Projection MPS Circuit DMRG#
The following code example illustrates how to use the state projection MPS API to perform circuit simulation using DMRG optimization, following the method described by [Ayral et al., 2023]. The full code can be found in the NVIDIA/cuQuantum repository (here).
Headers, error handling, and helper functions#
7#include <cstdlib>
8#include <cstdio>
9#include <cassert>
10#include <complex>
11#include <cmath>
12#include <vector>
13#include <limits>
14#include <iostream>
15
16#include <cuda_runtime.h>
17#include <cutensornet.h>
18#include <cublas_v2.h>
19
20#define HANDLE_CUDA_ERROR(x) \
21 { \
22 const auto err = x; \
23 if (err != cudaSuccess) \
24 { \
25 printf("CUDA error %s in line %d\n", cudaGetErrorString(err), __LINE__); \
26 fflush(stdout); \
27 std::abort(); \
28 } \
29 };
30
31#define HANDLE_CUTN_ERROR(x) \
32 { \
33 const auto err = x; \
34 if (err != CUTENSORNET_STATUS_SUCCESS) \
35 { \
36 printf("cuTensorNet error %s in line %d\n", cutensornetGetErrorString(err), __LINE__); \
37 fflush(stdout); \
38 std::abort(); \
39 } \
40 };
41
42#define HANDLE_CUBLAS_ERROR(x) \
43 { \
44 const auto err = x; \
45 if (err != CUBLAS_STATUS_SUCCESS) \
46 { \
47 printf("cuBLAS error (status code %d) in line %d\n", static_cast<int>(err), __LINE__); \
48 fflush(stdout); \
49 std::abort(); \
50 } \
51 };
52
53// Helper function to compute maximum bond extents
54std::vector<int64_t> getMaxBondExtents(const std::vector<int64_t>& stateModeExtents, int64_t maxdim = -1)
55{
56 const int32_t numQubits = stateModeExtents.size();
57 std::vector<int64_t> cumprodLeft(numQubits), cumprodRight(numQubits);
58
59 // Compute cumulative products from left and right
60 cumprodLeft[0] = stateModeExtents[0];
61 for (int32_t i = 1; i < numQubits; ++i)
62 {
63 cumprodLeft[i] = cumprodLeft[i - 1] * stateModeExtents[i];
64 }
65
66 cumprodRight[numQubits - 1] = stateModeExtents[numQubits - 1];
67 for (int32_t i = numQubits - 2; i >= 0; --i)
68 {
69 cumprodRight[i] = cumprodRight[i + 1] * stateModeExtents[i];
70 }
71
72 std::vector<int64_t> maxBondExtents(numQubits - 1);
73 for (int32_t i = 0; i < numQubits - 1; ++i)
74 {
75 int64_t minVal = std::min(cumprodLeft[i], cumprodRight[i + 1]);
76 maxBondExtents[i] = (maxdim > 0) ? std::min(minVal, maxdim) : minVal;
77 }
78
79 return maxBondExtents;
80}
81
82int main()
83{
84 static_assert(sizeof(size_t) == sizeof(int64_t), "Please build this sample on a 64-bit architecture!");
85
86 constexpr std::size_t fp64size = sizeof(double);
Define the tensor network state and quantum circuit configuration#
Let’s define a tensor network state corresponding to a 16-qubit QFT quantum circuit.
