Installation Guide for Autonomous Job Recovery#
Introduction#
This guide provides installation instructions for the Autonomous Job Recovery (AJR). AJR is included in the NVIDIA Mission Control “On-Prem” software bundle for DGX SuperPod B200 and DGX SuperPod GB200. AJR is a suite of microservices deployed in a Kubernetes (k8s) cluster, designed to improve AI cluster efficiency by integrating all components of the AI training lifecycle into a unified, automated flow that minimizes downtime. It offers core services tailored to automate both manual and automated recovery processes. AJR autonomously handles most failures in the AI workflow, initiating immediate recovery without input from model engineers. This capability increases automation-driven productivity and enables the scaling of successful AI training practices across current and future generations of AI supercomputers.
Prerequisites#
The following prerequisites for the Autonomous Job Recovery (AJR) are installed by NVIDIA Mission Control using the installation wizard. The following prerequisites are required:
BCM license that allows AJR installation
Kubernetes is deployed and configured with the cm-kubernetes-setup wizard. In addition to Kubernetes, the following configuration changes and additional packages must be applied:
Kyverno is disabled during Kubernetes installation
Prometheus Operator Stack is installed
Prometheus Adapter is installed
Grafana Loki is installed
Grafana Promtail is installed
Disable collection of /var/log logs
Kubernetes Metrics Server is installed
Kubernetes State Metrics is installed
Local Path storage class is enabled with the default NFS-based storage path
Ingress NGINX Controller is installed
Slurm is deployed with the cm-wlm-setup wizard
MySQL is installed on the head node
