Google Cloud Platform (GCP)#
Steps to use OneClick script to deploy on GCP.
The cloud deployment uses the same Helm chart and the default topology as detailed at Default Deployment Topology and Models in Use.
Note
This release of the OneClick scripts supports single-node deployments to GCP as documented in this page.
Prerequisites#
Host System Prerequisites#
Ubuntu 22.04
No GPU required
The following tools need to be installed on the OS of the host system for the scripts to execute:
Install
jqsudo apt update sudo apt-get install -y jq
Install
yqsudo wget https://github.com/mikefarah/yq/releases/download/v4.34.1/yq_linux_amd64 -O /usr/bin/yq sudo chmod +x /usr/bin/yq
Install
python3,venv, andpipsudo apt update sudo apt-get install python3.10 python3-venv python3-pip -y
Install
OpenTofusudo snap install --classic opentofu
Note
Minimum version of OpenTofu must be 1.9.0.
GCP Prerequisites#
GCP service account is required to run the installations using one-click scripts.
You must also have a GCP cloud storage bucket to capture the metadata (state) of the deployment. This allows the script to track infrastructure created and be able to destroy it and consequently save on running costs when it is no longer needed. Not having a storage for this metadata can result in you having to manually delete created resources.
You must have access to a GCP project with admin level privileges to configure the prerequisites.
Confirm access by navigating to the Google Cloud Console.
Service Account Setup#
Select the IAM & Admin from the left navigation menu.
Select the Service Accounts.
Click on the Create Service Account button at the top of the Service Accounts page to create new service account.
In the wizard, go to section Service account details:
Service account name: Provide an appropriate name.
Service account ID: It will be auto populated based on the service account name.
Service account description: Provide an appropriate description for service account.
Click on the Create and Continue button.
Go to section Grant this service account access to project.
Select an Owner role and click on Continue.
Grant users access to this service account section is optional.
Click on DONE.
You will be automatically taken to the Service accounts pages. If not:
Select the IAM & Admin from the left navigation menu.
Select the Service Accounts from the left menu.
On Service accounts page, it will show all the service accounts available in this project.
Identify the service account created using Email or Name field.
Click on created Service accounts from the list. It will open page showing all details about service account.
Click on KEYS option available in middle of page.
Click on ADD KEY and select Create new key option and select JSON as Key type.
The key file will be automatically downloaded to your local machine. This Key file contains the private key needed to authenticate as the service account with GCP.
State Storage Setup#
From the Navigation Menu page:
Select the Cloud Storage from the category (on the left).
Click on the +Create button to create a new storage account.
In the wizard:
In the Name your bucket section:
Provide globally unique name for the bucket. (We are creating this bucket to store deployment state.)
Optionally add Labels.
In the Choose where to store your data section:
Select location type as region.
Select appropriate region from drop-down list.
Leave all other sections as is.
Click CREATE.
Get the OneClick Deployment Package#
Clone the NVIDIA AI Blueprint: Video Search and Summarization repository.
git clone https://github.com/NVIDIA-AI-Blueprints/video-search-and-summarization.git
Untar the package
cd video-search-and-summarization/deploy/one_click tar -xvf deploy-gcp-cns.tar.gz
Prepare env Variables#
Prepare a file, via-env-template.txt, to hold required
envvariables and their values:#Env: GCP secrets export CLOUDSDK_CORE_PROJECT='project-id' export CLOUDSDK_AUTH_CREDENTIAL_FILE_OVERRIDE='/path to/service-account-key.json' #Env: Nvidia Secrets: export NGC_API_KEY= #Env: Hugging Face Token: export HF_TOKEN= #Env: OpenAI Secrets: export OPENAI_API_KEY= #Env: App secrets export VIA_DB_PASSWORD=password export ARANGO_DB_PASSWORD=password export MINIO_SECRET_KEY=minio123 #Non secrets: #GCP Resources created above in Section: GCP pre-requisites export VIA_DEPLOY_GCP_GCSB='gcp-bucket-name' #Unique name for the VSS deployment export VIA_DEPLOY_ENV='vss-deployment'
Note
NGC_API_KEY: refers to Obtain NGC API Key.HF_TOKEN: refer to Obtain Hugging Face Token.OPENAI_API_KEY: API key from https://platform.openai.com/api-keys.Consider updating
VIA_DEPLOY_ENVto something other than the default to identify the deployment. For example,VIA_DEPLOY_ENV='vss-demo'.Update
CLOUDSDK_CORE_PROJECT,CLOUDSDK_AUTH_CREDENTIAL_FILE_OVERRIDE, andVIA_DEPLOY_GCP_BUCKETto reflect the GCP Resource created above in GCP Prerequisites.
