VSS Blueprint Architecture#
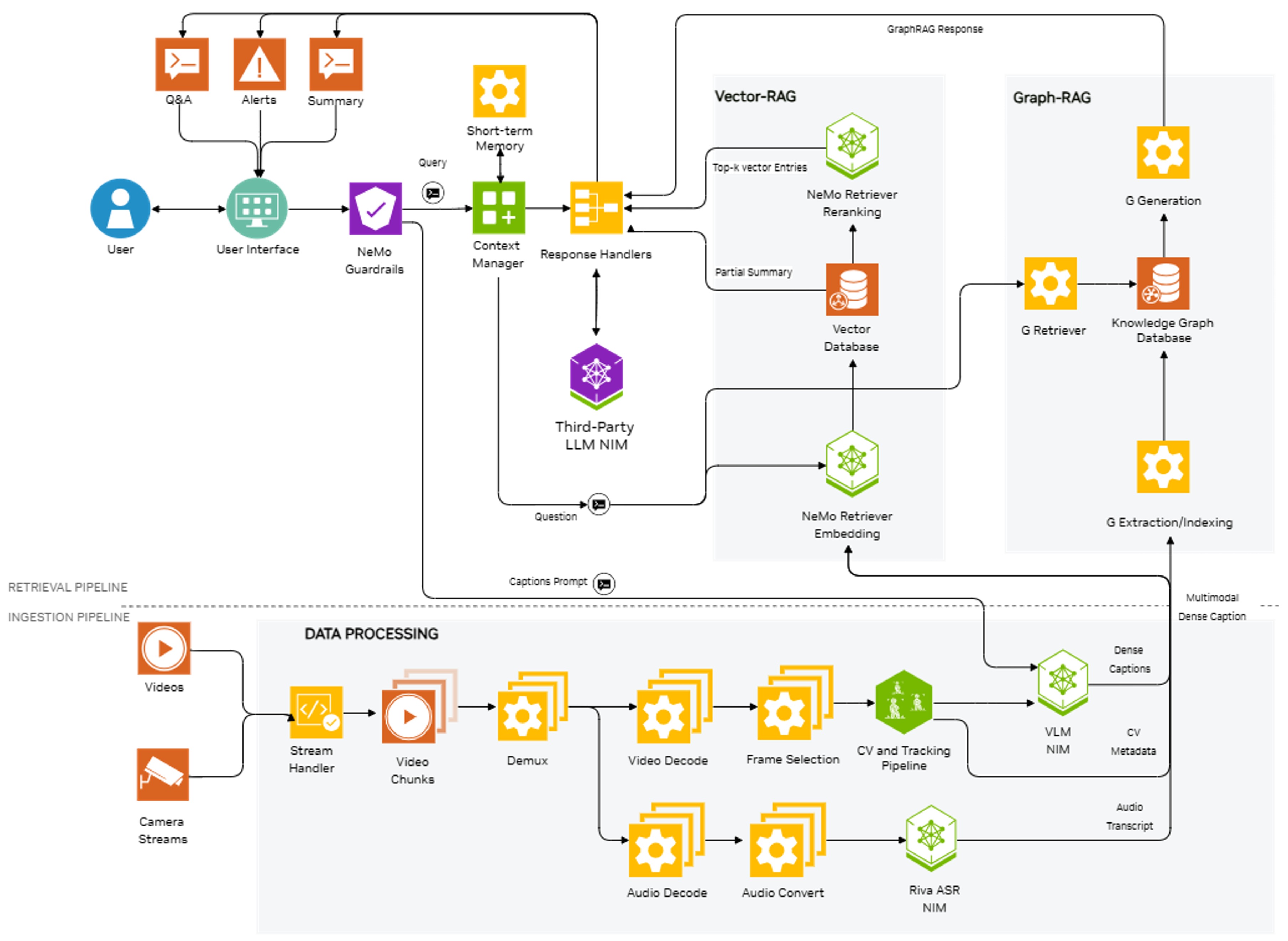
VSS is composed of two main parts:
Ingestion Pipeline: Extract visual insights from the input video in the form of captions and scene descriptions.
Retrieval Pipeline: Visual insights from the ingestion pipeline are further processed, indexed, and used in retrieval tasks like summarization and Q&A.
Ingestion Pipeline#
The ingestion pipeline supports offline and batch processing of video and image files as well as online processing of live streams from cameras.
Video files are processed as small chunks (typically a few seconds or a few minutes, based on model and use case). The chunks represent a small portion of the video file. Processing of individual chunks is distributed across the GPUs in parallel for better performance.
The frames from each chunk are sampled to select a limited number of frames from the entire chunk. For example, 8 frames from a 30-second chunk, which has 900 frames. This depends on the chunk duration and the VLM requirements.
Video embeddings are generated for the sampled video frames for each chunk.
VLM captions are generated using the embeddings and user prompt for each chunk. Supported VLMs are Cosmos-Reason2, Cosmos-Reason1 and GPT-4o. Custom VLM models can also be hooked into the pipeline.
If audio transcription is enabled, audio content from each chunk of input video is converted to 16 kHz mono audio and it is then passed to the Riva ASR service. The Riva ASR service generates the audio transcript for the chunk.
If CV metadata is enabled, the CV metadata is generated for complete input video using CV pipeline. The CV metadata is then overlaid on the video frames, which are passed to VLM.
The VLM captions (text), audio transcripts (if enabled), CV metadata (if enabled) and additional metadata, like timestamp information, for each chunk are sent to the retrieval pipeline for further processing and indexing.
Retrieval Pipeline#
Retrieval pipeline, where Context-Aware RAG (CA-RAG) plays a major role, is responsible for processing the output of the ingestion pipeline and using it for various retrieval tasks like summarization of long video files, live streams, and Q&A on the indexed data.
VLM captions, audio transcripts (if enabled) and associated metadata are processed and indexed and stored in vector and graph Databases.
Accelerated NeMo Retriever Embedding NIM is used for better throughput with the VLM caption text embedding process. These text embeddings, along with associated metadata, are inserted in the vector database.
LLMs like LLaMA 3.1 or GPT-4o are used for tool calling, for parsing the VLM captions, and generating the graph database insertion API calls. They help populate the knowledge graph for the input video.
For summarization, the VLM captions and audio transcripts are summarized together to get a final aggregated summary using an LLM.
For Q&A, with the help of LLM tool calling, information relevant to your query is extracted from the knowledge graph and the vector database. The retrieved information is passed to the NeMo reranking service and the output is used as context by the LLM for generating the answer to your question.