The NVCR (nvcr.io, NVIDIA container registry) token used to pull the images.
OEMs/Partners: Contact Tim Zapetis (tzapetis@nvidia.com) or Digvijay Kulkarni (dkulkarni@nvidia.com) to request your token.
NVIDIA Professional Services (NVIS): Contact Christiane Pousa Ribeiro (cribiero@nvidia.com) for access token to NGC ‘nmc-prod’ registry.
An example configuration is shown. Some options or packages might look different.
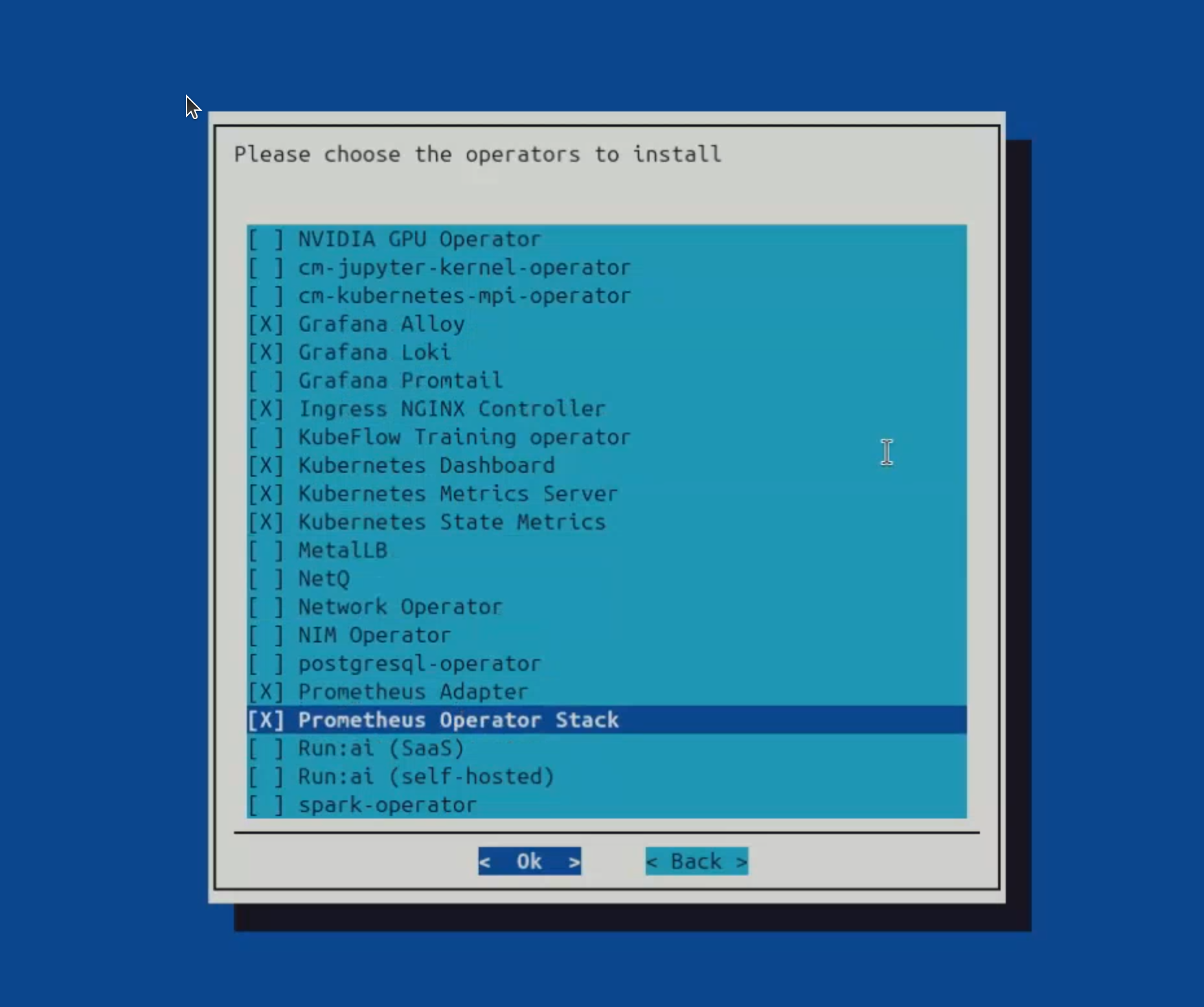
All prerequisites must be installed before you begin the AJR installation.
Before the Autonomous Job Recovery installation#
The following additional steps are required before the AJR installation can begin:
Kubernetes namespace for the Heimdall must be created with a particular label.
- Create a file create-are-namespace.yaml on the active headnode
with the following content:
apiVersion: v1 kind: Namespace metadata: name: heimdall labels: zarf.dev/agent: ignore
Apply this file on the active headnode:
kubectl apply -f create-are-namespace.yaml namespace/heimdall created
Run this command to update the BCM installation wizard script so it allows longer API token to be entered during installation.
sed -i "s/data=token, buffer_length=128/data=token, buffer_length=512/g" /cm/local/apps/cm-setup/lib/python3.12/site-packages/cmsetup/plugins/autonomous_job_recovery/questions/autonomous_hardware_recovery.py
Autonomous Job Recovery Installation#
After all prerequisites are met, start the AJR installation with the cm-mission-control-setup wizard.
We use the wizard to create the cm-mission-control-setup.conf file. Then the file is customized before we do the deployment.
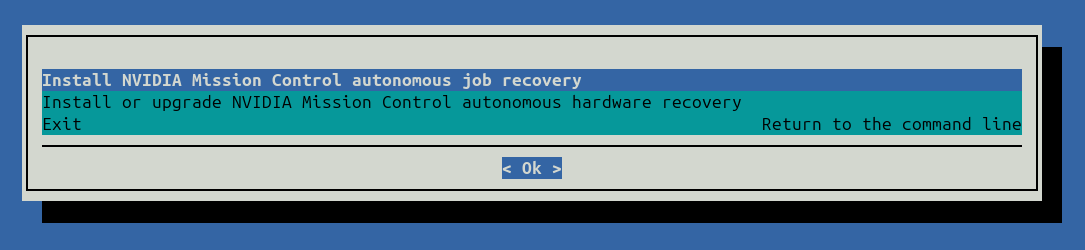
Select Install NVIDIA Mission Control autonomous job recovery when the wizard starts. Some steps may vary depending on the installation wizard version.
