SFT on OpenMathInstruct-2#
This guide explains how to use NeMo RL to run SFT on the nvidia/OpenMathInstruct-2 math instruction tuning dataset. We then show how to use NeMo RL’s evaluation scripts to evaluate the trained model on the MATH-500 benchmark.
Train the Model#
To train the model using NeMo RL, use the examples/configs/sft_openmathinstruct2.yaml config file. This file closely matches the experiment settings in the original OpenMathInstruct-2 paper.
uv run examples/run_sft.py --config=examples/configs/sft_openmathinstruct2.yaml
Dataset Splits#
The OpenMathInstruct-2 has several versions of different sizes. Configure the version of the dataset via the data.split config:
train: full 14 M problem–solution pairstrain_1M,train_2M,train_5M: fair-downsampled subsets of 1M, 2M, or 5M examples
By default, the config uses the 1M subset (data.split=train_1M).
Training Time#
The default config uses 8 GPUs (cluster.gpus_per_node) on 1 node (cluster.num_nodes), which should complete 1 epoch of training for the train_1M dataset (1855 steps) in around 20 hours. Additional nodes can be used to speed up training. We found in our experiments that using 8 nodes, we can complete 1 epoch of training for the train_1M dataset in less than 4 hours.
Evaluate the Model#
Throughout training, the checkpoints of the model will be saved to the results/sft_openmathinstruct2 folder (specified by checkpointing.checkpoint_dir). To evaluate the model, we first need to convert the PyTorch distributed checkpoint to Hugging Face format:
uv run examples/converters/convert_dcp_to_hf.py \
--config=results/sft_openmathinstruct2/step_1855/config.yaml \
--dcp-ckpt-path=results/sft_openmathinstruct2/step_1855/policy/weights \
--hf-ckpt-path=results/sft_openmathinstruct2/step_1855/hf
Replace results/sft_openmathinstruct2/step_1855 with the path to the checkpoint you are evaluating. The resulting Hugging Face checkpoint will be saved to --hf-ckpt-path.
To evaluate on the MATH-500 benchmark, use the following command:
uv run examples/run_eval.py \
--config=examples/configs/evals/eval.yaml \
generation.model_name=results/sft_openmathinstruct2/step_1855/hf \
tokenizer.name=meta-llama/Llama-3.1-8B-Instruct \
data.dataset_name=HuggingFaceH4/MATH-500 \
data.dataset_key=test
Use generation.model_name to specify the path to the Hugging Face checkpoint.
Results#
In this section we present the results of several reference experiments for the train_1M and train versions of the dataset.
train_1M#
Using the above instructions to train a Llama-3.1-8B model for 1 epoch on the train_1M version of the OpenMathInstruct-2 dataset, we get the following loss curve:
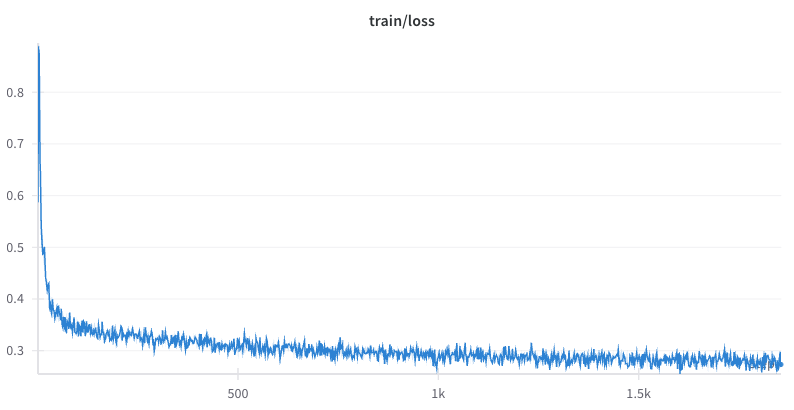
Evaluating the final checkpoint on MATH-500, we get the following result:
============================================================
model_name='hf' dataset_name='MATH-500'
max_new_tokens=2048 temperature=0.0 top_p=1.0 top_k=-1
metric='pass@1' num_tests_per_prompt=1
score=0.5020 (251.0/500)
============================================================
As a reference, using NeMo-Aligner and NeMo-Skills (as is done in the original OpenMathInstruct-2 paper) to train and evaluate the same model on the same dataset achieves the same score of 0.5020 on MATH-500.
train#
We also trained a Llama-3.1-8B model for 1 epoch on the full train version of the OpenMathInstruct-2 dataset. We obtain the following loss curve:
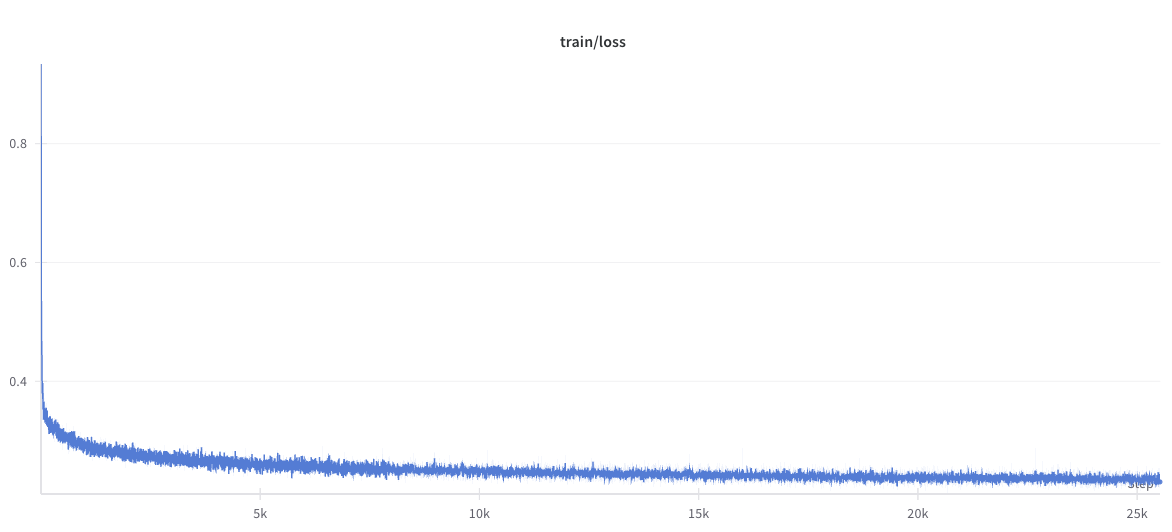
Evaluating the final checkpoint on MATH-500, we get the following result:
============================================================
model_name='hf' dataset_name='MATH-500'
max_new_tokens=2048 temperature=0.0 top_p=1.0 top_k=-1
metric='pass@1' num_tests_per_prompt=1
score=0.6220 (311.0/500)
============================================================
Using NeMo-Aligner and NeMo-Skills to train the model in the same settings achieves a score of 0.6140 (307/500).
As another point of reference, using a checkpoint after 10,000 steps of training using NeMo-RL achieves a score of 0.5800 (290.0/500).