Distributed Index Bit Swap API¶
About this document¶
The cuStateVec library contains the API for distributed index bit swap, which is used to distribute state vector simulations over multiple devices and nodes. This document explains its design and usage.
Distributed state vector simulation¶
State vector distribution¶
In distributed state vector simulation, state vector is equally partitioned and distributed to multiple GPUs. In cuStateVec, these partitioned state vectors are called as sub state vectors. Sub state vectors are distributed to GPUs whose number is power of two.
An example of the state vector distribution is shown in Figure 1 (a) where \(n_{local}\) represents the number of qubits of the sub state vector. By combining multiple sub state vectors distributed to GPUs, one can add qubits to the state vector. In Figure 1, four sub state vectors are combined to add 2 (\(= log_2(4)\)) qubits.
The bits of the state vector index directly map to qubits (or wires) in quantum circuits. There are two types of index bits. The first is the index bits of sub state vectors local to GPUs. The second is the index bits that correspond to the sub state vector index. These types of index bits are called as local and global index bits as shown in Figure 1 (b).
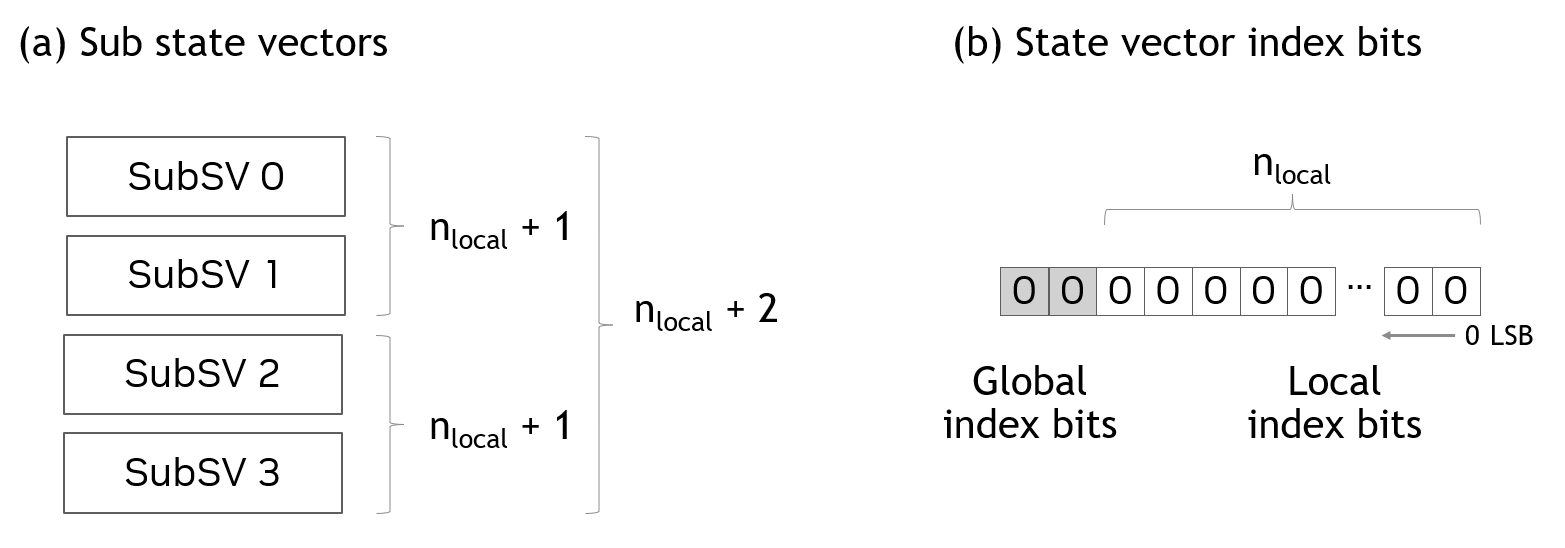
Figure 1. Sub state vectors¶
If a gate acts on local index bits, the gate is applied in each sub state vector concurrently without accessing other GPUs. However, if a gate acts on global index bits, gate application needs accesses to multiple sub state vectors. As sub state vectors are distributed to multiple GPUs, gate applications on global index bits results in data transfers between GPUs, which is the performance limiter for the distributed state vector simulation.
Qubit reordering and distributed index bit swap¶
There is a known optimization called as qubit reordering for distributed state vector simulation. Qubit reordering reorders qubits to move global index bits to local index bit positions. As the state vector simulator proactively utilizes in-place operations to save the memory usage, the qubit reordering is implemented as swaps of global and local index bits of the distributed state vector (Figure 2 (a)). By qubit reordering, gates act on global index bits are moved to those act on local index bits (Figure 2 (b)). From cuStateVec 1.3, this feature is provided by the distributed index swap API.