90 // Quantum state configuration
91 const int32_t numQubits = 16;
92 const std::vector<int64_t> qubitDims(numQubits, 2);
93 std::cout << "DMRG quantum circuit with " << numQubits << " qubits\n";
Initialize the cuTensorNet library handle#
97 // Initialize the cuTensorNet library
98 HANDLE_CUDA_ERROR(cudaSetDevice(0));
99 cutensornetHandle_t cutnHandle;
100 HANDLE_CUTN_ERROR(cutensornetCreate(&cutnHandle));
101 std::cout << "Initialized cuTensorNet library on GPU 0\n";
102
103 cublasHandle_t cublasHandle;
104 HANDLE_CUBLAS_ERROR(cublasCreate(&cublasHandle));
105
Define quantum gates on GPU#
108 // Define necessary quantum gate tensors in Host memory
109 const double invsq2 = 1.0 / std::sqrt(2.0);
110 const double pi = 3.14159265358979323846;
111 using GateData = std::vector<std::complex<double>>;
112
113 // CR(k) gate generator
114 auto cRGate = [&pi](int32_t k)
115 {
116 const double phi = pi / std::pow(2.0, k);
117 const GateData cr{{1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
118 {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0}, {0.0, 0.0},
119 {0.0, 0.0}, {0.0, 0.0}, {1.0, 0.0}, {0.0, 0.0},
120 {0.0, 0.0}, {0.0, 0.0}, {0.0, 0.0}, {std::cos(phi), std::sin(phi)}};
121 return cr;
122 };
123
124 // Hadamard gate
125 const GateData h_gateH{{invsq2, 0.0}, {invsq2, 0.0}, {invsq2, 0.0}, {-invsq2, 0.0}};
126
127 // CR(k) gates (controlled rotations)
128 std::vector<GateData> h_gateCR(numQubits);
129 for (int32_t k = 0; k < numQubits; ++k)
130 {
131 h_gateCR[k] = cRGate(k + 1);
132 }
133
134 // Copy quantum gates into Device memory
135 void* d_gateH{nullptr};
136 std::vector<void*> d_gateCR(numQubits, nullptr);
137 HANDLE_CUDA_ERROR(cudaMalloc(&d_gateH, 4 * (2 * fp64size)));
138 for (int32_t k = 0; k < numQubits; ++k)
139 {
140 HANDLE_CUDA_ERROR(cudaMalloc(&(d_gateCR[k]), 16 * (2 * fp64size)));
141 }
142
143 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateH, h_gateH.data(), 4 * (2 * fp64size), cudaMemcpyHostToDevice));
144 for (int32_t k = 0; k < numQubits; ++k)
145 {
146 HANDLE_CUDA_ERROR(cudaMemcpy(d_gateCR[k], h_gateCR[k].data(), 16 * (2 * fp64size), cudaMemcpyHostToDevice));
147 }
148 std::cout << "Copied quantum gates into GPU memory\n";
Create initial quantum state and apply gates#
Here we query the available GPU memory and allocate a scratch buffer for computations, followed by creating the pure quantum state and then applying the quantum gates.
152 // Query free memory on Device and allocate a scratch buffer
153 std::size_t freeSize{0}, totalSize{0};
154 HANDLE_CUDA_ERROR(cudaMemGetInfo(&freeSize, &totalSize));
155 const std::size_t scratchSize = (freeSize - (freeSize % 4096)) / 2;
156 void* d_scratch{nullptr};
157 HANDLE_CUDA_ERROR(cudaMalloc(&d_scratch, scratchSize));
158 std::cout << "Allocated " << scratchSize << " bytes of scratch memory on GPU\n";
159
160 // Create the initial quantum state
161 cutensornetState_t quantumState;
162 HANDLE_CUTN_ERROR(cutensornetCreateState(cutnHandle, CUTENSORNET_STATE_PURITY_PURE, numQubits, qubitDims.data(),
163 CUDA_C_64F, &quantumState));
164 std::cout << "Created the initial quantum state\n";
165
166 // Construct the quantum circuit state (apply quantum gates)
167 int64_t id;
168 for (int32_t i = 0; i < numQubits; ++i)
169 {
170 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(
171 cutnHandle, quantumState, 1, std::vector<int32_t>{{i}}.data(), d_gateH, nullptr, 1, 0, 1, &id));
172 for (int32_t j = (i + 1); j < numQubits; ++j)
173 {
174 HANDLE_CUTN_ERROR(cutensornetStateApplyTensorOperator(cutnHandle, quantumState, 2,
175 std::vector<int32_t>{{j, i}}.data(), d_gateCR[j - i],
176 nullptr, 1, 0, 1, &id));
177 }
178 }
179 std::cout << "Applied quantum gates\n";
Set up and specify the MPS representation of the output state#
Now let’s set up the MPS representation of the output state for our 16-qubit quantum circuit.
183 // Define the MPS representation and allocate memory buffers for the MPS tensors
184 const int64_t maxExtent = 8;
185 std::vector<int64_t> dimExtents(numQubits, 2);
186 std::vector<int64_t> maxBondExtents = getMaxBondExtents(dimExtents, maxExtent);
187
188 std::vector<std::vector<int64_t>> projMPSTensorExtents;
189 std::vector<const int64_t*> projMPSTensorExtentsPtr(numQubits);
190 std::vector<void*> d_projMPSTensors(numQubits, nullptr);
191 std::vector<int64_t> numElements(numQubits);
192 std::vector<void*> d_envTensorsExtract(numQubits, nullptr);
193 std::vector<void*> d_envTensorsInsert(numQubits, nullptr);
Initialize the MPS in the vacuum state#
For simplicity and reproducibility, we initialize the MPS as the vacuum state. This includes logic for the bond dimension, as we require the MPS to not have overcomplete bond dimensions.