Load these
envvariables into your current shell session:source via-env-template.txt
Prepare the config File#
Make a copy of config-template.yml of your own choice. For example, config.yml.
Or you can populate the config file as based on definition of each attribute.
schema_version: '0.0.10'
name: "via-gcp-cns-{{ lookup('env', 'VIA_DEPLOY_ENV') }}"
spec:
infra:
csp: 'gcp'
backend:
bucket: "{{ lookup('env', 'VIA_DEPLOY_GCP_GCSB') }}"
credentials: "{{ lookup('env', 'CLOUDSDK_AUTH_CREDENTIAL_FILE_OVERRIDE') }}"
provider:
project: "{{ lookup('env', 'CLOUDSDK_CORE_PROJECT') }}"
credentials: "{{ lookup('env', 'CLOUDSDK_AUTH_CREDENTIAL_FILE_OVERRIDE') }}"
configs:
cns:
version: 12.2
git_ref: ebf03a899f13a0adaaa3d9f31a299cff6ab33eb3
override_values:
cns_nvidia_driver: yes
gpu_driver_version: '580.65.06'
access_cidrs:
- 'my-org-ip-cidr' ### Make sure to update this e.g. 'xxx.xxx.xxx.xxx/32' for a single IP address.
region: 'us-west1' ### Update this to change the deployment region
ssh_public_key: "{{ lookup('file', lookup('env', 'HOME') + '/.ssh/id_rsa.pub') }}"
ssh_private_key_path: "{{ lookup('env', 'HOME') + '/.ssh/id_rsa' }}"
additional_ssh_public_keys:
### Add public key of another system e.g. your colleague's if you are working in a team else add your own.
- "{{ lookup('file', lookup('env', 'HOME') + '/.ssh/id_rsa.pub') }}"
clusters:
app:
private_instance: false
master:
### Modify this to change the GPU type.
type: 'a3-megagpu-8g'
labels: {}
taints: []
ports:
backend:
port: 30081
frontend:
port: 30082
features:
cns: true
platform: true
app: true
platform:
configs:
namespace: 'default'
app:
configs:
namespace: 'default'
backend_port: 'backend'
frontend_port: 'frontend'
ngc_api_key: "{{ lookup('env', 'NGC_API_KEY') }}"
openai_api_key: "{{ lookup('env', 'OPENAI_API_KEY') }}"
hf_token: "{{ lookup('env', 'HF_TOKEN') }}"
db_username: 'neo4j'
db_password: "{{ lookup('env', 'VIA_DB_PASSWORD') | default('password') }}"
arango_db_username: 'root'
arango_db_password: "{{ lookup('env', 'ARANGO_DB_PASSWORD') | default('password') }}"
minio_access_key: 'minio'
minio_secret_key: "{{ lookup('env', 'MINIO_SECRET_KEY') | default('minio123') }}"
vss_chart:
repo:
name: 'nvidia-blueprint'
url: 'https://helm.ngc.nvidia.com/nvidia/blueprint'
chart: 'nvidia-blueprint-vss' # repo should be removed/commented-out when using local charts
version: '2.4.1'
#override_values_file_absolute_path: '/home/user/vss-values.yml'
Note
The above is just a reference. Make a copy of config-template.yml
and update it as required.
Make sure to update the config sections:
region(spec/infra/configs/), the machinetypeaccess_cidrs: runecho `curl ifconfig.me`/32to get the user machine’s IP rangeoverride_values_file_absolute_path(optional) in the config file:To use the
overrides.yamlfile as discussed in sections like Configuration Options.
