NVIDIA Mission Control autonomous hardware recovery Installation Guide#
NVIDIA Mission Control autonomous hardware recovery automates the testing, diagnosis, and repair of your SuperPODs. NVIDIA Mission Control autonomous hardware recovery is delivered as a component of the mission control product. The core capabilities of NVIDIA Mission Control autonomous hardware recovery are as follows:
Automated Baseline Testing NVIDIA Mission Control autonomous hardware recovery provides a “one click” mechanism to validate the SuperPOD hardware. For GB200, this includes tray, rack, and multi rack testing. For B200, this includes node and multi node testing. A comprehensive set of reports is included to facilitate the tracking of the cluster bring-up progress.
Automated Health Checks NVIDIA Mission Control autonomous hardware recovery provides a full suite of automated health checks that detect failures at the tray, rack, and system levels for GB200 and node level for B200 levels. In addition, system wide health checks are performed by integrating with the UFM and NMX-M network control planes.
Automated Break / Fix Workflows (coming soon) NVIDIA Mission Control autonomous hardware recovery will provide a series of break / fix workflows to handle tray (GB200) and node (B200) failures. In addition, for GB200, NVIDIA Mission Control autonomous hardware recovery will include rack (NVL72) level break / fix. The break / fix workflows execute a series of diagnostic steps to determine the cause of the failure and potential repair steps. These diagnostics include OneDiags / IST field diags to facilitate RMA.
Deployment Diagram#
NVIDIA Mission Control autonomous hardware recovery leverages an agent based architecture with a stateful backend. The NVIDIA Mission Control autonomous hardware recovery agent is deployed on all computers managed by NVIDIA Mission Control autonomous hardware recovery e.g. on the compute nodes, the Kubernetes worker nodes, and/or on the BCM head nodes. The agent is installed in BCM’s image for distribution to the managed computers. The NVIDIA Mission Control autonomous hardware recovery backend runs on the Kubernetes worker nodes of the control plane. It is installed to the control plane via helm. For failover purposes, the backend includes a primary and secondary replica. Data is synchronized between the primary and secondary. Other Mission Control components (e.g. Heimdall or BCM) integrate with NVIDIA Mission Control autonomous hardware recovery via the backend’s APIs. There is no direct communication to the agents i.e. all usage of NVIDIA Mission Control autonomous hardware recovery is intermediated by the backend.
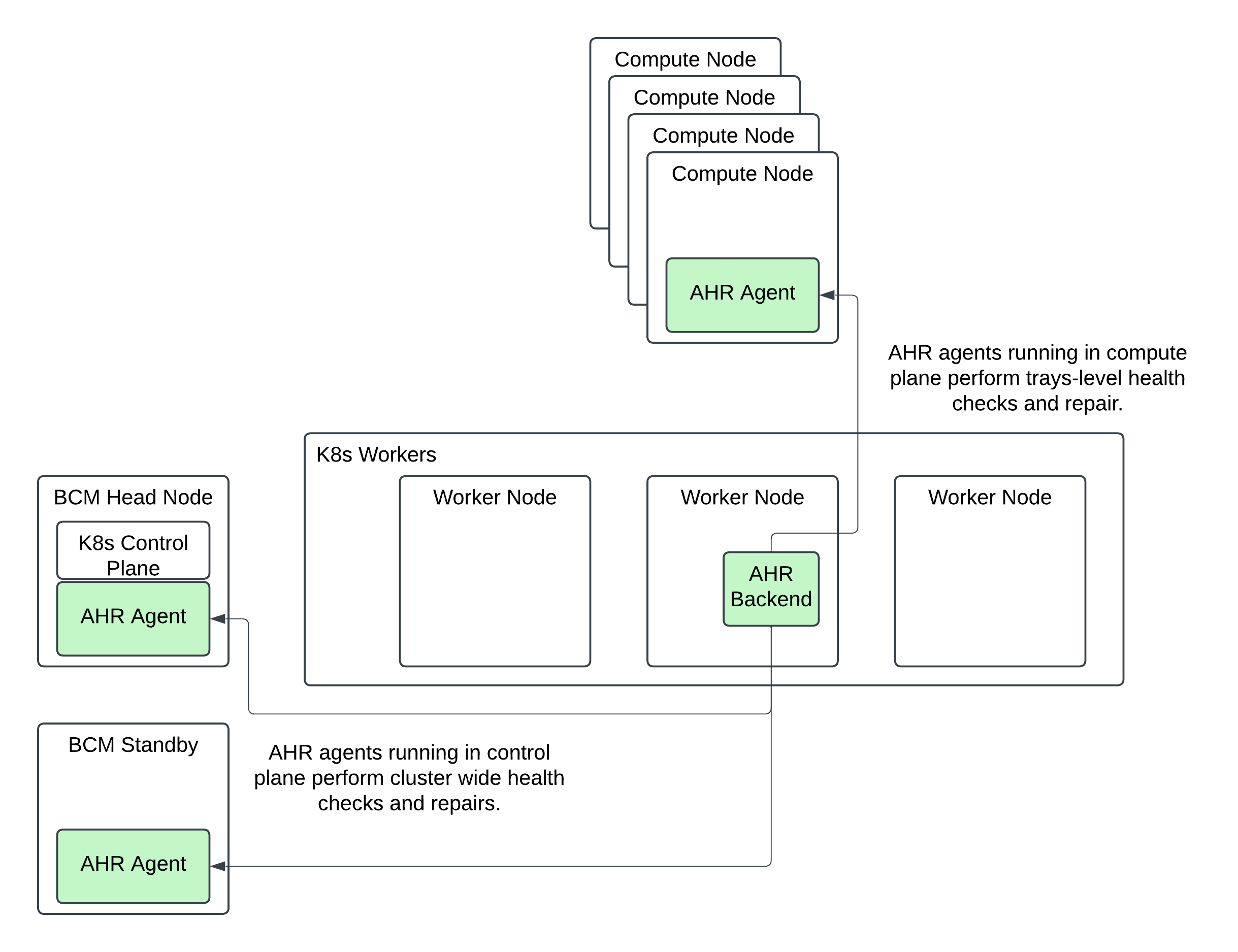
Figure: Mission Control overall architecture. NVIDIA Mission Control autonomous hardware recovery components in green.
Prerequisites#
BCM#
Version 11 or above
At least 1 BCM user created for initial login to assign the AHR ‘Administer’ permission to other users
Worker nodes for NVIDIA Mission Control autonomous hardware recovery backend#
Storage
A single storage device with a capacity of 1.5 TB with no filesystem present to be configured for object storage. RAID configurations or partitions are acceptable provided that no filesystem is used.
A location on the root filesystem to store application files
at least 500GB available for AHR backend in this location
At least 20GB available under /var for storing container images
16 cores CPU
32 GB Memory
Kubernetes control plane#
Enable exposure of Kubernetes Ingress to default HTTPS port 443
Create certificates for AHR endpoints#
Choose a domain that will be used for the application’s endpoints in the customer’s environment, e.g.
ahr.customer-domain.com.Have the customer’s IT team generate a wildcard certificate by a trusted certificate authority for the domain that was chosen, e.g. the certificates for the
ahr.customer-domain.comdomain would be for*.ahr.customer-domain.com.One way of generating publicly-signed wildcard certs manually yourself is by leveraging a service like letsencrypt using the certbot binary. One limitation of generating certificates this way is that they will need to be rotated every 90 days, so leveraging certificates managed by the customer’s IT team is the preferred method.
A self-signed certificate also can be used for the environment. If it needs to be created, follow steps in the Backend Setup with a Self-Signed Certificate Guide to generate it.
The following example demonstrates how to generate a certificate when your domain is managed with Route53 as your public DNS provider:
Generate wildcard certificates using certbot. Note: You will need the person who has the ability to add DNS records to the customer’s DNS zone present when running this command. Make sure to replace the value with the correct domain when setting the
AHR_DOMAINvariable:export AHR_DOMAIN=ahr.customer-domain.com
apt-get update && apt-get install -y certbot certbot certonly --manual \ --preferred-challenges dns \ --debug-challenges --agree-tos \ -d "*.${AHR_DOMAIN}","${AHR_DOMAIN}"
Two TXT records will be produced that will need to be added to the DNS zone under the same entry (DNS standards allow for multiple distinct TXT records with the same name). Sample output of a DNS record to be added:
Please deploy a DNS TXT record under the name: _acme-challenge.ahr.customer-domain.com. with the following value: zeLqHJbd7WG3JQCXZJbADYhWbk0kI8ADiw6KMVoS_Fk
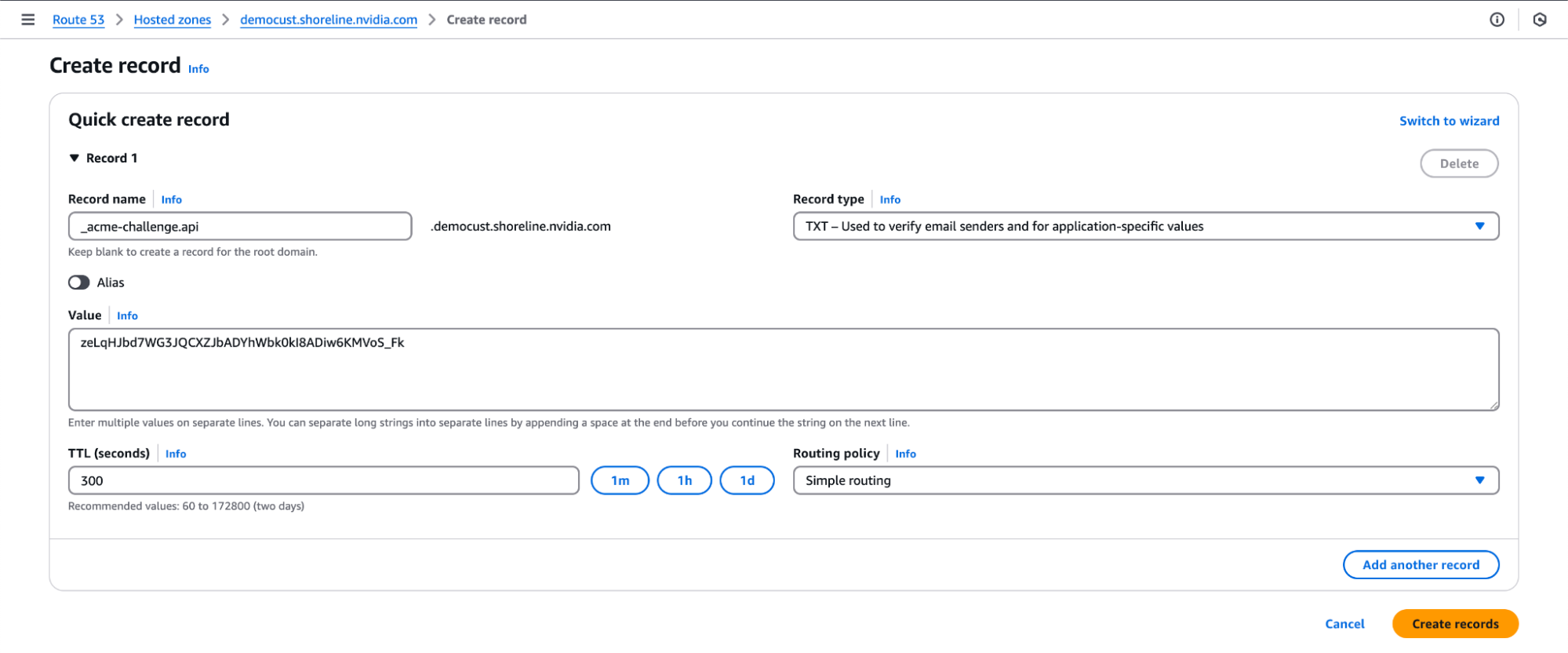
Once you add all the DNS TXT records to your public DNS, you should see a message like this
Successfully received certificate. Certificate is saved at: /etc/letsencrypt/live/ahr.customer-domain.com/fullchain.pem Key is saved at: /etc/letsencrypt/live/ahr.customer-domain.com/privkey.pem This certificate expires on 2025-07-24. These files will be updated when the certificate renews.
Copy the generated certs to a directory named by domain to the local directory for easy access:
sh -c "cd /etc/letsencrypt/live/; tar -chf - ${AHR_DOMAIN}" | tar -xvf -
Save the copied
.keyand.crtfiles from the new directory somewhere safe as they will be needed at a later step in the installation:cp ${AHR_DOMAIN}/privkey.pem ahr.key cp ${AHR_DOMAIN}/fullchain.pem ahr.crt
Later on, if installing AHR via the BCM TUI wizard, you will need this cert/key pair present in the directory from which
cm-mission-control-setupis to be run.