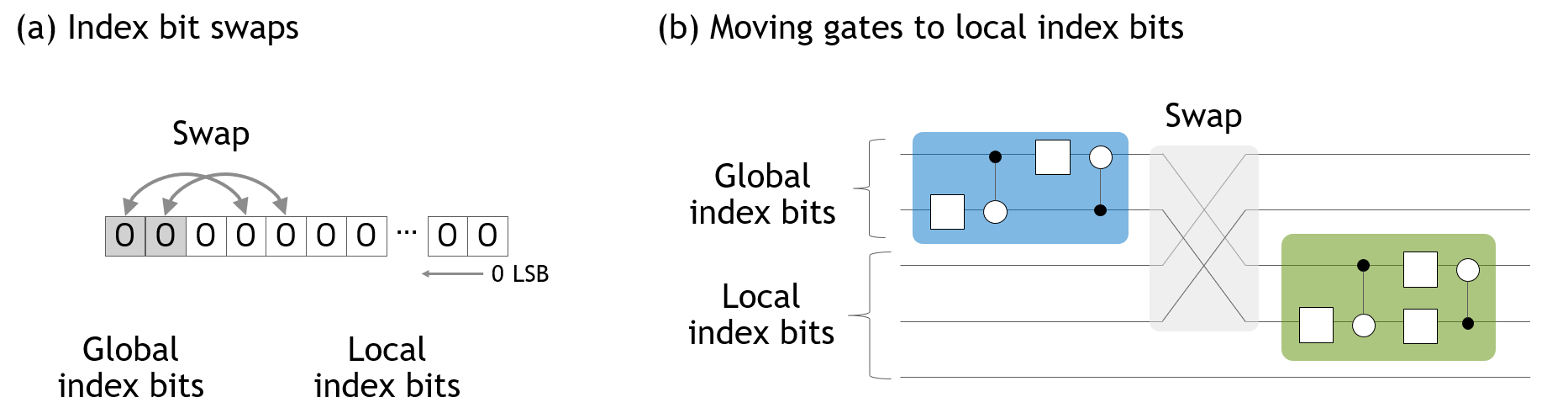
Figure 2. Qubit reordering¶
Requirements¶
The distributed index bit swap API requires the following.
Single-GPU / single-process
The main focus of this release is to support the single-GPU / single process configuration *. One process owns one GPU and one sub state vector. The sub state vector index is identical to the rank of a process that allocates the sub state vector.
CUDA-aware MPI
The MPI library should be CUDA-aware. The current release requires that
MPI_Isend()andMPI_Irecv()accept device pointers.
Note
The current version also allows multiple sub state vectors in a single process with a limitation in synchronization. It is a preliminary feature and would be supported in future releases.
API design¶
API design¶
cuStateVec’s distributed index bit swap API executes the index bit swaps with the following steps:
Define the pairs of devices that swaps state vector elements,
Compute the classical basis(mask) of the elements being transferred between pairs of devices,
Swap state vector elements.
Scheduling index bit swaps by using batch index¶
The batch index is defined as the bit-wise xor of two sub state vector indices. By giving a value to the batch index, the pairs of sub state vectors are defined.
Figure 3 shows an example with four sub state vectors. By changing the batch index from 1 to 3 *, all GPU pairs are enumerated (Figure 3 (a)). Once the pairs of sub state vectors are defined, the set of parameters to swap state vector elements are computed from the specified index bit swaps for each sub state vector (Figure 3 (b)).
The sequence of data transfers controlled by the batch index is the key concept of the distributed index bit swap API. The batch index organizes concurrent pair-wise data transfers between sub state vectors.
