Further Experimentation#
Workflow Agent Model Assignment#
Experiment with the self-hosted endpoint options to utilize other models by adjusting the NIM startup script, or by exercising the local model with other parts of the workflow (Generator, Answer Grader, etc.). Consider how other models perform regarding various chat prompt tasks.
Local Model Compose#
This AI Virtual Workstation Toolkit details how to manually start a local NIM as a workflow Agent model. This method features a local shell script to start the local model. Another method of starting a local model involves a compose file. The compose file is a configuration to start and address a local model for use by AI Workbench or other solutions. The instructions in the next section detail the use of a compose file in AI Workbench.
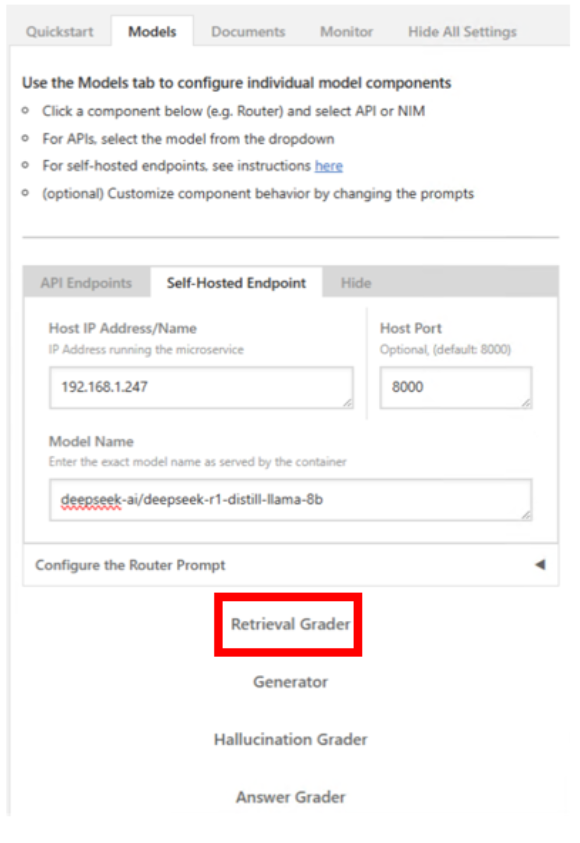
Navigate to the AI Workbench Dashboard->Compose section, select View Compose Settings, and then Edit the compose file.
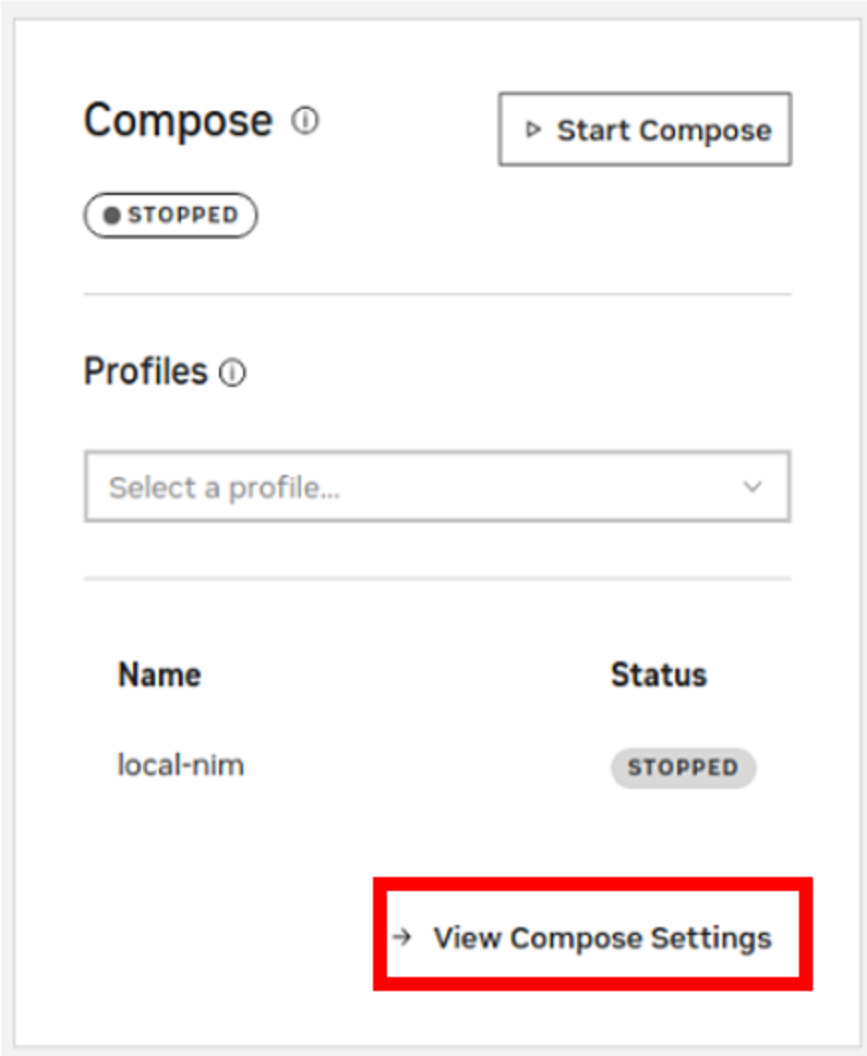
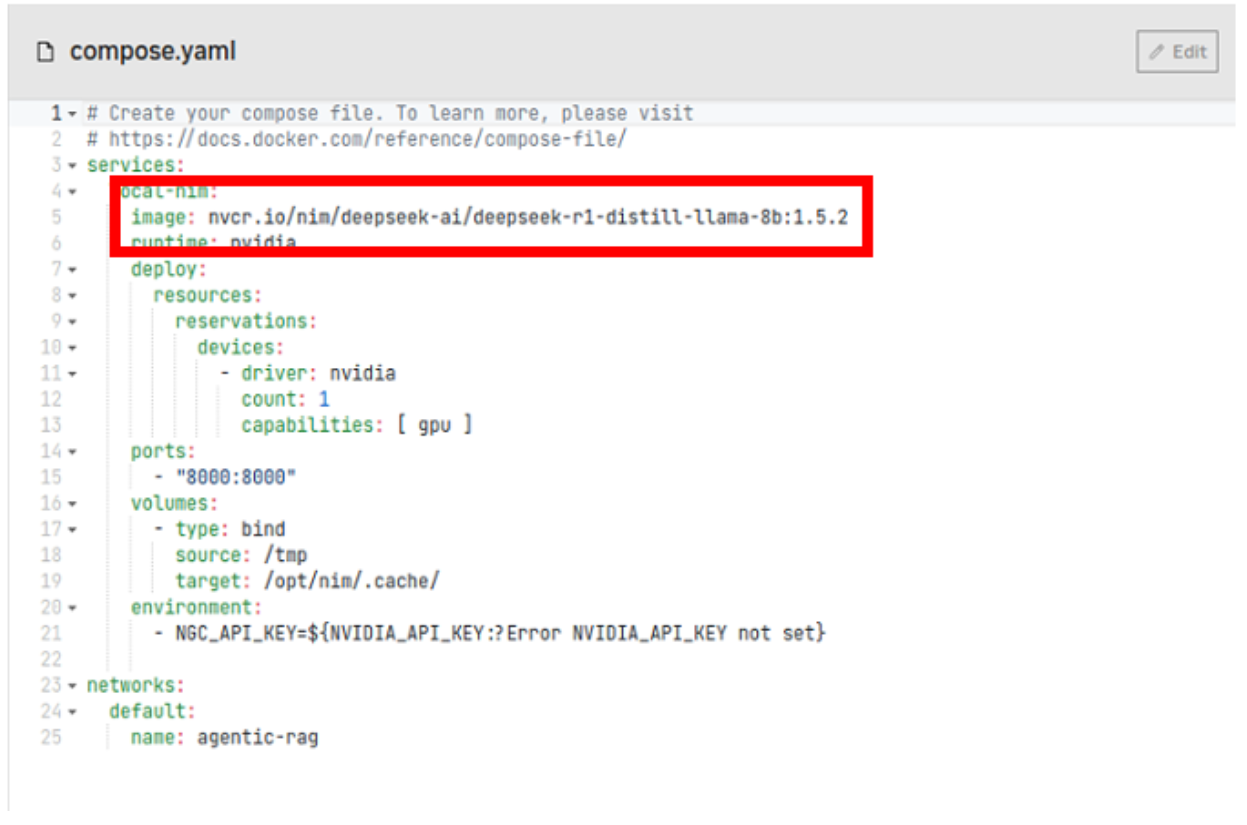
Adjust the compose file to suit the NGC repo and model as required. In this example, the same model is used as shown in the manual example, previously. Adjust and save the compose file when completed.