Setup DNS resolution for AHR endpoints#
Add A records to the DNS zone containing $AHR_DOMAIN for the 2 AHR endpoints needed to access the AHR UI from your local browser. You will need a person who has the ability to add DNS records to the $AHR_DOMAIN DNS zone to do this for you. The following endpoints should have their value resolve to the BCM headnode’s external/floating IP address (the IP you used to ssh to the BCM headnode):
$AHR_DOMAIN
api.$AHR_DOMAIN
NVIDIA Mission Control autonomous hardware recovery Backend and Agent Installation - BCM TUI Wizard#
Before you begin the installation of AHR with the BCM TUI Wizard, you will need to create the
autonomous-hardware-recoverynamespace with a specific label to allow container pulls from non-local registries. Run the following command to define the namespace in a file titledahr-namespace.yamlcat <<EOF > ahr-namespace.yaml apiVersion: v1 kind: Namespace metadata: name: autonomous-hardware-recovery labels: zarf.dev/agent: ignore EOF
then run the following to apply the definition:
kubectl apply -f ahr-namespace.yaml --kubeconfig /root/.kube/config-k8s-admin
You will also need to create a BCM user with which to deploy the AHR application with by running the following command. Make sure to replace
<strong-password>with a new valuecmsh -c 'user; add mission-control-admin; set password <strong-password>; commit;'
From the active BCM headnode, run the
cm-mission-control-setupcommand.Choose
Install or upgrade NVIDIA Mission Control autonomous hardware recoveryand then select< OK >
When prompted to select user, select the
mission-control-adminuser you just created:
For the following three screens:
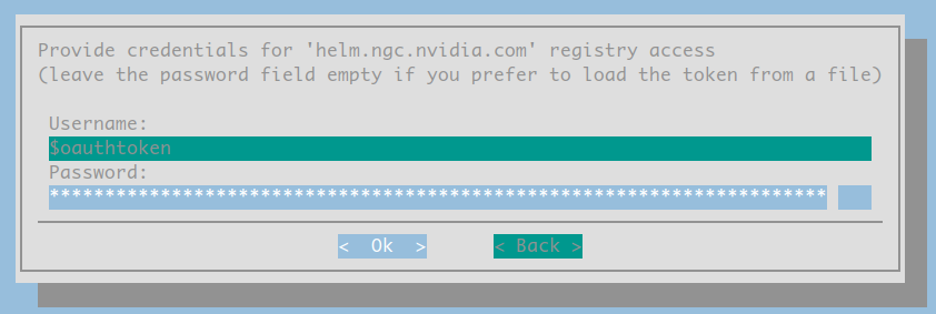
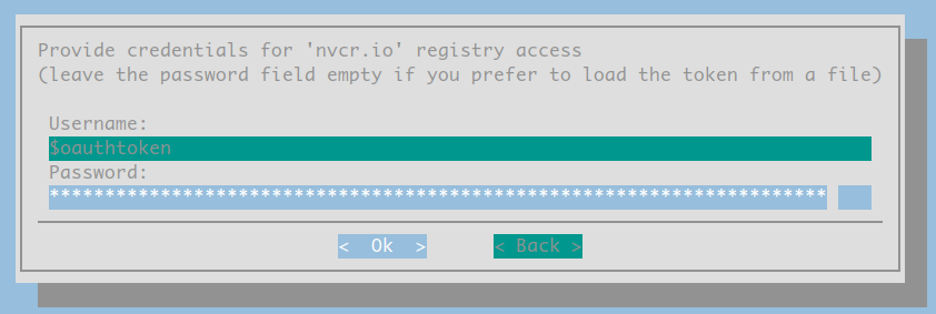
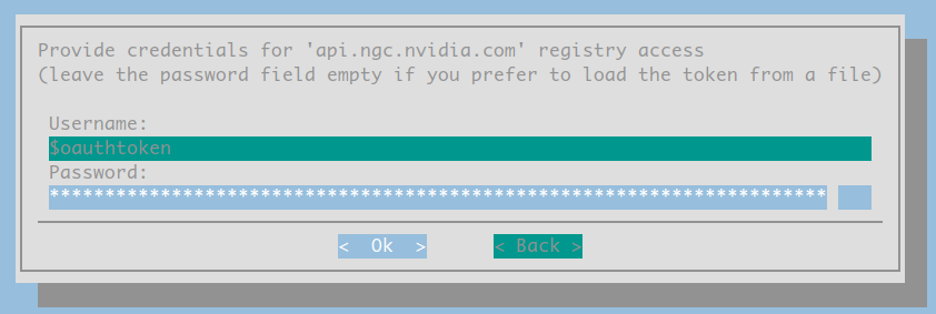
Internal users: please use the token found here: PrivateBin. This link is only available while connected to the Nvidia corporate network and will provide you with a read-only token for accessing NGC resources.
OEMs and Partners: a temporary private registry (nmc-prod) has been provisioned with access to AHR charts, containers, and resources. Read-only service keys (valid for 6 months) have been issued to existing customers. Please reach out to tzapetis@nvidia.com and dkulkarni@nvidia.com to request your service key.
When entering the key provisioned for you in the wizard, you will see failures like the following:
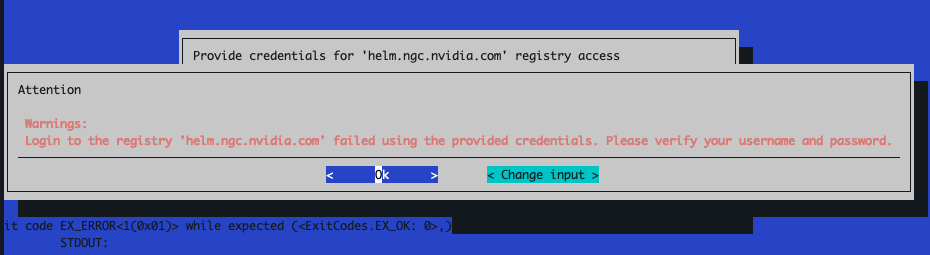
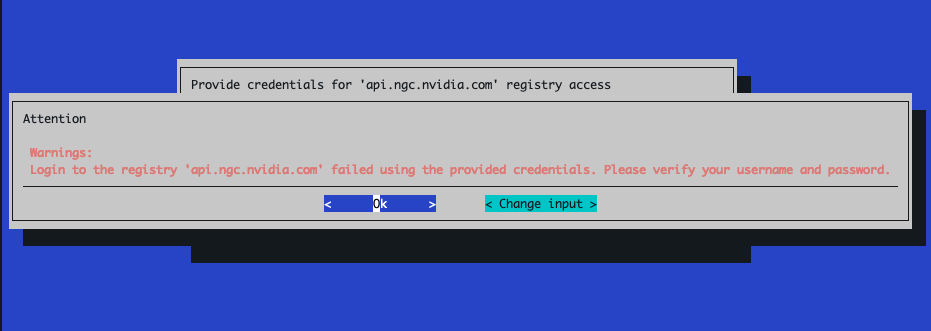
Ignore these and proceed through the wizard by selecting ‘Ok’ when these warnings show up, we will address these in a later step of the procedure.
When prompted for a wildcard TLS certificate, use the
ahr.crtandahr.keyfiles obtained from the Prerequisites section of this document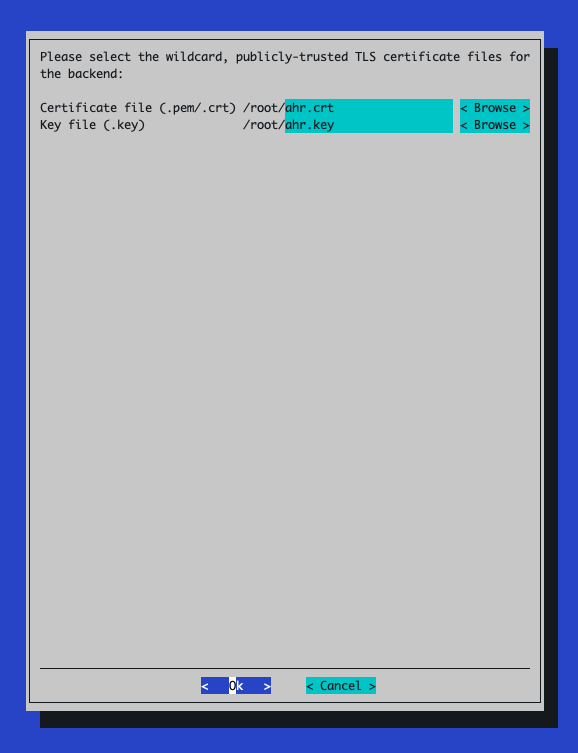
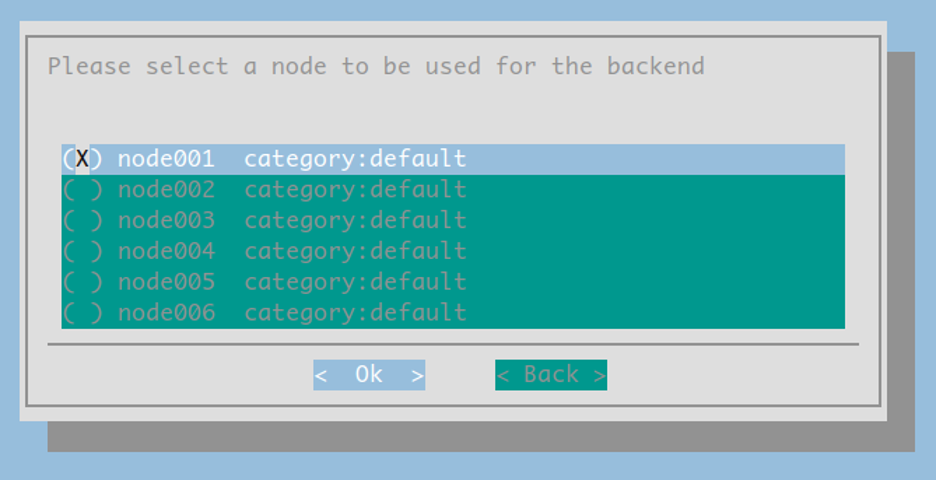
Select the node to be used for the AHR backend pod
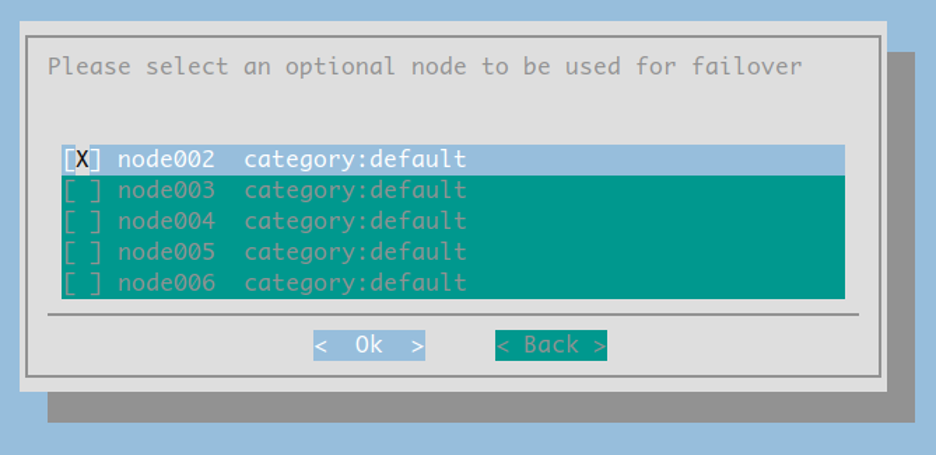
(Optional) Select a different node to be used as the failover node. More information on the failover feature can be found in the NVIDIA Mission Control autonomous hardware recovery Failover section of this document.