AJR requires a MySQL database. By default, the database is installed on the head node. The installation wizard prompts for admin credentials to create the AJR MySQL database and user:

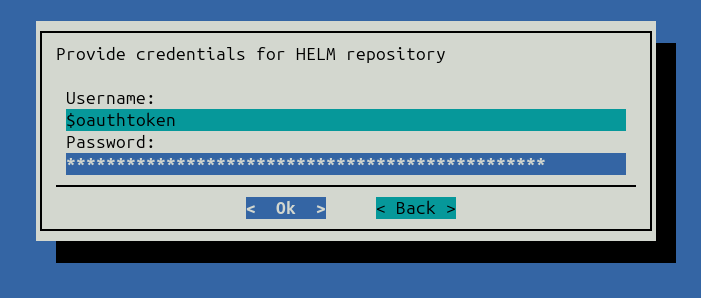
When prompted, provide credentials for the Helm chart repository. You must supply an NVIDIA Container Registry (NVCR) personal access token for the operator and container images.
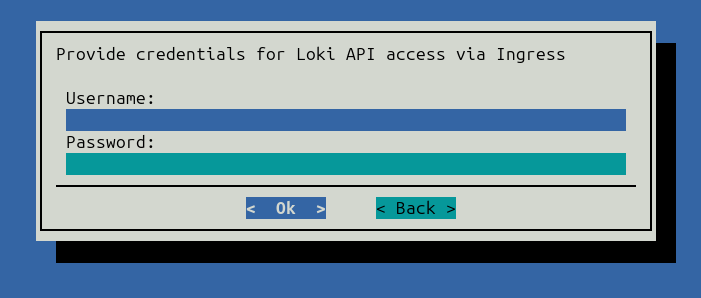
Optionally, provide credentials for the Loki API.
Select the log collection application (currently, only Grafana Promtail is available).
If NVIDIA Mission control autonomous hardware recovery has been installed, the AJR installation wizard will prompt you to enable integration with it. This is optional but enhances capabilities of AJR.
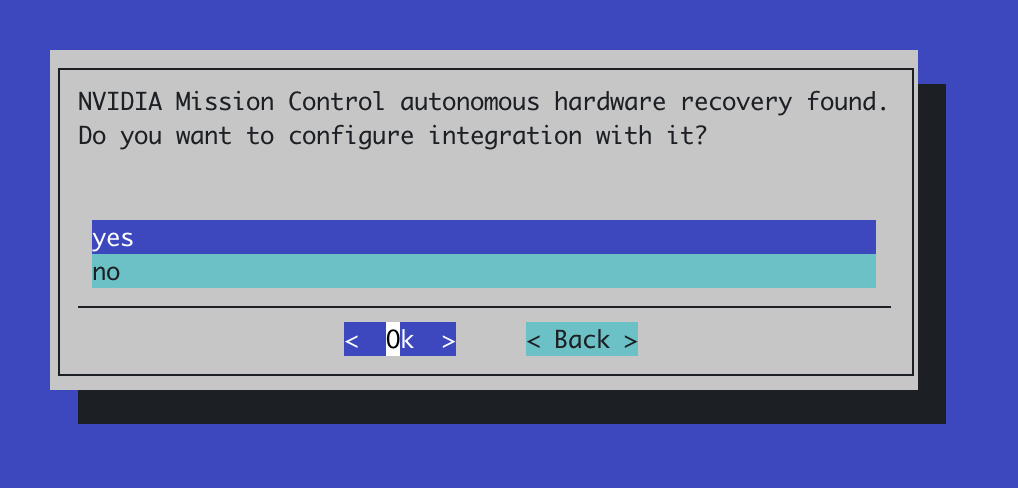
In case if integration is desired, select yes and proceed to the configuration step:
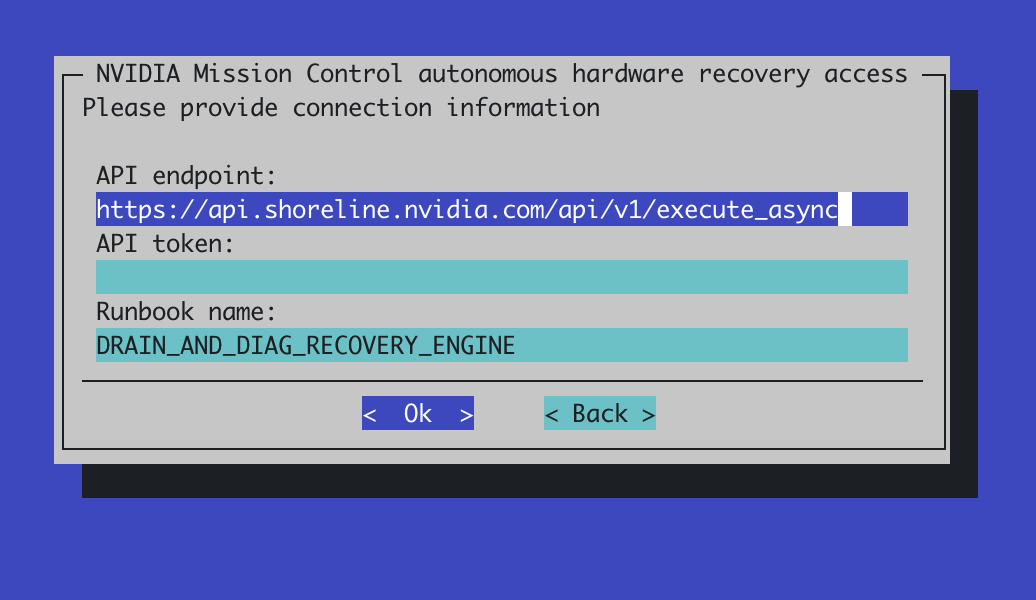
Default values do not need to be changed. Please refer to the NVIDIA Mission Control autonomous hardware recovery documentation for the ways to obtain the API token. Proceed to the next step after the token isentered.
In the next step, select Save config & exit. The installation wizard saves the collected information to the specified file and exits.
Customize the configuration file and deploy AJR#
Assuming the configuration file is cm-mission-control-setup.conf, customize the file to point to the appropriate registry to access AJR helm charts as well as the token for pulling images and the repo.
