

Key Abstractions
NeMo Curator introduces core abstractions to organize and scale video curation workflows:
- Pipelines: Ordered sequences of stages forming an end-to-end workflow.
- Stages: Individual processing units that perform a single step (for example, reading, splitting, format conversion, filtering, embedding, captioning, writing).
- Tasks: The unit of data that flows through a pipeline (for video,
VideoTaskholding aVideoand itsClipobjects). - Executors: Components that run pipelines on a backend (Ray) with automatic scaling.
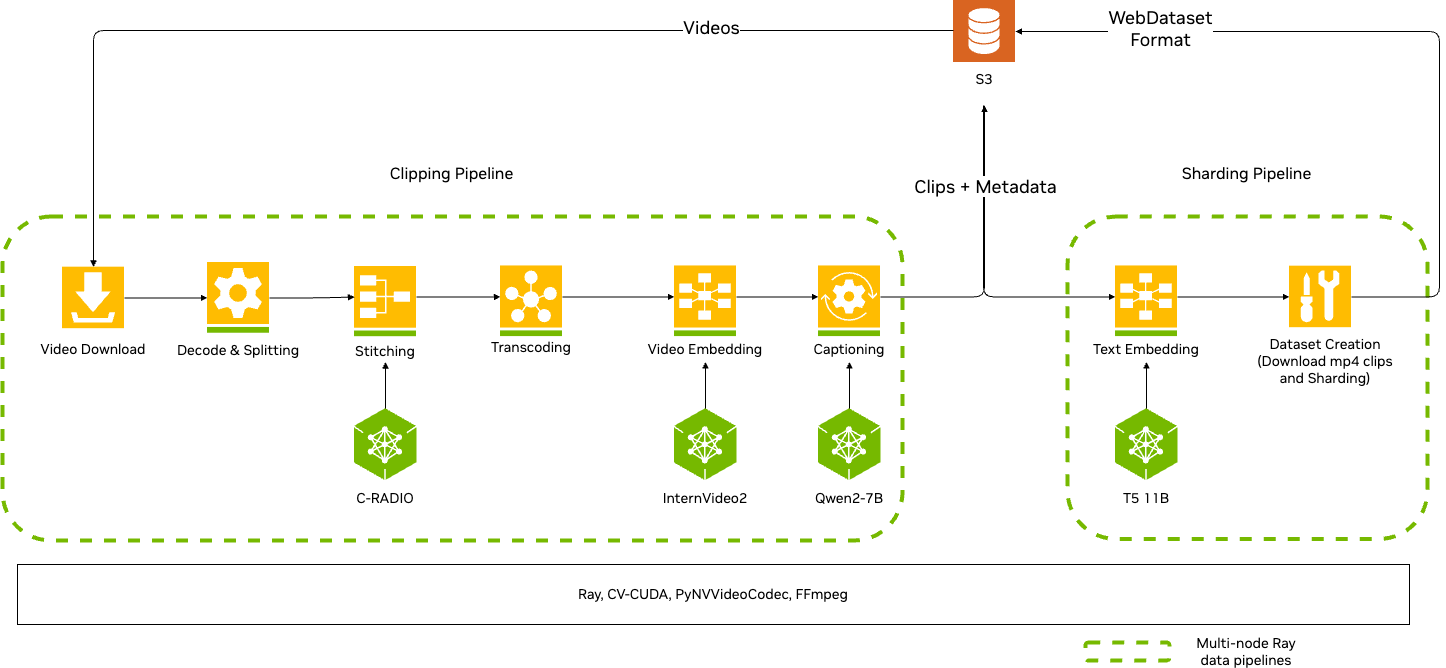
Pipelines
A pipeline orchestrates stages into an end-to-end workflow. Key characteristics:
- Stage Sequence: Stages must follow a logical order where each stage’s output feeds into the next
- Input Configuration: Specifies the data source location
- Stage Configuration: Stages accept their own parameters, including model paths and algorithm settings
- Execution Mode: Supports streaming and batch processing through the executor
Stages
A stage represents a single step in your data curation workflow. Video stages are organized into several functional categories:
- Input/Output: Read video files and write processed outputs to storage (Save & Export Documentation)
- Video Clipping: Split videos into clips using fixed stride or scene-change detection (Video Clipping Documentation)
- Frame Extraction: Extract frames from videos or clips for analysis and embeddings (Frame Extraction Documentation)
- Embedding Generation: Generate clip-level embeddings using Cosmos-Embed1 models (Embeddings Documentation)
- Filtering: Filter clips based on motion analysis and aesthetic quality scores (Filtering Documentation)
- Caption and Preview: Generate captions and preview images from video clips (Captions & Preview Documentation)
- Deduplication: Remove near-duplicate clips using embedding-based clustering (Duplicate Removal Documentation)
Stage Architecture
Each processing stage:
- Inherits from
ProcessingStage - Declares a stable
nameandresources: Resources(CPU cores, GPU memory, or multiple GPUs) - Defines
inputs()/outputs()to document required attributes and produced attributes on tasks - Implements
setup(worker_metadata)for model initialization andprocess(task)to transform tasks
This design enables map-style execution with executor-managed fault tolerance and dynamic scaling per stage. Stages can optionally provide process_batch() to support vectorized batch processing.
Composite stages provide a user-facing convenience API and decompose into one or more execution stages at build time.
Refer to the stage base and resources definitions in Curator for full details.
Resource Semantics
Resources support both fractional and whole‑GPU semantics:
gpu_memory_gb: Request a fraction of a single GPU by memory; Curator rounds to a fractional GPU share and enforces thatgpu_memory_gbstays within one device.gpus: Request one or more GPUs for a stage that is GPU aware.
Choose one of gpu_memory_gb (single‑GPU fractional) or gpus (one or more full GPUs). Combining both is not allowed.
Tasks
Video pipelines operate on task types defined in Curator:
VideoTask: Wraps a single inputVideoVideo: Holds decoded metadata, frames, and lists ofClipClip: Holds buffers, extracted frames, embeddings, and caption windows
Stages transform tasks stage by stage (for example, VideoReader populates Video, splitting stages create Clip objects, embedding and captioning stages annotate clips, and writer stages persist outputs).
Executors
Executors run pipelines on a backend. Curator uses XennaExecutor to translate ProcessingStage definitions into Cosmos-Xenna stage specifications and run them on Ray with automatic scaling. Execution modes include streaming (default) and batch.