Start the compose process and monitor the process in the compose status window.
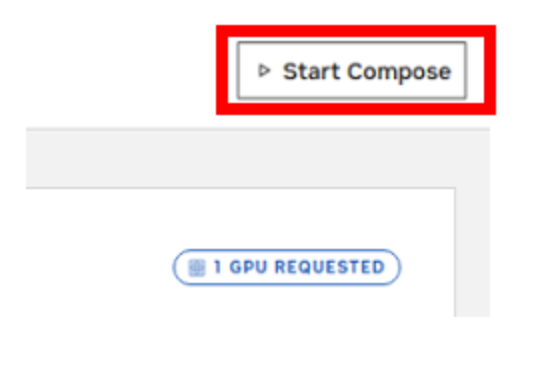
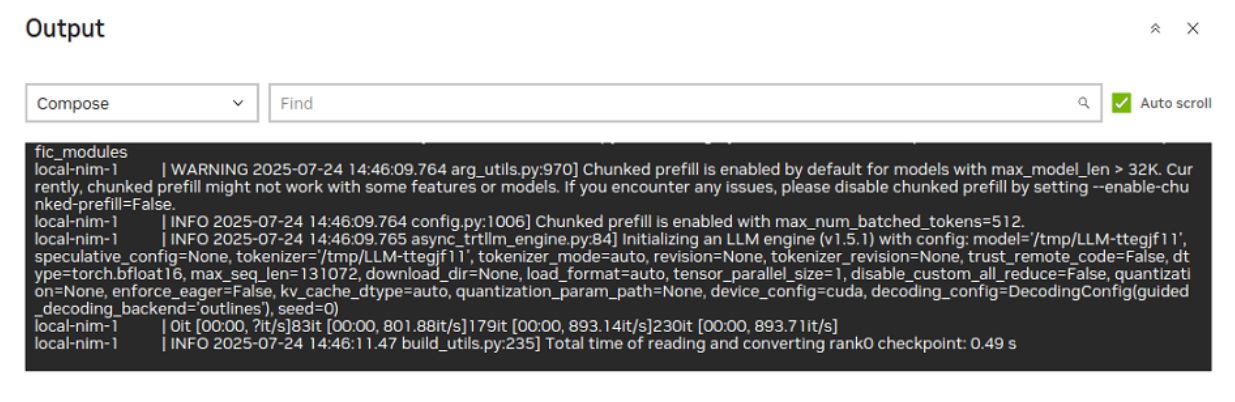
The process will take some time to fully start the model which is packaged as a NIM. Follow the container processes in a console shell. Verify “Application startup complete” in the compose status output.
Use the command
docker psto monitor docker containers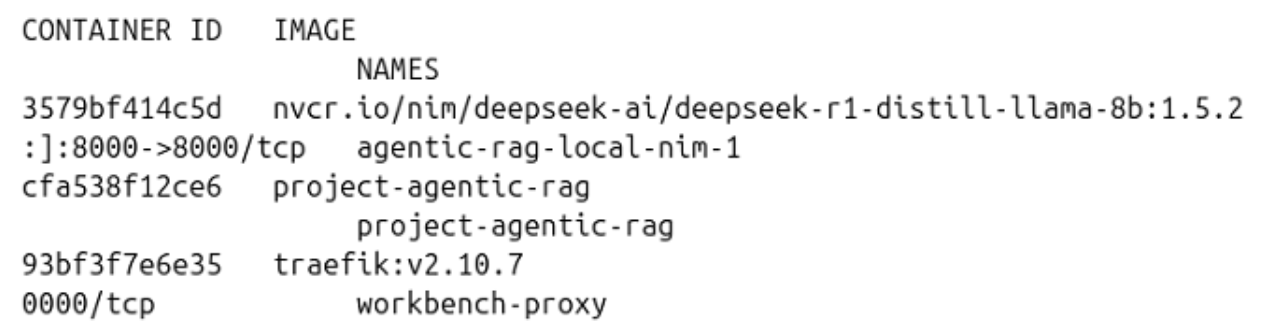
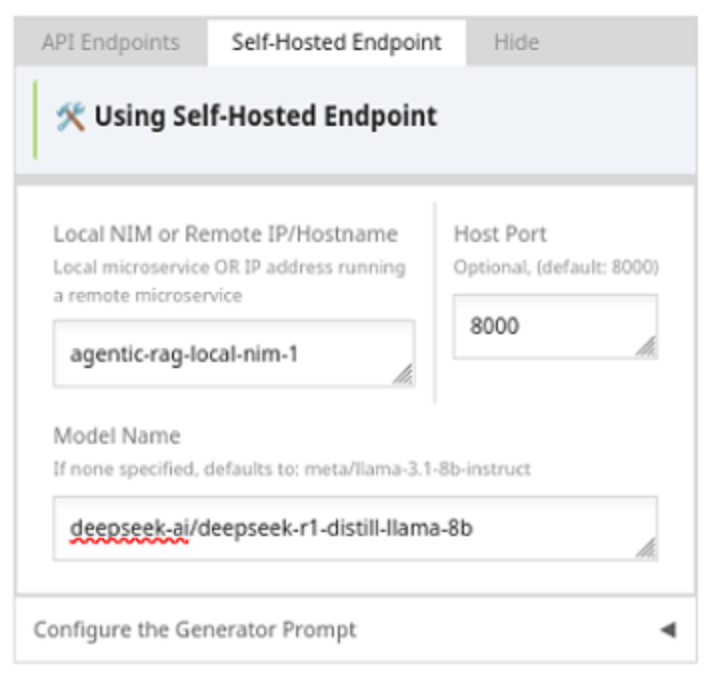