198 for (int32_t i = 0; i < numQubits; ++i)
199 {
200 if (i == 0)
201 {
202 // left boundary MPS tensor
203 auto extent2 = std::min(maxBondExtents[i], maxExtent);
204 projMPSTensorExtents.push_back({2, extent2});
205 numElements[i] = 2 * extent2;
206 HANDLE_CUDA_ERROR(cudaMalloc(&d_projMPSTensors[i], numElements[i] * (2 * fp64size)));
207 //projMPSTensorStrides.push_back({1, 2});
208 }
209 else if (i == numQubits - 1)
210 {
211 // right boundary MPS tensor
212 auto extent1 = std::min(maxBondExtents[i - 1], maxExtent);
213 projMPSTensorExtents.push_back({extent1, 2});
214 numElements[i] = extent1 * 2;
215 HANDLE_CUDA_ERROR(cudaMalloc(&d_projMPSTensors[i], numElements[i] * (2 * fp64size)));
216 }
217 else
218 {
219 // middle MPS tensors
220 auto extent1 = std::min(maxBondExtents[i - 1], maxExtent);
221 auto extent3 = std::min(maxBondExtents[i], maxExtent);
222 projMPSTensorExtents.push_back({extent1, 2, extent3});
223 numElements[i] = extent1 * 2 * extent3;
224 HANDLE_CUDA_ERROR(cudaMalloc(&d_projMPSTensors[i], numElements[i] * (2 * fp64size)));
225 }
226 projMPSTensorExtentsPtr[i] = projMPSTensorExtents[i].data();
227
228 HANDLE_CUDA_ERROR(cudaMalloc(&d_envTensorsExtract[i], numElements[i] * (2 * fp64size)));
229 HANDLE_CUDA_ERROR(cudaMalloc(&d_envTensorsInsert[i], numElements[i] * (2 * fp64size)));
230 }
231
232 // Initialize the vacuum state
233 for (int32_t i = 0; i < numQubits; ++i)
234 {
235 std::vector<std::complex<double>> hostTensor(numElements[i]);
236 for (int64_t j = 0; j < numElements[i]; ++j)
237 {
238 hostTensor[j] = {0.0, 0.0};
239 }
240 hostTensor[0] = {1.0, 0.0};
241 HANDLE_CUDA_ERROR(
242 cudaMemcpy(d_projMPSTensors[i], hostTensor.data(), numElements[i] * (2 * fp64size), cudaMemcpyHostToDevice));
243 }
244 std::cout << "Allocated GPU memory for projection MPS tensors\n";
Define MPS representation and allocate projection MPS tensors#
Here we set up the MPS representation to be optimized by the projection MPS API and allocate GPU memory for the projection MPS tensors and environment tensors to be used over the course of the DMRG optimization.
248 // Prepare state projection MPS
249 std::vector<cutensornetState_t> states = {quantumState};
250 std::vector<cuDoubleComplex> coefficients = {{1.0, 0.0}};
251
252 // Environment specifications
253 std::vector<cutensornetMPSEnvBounds_t> envSpecs;
254 for (int32_t i = 0; i < numQubits; ++i)
255 {
256 cutensornetMPSEnvBounds_t spec;
257 spec.lowerBound = i - 1;
258 spec.upperBound = i + 1;
259 envSpecs.push_back(spec);
260 }
261
262 cutensornetMPSEnvBounds_t initialOrthoSpec;
263 initialOrthoSpec.lowerBound = -1;
264 initialOrthoSpec.upperBound = numQubits;
Create state projection MPS#
Now we create the cutensornetStateProjectionMPS_t object that will be used for DMRG optimization.
Many MPS optimization algorithms, including circuit DMRG, make use of the gauge degree of freedom of the MPS and enforce
orthogonality conditions on the MPS tensors, such that the optimized tensors constitute coefficients of the quantum state in a orthonormal basis defined by the other MPS tensors.
By default, the cutensornetStateProjectionMPSExtract API enforces these orthogonality conditions by performing orthogonalization of the MPS tensors towards the environment for which the extraction happens.
The following figure illustrates the main idea behind the state projection MPS API for the four-qubit case.