To use a Helm overrides value file to customize the various parts of the VSS blueprint deployment, do the following:
Uncomment and update
override_values_file_absolute_pathto set the actual path to the overrides file.Uncomment line
- "{{ configs.vss_chart.override_values_file_absolute_path }}"indist/app-tasks.ymlnear the end of the file.More information on the VSS Helm overrides file can be found in Configuration Options.
Attributes of the config-template.yml
Attribute |
Optional |
Description |
|---|---|---|
name |
A unique name to identify the infrastructure resources being created. |
|
spec > infra > backend > bucket |
Name of the GCP Cloud Storage bucket in which state of the resources provisioned is stored. |
|
spec > infra > backend > credentials |
Path of the GCP service account credential used to access the backend bucket and table. |
|
spec > infra > provider > project |
The name of the GCP project used to provision resources. |
|
spec > infra > provider > credentials |
Path of the GCP service account credential used to access the backend bucket and table. |
|
spec > infra > configs > cns |
yes |
CNS configurations. |
spec > infra > configs > cns > version |
yes |
The version of CNS to install on the clusters. Defaults to 12.2. |
spec > infra > configs > cns > override_values |
yes |
CNS values to override while setting up a cluster. |
spec > infra > configs > cns > override_values > cns_value |
yes |
The value of the cns_value found in cns_values.yaml. |
spec > infra > configs > access_cidrs |
List of CIDRs from which app will be accessible. |
|
spec > infra > configs > region |
GCP region in which to bring up the resources. |
|
spec > infra > configs > ssh_private_key_path |
Absolute path of the private key to be used to SSH the hosts. |
|
spec > infra > configs > ssh_public_key |
Content of the public counterpart of the private key used to SSH the hosts. |
|
spec > infra > configs > additional_ssh_public_keys |
yes |
List of contents of public counterparts to the additional keys that will be used to SSH the hosts. |
spec > infra > configs > bastion |
yes |
Details of the GCP instance to be used as a bastion host for private clusters. |
spec > infra > configs > bastion > type |
yes |
GCP instance type for the bastion node (if required). Defaults to e2-medium. |
spec > infra > configs > bastion > zone |
yes |
GCP availability zone in the region for the bastion node (if required). Defaults to the first (alphabetically) AZ of the region. |
spec > infra > configs > bastion > disk_size_gb |
yes |
Root volume disk size for the bastion node. Defaults to 128. |
spec > infra > configs > clusters |
Definitions of clusters to be created. |
|
spec > infra > configs > clusters > cluster |
Unique key to identify a cluster. There can be 1 or more clusters. |
|
spec > infra > configs > clusters > cluster > private_instance |
yes |
If true, creates the cluster instances within a private subnet. Defaults to false |
spec > infra > configs > clusters > cluster > zone |
yes |
GCP availability zone in the region for the master and nodes of the cluster. Defaults to the first (alphabetically) AZ of the region. |
spec > infra > configs > clusters > cluster > master |
Definitions of the master node of the cluster. |
|
spec > infra > configs > clusters > cluster > master > type |
yes |
GCP instance type for the master node. Defaults to a2-ultragpu-8g. |
spec > infra > configs > clusters > cluster > master > guest_accelerators |
yes |
List of guest accelerators to attach to the GCP instance type for the master node. Defaults to none. |
spec > infra > configs > clusters > cluster > master > guest_accelerators > index |
Details of one of the guest accelerators to attach to the GCP instance type for the master node. |
|
spec > infra > configs > clusters > cluster > master > guest_accelerators > index > type |
The type of the index guest accelerators for the master node. |
|
spec > infra > configs > clusters > cluster > master > guest_accelerators > index > count |
The count of the index guest accelerators for the master node. |
|
spec > infra > configs > clusters > cluster > master > disk_size_gb |
yes |
Root volume disk size for the master node. Defaults to 1024. |
spec > infra > configs > clusters > cluster > master > labels |
yes |
Labels to apply to the master node. Defaults to {}. |
spec > infra > configs > clusters > cluster > master > taints |
yes |
Taints to apply to the master node. Defaults to []. |
spec > infra > configs > clusters > cluster > nodes |
yes |
Definitions of nodes of the cluster. Set to {} if no extra nodes other than master needed. |
spec > infra > configs > clusters > cluster > nodes > node |
Unique key to identify a node. There can be 0 or more nodes. |
|