Select the node categories for the agent installation. These are usually the category of node used for the GPU nodes in your environment and, if present, the category used for your slurm controller nodes
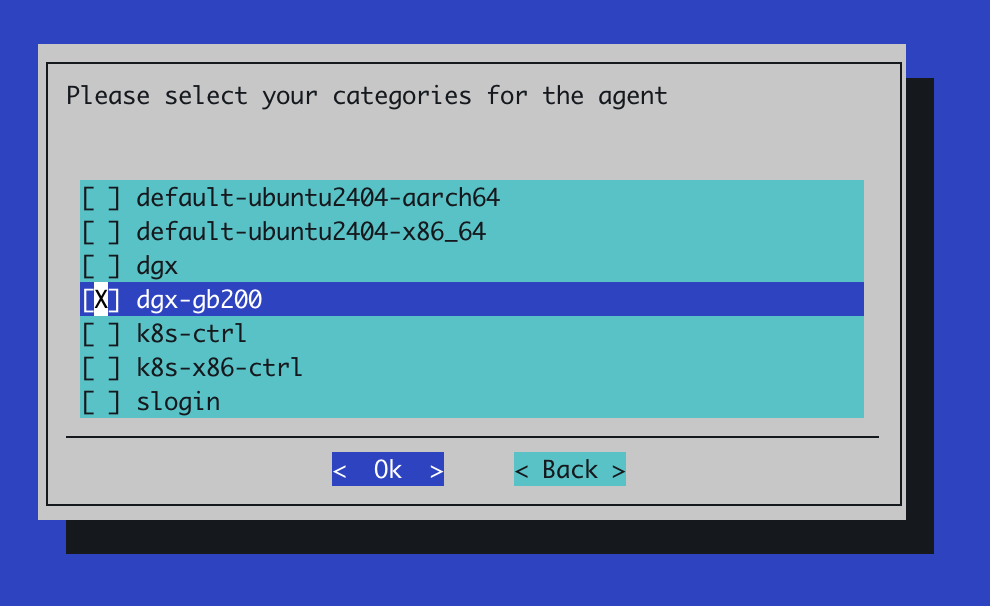
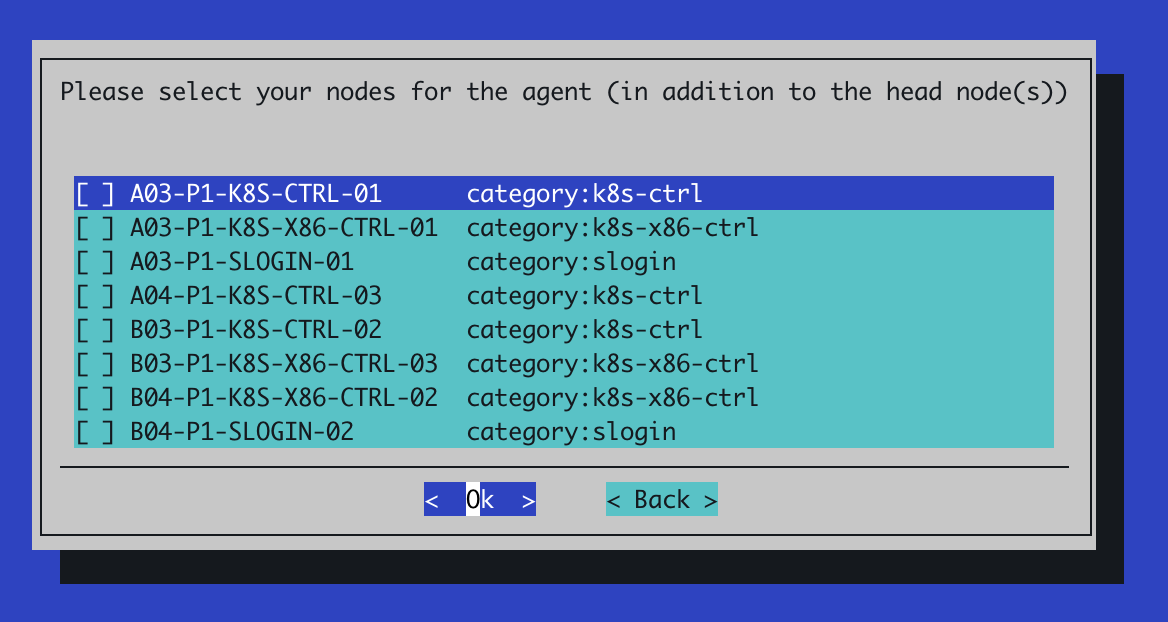
If prompted to select additional nodes for the agent, don’t select any additional nodes here:
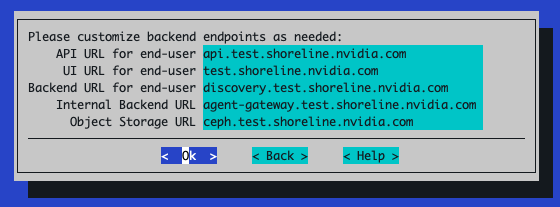
Setting custom values and version selection, populated defaults are typically fine
Selecting
Okwill attempt to verify that DNS resolution is working correctly for the endpoints listed above. If there is an issue with DNS resolution for those endpoints, you can safely ignore them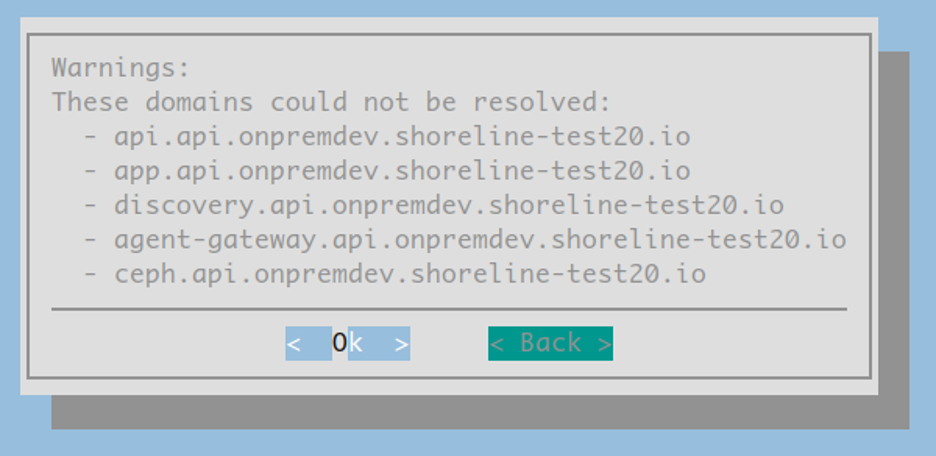
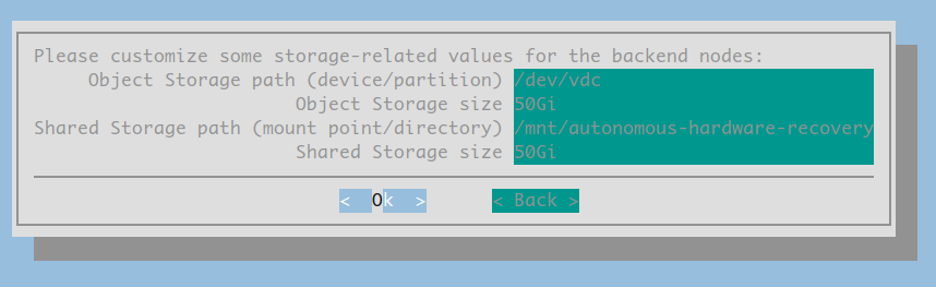
For storage configuration, the default sizes are typically sufficient but verify that each storage path is correctly specified. The ‘Object Storage path’ should reference an unpartitioned disk device, while the ‘Shared Storage path’ must point to an existing directory on the node selected to be used for the AHR backend pod.
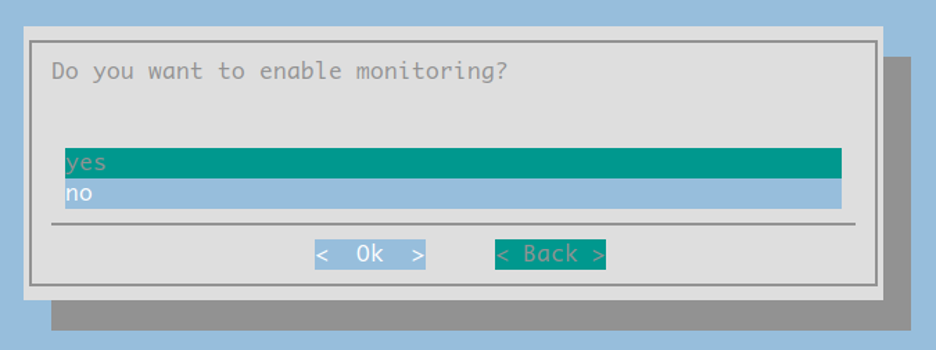
When prompted to enable monitoring, select ‘No’.
Save config
Internal Users: Select ‘Save config and deploy’:
OEMS and Partners: Select ‘Save config & exit’:
We will need to update the config file you just saved to point to the appropriate registry to access AHR helm charts, containers, and resources. In these examples, the file was saved with the name
cm-mission-control-setup.conf. Make sure to replace this file with the appropriate name of the file that was just saved from thecm-mission-control-setupwizard:Backup the original file just in case:
cp cm-mission-control-setup.conf cm-mission-control-setup.conf.orig
Update the container and resource urls to the appropriate registry:
sed -i 's|nvidian/team/shoreline|fcypcg1knhby/team/nmc-prod|g' cm-mission-control-setup.conf
Update the helm chart url to the appropriate registry:
sed -i 's|nvidian/shoreline|fcypcg1knhby/nmc-prod|g' cm-mission-control-setup.conf
Update registry locations in the AHR backend helm chart for the AHR backend containers:
grep -q 'registry: "nvcr.io/fcypcg1knhby/nmc-prod/shoreline-backend"' cm-mission-control-setup.conf || sed -i '/[[:space:]]*ENABLE_BCM_GPU_DISCOVERY: false/a\ registry: "nvcr.io/fcypcg1knhby/nmc-prod/shoreline-backend"' cm-mission-control-setup.conf if ! grep -q '[[:space:]]frontend:' cm-mission-control-setup.conf; then awk ' /^[[:space:]]*values:[[:space:]]*$/ { values_found = 1; print; next } values_found && /^[[:space:]]*data:[[:space:]]*$/ { print; print " frontend:" print " registry: \"nvcr.io/fcypcg1knhby/nmc-prod/shoreline-frontend\"" print " system_metadata:" print " registry: \"nvcr.io/fcypcg1knhby/nmc-prod/shoreline-metadata\"" print " ops_tool:" print " registry: \"nvcr.io/fcypcg1knhby/nmc-prod/ops-tool\"" print " ui:" print " registry: \"nvcr.io/fcypcg1knhby/nmc-prod/shoreline-ui\"" print " ceph:" print " registry: \"nvcr.io/fcypcg1knhby/nmc-prod/shoreline-ceph\"" print " openbao:" print " registry: \"nvcr.io/fcypcg1knhby/nmc-prod/shoreline-openbao\"" print " ceph_exporter:" print " registry: \"nvcr.io/fcypcg1knhby/nmc-prod/ceph_exporter:4.2.3\"" values_found = 0; next } { print } ' cm-mission-control-setup.conf > cm-mission-control-setup.conf.tmp if [ -f cm-mission-control-setup.conf.tmp ]; then mv cm-mission-control-setup.conf.tmp cm-mission-control-setup.conf fi fi
Update the AHR agent config file to point to the appropriate registry:
grep -q 'AGENT_IMAGE=fcypcg1knhby/nmc-prod/shoreline-agent' /cm/local/apps/cm-setup/lib/python3.12/site-packages/cmsetup/plugins/autonomous_hardware_recovery/templates/agent.config || sed -i 's|AGENT_IMAGE=nvidian/shoreline/agent|AGENT_IMAGE=fcypcg1knhby/nmc-prod/shoreline-agent|' /cm/local/apps/cm-setup/lib/python3.12/site-packages/cmsetup/plugins/autonomous_hardware_recovery/templates/agent.config
Run the
cm-mission-control-setupinstaller with the updated config:cm-mission-control-setup -c cm-mission-control-setup.conf
[Only if using self-signed certificate] Run post-install backend configuration steps.
Monitoring and observability installation#
Once the AHR backend has been successfully deployed using cm-mission-control-setup, you will want to deploy the AHR observability resources to the BCM-managed Grafana instance.
Create a file with the necessary values required to deploy the observability resources.
Assign an environment variable for each endpoint. *Please substitute correct values for each of the following
GRAFANA_ENDPOINT- This is the URL that will be used to access the Grafana instance deployed in the NVIDIA Mission Control environment and is where observability resources specific to the autonomous hardware recovery backend will be deployed to (dashboards and alerts). You can obtain the value for this from the team who setup the Prometheus Operator stack in the environment, or if you set the Prometheus Operator stack up yourself, can set this to the bcm headnode’s external ip, prefixed withhttps://and suffixed with/grafana, ex:https://grafana.ahr.nvidia.com/grafanaorhttps://1.1.1.1/grafana.GRAFANA_USER- The user with permissions to provision dashboards and alerts via API to the Grafana instance deployed in the NVIDIA Mission Control environment. This can be obtained by running the following command:kubectl --kubeconfig /root/.kube/config-k8s-admin --namespace prometheus get secrets kube-prometheus-stack-grafana -o jsonpath="{.data.admin-user}" | base64 -d ; echoGRAFANA_PASSWORD- The password for the user defined forGRAFANA_USER. This can be obtained by running the following command:kubectl --kubeconfig /root/.kube/config-k8s-admin --namespace prometheus get secrets kube-prometheus-stack-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echoexport GRAFANA_ENDPOINT=https://<headnode_ip>/grafana export GRAFANA_USER="admin" export GRAFANA_PASSWORD="xxxxx"
Create
values-observability.yamlfile by running the following command:cat <<EOF > values-observability.yaml data: enable_monitoring: true fluent_bit: disable: true servicemonitor: enable: true namespace: prometheus labels: release: "kube-prometheus-stack" grafana: deploy_alerts: true deploy_dashboards: true url: "$GRAFANA_ENDPOINT" user: "$GRAFANA_USER" password: "$GRAFANA_PASSWORD" EOF
Upgrade the backend by merging the values in the
values-observability.yamlfile with the existing values used for the AHR backend installation:helm upgrade backend shoreline-onprem-backend/shoreline-onprem-backend -f values-observability.yaml --reuse-values --version "$(helm get values --kubeconfig /root/.kube/config-k8s-admin -n autonomous-hardware-recovery backend | grep platform_ver | cut -d '-' -f 2)" --namespace autonomous-hardware-recovery --kubeconfig /root/.kube/config-k8s-admin
Failover Replication Verification (if installed)#
If the failover option was selected, you’ll want to verify that data replication between the primary and secondary backend instances is occurring successfully
Verify Ceph replication is set up properly
From the headnode run the following against the primary backend:
kubectl --kubeconfig /root/.kube/config-k8s-admin exec -it -n autonomous-hardware-recovery shorelinebackend-0 -c ceph -- radosgw-admin sync status
The following is the expected output if the replication is running properly:
metadata sync no sync (zone is master) data sync source: 71f9ccd2-97ff-4b92-aff1-d7a5324bb207 (shoreline-zone-shorelinebackend-failover-0) syncing full sync: 0/128 shards incremental sync: 128/128 shards data is caught up with source
From the headnode run the following against the secondary (failover) backend:
kubectl --kubeconfig /root/.kube/config-k8s-admin exec -it -n autonomous-hardware-recovery shorelinebackend-failover-0 -c ceph -- radosgw-admin sync status
The following is the expected output if the replication is running properly:
metadata sync syncing full sync: 0/64 shards incremental sync: 64/64 shards metadata is caught up with master data sync source: 32af394d-ee8f-4d6b-a221-ebce96ce981b (shoreline-zone-shorelinebackend-0) syncing full sync: 0/128 shards incremental sync: 128/128 shards data is caught up with source
Verify bucket data replication. On the headnode, run:
kubectl --kubeconfig /root/.kube/config-k8s-admin exec -it -n autonomous-hardware-recovery shorelinebackend-0 -c openbao -- /bin/sh aws s3 ls s3://onprem-org-shoreline-mdkey-mr/ --endpoint-url http://shoreline-ceph-service:7480 --recursive aws s3 ls s3://onprem-org-shoreline-mdkey-mr/ --endpoint-url http://shoreline-ceph-service-failover:7480 --recursive exit
The contents of the 2 buckets should match
Backup AHR databases. On the headnode, run:
kubectl --kubeconfig /root/.kube/config-k8s-admin exec -it -n autonomous-hardware-recovery shorelinebackend-0 -c ops-tool -- /bin/bash
Then, once in the ops-tool container, run:
python3 # Run in the python3 console import ops_tool # This command can take some time to run: ops_tool.backup_backend("shorelinecust") exit() exit
Verify database backups. On the headnode, run:
### on the primary backend kubectl --kubeconfig /root/.kube/config-k8s-admin exec -it -n autonomous-hardware-recovery shorelinebackend-0 -c openbao -- /bin/sh aws s3 ls --endpoint-url http://shoreline-ceph-service:7480 ### Choose the bucket that contains your change aws s3 ls s3://ss-arc-shorelinecust-onprem-local --recursive | sort ### in the expected output, the db will contain the latest timestamp ### the following is just an example 2025-03-04 01:57:07 110592 7482318612660724179_shorelinecust_internal_configuration_1.db exit
Verify OpenBao backup cron job. On the BCM headnode, run:
### choose a completed shoreline-backup-xxxxxxxx pod kubectl --kubeconfig /root/.kube/config-k8s-admin -n autonomous-hardware-recovery get pod kubectl --kubeconfig /root/.kube/config-k8s-admin -n autonomous-hardware-recovery logs <backup pod> ### expected output in the log upload: ./openbao.tar to s3://onprem-org-shoreline-mdkey-mr/openbao.tar ### other useful commands to get some details about cronjobs kubectl get cronjobs -n autonomous-hardware-recovery --kubeconfig /root/.kube/config-k8s-admin kubectl get cronjob shoreline-backup -n autonomous-hardware-recovery --kubeconfig /root/.kube/config-k8s-admin -o yaml
Initial Login to the NVIDIA autonomous hardware recovery UI#
In a browser, navigate to the url used for the APP/UI endpoint. This is the value that was set for
$AHR_DOMAINin the Prerequisites section of this document:https://$AHR_DOMAIN/. Login using your BCM LDAP credentials.You will need to enable the
Administerrole for the relevant users:Navigate to the Access Control page in the left sidebar.