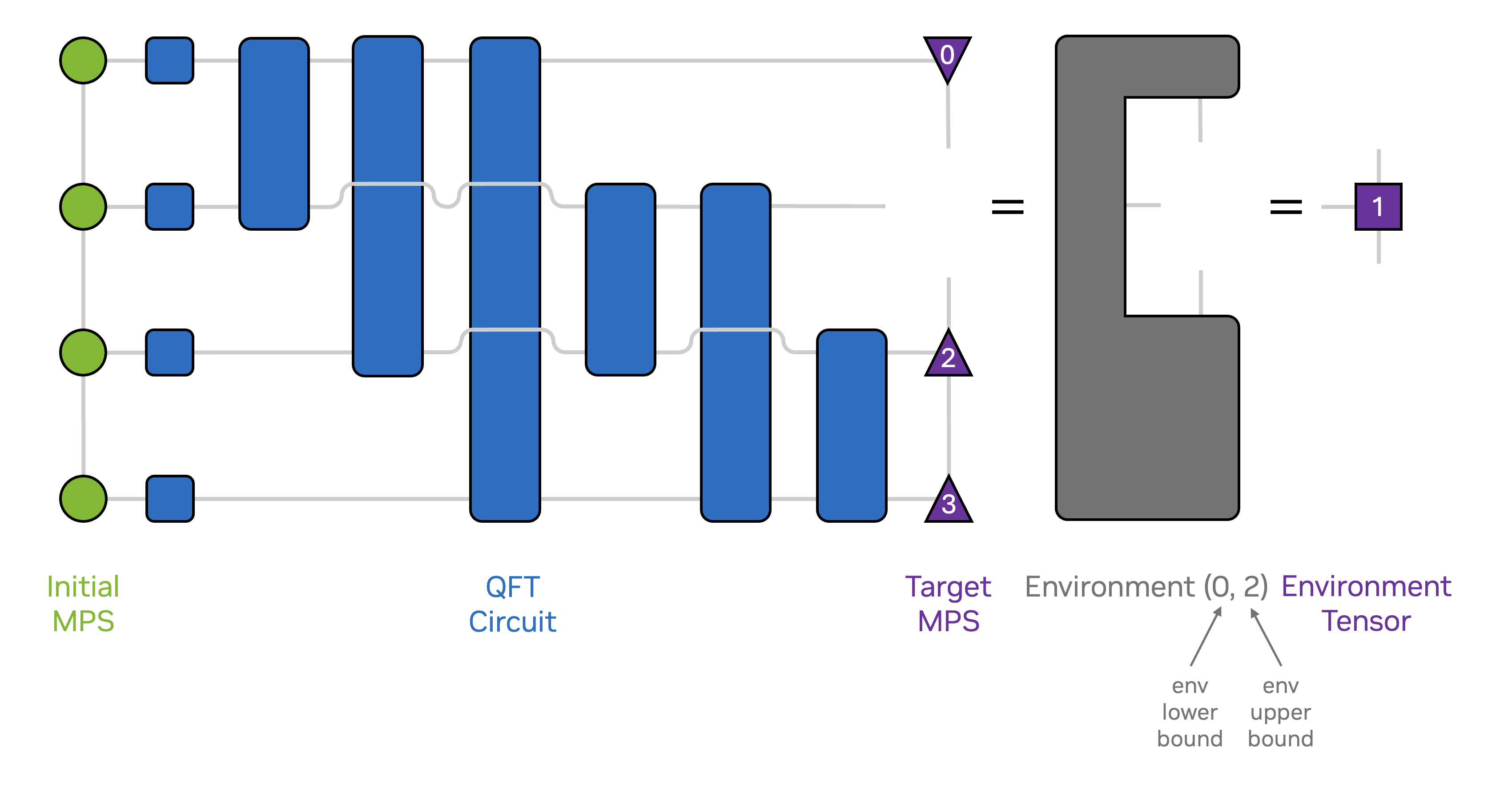
The environment network is the initial MPS (left) contracted with the circuit gates (middle) and the target MPS (right), where the tensor to be variationally optimized is removed from the network. Contracting this network results in a single-site tensor, which we will call the environment tensor. Note that we use the following convention for the indexing of the environment tensors: The single-site environment for tensor \(i\) is specified by the environment specification \((i-1, i+1)\).