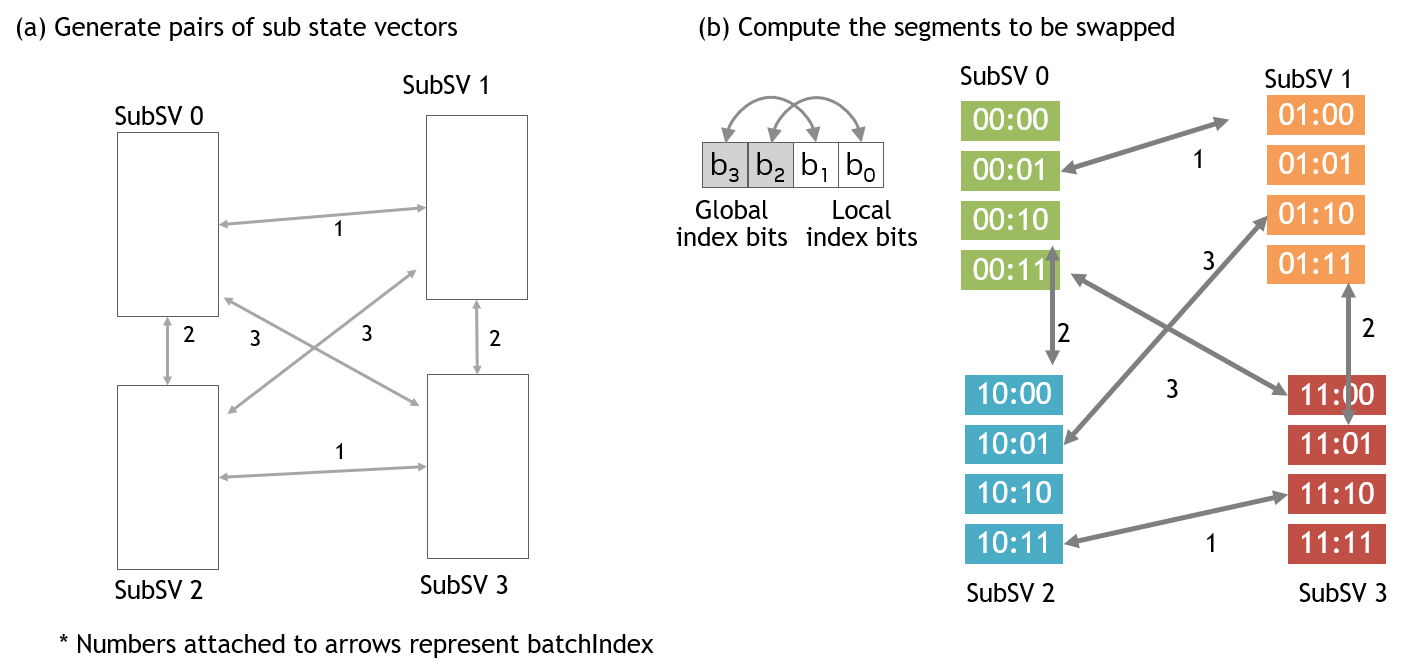
Figure 3. Index bit swap scheduling¶
Note
The batch index can be 0 when global-global and global-local index bit swaps are mixed.
In cuStateVec API, custatevecDistIndexBitSwapScheduler does this task. This component accepts index bit swaps and then computes the basis for state vector elements being swapped according to the batch index. The computed parameters is obtained by using custatevecSVSwapParameters.
Swap state vector elements¶
The next step is to swap state vector elements. The custatevecSVSwapWorker accepts the parameters generated in the previous step, selects sub state vector elements, and swaps them.
custatevecSVSwapWorker can use two communication paths.
The first path is the default and uses custatevecCommunicator that wraps the MPI library for inter-process communications. Please refer to the next section for details.
The second is optional and uses GPUDirect P2P that enables direct accesses to the device memory pointers allocated in other processes. Users need to use CUDA IPC to retrieve device pointers. The obtained P2P device pointers are set to custatevecSVSwapWorker by calling custatevecSVSwapWorkerSetSubSVsP2P().
For the detailed usage, please refer to the custatevecSVSwapWorkerCreate() and custatevecSVSwapWorkerSetSubSVsP2P() sections.
Inter-process communication by custatevecCommunicator¶
A prerequisite of the current release is that each process owns one GPU and each GPU has one sub state vector allocated on it. Thus, inter-process communication happens during data swaps between sub state vectors. In cuStateVec API, custatevecCommunicator manages inter-process communications. In the current release, MPI is the library used for the inter-process communications and custatevecCommunicator wraps it.
As there are variations of MPI libraries with different ABIs, libcustatevec.so does not link to any specific MPI library. Instead, cuStateVec provides two mechanisms to utilize MPI libraries.
Dynamic loading of MPI library
A user is able to use a recent version of Open MPI or MPICH by specifying options to
custatevecCommunicatorCreate(). This function dynamically loads the specified library by usingdlopen(). ABI differences are managed inlibcustatevec.so.The versions shown below are validated or expected to work.