Find the section ‘autonomous job recovery -> repo’
Then update url of aipot from ‘url: https://helm.ngc.nvidia.com/nvidian/aidot’ to ‘url: https://helm.ngc.nvidia.com/fcypcg1knhby/nmc-prod’
Replace the password in ‘image_pull_secrets -> auths -> nvcr.io -> password’ with the appropriate token.
Find the section ‘autonomous job recovery -> image_pull_secrets’
Replace the password in ‘repo -> credentials -> nvcr.io -> password’ with the appropriate token.
For example, if the configuration file contains:
image_pull_secrets:
- auths:
nvcr.io:
password: bHNrZGpma2xzZGpm
username: $oauthtoken
name: regcred
install_helm: true
kind: autonomous job recovery
repo:
credentials:
password: bHNrZGpma2xzZGpm
username: $oauthtoken
name: aidot
url: https://helm.ngc.nvidia.com/nvidian/aidot
Change it to:
image_pull_secrets:
- auths:
nvcr.io:
password: << MY TOKEN >>
username: $oauthtoken
name: regcred
install_helm: true
kind: autonomous job recovery
repo:
credentials:
password: << MY TOKEN >>
username: $oauthtoken
name: aidot
url: https://helm.ngc.nvidia.com/fcypcg1knhby/nmc-prod
Now, rerun the installation wizard with the command cm-mission-control-setup -c cm-mission-control-setup.conf
After installation completes, verify the installation by accessing the Grafana dashboards, AJR UI and following the steps in the Autonomous Job Recovery Verification Steps section below.
Autonomous Job Recovery post-installation steps#
For the Heimdall efficiency Grafana dashboard to operate correctly, an additional step should be performed.
