worksize <= scratchSize) {
294 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
295 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
296 }else{
297 std::cout << "ERROR: Insufficient workspace size on Device!\n";
298 std::abort();
299 }
300 std::cout << "Set the workspace buffer and prepared the MPS computation\n";
Compute MPS factorization#
Once the MPS factorization procedure has been configured and prepared, let’s compute the MPS factorization of the final quantum circuit state.
304 // Compute the MPS factorization of the quantum circuit state
305 HANDLE_CUTN_ERROR(cutensornetStateCompute(cutnHandle, quantumState,
306 workDesc, mpsModeExtentsPtr.data(), /*strides=*/nullptr, d_mpsTensors.data(), 0));
307 std::cout << "Computed the MPS factorization of the quantum circuit state\n";
308
Create the tensor network state sampler#
Once the quantum circuit state has been constructed and factorized using the MPS representation, let’s create the tensor network state sampler for all qubits.
311 // Create the quantum circuit sampler
312 cutensornetStateSampler_t sampler;
313 HANDLE_CUTN_ERROR(cutensornetCreateSampler(cutnHandle, quantumState, numQudits, nullptr, &sampler));
314 std::cout << "Created the quantum circuit sampler\n";
Configure the tensor network state sampler#
Optionally, we can configure the tensor network state sampler by setting the number of hyper-samples to be used by the tensor network contraction path finder.
318 // Configure the quantum circuit sampler
319 const int32_t numHyperSamples = 8; // desired number of hyper samples used in the tensor network contraction path finder
320 HANDLE_CUTN_ERROR(cutensornetSamplerConfigure(cutnHandle, sampler,
321 CUTENSORNET_SAMPLER_OPT_NUM_HYPER_SAMPLES, &numHyperSamples, sizeof(numHyperSamples)));
Prepare the tensor network state sampler#
Now let’s prepare the tensor network state sampler.
325 // Prepare the quantum circuit sampler
326 HANDLE_CUTN_ERROR(cutensornetSamplerPrepare(cutnHandle, sampler, scratchSize, workDesc, 0x0));
327 std::cout << "Prepared the quantum circuit state sampler\n";
Set up the workspace#
Now we can set up the required workspace buffer.
331 // Attach the workspace buffer
332 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle,
333 workDesc,
334 CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
335 CUTENSORNET_MEMSPACE_DEVICE,
336 CUTENSORNET_WORKSPACE_SCRATCH,
337 &worksize));
338 std::cout << "Scratch GPU workspace size (bytes) for MPS Sampling = " << worksize << std::endl;
339 assert(worksize > 0);
340 if(worksize <= scratchSize) {
341 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
342 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
343 }else{
344 std::cout << "ERROR: Insufficient workspace size on Device!\n";
345 std::abort();
346 }
347 std::cout << "Set the workspace buffer\n";
Perform sampling of the final quantum circuit state#
Once everything had been set up, we perform sampling of the final MPS-factorized quantum circuit state and print the output samples.
351 // Sample the quantum circuit state
352 std::vector<int64_t> samples(numQudits * numSamples); // samples[SampleId][QuditId] reside in Host memory
353 HANDLE_CUTN_ERROR(cutensornetSamplerSample(cutnHandle, sampler, numSamples, workDesc, samples.data(), 0));
354 std::cout << "Performed quantum circuit state sampling\n";
355 std::cout << "Generated samples:\n";
356 for(int64_t i = 0; i < numSamples; ++i) {
357 for(int64_t j = 0; j < numQudits; ++j) std::cout << " " << samples[i * numQudits + j];
358 std::cout << std::endl;
359 }
Free resources#
363 // Destroy the quantum circuit sampler
364 HANDLE_CUTN_ERROR(cutensornetDestroySampler(sampler));
365 std::cout << "Destroyed the quantum circuit state sampler\n";
366
367 // Destroy the workspace descriptor
368 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
369 std::cout << "Destroyed the workspace descriptor\n";
370
371 // Destroy the MPO tensor network operators
372 HANDLE_CUTN_ERROR(cutensornetDestroyNetworkOperator(tnOperator2));
373 HANDLE_CUTN_ERROR(cutensornetDestroyNetworkOperator(tnOperator1));
374 std::cout << "Destroyed the MPO tensor network operators\n";
375
376 // Destroy the quantum circuit state
377 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
378 std::cout << "Destroyed the quantum circuit state\n";
379
380 // Free GPU buffers
381 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
382 for (int32_t i = 0; i < numQudits; ++i) {
383 HANDLE_CUDA_ERROR(cudaFree(d_mpsTensors[i]));
384 }
385 for (int32_t i = 0; i < mpoNumSites; ++i) {
386 HANDLE_CUDA_ERROR(cudaFree(d_mpoTensors[i]));
387 }
388 std::cout << "Freed memory on GPU\n";
389
390 // Finalize the cuTensorNet library
391 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
392 std::cout << "Finalized the cuTensorNet library\n";
393
394 return 0;
395}
Useful tips#
For debugging, one can set the environment variable
CUTENSORNET_LOG_LEVEL=n. The leveln= 0, 1, …, 5 corresponds to the logger level as described and used incutensornetLoggerSetLevel(). The environment variableCUTENSORNET_LOG_FILE=<filepath>can be used to redirect the log output to a custom file at<filepath>instead ofstdout.