An in-depth Walkthrough of DAPO in NeMo RL#
This guide covers the Decoupled Clip and Dynamic Sampling Policy Optimization (DAPO) implementation in NeMo RL.
DAPO introduces four key improvements over Group Relative Policy Optimization (GRPO):
Clip-Higher, which promotes the diversity of the system and avoids entropy collapse
Dynamic Sampling, which improves training efficiency and stability
Token-Level Policy Gradient Loss, which is critical in long-CoT RL scenarios
Overlong Reward Shaping, which reduces reward noise and stabilizes training
This document focuses on DAPO-specific features: Dynamic Sampling and Overlong Reward Shaping. For foundational concepts on GRPO including data handling, policy training, generation, and loss functions, see the NeMo RL GRPO Guide.
Quickstart: Launch a DAPO Run#
To get started quickly, use the example configuration examples/configs/recipes/llm/dapo-qwen2.5-7b.yaml. You can launch this using the same script as GRPO:
uv run examples/run_grpo.py --config examples/configs/recipes/llm/dapo-qwen2.5-7b.yaml {overrides}
Reminder: Don’t forget to set your HF_HOME, WANDB_API_KEY, and HF_DATASETS_CACHE (if needed). You’ll need to do a huggingface-cli login as well for LLaMA models.
Dynamic Sampling#
Standard GRPO trains on all generated responses, even when they have identical rewards (zero gradient signal) within a prompt group of generations. Dynamic sampling filters to keep only groups with diverse rewards (std > 0), and accumulates them across batches until reaching the target batch size. Dynamic sampling can be enabled by setting use_dynamic_sampling=True in your configuration. For implementation details, see the dynamic_sampling function.
Algorithm: For each training step:
Sample
batch_multiplier × num_prompts_per_stepprompts from the dataset. The default value ofbatch_multiplieris 1.Generate
num_generations_per_promptresponses per prompt and compute rewards.Compute the baseline and standard deviation for each prompt group.
Filter prompt groups where
std > 0.Store these prompts in a cache until reaching the target training batch size of
num_prompts_per_step × num_generations_per_promptsamples.Samples are accumulated until the maximum number of allowed batches (
dynamic_sampling_max_gen_batches) is reached. If the cache still does not meet the target rollout batch size at that point, an error is raised. To resolve this, consider adjusting parameters such asnum_prompts_per_stepornum_generations_per_promptto increase sample diversity, or revisit the complexity of your data.Perform training on the collected samples with nonzero standard deviation
About batch_multiplier#
batch_multiplier (a float ≥ 1.0) controls the initial prompt pool size by sampling batch_multiplier × num_prompts_per_step prompts before dynamic sampling. Higher values increase memory and compute requirements, while very low values (e.g., 1.0) may slow the cache accumulation of prompt groups with nonzero standard deviation. The optimal value depends on the dataset, model capacity, and overall training setup. When dynamic sampling is enabled, we also log two additional metrics:
dynamic_sampling_num_gen_batches: The number of generation rounds required to producenum_prompts_per_step * num_generations_per_promptsamples with a nonzero standard deviation. If this number remains consistently high across iterations, try increasing thebatch_multiplier. The maximum allowed value for this parameter is determined bydynamic_sampling_max_gen_batches.dynamic_sampling_num_discarded_valid_samples: The number of samples with a nonzero standard deviation that are discarded because the total exceedsnum_prompts_per_step * num_generations_per_prompt. If this value is frequently high (e.g., above0.5 * num_prompts_per_step * num_generations_per_prompt) anddynamic_sampling_num_gen_batchesis consistently 1, it suggests that a large fraction of the dataset is being discarded unnecessarily. To improve data efficiency, consider decreasing thebatch_multiplier.
Reward Shaping#
DAPO introduces an overlong reward shaping mechanism to reduce reward noise and stabilize training. This approach penalizes responses that exceed a specified length threshold, helping to prevent the model from generating excessively long outputs while maintaining solution quality.
For a detailed explanation of the overlong reward shaping mechanism, please refer to Section 3.4 of the DAPO paper. For implementation details, see the apply_reward_shaping function.