MySQL user heimdall-kpis-reader must be created
Log in to the MySQL database as a root user and execute the following statements. Replace the password with a random generated one.
mysql> CREATE USER 'heimdall-kpis-reader' IDENTIFIED BY 'password';
Query OK, 0 rows affected (0.02 sec)
mysql> GRANT SELECT ON heimdall.job_efficiency_records TO 'heimdall-kpis-reader';
Query OK, 0 rows affected (0.01 sec)
After the AJR is installed, a new mysql data source has to be created in Grafana using heimdall-kpis-reader username and the password specified above. Without it, the Heimdall efficiency Grafana dashboard will not function properly.
a. To add a new mysql data source, access the Grafana UI which is located at https://headnode_ip_address/grafana URL. Replace the headnode_ip_address with the actual IP address. Refer to the Observability Stack Configuration guide for any Grafana setup details and authorization information.
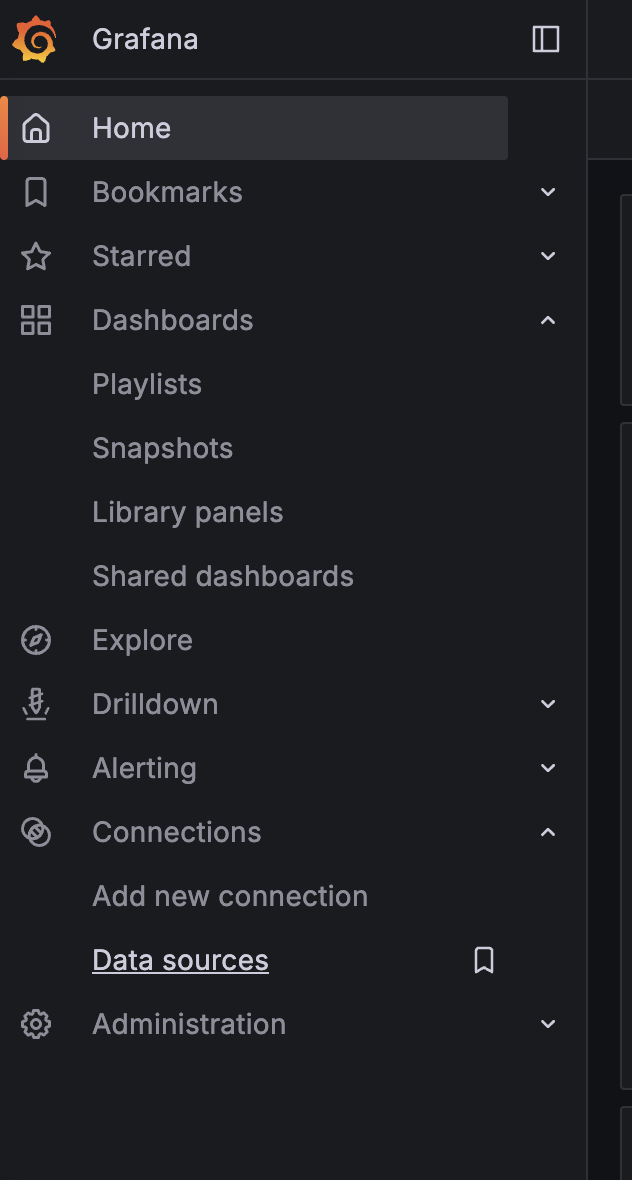
Log in to Grafana and click Data Sources in the Connections section. Select Add new data source and click on MySQL datasource in the SQL section.
On the following screen, configure the following fields:
For the name, use ‘mysql’
For the Host URL, use ‘master:3306’
For the database, enter ‘heimdall’
For the username, use ‘heimdall-kpis-reader’
For the password, use the password specified during the creation of the heimdall-kpis-reader user.
Leave the rest of the fields with the default settings
Click the Save and Test button. A green popup with the “Database connection ok” message should appear.
Autonomous Job Recovery Verification Steps#
These are instructions on how to run a simple sbatch script to verify the basic AJR functionality as a verification test.
The goal here is to verify the AJR deployment works from end to end in a short amount of time.