spec > infra > configs > clusters > cluster > nodes > node > type |
yes |
GCP instance type for the node node. Defaults to a2-ultragpu-8g. |
spec > infra > configs > clusters > cluster > nodes > node > guest_accelerators |
yes |
List of guest accelerators to attach to the GCP instance type for the node node. Defaults to none. |
spec > infra > configs > clusters > cluster > nodes > node > guest_accelerators > index |
Details of one of the guest accelerators to attach to the GCP instance type for the node node. |
|
spec > infra > configs > clusters > cluster > nodes > node > guest_accelerators > index > type |
The type of the index guest accelerators for the node node. |
|
spec > infra > configs > clusters > cluster > nodes > node > guest_accelerators > index > count |
The count of the index guest accelerators for the node node. |
|
spec > infra > configs > clusters > cluster > nodes > node > disk_size_gb |
yes |
Root volume disk size for the node node. Defaults to 1024. |
spec > infra > configs > clusters > cluster > nodes > node > labels |
yes |
Labels to apply to the node node. Defaults to {}. |
spec > infra > configs > clusters > cluster > nodes > node > taints |
yes |
Taints to apply to the node node. Defaults to []. |
spec > infra > configs > clusters > cluster > ports |
yes |
Definitions of ports of the cluster. Set to {} if no ports are exposed by the cluster. |
spec > infra > configs > clusters > cluster > ports > port |
Unique key to identify a port. There can be 0 or more ports. |
|
spec > infra > configs > clusters > cluster > ports > port > port |
The port number of the port. |
|
spec > infra > configs > clusters > cluster > ports > port > protocol |
yes |
The protocol of the port. Defaults to http. |
spec > infra > configs > clusters > cluster > ports > port > path |
yes |
The path of the application on the port for the landing URL. Defaults to /. |
spec > infra > configs > clusters > cluster > features |
yes |
Definitions of features of the cluster. Set to {} if no features defined for the cluster. |
spec > infra > configs > clusters > cluster > features > feature |
Key to identify a feature and value represents enabled/disabled by setting it to true/false. There can be 0 or more features. |
|
spec > platform > configs > namespace |
yes |
Namespace to deploy the platform components in. Defaults to default. |
spec > app > configs > namespace |
yes |
Namespace to deploy the app in. Defaults to default. |
spec > app > configs > backend_port |
Identifier of the port in the cluster to expose the api over. |
|
spec > app > configs > frontend_port |
Identifier of the port in the cluster to expose the ui over. |
|
spec > app > configs > ngc_api_key |
NGC API key used to download application charts, models and containers. |
|
spec > app > configs > openai_api_key |
OPENAI API key used by the application. |
|
spec > app > configs > db_username |
The username used to access the DB. |
|
spec > app > configs > db_password |
The password used to access the DB. |
|
spec > app > configs > arango_db_username |
The username used to access the Arango DB. |
|
spec > app > configs > arango_db_password |
The password used to access the Arango DB. |
|
spec > app > configs > minio_access_key |
The access key used to access the Minio DB. |
|
spec > app > configs > minio_secret_key |
The secret key used to access the Minio DB. |
|
spec > app > configs > vss_chart |
Configuration details of the VSS chart. |
|
spec > app > configs > vss_chart > repo |
yes |
Helm repo details of the chart. Can be ignored if using a local chart. |
spec > app > configs > vss_chart > repo > name |
Name provided to refer the added Helm repo. |
|
spec > app > configs > vss_chart > repo > url |
Url of the Helm repo containing the chart. |
|
spec > app > configs > vss_chart > chart |
The name of the chart for a remote repo source. The absolute path of a local chart. |
|
spec > app > configs > vss_chart > version |
The version of the chart. |
Run OneClick Script to Deploy on GCP#
Make sure the host machine to run OneClick script has RSA keys generated. If not, use the following command to generate:
sudo apt-get install -y openssh-client ssh-keygen -t rsa -N "" -f ~/.ssh/id_rsa
Deployment
Use the config from Prepare env Variables. Place it in the
distdirectory.Choose machine type:
The default machine type is: H100 GPU. You can change this to other configurations. This change can be made in the
config.yamlfile available in Section: Prepare env Variables.### Default is: H100 GPU ### Modify this to change the GPU type. ### Alternatives: ### - a2-ultragpu-8g (8 x A100 80GB) ### - a3-megagpu-8g (8 x H100 80GB) type: 'a3-megagpu-8g'
More info on the machine types can be found in the GCP Compute Engine documentation here.