Configuration#
grpo:
use_dynamic_sampling: true # Enable DAPO dynamic sampling
num_prompts_per_step: 512 # Target number of prompts per training step
num_generations_per_prompt: 16 # Generations per prompt
batch_multiplier: 3 # Dataloader batch size = batch_multiplier × num_prompts_per_step
dynamic_sampling_max_gen_batches: 10 # Maximum number of batches to be used for accumulating non-zero std prompts
reward_scaling:
enabled: true
source_min: 0.0
source_max: 1.0
target_min: -1.0
target_max: 1.0
reward_shaping:
enabled: true
overlong_buffer_length: 4096 # Threshold before penalties apply (paper uses 4096)
overlong_buffer_penalty: 1.0 # Penalty per excess token
max_response_length: 20480 # Hard maximum generation length
Key Parameters:
use_dynamic_sampling: When enabled, activates DAPO’s dynamic sampling algorithm to filter and accumulate prompt groups with nonzero standard deviationbatch_multiplier: Factor that scales the initial prompt pool size for sampling.dynamic_sampling_max_gen_batches: Maximum number of batches to be used for accumulating nonzero standard deviation prompts.reward_scaling: When enabled, clamps each reward in the batch to [source_min, source_max] and linearly rescales it to [target_min, target_max]. Defaults: source_min=0.0, source_max=1.0, target_min=0.0, target_max=1.0.reward_shaping: When enabled, applies the overlong penalty mechanism described in the Reward Shaping section above. Responses exceedingmax_response_length - overlong_buffer_lengthreceive penalties proportional to their excess length, helping to reduce reward noise and stabilize training.
Note
When dynamic sampling is enabled, monitor the filtered_reward metric to track the average reward of the prompts with std > 0.
Note
Clip-Higher and Token-Level Policy Gradient Loss are already supported in NeMo RL and can be configured through the loss_fn section of your experiment config:
Set
ratio_clip_maxto enable Clip-Higher (e.g.,ratio_clip_max: 0.28)Set
token_level_loss: trueto enable Token-Level Policy Gradient Loss
See the full DAPO example config for reference.
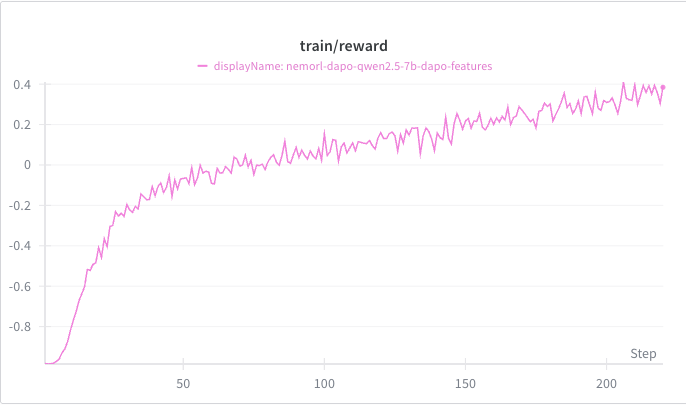
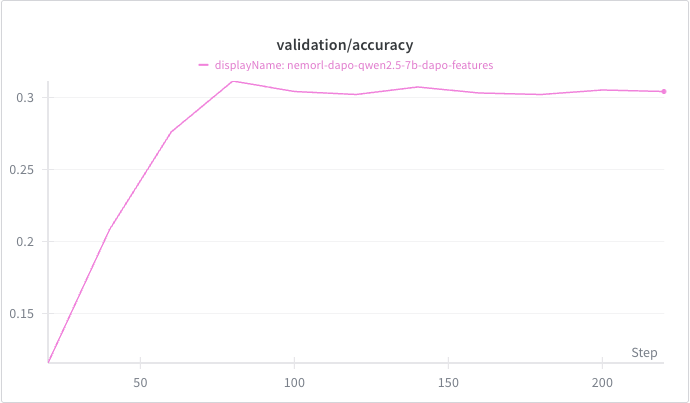
Example Training Results#
Using the DAPO example config, you can expect to see intermediate plots such as the training reward curve and validation accuracy on AIME24 for Qwen/Qwen2.5-Math-7B. These plots serve as reference outputs to help verify reproducibility. They are not intended to reflect the best accuracy that can be achieved using DAPO for this model.