Sbatch script:
#!/bin/bash
#SBATCH -t 00:05:00
#SBATCH --comment='{"APS": {"auto_resume_mode": "requeue", "max_requeue_times": 1}}'
DATETIME=`date +'date_%y-%m-%d_time_%H-%M-%S'`
echo 'AJR light-weight fault simulation test (auto resume mode: requeue)'
# This srun command sets the output file for the job step. In the job step, it simply sleep for 30s, then print a
# log line that will be recognized by AJR as segment fault, then sleep for another 60s before exiting with 1.
srun --output="$(pwd)/%x_%j_$DATETIME.log" bash -c \
"echo 'Start time: $DATETIME' && echo 'Sleeping 30 seconds' && \
sleep 30 && echo 'Rank0: (1) segmentation fault: artificial segfault' && \
echo 'Sleep another 60 seconds' && \
sleep 60 && exit 1"
Copy the contents of the bash script above and save it into a file in Slurm, e.g.:
bcm_sbatch_test_requeue.sh.Notice that this script specifies the
--commentsection, where theauto_resume_modeis set to berequeueandmax_requeue_timesto be1, which instructs AJR to use requeue to continue the progress. We also use the user level directive to override the max requeue times to be 1 to only allow 1 requeue to happen to reduce the test duration.Submit one job to Slurm with the
sbatchscript, note that you have to specify at least the job name (with -J option) and the partition name (with -p option) since they are not encoded in the script:sbatch -J ajr-verification-requeue-test -p <your_partition_name> bcm_sbatch_test_requeue.sh
The job will be submitted and the job ID will be displayed. Keep note of the job ID.
Monitor the job status using the
squeuecommand.squeue -u <your_user_id>
The log file of the Slurm job step will be created in the same directory where the sbatch script is located after the job starts execution. Since we encode the batch script execution time in the srun output file name, each job attempt will have its own log file. In this case, there will be 2 files created after the whole test is finished.
Check the AJR UI to verify the job attempts are in correct state and with anomaly properly persisted. The AJU UI can be found at https://<FQDN>/mission-control/recovery-engine/dashboard/workflow where <FQDN> is the fully qualified domain name of the headnode.
The sequence should be:
The 1st job attempt is killed due to CRASH anomaly
The same job id is requeued and held to create a new job attempt.
The 2nd job attempt is released for execution.
The 2nd job attempt is killed due to CRASH anomaly
No more requeue because the maximum requeue limit has been reached.
To verify the CRASH anomaly, hover your cursor over the red triangle icon to view status information for the job ID you created in step 2. See figure below for example.

Figure 2 Red triangle indicators (circled) showing hover locations for verification#
Confirm that the expected verification data appears in the tooltip.
Autonomous Job Recovery uninstallation#
AJR uninstallation should be initiated with the cm-mission-control-setup wizard started on the active headnode.
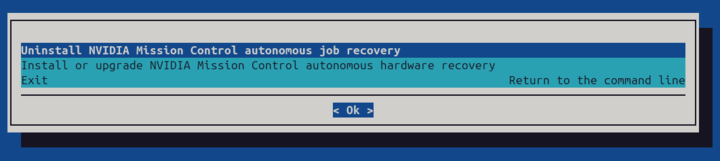
Select Uninstall NVIDIA Mission Control autonomous job recovery.
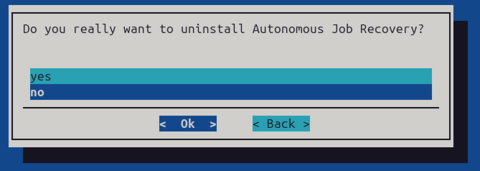
Confirm the uninstallation on the next page. Uninstallation wizard would uninstall AJR and remove the ‘heimdall’ namespace.
Existing data in MySQL database and ‘heimdall-kpis-reader’ MySQL user would not be affected. In case there is a need to perform complete uninstall, log in to MySQL database as root user and perform the following steps:
DROP USER IF EXISTS 'heimdall-kpis-reader'@'%';
DROP USER IF EXISTS 'heimdall_user'@'%';
DROP DATABASE heimdall;
This will remove ‘heimdall-kpis-reader’ and ‘heimdall_user’ MySQL users and related ‘heimdall’ database.