In the top right corner, click on the ‘Remove all limits’ button.
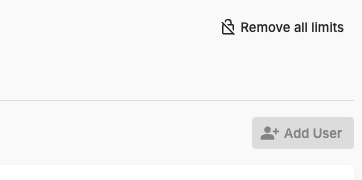
Enter the default password of
admin.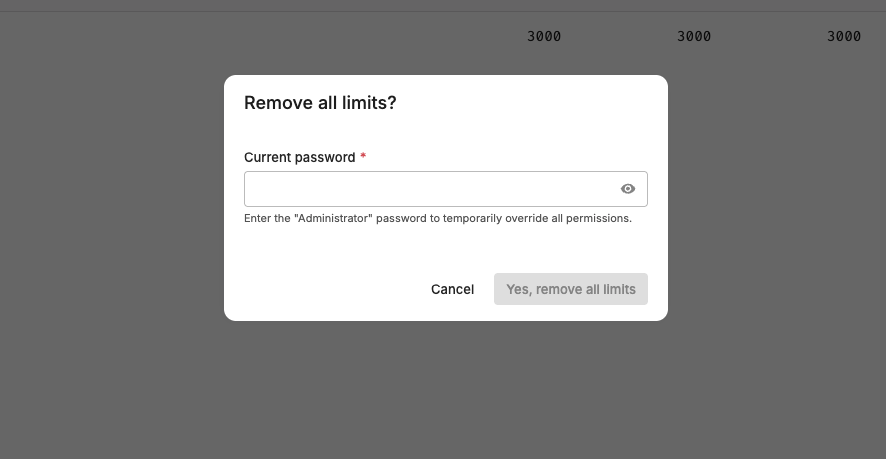
The bottom of your left sidebar should now say
Elevated privilegesfor your user.
The ‘Remove all limits’ button should now say ‘Change Administrator password’. Click this button to immediately change the default password to another value and save it somewhere safe.
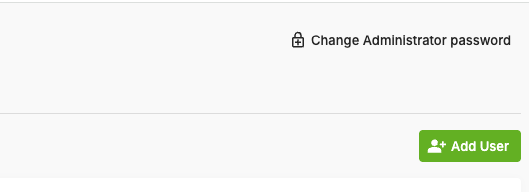
Your user will now have the ability to grant the
Administerrole to the relevant users by click the ‘Manage permissions’ button and enabling theAdministratortoggle.
BCM Connectivity Integration#
Login into the UI as a user with the
Administerrole.From the left menu bar, select “Integrations”.
Click the “Configure” button within the “BCM Connectivity” tile.
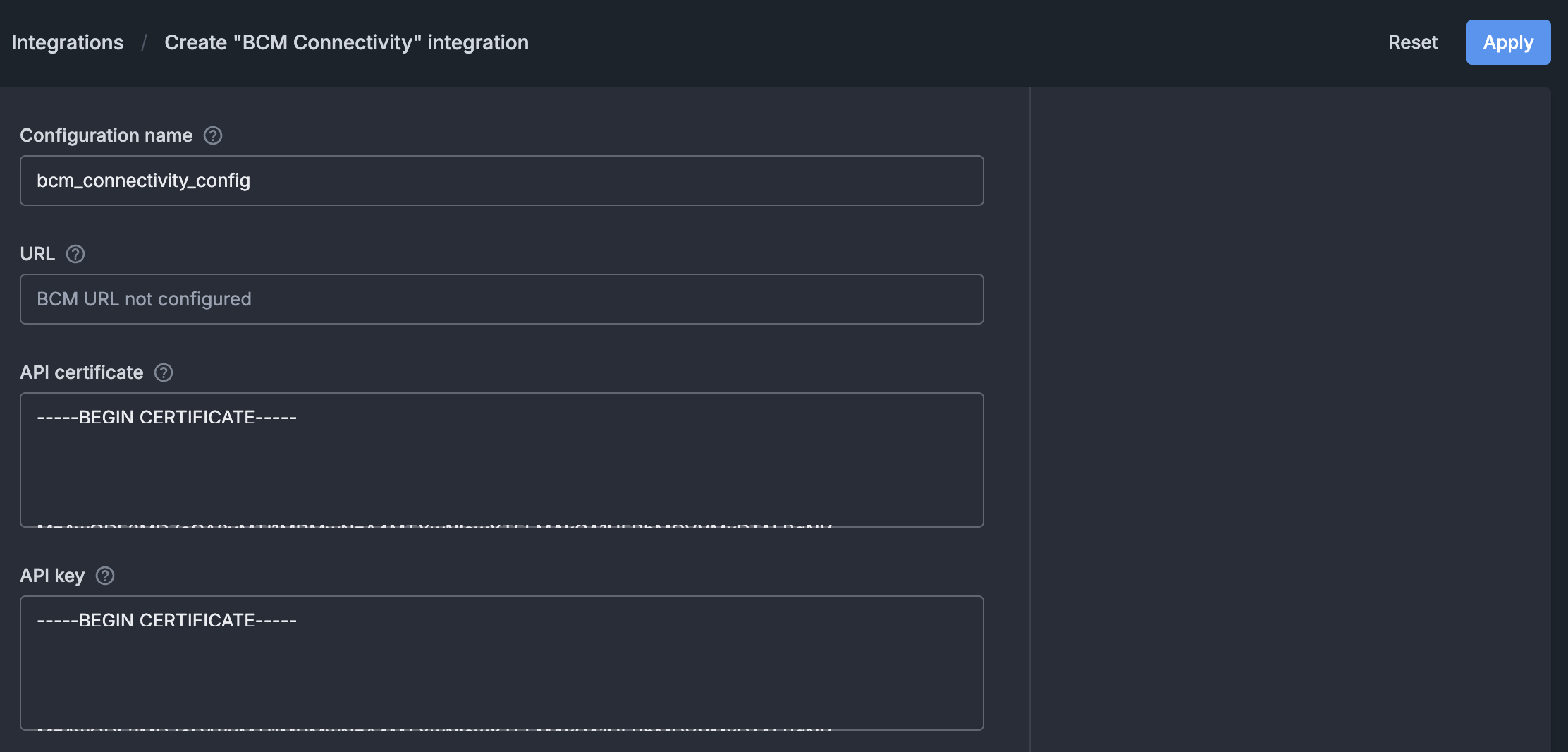
On the BCM Connectivity configuration page:
Enter a name for the integration (e.g., bcm_connectivity_configuration).
Set the “API certificate” field to the content of
/cm/local/apps/autonomous-hardware-recovery/etc/autonomous-hardware-recovery.pemfile (cat /cm/local/apps/autonomous-hardware-recovery/etc/autonomous-hardware-recovery.pemcan be run on BCM headnode to view the contents of the file).Set the “API key” field to the content of
/cm/local/apps/autonomous-hardware-recovery/etc/autonomous-hardware-recovery.keyfile (cat /cm/local/apps/autonomous-hardware-recovery/etc/autonomous-hardware-recovery.keycan be run on BCM headnode to view the content of the file).Click the “Apply” button on the top right.
To check the BCM Connectivity integration health, a user with the
Administerpermission should click on the “Test” button on the top right.
Backend Health and Agent Connectivity#
To verify that the backend is running and agents are successfully registered:
Log in to the NVIDIA Mission Control Autonomous Hardware Recovery portal using your credentials, and navigate to the Runbooks section.
Click New Runbook in the top-right corner. You should see a screen similar to the example below:

In the central page, click Op Statement to create your first cell to query the resource.
Type
hostin the cell as your query and press Enter.Successfully registered agents will be listed with their host information, as shown in the example below:
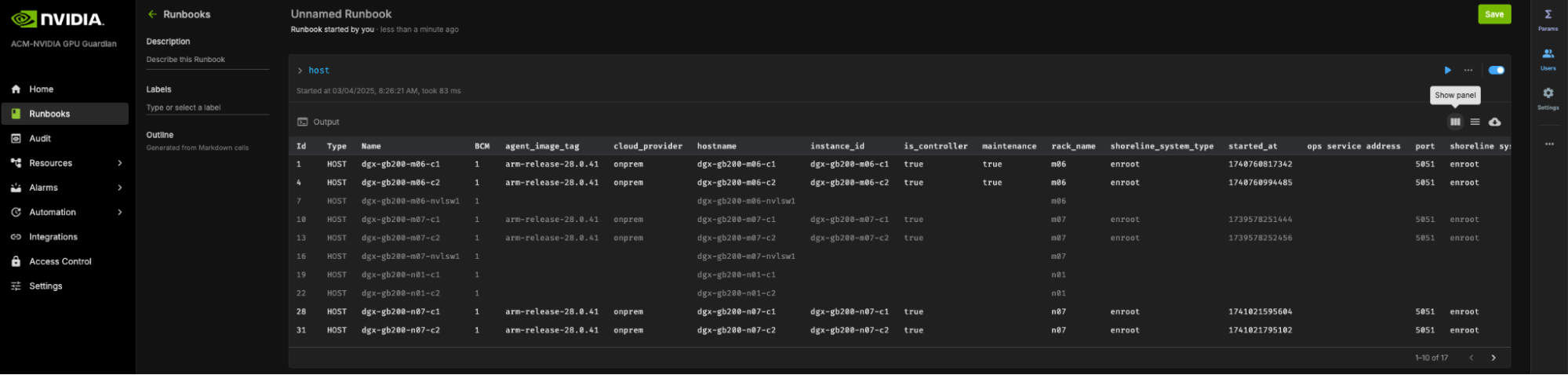
This confirms that the backend is operational, and the agents have successfully discovered and registered with it through its secure discovery endpoint.
NVIDIA Mission Control autonomous hardware recovery Runbook Deployment#
NVIDIA Mission Control autonomous hardware recovery uses OpenTofu, an open source infrastructure-as-code (IAC) tool, to automate the deployment of resources required to run baseline tests, health checks, and break/fix workflows. Follow the steps below to deploy the most updated version of the NVIDIA Mission Control autonomous hardware recovery tests.
Install the
tofubinary on the BCM headnode:apt-get update && apt-get install -y apt-transport-https ca-certificates curl gnupg install -m 0755 -d /etc/apt/keyrings curl -fsSL https://get.opentofu.org/opentofu.gpg | tee /etc/apt/keyrings/opentofu.gpg >/dev/null curl -fsSL https://packages.opentofu.org/opentofu/tofu/gpgkey | gpg --no-tty --batch --dearmor -o /etc/apt/keyrings/opentofu-repo.gpg >/dev/null chmod a+r /etc/apt/keyrings/opentofu.gpg /etc/apt/keyrings/opentofu-repo.gpg echo \ "deb [signed-by=/etc/apt/keyrings/opentofu.gpg,/etc/apt/keyrings/opentofu-repo.gpg] https://packages.opentofu.org/opentofu/tofu/any/ any main deb-src [signed-by=/etc/apt/keyrings/opentofu.gpg,/etc/apt/keyrings/opentofu-repo.gpg] https://packages.opentofu.org/opentofu/tofu/any/ any main" | \ tee /etc/apt/sources.list.d/opentofu.list > /dev/null chmod a+r /etc/apt/sources.list.d/opentofu.list apt-get update apt-get install tofu
Verify the binary was successfully installed by running:
tofu versionCreate Service Accounts for NVIDIA Mission Control autonomous hardware recovery API and Runbooks. These users are used to deploy the runbooks, during the Firmware Upgrade process, and also during the Break/Fix workflow to verify that the AHR agents are connected back to the backend. Note: We recommended creating a different user for each of the tasks to gain better access control and auditing.
Login to NVIDIA Mission Control autonomous hardware recovery UI
https://{AHR_APP_URL}/with BCM LDAP CredentialsNavigate to the Access Control page in the left sidebar and then to the Users tab.