268 // Create state projection MPS
269 cutensornetStateProjectionMPS_t projectionMps;
270 HANDLE_CUTN_ERROR(cutensornetCreateStateProjectionMPS(
271 cutnHandle, states.size(), states.data(), coefficients.data(), false, envSpecs.size(), envSpecs.data(),
272 CUTENSORNET_BOUNDARY_CONDITION_OPEN, numQubits, 0, projMPSTensorExtentsPtr.data(), 0,
273 d_projMPSTensors.data(), &initialOrthoSpec, &projectionMps));
274 std::cout << "Created state projection MPS\n";
275
276 // Prepare the state projection MPS computation
277 cutensornetWorkspaceDescriptor_t workDesc;
278 HANDLE_CUTN_ERROR(cutensornetCreateWorkspaceDescriptor(cutnHandle, &workDesc));
279 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSPrepare(cutnHandle, projectionMps, scratchSize, workDesc, 0x0));
280
281 int64_t worksize{0};
282 HANDLE_CUTN_ERROR(cutensornetWorkspaceGetMemorySize(cutnHandle, workDesc, CUTENSORNET_WORKSIZE_PREF_RECOMMENDED,
283 CUTENSORNET_MEMSPACE_DEVICE, CUTENSORNET_WORKSPACE_SCRATCH,
284 &worksize));
285 std::cout << "Workspace size for MPS projection = " << worksize << " bytes\n";
286
287 if (worksize <= scratchSize)
288 {
289 HANDLE_CUTN_ERROR(cutensornetWorkspaceSetMemory(cutnHandle, workDesc, CUTENSORNET_MEMSPACE_DEVICE,
290 CUTENSORNET_WORKSPACE_SCRATCH, d_scratch, worksize));
291 }
292 else
293 {
294 std::cout << "ERROR: Insufficient workspace size on Device!\n";
295
296 // Cleanup
297 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
298 HANDLE_CUTN_ERROR(cutensornetDestroyStateProjectionMPS(projectionMps));
299 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
300
301 // Free GPU buffers
302 for (int32_t i = 0; i < numQubits; i++)
303 {
304 HANDLE_CUDA_ERROR(cudaFree(d_projMPSTensors[i]));
305 HANDLE_CUDA_ERROR(cudaFree(d_envTensorsExtract[i]));
306 HANDLE_CUDA_ERROR(cudaFree(d_envTensorsInsert[i]));
307 }
308 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
309 for (auto ptr : d_gateCR) HANDLE_CUDA_ERROR(cudaFree(ptr));
310 HANDLE_CUDA_ERROR(cudaFree(d_gateH));
311 std::cout << "Freed memory on GPU\n";
312
313 // Finalize the cuTensorNet library
314 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
315
316 std::abort();
317 }
Perform DMRG optimization#
Once the state projection MPS has been prepared, we perform DMRG optimization through forward and backward sweeps to optimize the MPS representation. For each tensor, we extract the site tensor, compute the corresponding environment tensor, and then insert the resulting tensor back into the MPS.
321 // DMRG iterations
322 const int32_t numIterations = 5;
323 std::cout << "Starting DMRG iterations\n";
324
325 for (int32_t iter = 0; iter < numIterations; ++iter)
326 {
327 std::cout << "DMRG iteration " << iter + 1 << "/" << numIterations << std::endl;
328
329 // Forward sweep
330 for (int32_t i = 0; i < numQubits; ++i)
331 {
332 // Environment bounds for site i
333 cutensornetMPSEnvBounds_t envBounds;
334 envBounds.lowerBound = i - 1;
335 envBounds.upperBound = i + 1;
336
337 // Extract site tensor
338 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSExtractTensor(
339 cutnHandle, projectionMps, &envBounds, nullptr, d_envTensorsExtract[i], workDesc, 0x0));
340
341 // Compute environment tensor
342 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSComputeTensorEnv(cutnHandle, projectionMps, &envBounds, 0, 0,
343 0, d_envTensorsInsert[i], 0,
344 0, workDesc, 0x0));
345
346 // Apply partial-fidelity scaling factor to the environment tensor
347 double f_tau_sqrt;
348 HANDLE_CUBLAS_ERROR(cublasDznrm2(cublasHandle, numElements[i],
349 static_cast<const cuDoubleComplex*>(d_envTensorsInsert[i]), 1,