Deploy:
cd dist/ ./envbuild.sh install -f config.yml -c all
Note
If you get an error like
could not process config file: ...while restarting/redeploying, try removing the temporary directory that is shown in the error logs. For example:rm -rf <dist-directory>/tmp.dZM7is5HUCConfirm that the SSH key was generated and is present on the path mentioned in the config for keys:
ssh_public_keyorssh_private_key_path. If there is no need foradditional_ssh_public_keys, comment that out in the config file.This project downloads and installs additional third-party open source software projects. Review the license terms of these open source projects before use.
Access the Deployment#
After success, verify that the logs are similar to the following:
access_urls:
app:
backend: http://<NODE-IP>:30081/
frontend: http://<NODE-IP>:30082/
ssh_command:
app:
master: ssh -i $HOME/.ssh/id_rsa -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null ubuntu@<NODE-IP>
Note
You must wait till the deployment installation is fully complete before trying to access the nodes.
Or, get this info after successful deployment on demand using command:
cd dist/
./envbuild.sh -f config.yml info
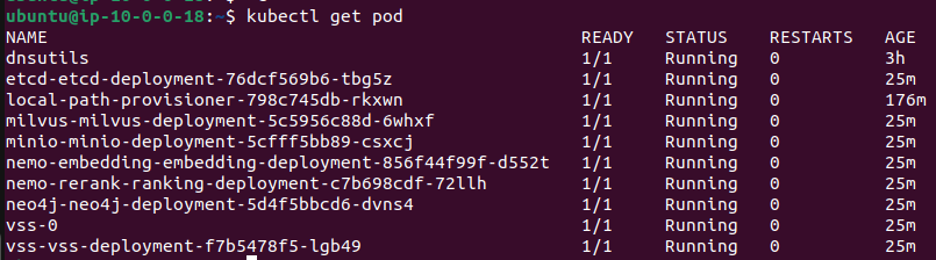
Wait for all pods and services to be up. Log in to the node using the ssh command
shown above and check pod status using kubectl get pod.
ssh -i $HOME/.ssh/id_rsa -o StrictHostKeyChecking=no -o UserKnownHostsFile=/dev/null ubuntu@<NODE-IP>
kubectl get pod
Make sure all pods are in Running or Completed STATUS and show 1/1 as READY as shown below.
Note
The terraform scripts will install the kubectl utility. You must not install Kubernetes
or kubectl manually.
Make sure the VSS API and UI are ready and accessible, check the logs for deployment using the command:
kubectl logs vss-vss-deployment-POD-NAME
Make sure that the following logs are present and that you do not observe any errors:
VIA Server loaded
Backend is running at http://0.0.0.0:8000
Frontend is running at http://0.0.0.0:9000
The VSS API and UI are now ready to be accessed at http://<NODE-IP>:30081 and http://<NODE-IP>:30082 respectively. Test the deployment by summarizing a sample video.
Teardown#
Un-installing:
$ cd dist/
$ ./envbuild.sh uninstall -f config.yml -c all
Common Issues#
VSS Pod is Failing and Restarting on L4 Node#
The VSS container startup might be timing out on an L4 node. Try increasing the startup timeout by using an overrides file with following values:
vss:
applicationSpecs:
vss-deployment:
containers:
vss:
startupProbe:
failureThreshold: 360