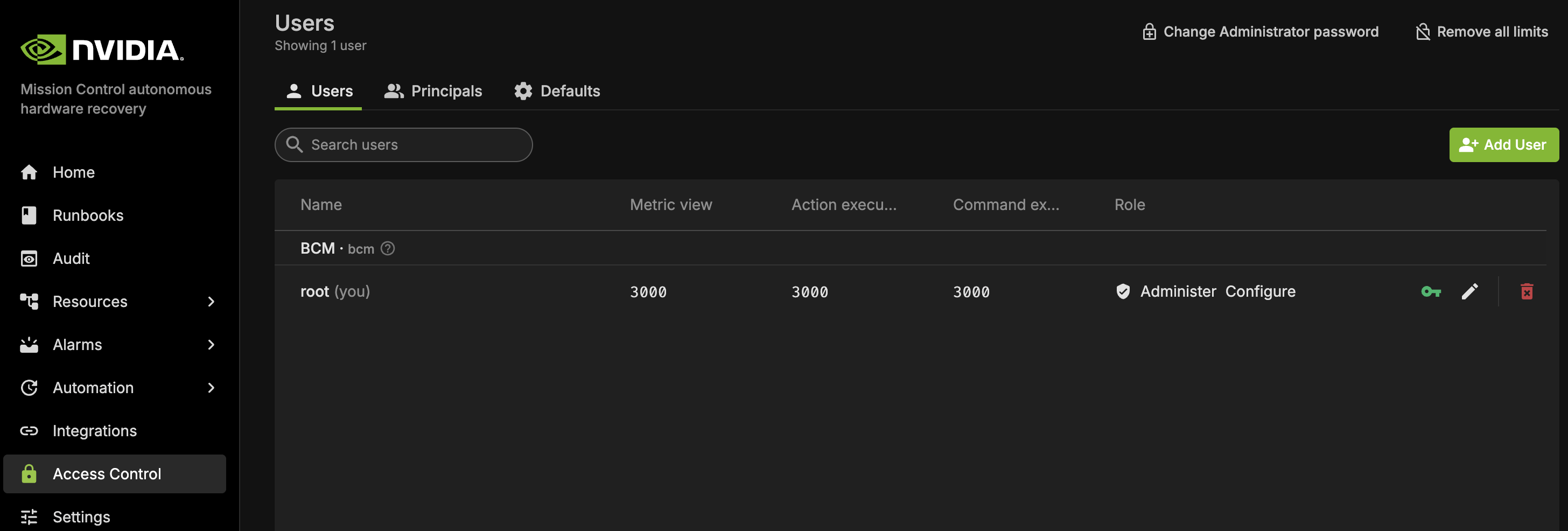
From there, you may either:
Use the default root user, or
Create a new user:
Click ‘Add User’ to create a new user, and apply the following settings:
Permission: Configure (for FW upgrade & Break/Fix) or Administer (for deployments)
Limits: Set all applicable limits to 3000
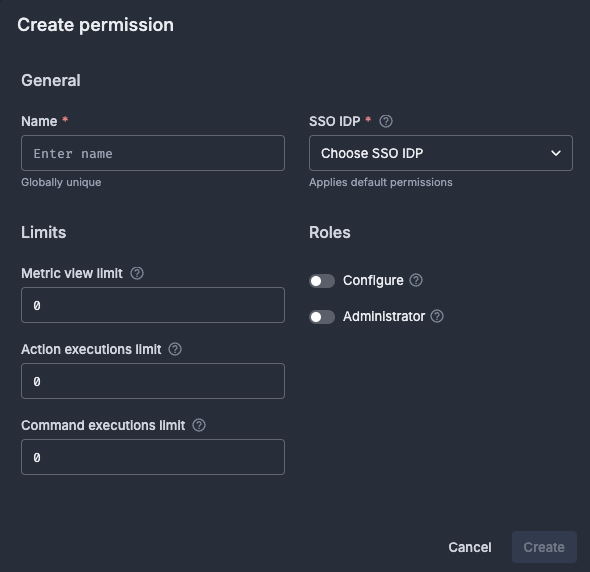
Once the user has been created, search for the user and click the Key icon to the right to generate an API Token. You must also provide an expiration based on the API key rotation policy.
 .
.Copy the token and use it to send requests to the AHR API.

Add Secrets to AHR
Navigate to: Settings → Secrets
Click the
+icon to add new secrets. Create the following two secrets. Important: Ensure the key names exactly match the ones below. These are referenced in the AHR runbooks:Secret 1
Key:
AHR_API_ENDPOINTValue: The API endpoint of your backend. Do not include
https://or a trailing slash.Example:
api-customer.nvidia.com
Secret 2
Key:
AHR_TOKENValue: The API token generated for the FW Upgrade and Break/Fix service user
Run the following commands to download and extract the appropriate artifacts package (
nmc-ahr.tgz) from the NGC registry, and place it on the headnode in the/cm/local/apps/autonomous-hardware-recovery/runbooks/folder. You will need to set theAHR_NGC_TOKENvariable to the key obtained in the Installation section of the document and also theAHR_NGC_VERSIONvariable to the version to download.CHIPshould be set to “GB200”.Set environment variables
export AHR_NGC_TOKEN=<ngc-token-used-during-installation> export AHR_NGC_VERSION=1.0.4 export AHR_NGC_ORG=nvidian export AHR_NGC_TEAM=shoreline export CHIP=GB200
OEM and Partners only: Please also run the following:
export AHR_NGC_ORG=fcypcg1knhby export AHR_NGC_TEAM=nmc-prod
Download the package and extract
curl -LO "https://api.ngc.nvidia.com/v2/org/${AHR_NGC_ORG}/team/${AHR_NGC_TEAM}/resources/nmc-ahr/versions/${AHR_NGC_VERSION}/files/nmc-ahr.tgz" -H "Authorization: Bearer ${AHR_NGC_TOKEN}" -H "Content-Type: application/json" mkdir -p /cm/local/apps/autonomous-hardware-recovery/runbooks cp nmc-ahr.tgz /cm/local/apps/autonomous-hardware-recovery/runbooks cd /cm/local/apps/autonomous-hardware-recovery/runbooks tar -xzvf nmc-ahr.tgz
OEMs and Partners only: Invoke the following command to switch to use the appropriate private container registry (
nmc-prod)sed -i 's/nvidian\/shoreline/fcypcg1knhby\/nmc-prod/g' ./Actions/actions.tf ./Runbooks/runbook_files/breakfix/HPL_TEST_MPIRUN.json ./Runbooks/runbook_files/breakfix/NCCL_TEST_MPIRUN.json ./Runbooks/runbook_files/breakfix/NVRASTOOL.json ./Runbooks/runbook_files/srt2/SR_CUDA_SAMPLES.json ./Runbooks/runbook_files/srt2/SR_MEMORY_BENCHPRESS.json
Deploy the runbooks via opentofu
In
/cm/local/apps/autonomous-hardware-recovery/runbooks/CHIP/${CHIP}/Baselinedirectory, create theterraform.tfvarsfile which includes these user inputs# terraform.tfvars # The hostname of the active headnode. Note: only one node is supported headnode_name="<headnode hostname>" # The name of the Slurm node from where to submit slurm jobs. Note: Only one node is supported slurm_node_name="<slurm_control_node hostname>" # The URL of the AHR API Endpoint ahr_url="https://your-instance.nvidia.com" # The jwt for the AHR API, found in Access Control ahr_token="<jwt>" # Nvidia Container Registry token ** nvcr_token="<token>" # Set to false if automated support ticket feature is opted in, else by default it is disabled disable_callhome=true
For the
nvcr_tokenvalue, use the ngc key obtained in the Installation section of the document.To resolve a known issue with BCM missing a required certificate, on ALL headnodes, please do the following:
sudo mkdir -p /shoreline/.cm sudo cp /root/.cm/admin.key /shoreline/.cm/admin.key sudo cp /root/.cm/admin.pem /shoreline/.cm/admin.pem sudo chown shoreline:shoreline /shoreline/.cm /shoreline/.cm/admin.pem /shoreline/.cm/admin.key
cdto the appropriate directory (with terraform.tfvars) and run opentofu commandscd /cm/local/apps/autonomous-hardware-recovery/runbooks/CHIP/${CHIP}/Baseline # Get value set for CUSTOMER_ID export CUSTOMER_ID=$(kubectl --kubeconfig /root/.kube/config-k8s-admin get configmap shoreline-variables -n autonomous-hardware-recovery -o jsonpath="{.data.CUSTOMER_ID}") # Set AWS environment variables for access ceph buckets export AWS_ENDPOINT_URL_S3=https://$(kubectl --kubeconfig /root/.kube/config-k8s-admin get configmap shoreline-variables -n autonomous-hardware-recovery -o jsonpath="{.data.CEPH_ENDPOINT}") export AWS_ACCESS_KEY_ID=$(kubectl --kubeconfig /root/.kube/config-k8s-admin get secret shoreline-secret -n autonomous-hardware-recovery -o jsonpath="{.data.aws-access-key-id}" | base64 -d) export AWS_SECRET_ACCESS_KEY=$(kubectl --kubeconfig /root/.kube/config-k8s-admin get secret shoreline-secret -n autonomous-hardware-recovery -o jsonpath="{.data.aws-secret-access-key}" | base64 -d) export AWS_DEFAULT_REGION=local tofu init \ -backend-config bucket="ss-arc-$CUSTOMER_ID-onprem-local-objects" \ -backend-config key="opentofu/terraform.tfstate" # if terraform.tfvars does not exist, # you will be prompted for values # ignore any warnings in the plan tofu apply
NVIDIA Mission Control autonomous hardware recovery Installation - Manual Install#
Backend Install#
Run the following steps on the BCM head node to install the NVIDIA Mission Control autonomous hardware recovery backend on the Kubernetes. In this section, we will resolve the NVIDIA Mission Control autonomous hardware recovery endpoints, create some k8s artifacts for NVIDIA Mission Control autonomous hardware recovery, and install the NVIDIA Mission Control autonomous hardware recovery backend with Helm.
Before you begin the installation of AHR with the BCM TUI Wizard, you will need to create the
autonomous-hardware-recoverynamespace with a specific label to allow container pulls from non-local registries. Run the following command to define the namespace in a file titledahr-namespace.yamlcat <<EOF > ahr-namespace.yaml apiVersion: v1 kind: Namespace metadata: name: autonomous-hardware-recovery labels: zarf.dev/agent: ignore EOF
then run the following to apply the definition:
kubectl --kubeconfig /root/.kube/config-k8s-admin apply -f ahr-namespace.yaml
Add required API token permissions to the NVIDIA Mission Control autonomous hardware recovery profile
Check if the autonomous-hardware-recovery profile exists in BCM:
cmsh -c 'profile list' Name (key) Services ----------------------------- ----------------------------------------------------------- admin autonomous-hardware-recovery CMDevice,CMUser autonomous-job-recovery CMDevice bootstrap cmhealth CMMon,CMMain,CMJob,CMDevice cmpam CMJob,CMMain litenode CMDevice,CMStatus,CMSession,CMMain,CMMon,CMNet,CMPart monitoringpush CMMon mqtt CMDevice,CMMon,CMPart node CMDevice,CMStatus,CMCert,CMSession,CMMain,CMPart,CMNet,CMP+ portal CMMain,CMKube,CMGui,CMJob,CMPart,CMMon,CMSession power CMDevice,CMStatus,CMMain,CMJob prs CMDevice,CMMon,CMJob readonly CMKube,CMEtcd,CMDevice,CMStatus,CMNet,CMPart,CMMon,CMJob,C+
Check if the certificate and key are present for the
autonomous-hardware-recoveryprofile. The certificate and key should be present in/cm/local/apps/autonomous-hardware-recovery/etc/asautonomous-hardware-recovery.pemandautonomous-hardware-recovery.key. If the certificate and key are missing, generate them using the command below:root@basecm10:~# cmsh [basecm10]% cert [basecm10->cert]% help createcertificate Name: createcertificate - Create a new certificate Usage: createcertificate <key-length> <common-name> <organization> <organizational-unit> <locality> <state> <country> <profile> <sys-login> <days> <key-file> <cert-file> Arguments: key-file Path to key file that will be generated cert-file Path to pem file that will be generated root@maple:~# cmsh [maple]% cert [maple->cert]% createcertificate 2048 AHR "" "" "" "" US autonomous-hardware-recovery "" 36500 /cm/local/apps/autonomous-hardware-recovery/etc/autonomous-hardware-recovery.key /cm/local/apps/autonomous-hardware-recovery/etc/autonomous-hardware-recovery.pem
Update the tokens associated with the
autonomous-hardware-recoveryprofile: The following token permissions should be present in theautonomous-hardware-recoveryprofile:GET_NVDOMAIN_INFO_TOKEN
GET_SYSINFO_COLLECTOR_TOKEN
GET_NETWORK_TOPOLOGY_TOKEN
GET_DEVICE_TOKEN
GET_GROUP_TOKEN
GET_RACK_TOKEN
[root@ts-tr-multiarch ~]# cmsh [ts-tr-multiarch]% profile [ts-tr-multiarch->profile]% use autonomous-hardware-recovery [ts-tr-multiarch->profile[autonomous-hardware-recovery]]% get tokens GET_DEVICE_TOKEN GET_RACK_TOKEN [ts-tr-multiarch->profile[autonomous-hardware-recovery]]% append tokens GET_NVDOMAIN_INFO_TOKEN [ts-tr-multiarch->profile*[autonomous-hardware-recovery*]]% append tokens GET_SYSINFO_COLLECTOR_TOKEN [ts-tr-multiarch->profile*[autonomous-hardware-recovery*]]% append tokens GET_NETWORK_TOPOLOGY_TOKEN [ts-tr-multiarch->profile*[autonomous-hardware-recovery*]]% append tokens GET_GROUP_TOKEN [ts-tr-multiarch->profile*[autonomous-hardware-recovery*]]% commit
Setup Certificates and endpoint DNS resolution
Using the certificates that were obtained from the Prerequisites section of this document, run the following to create K8s secrets for the certificates
kubectl create secret tls shoreline-api-certificate \ --namespace=autonomous-hardware-recovery \ --cert=ahr.crt \ --key=ahr.key \ --kubeconfig /root/.kube/config-k8s-admin kubectl create secret tls shoreline-app-certificate \ --namespace=autonomous-hardware-recovery \ --cert=ahr.crt \ --key=ahr.key \ --kubeconfig /root/.kube/config-k8s-admin kubectl create secret tls shoreline-discovery-certificate \ --namespace=autonomous-hardware-recovery \ --cert=ahr.crt \ --key=ahr.key \ --kubeconfig /root/.kube/config-k8s-admin kubectl create secret tls shoreline-ceph-certificate \ --namespace=autonomous-hardware-recovery \ --cert=ahr.crt \ --key=ahr.key \ --kubeconfig /root/.kube/config-k8s-admin
Resolve NVIDIA Mission Control autonomous hardware recovery endpoints
Option 1: customized public dns server (e.g. route53) - for these 5 NVIDIA Mission Control autonomous hardware recovery endpoints, follow the instructions in the Prerequisites section of this document.
