Audio Processing Support#
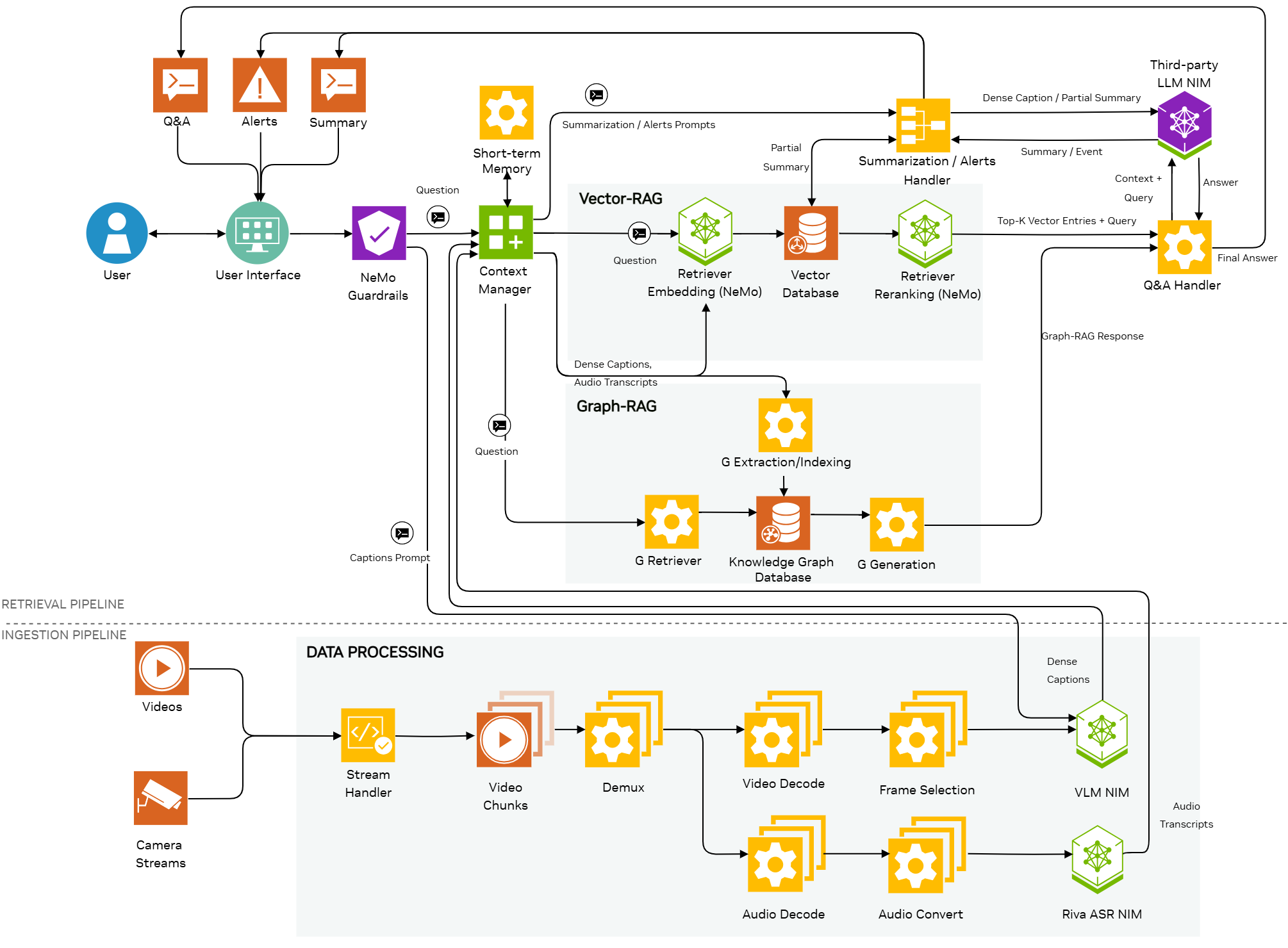
VSS supports processing of audio content in the input media to generate audio transcripts using NVIDIA Riva Automatic Speech Recognition (ASR) service. This feature can be used to extract the audio information in the input and use it to supplement video description for summarization, Q&A and alerts. This way the accuracy of responses can be improved for inputs like conference videos, presentations.
By default, audio content in Opus and Vorbis formats is supported.
To enable decoding of audio encoded with other codecs,
set INSTALL_PROPRIETARY_CODECS to true in the overrides file and enable root permissions.
This installs additional multimedia packages, refer Enabling Audio for Helm / Enabling Audio for Docker Compose.
Audio transcription is supported for offline and batch processing of video files as well as online processing of live streams.
Video files are processed as small chunks (typically a few seconds or a few minutes). The chunks represent a small portion of the video file. Processing of individual chunks is distributed across the GPUs in parallel for better performance.
For each chunk the audio stream from the input video is converted to 16 kHz mono audio and it is then passed to the Riva ASR service. The Riva ASR service generates the audio transcript for the chunk.
The video captions from VLM, audio transcripts and additional metadata, like timestamp information, for each chunk are sent to the retrieval pipeline for further processing and indexing.
The audio processing can be enabled or disabled at initialization of VSS. Also each summarization request can be configured to enable or disable audio transcription.
The Riva ASR service can be deployed locally as part of VSS or a remote Riva ASR NIM service from build.nvidia.com can be used, for example, https://build.nvidia.com/nvidia/parakeet-ctc-0_6b-asr/api.