Open MPI
Validated: v4.1.4 / UCX v1.13.1
Expected to work: v3.0.x, v3.1.x, v4.0.x, v4.1.x
MPICH
Validated: v4.1
External shared library as an extension
A user is able to use any preferred MPI library. The source code that wraps the MPI library is provided in the samples_mpi directory on NVIDIA/cuQuantum. This source code is compiled against the MPI library of choice to generate a shared library. The compiled shared library will be dynamically loaded by
custatevecCommunicatorCreate()if we pass the full path to it via thesonameargument.
Performance consideration¶
All data transfers happen between pairs of devices as shown in Figure 3.
These transfers are executed by calling
MPI_Isend()andMPI_Irecv(). The performance will be improved by optimizing the performance of these function calls.custatevecSVSwapWorkeraccepts the transfer workspaceTransfer workspace is used as the temporary buffer to send/receive data. Depending on systems, larger size of transfer workspace can give better performance.
Data transfers are internally chunked and pipelined. The single transfer size is
transferWorkspaceSize / 4.
Example¶
As explained above, the distributed index bit swap API works with the following steps as shown in Figure 4.
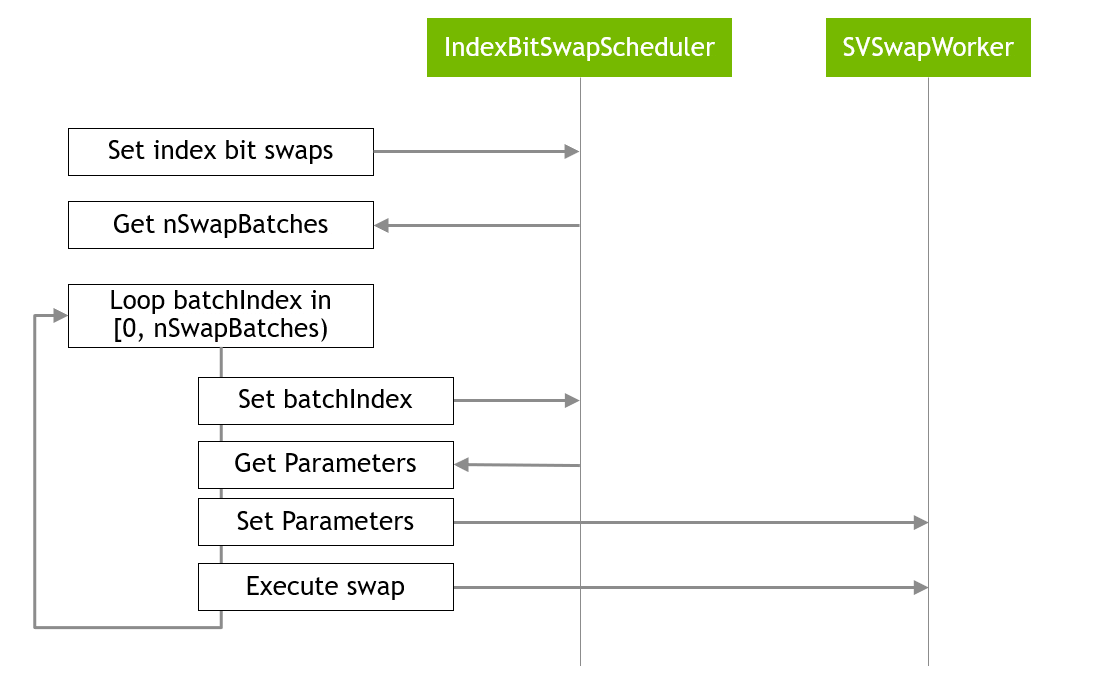
Figure 4. The main loop for distributed index batch swap¶
The following code is an excerpt of the sample.
// set the pairs of index bits being swapped
// get nSwapBatches as the number of batched swaps
unsigned nSwapBatches = 0;
custatevecDistIndexBitSwapSchedulerSetIndexBitSwaps(
handle, scheduler, indexBitSwaps, nIndexBitSwaps,
nullptr, nullptr, 0, &nSwapBatches);
// main loop, loop batchIndex in [0, nSwapBatches)
for (int batchIndex = 0; batchIndex < nSwapBatches; ++batchIndex)
{
// get parameters
custatevecSVSwapParameters_t parameters;
custatevecDistIndexBitSwapSchedulerGetParameters(
handle, scheduler, batchIndex, orgSubSVIndex, ¶meters);
// set parameters to the worker
custatevecSVSwapWorkerSetParameters(
handle, svSwapWorker, ¶meters, rank);
// execute swap
custatevecSVSwapWorkerExecute(
handle, svSwapWorker, 0, parameters.transferSize);
}
// synchronize all operations on device
cudaStreamSynchronize(localStream);
The complete sample code can be found in the NVIDIA/cuQuantum repository.