Option 2: local dns server - bind9
Ensure the bind9 configuration is correct
grep -Fxq "include \"/etc/bind/named.conf.include\";" /etc/bind/named.conf || echo "include \"/etc/bind/named.conf.include\";" >> /etc/bind/named.conf
Create DNS A records for each NVIDIA Mission Control autonomous hardware recovery endpoints. Make sure to replace <bcm_headnode_external_ip> with the correct value
export EXTERNAL_IP=<bcm_headnode_external_ip> export INTERNAL_IP=$(kubectl --kubeconfig /root/.kube/config-k8s-admin get nodes -l node-role.kubernetes.io/control-plane -o jsonpath="{range .items[*]}{.metadata.name}{'\t'}{.status.addresses[?(@.type=='InternalIP')].address}{'\n'}{end}" | awk '{print $2}')
then run the following command as is:
cat << 'EOT' >> /etc/bind/named.conf.include zone "shoreline.nvidia.com" { type master; file "/etc/bind/shoreline.zone"; }; EOT cat << EOT > /etc/bind/shoreline.zone \$TTL 86400 @ IN SOA ns.shoreline.nvidia.com. admin.shoreline.nvidia.com. ( 2024053001 ; Serial 3600 ; Refresh 1800 ; Retry 604800 ; Expire 86400 ) ; Minimum TTL ; @ IN NS ns.shoreline.nvidia.com. ns IN A $EXTERNAL_IP missioncollege IN A $EXTERNAL_IP api.missioncollege IN A $EXTERNAL_IP ceph.missioncollege IN A $INTERNAL_IP discovery.missioncollege IN A $INTERNAL_IP agent-gateway.missioncollege IN A $INTERNAL_IP EOT systemctl restart bind9
A dedicated disk should already be created on the machine for Ceph, but on the off-chance that it isn’t, run the BCM Control Plane Disk Setup to create one
Create the values.yaml
Set the following environment variables in your environment *Please substitute correct values for each of the following
AHR_BACKEND_NODE- worker node name where NVIDIA Mission Control autonomous hardware recovery backend will be installedAHR_FAILOVER_NODE(optional) - worker node name where NVIDIA Mission Control autonomous hardware recovery secondary/failover node will be installedAHR_OBJECT_STORE_PATH- dedicated disk path without file system for NVIDIA Mission Control autonomous hardware recovery backendAHR_BCM_ADMIN_ACCOUNTS- BCM users allowed to configure AHR access control and integrations (at least one required). Must be a serialized comma separated list of single quoted strings (eg. “[‘accountX’,’accountY’]”)GRAFANA_ENDPOINT- This is the URL that will be used to access the Grafana instance deployed in the NVIDIA Mission Control environment and is where observability resources specific to the autonomous hardware recovery backend will be deployed to (dashboards and alerts). You can obtain the value for this from the team who setup the Prometheus Operator stack in the environment, or if you set the Prometheus Operator stack up yourself, can set this to the bcm headnode’s external ip, prefixed withhttps://and suffixed with/grafana, ex:https://grafana.ahr.nvidia.com/grafanaorhttps://1.1.1.1/grafana.GRAFANA_USER- The user with permissions to provision dashboards and alerts via API to the Grafana instance deployed in the NVIDIA Mission Control environment. This can be obtained from the team who setup the Prometheus Operator stack in the environment, or can retrieve the name of the user with the following command:kubectl --kubeconfig /root/.kube/config-k8s-admin --namespace prometheus get secrets kube-prometheus-stack-grafana -o jsonpath="{.data.admin-user}" | base64 -d ; echoGRAFANA_PASSWORD- The password for the user defined forGRAFANA_USER. This can be obtained from the team who setup the Prometheus Operator stack in the environment, or can retrieve the password for the$GRAFANA_USERuser with the following command:kubectl --kubeconfig /root/.kube/config-k8s-admin --namespace prometheus get secrets kube-prometheus-stack-grafana -o jsonpath="{.data.admin-password}" | base64 -d ; echoAHR_NGC_TOKEN:Internal users: please use the token found here: PrivateBin. This link is only available while connected to the Nvidia corporate network and will provide you with a read-only token for accessing NGC resources.
OEMs and Partners: a temporary private registry (nmc-prod) has been provisioned with access to AHR charts, containers, and resources. Read-only service keys (valid for 6 months) have been issued to existing customers. Please reach out to tzapetis@nvidia.com and dkulkarni@nvidia.com to request your service key.
export AHR_BACKEND_NODE=node001 export AHR_FAILOVER_NODE=node002 # only include this line if you are installing the environment with failover enabled export AHR_OBJECT_STORE_PATH=/dev/vdc export GRAFANA_ENDPOINT=https://10.3.192.171/grafana export GRAFANA_USER="admin" export GRAFANA_PASSWORD="xxxxx" export AHR_BCM_ADMIN_ACCOUNTS="['<bcm_user>']" export AHR_NGC_TOKEN=nvapi-XXXXXXX export AHR_PLATFORM_VER=release-28.4.107 export AHR_UI_VER=stable-28.4.26 export AHR_HELM_VER=28.4.107
Substitute the env vars for the values.yaml
If you don’t need to setup the observability stack for monitoring your autonomous hardware recovery deployment, please set
data.enable_monitoring: falsein your values.yaml filenote that if you have metalLB setup, please change following two parameters
bcm_headnode_ip: "<your bcm cluster external ip>"enable_lb: true
cat <<EOF > values.yaml global: platform_ver: "$AHR_PLATFORM_VER" ui_ver: "$AHR_UI_VER" customer_id: "$CUST_ID" api_endpoint: "$AHR_API_URL" app_endpoint: "$AHR_APP_URL" discovery_endpoint: "$AHR_DISCOVERY_URL" agent_gateway_endpoint: "$AHR_AGENT_GATEWAY_URL" ceph_endpoint: "$AHR_CEPH_URL" data: imageCredentials: password: "$AHR_NGC_TOKEN" bcm_headnode_ip: "$EXTERNAL_IP" backend_node: "$AHR_BACKEND_NODE" disable_disk_cleanup: true enable_failover: true service_monitor: enable: true namespace: "prometheus" labels: release: "kube-prometheus-stack" # storage requirements object_storage_path: "$AHR_OBJECT_STORE_PATH" object_storage_size: "1500Gi" shared_storage_path: "/mnt/autonomous-hardware-recovery" shared_storage_size: "500Gi" # only include these 3 lines if you are installing the environment with failover enabled backend_node_failover: "$AHR_FAILOVER_NODE" object_storage_path_failover: "$AHR_OBJECT_STORE_PATH" shared_storage_path_failover: "/mnt/autonomous-hardware-recovery" backend: ENABLE_BCM_GPU_DISCOVERY: false ops_tool: BCM_ADMIN_ACCOUNTS: "$AHR_BCM_ADMIN_ACCOUNTS" grafana: deploy_dashboards: true deploy_alerts: true url: "$GRAFANA_ENDPOINT" user: "$GRAFANA_USER" password: "$GRAFANA_PASSWORD" EOF
Install NVIDIA Mission Control autonomous hardware recovery backend with values.yaml
helm repo add shoreline-onprem-backend https://helm.ngc.nvidia.com/nvidian/shoreline --username='$oauthtoken' --password=${AHR_NGC_TOKEN} helm repo update helm install backend shoreline-onprem-backend/shoreline-onprem-backend --values values.yaml --version $AHR_HELM_VER --namespace autonomous-hardware-recovery --kubeconfig /root/.kube/config-k8s-admin
Set the exclude list for the BCM software image.
cmsh -f /dev/stdin <<< 'fspart excludelistsnippets <image of $AHR_BACKEND_NODE> add shoreline set excludelist <shared_storage_path> <shared_storage_path>/* commit'
For example, if the AHR_BACKEND_NODE is
node001and the shared_storage_path is/mnt/autonomous-hardware-recovery, the following steps can be used to get the image of the backend node and update the exclude list of that image.root@aesposito-t-u2404-04-28:~# cmsh [aesposito-t-u2404-04-28]% device [aesposito-t-u2404-04-28->device]% use node001 [aesposito-t-u2404-04-28->device[node001]]% get softwareimage default-image (category:default)
The node has the default-image, so we can configure it as below:
cmsh -f /dev/stdin <<< 'fspart excludelistsnippets /cm/images/default-image add shoreline set excludelist /mnt/autonomous-hardware-recovery /mnt/autonomous-hardware-recovery* commit'
[For bind9 user] in local, run:
EXTERNAL_IPis BCM head node external IP or theshoreline-nginx-serviceip if you have metalLB setupEXTERNAL_IP=10.3.194.72 sudo sh -c "echo \"$EXTERNAL_IP ui.ahr.nvidia.com\" >> /etc/hosts" sudo sh -c "echo \"$EXTERNAL_IP api.ahr.nvidia.com\" >> /etc/hosts" sudo sh -c "echo \"$EXTERNAL_IP ceph.ahr.nvidia.com\" >> /etc/hosts"
[Only if using self-signed certificate] Complete the post-install backend configuration steps.
Setup the BCM Connectivity integration
Note - integration configuration must happen before agent installation and requires
Administerpermission (set by default viaAHR_BCM_ADMIN_ACCOUNTSduring backend install)Login into the UI as a user with the
Administerrole.From the left menu bar, select “Integrations”.
Click the “Configure” button within the “BCM Connectivity” tile.
On the BCM Connectivity configuration page:
Enter a name for the integration (e.g., bcm_connectivity_configuration).
Set the “API certificate” field to the content of
/cm/local/apps/autonomous-hardware-recovery/etc/autonomous-hardware-recovery.pemfile (cat /cm/local/apps/autonomous-hardware-recovery/etc/autonomous-hardware-recovery.pemcan be run on BCM headnode to view the contents of the file).Set the “API key” field to the content of
/cm/local/apps/autonomous-hardware-recovery/etc/autonomous-hardware-recovery.keyfile (cat /cm/local/apps/autonomous-hardware-recovery/etc/autonomous-hardware-recovery.keycan be run on BCM headnode to view the content of the file).Click the “Apply” button on the top right.
To check the BCM Connectivity integration health, a user with the
Administerpermission should click on the “Test” button on the top right.
Now you should be able to access the NVIDIA Mission Control autonomous hardware recovery UI in the browser!
Agent Install#
NVIDIA Mission Control autonomous hardware recovery agents need to be installed on 2 types of node - BCM headnode, and BCM compute nodes
Installation on headnode#
On BCM head nodes, NVIDIA Mission Control autonomous hardware recovery agents will be directly installed. Here we will create a NVIDIA Mission Control autonomous hardware recovery agent config and run a NVIDIA Mission Control autonomous hardware recovery install script.
Get agent secret from backend pod and set
CUSTOMER_ID,AHR_DISCOVERY_URL, andAHR_NGC_TOKENexport AHR_AGENT_SECRET=$(kubectl --kubeconfig /root/.kube/config-k8s-admin exec -it -n autonomous-hardware-recovery shorelinebackend-0 -c ops-tool -- cat /mnt/ops-tool-data/agent_secret | tr -d '\r') export CUSTOMER_ID=$(kubectl --kubeconfig /root/.kube/config-k8s-admin get configmap shoreline-variables -n autonomous-hardware-recovery -o jsonpath="{.data.CUSTOMER_ID}") export AHR_DISCOVERY_URL=$(kubectl --kubeconfig /root/.kube/config-k8s-admin get configmap shoreline-variables -n autonomous-hardware-recovery -o jsonpath="{.data.DISCOVERY_ENDPOINT}") export AHR_NGC_TOKEN=nvapi-xxxxx
For setting
AHR_NGC_TOKEN:Internal users: please use the token found here: PrivateBin. This link is only available while connected to the Nvidia corporate network and will provide you with a read-only token for accessing NGC resources.
OEMs and Partners: a temporary private registry (nmc-prod) has been provisioned with access to AHR charts, containers, and resources. Read-only service keys (valid for 6 months) have been issued to existing customers. Please reach out to tzapetis@nvidia.com and dkulkarni@nvidia.com to request your service key.
Create agent.config
cat <<EOF > agent.config ### Agent Information AGENT_VERSION=28.4.107 BACKEND_ADDRESS=$AHR_DISCOVERY_URL:443 SECRET=$AHR_AGENT_SECRET CUSTOMER_ID=$CUSTOMER_ID ### Enroot Configuration USE_ENROOT=1 FORCE_ON_PREM=true ALLOW_SUDO=true ### NVCR PKG_PATH_D="https://api.ngc.nvidia.com/v2/org/nvidian/team/shoreline/resources/shoreline_vm_package_distro/versions" SHORELINE_PKG_DEB="\${PKG_PATH_D}/\${AGENT_VERSION}-enroot/files/shoreline_\${AGENT_VERSION}-enroot.deb" PKG_CURL_CMD="-L -H 'Authorization: Bearer \${AHR_NGC_TOKEN}'" AGENT_IMAGE=nvidian/shoreline/agent AGENT_REGISTRY=nvcr.io DOCKER_USERNAME=\\\$oauthtoken DOCKER_TOKEN='$AHR_NGC_TOKEN' ### OTHER Config AGENT_MOUNT_ON_PREM=true AGENT_NAME_SCRIPT=/usr/lib/shoreline/bcmAgentName.sh MAX_ALARM_QUERY_WORKERS=10 REGISTRATION_BACKOFF_INITIAL_DELAY=30000 REGISTRATION_BACKOFF_MAX_DELAY=900000 AGENT_MEMORY_LIMIT=5G AGENT_USER_HOME_DIR=/shoreline NODE_IP=127.0.0.1 AGENT_UID=555 AGENT_GID=556 SYSTEM_USER_NAME=NVIDIA PERMISSIONS_USER_NAME=NVIDIA SYSTEM_OPERATION_SOURCE=SYSTEM EOF
Install NVIDIA Mission Control autonomous hardware recovery agent
root@headnode:~# curl -LO 'https://api.ngc.nvidia.com/v2/org/nvidian/team/shoreline/resources/shoreline_vm_agent_installer/versions/28.4.107/files/vm_base_install.sh' -H "Authorization: Bearer $AHR_NGC_TOKEN" && chmod +x vm_base_install.sh && ./vm_base_install.sh root@headnode:~# systemctl daemon-reload root@headnode:~# systemctl start shoreline
[Only if using self-signed certificate] Complete the post-install agent configuration steps.