When the NIM is fully running, Open the Chat application and navigate to Models->Self-Hosted Endpoint->Generator. Adjust the Local NIM, Port, and Model name to address the local NIM.
A GPU monitoring tool can help verify the local GPU utilization when issuing a chat prompt. Note the compute and memory utilization when the agent model is processing.
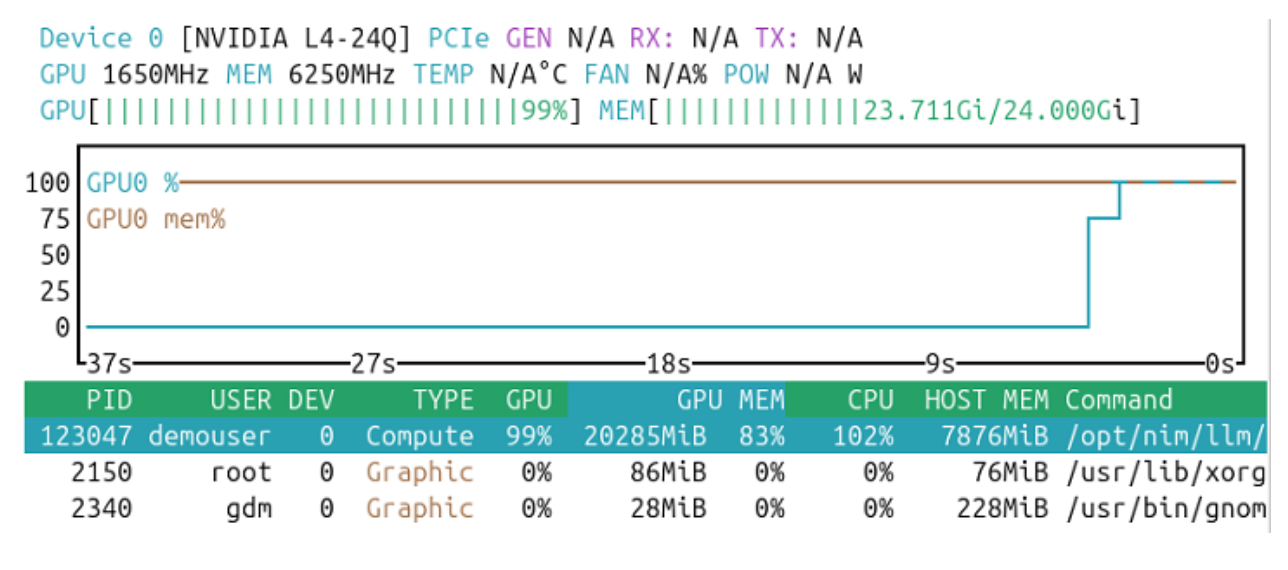
Docker provides a container statistic utility for container utilization monitoring. Note the utilization when the agent model is processing.
docker stats <container ID>