350 &f_tau_sqrt));
351 HANDLE_CUDA_ERROR(cudaStreamSynchronize(0));
352
353 if (f_tau_sqrt < std::sqrt(std::numeric_limits<double>::epsilon()))
354 {
355 std::cout << "ERROR: Scaling factor is zero!\n";
356 std::abort();
357 }
358 cuDoubleComplex scaling_factor = {1.0 / f_tau_sqrt, 0.0};
359
360 HANDLE_CUBLAS_ERROR(cublasZscal(cublasHandle, numElements[i],
361 &scaling_factor,
362 static_cast<cuDoubleComplex*>(d_envTensorsInsert[i]), 1));
363
364 // Insert updated tensor
365 cutensornetMPSEnvBounds_t orthoSpec = envBounds;
366 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSInsertTensor(cutnHandle, projectionMps, &envBounds,
367 &orthoSpec, 0,
368 d_envTensorsInsert[i], workDesc, 0x0));
369 }
370
371 // Backward sweep
372 for (int32_t i = numQubits - 1; i >= 0; --i)
373 {
374 // Environment bounds for site i
375 cutensornetMPSEnvBounds_t envBounds;
376 envBounds.lowerBound = i - 1;
377 envBounds.upperBound = i + 1;
378
379 // Extract site tensor
380 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSExtractTensor(
381 cutnHandle, projectionMps, &envBounds, 0, d_envTensorsExtract[i], workDesc, 0x0));
382
383 // Compute environment tensor
384 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSComputeTensorEnv(cutnHandle, projectionMps, &envBounds, 0, 0,
385 0, d_envTensorsInsert[i], 0,
386 0, workDesc, 0x0));
387
388 // Apply partial-fidelity scaling factor to the environment tensor
389 double f_tau_sqrt;
390 HANDLE_CUBLAS_ERROR(cublasDznrm2(cublasHandle, numElements[i],
391 static_cast<const cuDoubleComplex*>(d_envTensorsInsert[i]), 1,
392 &f_tau_sqrt));
393 HANDLE_CUDA_ERROR(cudaStreamSynchronize(0));
394
395 if (f_tau_sqrt < std::sqrt(std::numeric_limits<double>::epsilon()))
396 {
397 std::cout << "ERROR: Scaling factor is zero!\n";
398 std::abort();
399 }
400 cuDoubleComplex scaling_factor = {1.0 / f_tau_sqrt, 0.0};
401
402 HANDLE_CUBLAS_ERROR(cublasZscal(cublasHandle, numElements[i],
403 &scaling_factor,
404 static_cast<cuDoubleComplex*>(d_envTensorsInsert[i]), 1));
405
406 // Insert updated tensor
407 cutensornetMPSEnvBounds_t orthoSpec = envBounds;
408 HANDLE_CUTN_ERROR(cutensornetStateProjectionMPSInsertTensor(cutnHandle, projectionMps, &envBounds,
409 &orthoSpec, 0,
410 d_envTensorsInsert[i], workDesc, 0x0));
411 }
412
413 std::cout << "Completed DMRG iteration " << iter + 1 << std::endl;
414 }
415
416 std::cout << "DMRG optimization completed\n";
Free resources#
420 // Cleanup
421 HANDLE_CUTN_ERROR(cutensornetDestroyWorkspaceDescriptor(workDesc));
422 HANDLE_CUTN_ERROR(cutensornetDestroyStateProjectionMPS(projectionMps));
423 HANDLE_CUTN_ERROR(cutensornetDestroyState(quantumState));
424
425 // Free GPU buffers
426 for (int32_t i = 0; i < numQubits; i++)
427 {
428 HANDLE_CUDA_ERROR(cudaFree(d_projMPSTensors[i]));
429 HANDLE_CUDA_ERROR(cudaFree(d_envTensorsExtract[i]));
430 HANDLE_CUDA_ERROR(cudaFree(d_envTensorsInsert[i]));
431 }
432 HANDLE_CUDA_ERROR(cudaFree(d_scratch));
433 for (auto ptr : d_gateCR) HANDLE_CUDA_ERROR(cudaFree(ptr));
434 HANDLE_CUDA_ERROR(cudaFree(d_gateH));
435 std::cout << "Freed memory on GPU\n";
436
437 HANDLE_CUBLAS_ERROR(cublasDestroy(cublasHandle));
438
439 // Finalize the cuTensorNet library
440 HANDLE_CUTN_ERROR(cutensornetDestroy(cutnHandle));
441 std::cout << "Finalized the cuTensorNet library\n";
442
443 return 0;
444}
References#
Ayral, Thomas, Thibaud Louvet, Yiqing Zhou, Cyprien Lambert, E. Miles Stoudenmire, and Xavier Waintal. 2023. “Density-Matrix Renormalization Group Algorithm for Simulating Quantum Circuits with a Finite Fidelity.” PRX Quantum 4 (April): 020304. https://doi.org/10.1103/PRXQuantum.4.020304.