Installation on GPU nodes - in BCM software image#
On BCM compute nodes, NVIDIA Mission Control autonomous hardware recovery agents will be installed as part of BCM software image. Here we will set some exclude lists for NVIDIA Mission Control autonomous hardware recovery agent, and let BCM to monitor/start NVIDIA Mission Control autonomous hardware recovery agent service, create a NVIDIA Mission Control autonomous hardware recovery agent config and run a NVIDIA Mission Control autonomous hardware recovery install script in the BCM software image, and sync to the whole subset of the compute nodes sharing that software image.
For generic purpose, this guide will use default category and default-image software image for BCM worker nodes. Please change the category and software image name based on the actual installation scenarios
Set the exclude list for BCM software image
root@headnode:~# cmsh [headnode]% category use default [headnode->category[default]]% set excludelistupdate ### add following directories ### # shoreline - /var/lib/shoreline/agent/databases/* - /var/lib/shoreline/agent/onprem/* - /var/lib/shoreline/agent/secrets/* - /var/lib/shoreline/agent/scraper.yml - /var/lib/shoreline/enroot-cache/* - /var/lib/shoreline/enroot-data/* - /etc/shoreline/agent_ssh/* - /run/shoreline/* - /shoreline/scripts/slurm/* - /shoreline/.config/enroot/* - /cm/local/apps/slurm/var/prologs/60-prolog-ahr.sh - /cm/local/apps/slurm/var/epilogs/60-epilog-ahr.sh no-new-files: - /var/lib/shoreline/agent/databases/* no-new-files: - /var/lib/shoreline/agent/onprem/* no-new-files: - /var/lib/shoreline/agent/secrets/* no-new-files: - /var/lib/shoreline/agent/scraper.yml no-new-files: - /var/lib/shoreline/enroot-cache/* no-new-files: - /var/lib/shoreline/enroot-data/* no-new-files: - /etc/shoreline/agent_ssh/* no-new-files: - /run/shoreline/* no-new-files: - /shoreline/scripts/slurm/* no-new-files: - /shoreline/.config/enroot/* no-new-files: - /cm/local/apps/slurm/var/prologs/60-prolog-ahr.sh no-new-files: - /cm/local/apps/slurm/var/epilogs/60-epilog-ahr.sh [headnode->category*[default*]]% set excludelistfullinstall ### add same above directories ### [headnode->category*[default*]]% set excludelistsyncinstall ### add same above directories ### [headnode->category*[default*]]% set excludelistgrabnew ### add same above directories ### [headnode->category*[default*]]% set excludelistgrab ### add same above directories ### [headnode->category*[default*]]% commit [headnode->category[default]]% exit
Add NVIDIA Mission Control autonomous hardware recovery as monitored service in BCM
root@headnode:~# cmsh [headnode]% category use default [headnode->category[default]]% services [headnode->category[default]->services]% add shoreline [headnode->category[default]->services*[shoreline*]]% set monitored yes [headnode->category[default]->services*[shoreline*]]% set autostart yes [headnode->category[default]->services*[shoreline*]]% commit [headnode->category[default]->services[shoreline]]% exit
Install NVIDIA Mission Control autonomous hardware recovery agent in software image
root@headnode:~# cp agent.config /cm/images/<agent-node-software-image-name>/root root@headnode:~# systemd-nspawn --chdir=/root --setenv=SUDO_CMD="sudo -h 127.0.0.1" -D /cm/images/<agent-node-software-image-name> root@default-image:~# bash -c "mount -o remount,size=10G /tmp" root@default-image:~# curl -LO 'https://api.ngc.nvidia.com/v2/org/nvidian/team/shoreline/resources/shoreline_vm_agent_installer/versions/28.4.107/files/vm_base_install.sh' -H "Authorization: Bearer $AHR_NGC_TOKEN" && chmod +x vm_base_install.sh && ./vm_base_install.sh root@default-image:~# exit
sync the image to worker nodes
root@headnode:~# cmsh [headnode]% device [headnode->device]% imageupdate -w -c default
Agent User Permissions#
As a best practice, we recommend configuring the Autonomous Hardware Recovery Agent user with only the minimum permissions required for the commands the agent will be executing.
NVIDIA Mission Control autonomous hardware recovery Failover#
Overview#
Mission Control provides the option to run AHR in failover mode if an extra node for the installation is available. In this configuration, AHR is installed on two nodes — a primary and a secondary — with data replicating between the two to ensure data synchronization. This setup allows for transition to the secondary node in the event of hardware issues on the primary node, ensuring that AHR functionality can continue with minimal interruption.
When to Initiate a Failover to the Secondary Node#
If a node becomes unhealthy due to a hardware issue that requires significant time to repair (e.g., disk failure, physical server issues), users can initiate a failover of AHR to the secondary node to allow for continued operation of AHR functionality.
Failover Procedure - Promote Secondary Node to Primary#
Promote Secondary Ceph to Primary
kubectl --kubeconfig /root/.kube/config-k8s-admin -n autonomous-hardware-recovery exec -it shorelinebackend-failover-0 -c ceph -- /bin/bash # Run in the ceph container /scripts/ceph-promote.sh exit
Restore data from backup:
kubectl --kubeconfig /root/.kube/config-k8s-admin -n autonomous-hardware-recovery exec -it shorelinebackend-failover-0 -c ops-tool -- /bin/bash # Run in the ops-tool container /scripts/user-promote.sh ### Successful command output should look like the following: # Command succeeded # Successful restore for System Metadata # Customer not found in backend before restore, skipping unassignment # Successful restore for Backend, for customer ID shorelinecust # Successfully assigned customer back to backend after restore exit
Verify database restoration:
kubectl --kubeconfig /root/.kube/config-k8s-admin -n autonomous-hardware-recovery exec -it shorelinebackend-failover-0 -c backend -- bash ls -trl databases/shorelinecust ### expected output - all databases have the timestamp of when user-promote.sh was run exit
Create notebook_run_output folder for the old Runs to properly load:
kubectl --kubeconfig /root/.kube/config-k8s-admin -n autonomous-hardware-recovery exec -it shorelinebackend-failover-0 -c backend -- bash # create notebook_run_output directory mkdir /backend/databases/shorelinecust/notebook_run_output # Update notebook_run dbclient time-partitioned-write shorelinecust notebook_runs "UPDATE notebook_run SET status =12, state = 2 WHERE state NOT IN (2, 3, 10) AND checkpoint_json <> '{}';" exit
Update values.yaml to bring up the failover stateful set as new primary backend:
helm get values --namespace autonomous-hardware-recovery backend --kubeconfig /root/.kube/config-k8s-admin > values-failover.yaml ### Use a text editor to modify this values-failover.yaml file # Change the enable_failover key to false to shut down the broken primary backend enable_failover: false # Add the switch_backend_failover key and set it to true switch_backend_failover: true
Perform helm upgrade using the
values-failover.yamlfile that was created to switch the secondary backend as primary backend and turn down the broken primary backend:helm upgrade backend shoreline-onprem-backend/shoreline-onprem-backend --values values-failover.yaml --version "$(helm --kubeconfig /root/.kube/config-k8s-admin get values -n autonomous-hardware-recovery backend | grep platform_ver | cut -d '-' -f 2)" --namespace autonomous-hardware-recovery --kubeconfig /root/.kube/config-k8s-admin
Verify previous primary backend is shut down:
### Check if the shorelinebackend statefulset disappears from the sts list kubectl get sts -n autonomous-hardware-recovery --kubeconfig /root/.kube/config-k8s-admin ### Expected output should look like: NAME READY AGE shorelinebackend-failover 1/1 104m
Verify UI shows all previous runbook runs and actions are persisted
Retrigger Break-Fix Workflows#
Failover may involve some loss of recent data not backed up to secondary node yet, such as recent runbook outputs and resource tags. After a failover event occurs and the primary backend instance has been failed over to the secondary backend instance, you will want to execute an AHR runbook to ensure maintenance tags are reset, allowing the health check system to re-classify nodes accurately. This allows nodes still requiring break/fix to be promptly detected and returned to maintenance status, triggering the necessary repair workflows.
Ensure the steps under the NVIDIA Mission Control autonomous hardware recovery Runbook Deployment have been completed successfully
In the AHR UI, in the Runbooks section, search for the runbook titled
CLEAR_MAINTENANCE_TAGS:Execute this runbook by clicking the ‘Create Run’ button at the top right and provided the appropriate rack name for the
RACK_NAMEparameter. If left empty, the runbook will be executed against all nodes.
Set Primary Node as the New Secondary Node#
Once the primary node’s issues have been resolved, you will want to add the primary node back to environment as the new secondary/failover node. To do so you will need to update the values.yaml file and run the helm upgrade again:
In values.yaml update enable_failover to true:
enable_failover: true
Run the helm upgrade again to bring up the previous primary backend as secondary
helm upgrade shorelinebackend shoreline-onprem-backend/shoreline-onprem-backend --values values.yaml --version "$(helm --kubeconfig /root/.kube/config-k8s-admin get values -n autonomous-hardware-recovery backend | grep platform_ver | cut -d '-' -f 2)" --namespace autonomous-hardware-recovery --kubeconfig /root/.kube/config-k8s-admin
NVIDIA Mission Control autonomous hardware recovery Uninstall#
Agent Uninstall#
Run the following procedure from the BCM headnode:
Uninstall the AHR agent from each
cmshsoftware image it was installed on:root@headnode:~# systemd-nspawn --chdir=/root --setenv=SUDO_CMD="sudo -h 127.0.0.1" -D /cm/images/<agent-node-software-image-name> root@default-image:~# ./vm_base_install.sh uninstall -c /etc/shoreline/agent.config
You may see the following warning in the script’s output:
System has not been booted with systemd as init system (PID 1). Can't operate. Failed to connect to bus: Host is down
This only occurs when the installer is run from within the software image and can be safely ignored.
Once the agent has been uninstalled, run the following while still in the software image:
rm -rf /var/lib/shoreline rm -rf /etc/sudoers.d/99-shoreline-user rm -rf /cm/local/apps/autonomous-hardware-recovery/etc/agent.config exit
Sync the updated image to the worker nodes
root@headnode:~# cmsh [headnode]% device [headnode->device]% imageupdate -w -c <agent-node-software-image-name> [headnode->device]% exit [headnode]% exit
Uninstall the agent from all available BCM headnodes:
pdsh -g headnode './vm_base_install.sh uninstall -c /etc/shoreline/agent.config' pdsh -g headnode 'rm -rf /var/lib/shoreline' pdsh -g headnode 'rm -rf /etc/sudoers.d/99-shoreline-user' pdsh -g headnode 'rm -rf /cm/local/apps/autonomous-hardware-recovery/etc/agent.config'
Remove the
shoreline-agentrole fromconfigurationoverlayroot@headnode:~# cmsh [headnode]% configurationoverlay [headnode->configurationoverlay]% remove shoreline-agent [headnode->configurationoverlay*]% commit [headnode->configurationoverlay]% exit [headnode]% exit
Backend Uninstall#
Run the following procedure from the BCM headnode:
Get current values for node names and storage paths:
export AHR_BACKEND_NODE=$(helm --kubeconfig /root/.kube/config-k8s-admin get values -n autonomous-hardware-recovery backend --all | grep backend_node: | awk '{print $2}') export AHR_FAILOVER_NODE=$(helm --kubeconfig /root/.kube/config-k8s-admin get values -n autonomous-hardware-recovery backend --all | grep backend_node_failover: | awk '{print $2}') export AHR_SHARED_STORAGE_PATH=$(helm --kubeconfig /root/.kube/config-k8s-admin get values -n autonomous-hardware-recovery backend --all | grep shared_storage_path: | awk '{print $2}') export AHR_OBJECT_STORAGE_PATH=$(helm --kubeconfig /root/.kube/config-k8s-admin get values -n autonomous-hardware-recovery backend --all | grep object_storage_path: | awk '{print $2}') export AHR_FAILOVER_OBJECT_STORAGE_PATH=$(helm --kubeconfig /root/.kube/config-k8s-admin get values -n autonomous-hardware-recovery backend --all | grep object_storage_path_failover: | awk '{print $2}') env | grep AHR
Uninstall the backend helm chart
helm uninstall backend -n autonomous-hardware-recovery --wait --cascade foreground --kubeconfig /root/.kube/config-k8s-admin
Delete all persistent volume claims (pvcs) associated with the AHR backend
kubectl delete pvc --all -n autonomous-hardware-recovery --kubeconfig /root/.kube/config-k8s-admin
Delete persistent volumes associated with the AHR backend
kubectl --kubeconfig /root/.kube/config-k8s-admin delete pv $(kubectl --kubeconfig /root/.kube/config-k8s-admin get pv -o json | jq -r '.items[] | select(.status.phase == "Released") | select(.spec.claimRef.namespace == "autonomous-hardware-recovery" ) | .metadata.name')
Delete the AHR namespace:
kubectl delete ns autonomous-hardware-recovery --kubeconfig /root/.kube/config-k8s-admin
Wipe the disk device used for $AHR_OBJECT_STORAGE_PATH
ssh $AHR_BACKEND_NODE blkdiscard -f $AHR_OBJECT_STORAGE_PATH # Run the following line only if failover was enabled in this environment ssh $AHR_FAILOVER_NODE blkdiscard -f $AHR_FAILOVER_OBJECT_STORAGE_PATH
Clean $AHR_SHARED_STORAGE_PATH on nodes
ssh $AHR_BACKEND_NODE rm -rf $AHR_SHARED_STORAGE_PATH/* # Run the following line only if failover was enabled in this environment ssh $AHR_FAILOVER_NODE rm -rf $AHR_SHARED_STORAGE_PATH/*
Remove the
shorelineBCM user:root@headnode:~# cmsh [headnode]% user [headnode->user]% remove shoreline [headnode->user*]% commit [headnode->user]% exit [headnode]% exit
Remove AHR Runbooks#
Delete the runbooks directory
rm -rf /cm/local/apps/autonomous-hardware-recovery/runbooks
AHR Re-installation#
Make sure to recreate the
autonomous-hardware-recoverynamespace with the specific label to allow container pulls from non-local registries. Run the following command to define the namespace in a file titledahr-namespace.yaml:cat <<EOF > ahr-namespace.yaml apiVersion: v1 kind: Namespace metadata: name: autonomous-hardware-recovery labels: zarf.dev/agent: ignore EOF
then run the following to apply the definition:
kubectl apply -f ahr-namespace.yaml --kubeconfig /root/.kube/config-k8s-admin
Then, you can rerun the installation from the command line with the same configuration as the original installation using the previously generated
cm-mission-control-setup.conffile:cm-mission-control-setup -c cm-mission-control-setup.conf
If you need to change any of the values chosen during the initial installation via the BCM TUI wizard, please reach out to AHR engineering support for assistance.
Backend Setup with a Self-Signed Certificate Guide#
To configure the backend environment to work with a self-signed certificate, follow these steps:
Generate the CA root certificate and the server certificate (signed by the CA).
Install the backend as described earlier in the documentation
Execute the post-installation steps after the backend installation.
Apply the post-installation steps after deploying the agent.
Detailed instructions for each step are provided below.
Generating Self-Signed Certificate#
This guide outlines the procedure for generating a Certificate Authority (CA) and server certificate from scratch.
If an existing Certificate Authority (CA) or intermediate certificates are already available, proceed directly to Step 2 to generate the server certificate.
Generate CA certificate
Generate unencrypted private key:
openssl genrsa -out ca.key 4096
Create
ca.cnf:# ca.cnf [ req ] default_bits = 4096 prompt = no default_md = sha256 x509_extensions = v3_ca distinguished_name = dn [ dn ] C = US ST = California L = Santa Clara O = Shoreline OU = Dev CN = Shoreline Root CA [ v3_ca ] subjectKeyIdentifier = hash authorityKeyIdentifier = keyid:always,issuer basicConstraints = critical, CA:true keyUsage = critical, keyCertSign, cRLSign
Generate self-signed CA cert:
openssl req -x509 -new -key ca.key -out ca.crt -days 3650 -config ca.cnf -extensions v3_ca
Generate the server certificate (requires the CA certificate from Step 1).
Create server.cnf, setting the Common Name (CN) and Subject Alternative Names (SAN) to match your environment:
[ req ] default_bits = 2048 prompt = no default_md = sha256 distinguished_name = dn req_extensions = req_ext [ dn ] C = US ST = CA L = Santa Clara O = Shoreline OU = Dev CN = your-instance.shoreline.nvidia.com [ req_ext ] subjectAltName = @alt_names [ alt_names ] DNS.1 = your-instance.shoreline.nvidia.com DNS.2 = *.your-instance.shoreline.nvidia.com
Create key and CSR
openssl req -new -nodes -out server.csr -newkey rsa:2048 -keyout server.key -config server.cnf
Sign the server CSR with your CA
openssl x509 -req -in server.csr -CA ca.crt -CAkey ca.key -CAcreateserial \ -out server.crt -days 8250 -extensions req_ext -extfile server.cnf
Create full chain and rename
server.keycat server.crt ca.crt > ahr.crt cp server.key ahr.key
To ensure you browser trusts this certificate when viewing the UI after installation, you’ll need to import the self-signed CA certificate generated in Step 1 (
ca.crt) into your local trust store. This is required to enable access to the site (secured with the server certificate) using browsers, curl, and other clients. If this certificate was generated on the bcm headnode, you’ll need to copy over theca.crtfile to your local machine first.To trust the self-signed CA certificate in Firefox, follow these steps:
Open Firefox and go to Preferences (or Options on Windows).
Navigate to Privacy & Security and scroll down to the Certificates section.
Click View Certificates.
In the Certificate Manager window, select the Authorities tab.
Click Import.
Choose your self-signed CA certificate file (e.g.,
ca.crt).When prompted, check “Trust this CA to identify websites”.
Click OK to complete the import.
To trust the self-signed CA certificate in Chrome, follow these steps:
Open Chrome and navigate to
chrome://settings/certificatesUnder Custom, click on Installed by you
Next to Trusted Certificates, click Import
Select the self-signed CA certificate file -
ca.crt
You will need to edit a specific file of the installer to bypass the endpoint readiness check. In a text editor, modify line 37 of
/cm/local/apps/cm-setup/lib/python3.12/site-packages/cmsetup/plugins/autonomous_hardware_recovery/stages/agent.pyfrom:return super().enabled and self.config.get_by_path('plan.agent') in {'install', 'upgrade'}
to
return False
The
ahr.crtandahr.keyfiles generated during this procedure satisfy the certificate prerequisite that can be used during the installation process.
Post-Install Backend Configuration#
After deploying AHR following the installation guide, complete the following steps to configure the AHR backend container to trust the Ceph endpoint when using a self-signed certificate.
Note: These steps should be repeated after every backend upgrade performed through Helm.
Manual Application of the Self-Signed Certificate to the Backend#
Note: If you do not have an existing certificate and key, please refer to the section Generating Self-Signed Certificate to create the required
ahr.crtandahr.keyfiles before proceeding.
Create a ConfigMap with the CA certificate in the backend cluster:
kubectl create configmap -n autonomous-hardware-recovery custom-ca \ --from-file=ca.crt=./ca.crt
Create
backendpatch.json:{ "spec": { "template": { "spec": { "volumes": [ { "emptyDir": {}, "name": "container-deps" }, { "emptyDir": { "sizeLimit": "10Mi" }, "name": "var-run-ceph" }, { "configMap": { "defaultMode": 420, "name": "shoreline-config" }, "name": "shoreline-config" }, { "configMap": { "defaultMode": 493, "name": "shoreline-scripts" }, "name": "shoreline-scripts" }, { "name": "shoreline-app-certificate", "secret": { "defaultMode": 420, "secretName": "shoreline-app-certificate" } }, { "name": "shoreline-api-certificate", "secret": { "defaultMode": 420, "secretName": "shoreline-api-certificate" } }, { "name": "shoreline-discovery-certificate", "secret": { "defaultMode": 420, "secretName": "shoreline-discovery-certificate" } }, { "name": "shoreline-ceph-certificate", "secret": { "defaultMode": 420, "secretName": "shoreline-ceph-certificate" } }, { "name": "custom-ca", "configMap": { "name": "custom-ca" } }, { "name": "ca-bundle", "emptyDir": {} } ], "initContainers": [ { "command": [ "sh", "-c", "[ -f /certificates/ca-key.pem ] || { /scripts/generate_certs.sh ; }; rm -f /mnt/container-deps/*" ], "image": "ubuntu:22.04", "imagePullPolicy": "IfNotPresent", "name": "generate-certs", "resources": {}, "terminationMessagePath": "/dev/termination-log", "terminationMessagePolicy": "File", "volumeMounts": [ { "mountPath": "/certificates", "name": "openbao-certificates" }, { "mountPath": "/scripts", "name": "shoreline-scripts" } ] }, { "name": "ca-bundle-builder", "image": "ubuntu:22.04", "command": [ "sh", "-c", "apt-get update && apt-get install -y ca-certificates && mkdir -p /usr/local/share/ca-certificates && cp /ca/ca.crt /usr/local/share/ca-certificates/custom-ca.crt && update-ca-certificates && cp /etc/ssl/certs/ca-certificates.crt /bundle/ca-certificates.crt" ], "volumeMounts": [ { "name": "custom-ca", "mountPath": "/ca" }, { "name": "ca-bundle", "mountPath": "/bundle" } ] } ] } } } }
Patch backend statefulset with the above file:
kubectl patch statefulset shorelinebackend -n autonomous-hardware-recovery --type='merge' --patch "$(cat backendpatch.json)" # Run the following line only if failover was enabled in this environment kubectl patch statefulset shorelinebackend-failover -n autonomous-hardware-recovery --type='merge' --patch "$(cat backendpatch.json)"
Run another patch to mount
ca-certificates.crt:INDEX=$(kubectl get statefulset shorelinebackend -n autonomous-hardware-recovery -o json \ | jq -r '.spec.template.spec.containers | to_entries[] | select(.value.name=="backend") | .key') kubectl patch statefulset shorelinebackend -n autonomous-hardware-recovery --type='json' -p="[ { \"op\": \"add\", \"path\": \"/spec/template/spec/containers/${INDEX}/volumeMounts/-\", \"value\": { \"name\": \"ca-bundle\", \"mountPath\": \"/etc/ssl/certs/ca-certificates.crt\", \"subPath\": \"ca-certificates.crt\" } } ]" INDEX=$(kubectl get statefulset shorelinebackend-failover -n autonomous-hardware-recovery -o json \ | jq -r '.spec.template.spec.containers | to_entries[] | select(.value.name=="backend") | .key') kubectl patch statefulset shorelinebackend-failover -n autonomous-hardware-recovery --type='json' -p="[ { \"op\": \"add\", \"path\": \"/spec/template/spec/containers/${INDEX}/volumeMounts/-\", \"value\": { \"name\": \"ca-bundle\", \"mountPath\": \"/etc/ssl/certs/ca-certificates.crt\", \"subPath\": \"ca-certificates.crt\" } } ]"
Post-Install Agent Configuration#
After deploying the agent, perform the following steps to enable the agent to trust the discovery endpoint using the self-signed certificate.
Note: These steps must also be repeated after every agent upgrade.
Manual Application of the Self-Signed Certificate on the Agent#
Add CA cert to the local store of all headnodes:
pdcp -g headnode ca.crt /usr/local/share/ca-certificates/self-signed.crt pdsh -g headnode 'update-ca-certificates'
Update the agent start script on all headnodes by adding mount option at line 216 for the
.crtfile in/usr/lib/shoreline/startAgent.sh:pdsh -g headnode "grep -Fq ' --mount \"/etc/ssl/certs/ca-certificates.crt:/etc/ssl/certs/ca-certificates.crt\" \\' /usr/lib/shoreline/startAgent.sh || sed -i '216i \\ --mount \"/etc/ssl/certs/ca-certificates.crt:/etc/ssl/certs/ca-certificates.crt\" \\\\' /usr/lib/shoreline/startAgent.sh"
Reload and restart shoreline service on all headnodes:
pdsh -g headnode "systemctl stop shoreline && systemctl daemon-reload && systemctl start shoreline && journalctl -xeu shoreline"
You will need to perform the following steps for EACH agent category
Copy the
ca.crtfile to the agent image category filesystem.root@headnode:~# cp ca.crt /cm/images/<agent-category>-image/usr/local/share/ca-certificates/self-signed.crt
For example, if the agent category was
default:root@headnode:~# cp ca.crt /cm/images/default-image/usr/local/share/ca-certificates/self-signed.crt
Update the ca certificates and update
startAgent.shin the software image:root@headnode:~# systemd-nspawn --chdir=/root --setenv=SUDO_CMD="sudo -h 127.0.0.1" -D /cm/images/<agent-node-software-image-name> root@default-image:~# bash -c "mount -o remount,size=10G /tmp" root@default-image:~# update-ca-certificates root@default-image:~# grep -q ' --mount "/etc/ssl/certs/ca-certificates.crt:/etc/ssl/certs/ca-certificates.crt" \\' /usr/lib/shoreline/startAgent.sh || sed -i '216i \ --mount "/etc/ssl/certs/ca-certificates.crt:/etc/ssl/certs/ca-certificates.crt" \\' /usr/lib/shoreline/startAgent.sh root@default-image:~# exit
Sync the image to nodes in agent category
root@headnode:~# cmsh [headnode]% device [headnode->device]% imageupdate -w -c <agent-category> [headnode->device]% exit [headnode]% exit
Restart the
shorelineservice on the nodes in the agent category:pdsh -g category=<agent-category> 'systemctl stop shoreline && systemctl daemon-reload && systemctl start shoreline && journalctl -xeu shoreline'
If both the backend and agent have been configured properly, the agent will register successfully on the backend. For instructions on verifying backend health and agent connectivity, you can refer to this guide.
Replacing Certificates in an Existing Environment#
Whether publicly-trusted or self-signed, you can replace the existing certificates of a running backend using the following procedure. The procedure assumes you have already obtained a new, valid cert/key pair from following the process in either the Prerequisites section or the Self-signed Certificate Guide.
Set the locations of your certificate and key files. If they are in your current working directory on the headnode, you would run
path_to_cert="./ahr.crt" path_to_privkey="./ahr.key"
Create a kubernetes resource definition for the base64-encoded versions of the cert and key files
cert_base64=$(sudo cat "${path_to_cert}" | base64 -w 0) privatekey_base64=$(sudo cat "${path_to_privkey}" | base64 -w 0) cat <<EOF > ahr-certificates.yaml apiVersion: v1 kind: Secret metadata: name: shoreline-api-certificate namespace: autonomous-hardware-recovery type: kubernetes.io/tls data: tls.crt: ${cert_base64} tls.key: ${privatekey_base64} --- apiVersion: v1 kind: Secret metadata: name: shoreline-app-certificate namespace: autonomous-hardware-recovery type: kubernetes.io/tls data: tls.crt: ${cert_base64} tls.key: ${privatekey_base64} --- apiVersion: v1 kind: Secret metadata: name: shoreline-discovery-certificate namespace: autonomous-hardware-recovery type: kubernetes.io/tls data: tls.crt: ${cert_base64} tls.key: ${privatekey_base64} --- apiVersion: v1 kind: Secret metadata: name: shoreline-ceph-certificate namespace: autonomous-hardware-recovery type: kubernetes.io/tls data: tls.crt: ${cert_base64} tls.key: ${privatekey_base64} EOF
Apply the new certificates to the cluster. Note that this will overwrite the existing certificates
kubectl --kubeconfig ~/.kube/config-k8s-admin apply -f ahr-certificates.yaml
Restart the nginx process to uptake the new certs without bringing down the AHR backend pod
kubectl --kubeconfig ~/.kube/config-k8s-admin exec -n autonomous-hardware-recovery shorelinebackend-0 -c ui -- kill -HUP 1
You may need to run this command twice to get the process to start using the new certs