Context-Aware RAG#
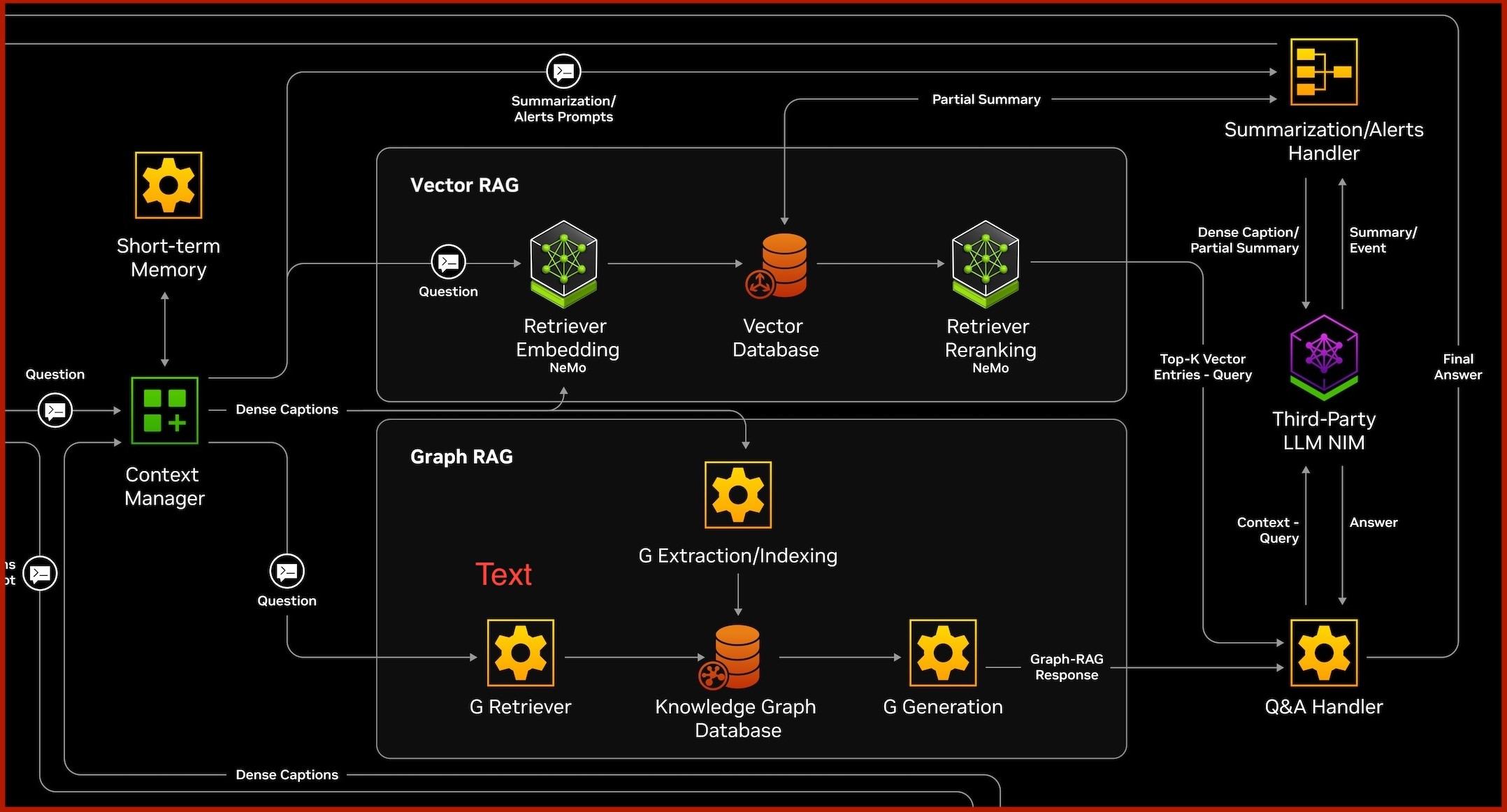
The VSS Context-Aware RAG is responsible for the video search and summarization based on the dense captions generated from the data processing pipeline. It implements the following data pipelines to achieve it:
Data Ingestion:
Responsible for receiving and processing incoming documents.
Uses the context manager to add documents, process them using batching, and prepare them for subsequent retrieval.
Data Retrieval:
Focuses on extracting the relevant context in response to user queries.
Leverages Graph-RAG and Vector-RAG functions to deliver precise, context-aware answers.
Context-Aware RAG starts its own process and event loop as to not block the main process and to increase performance.
Data Ingestion#
Parallel and Asynchronous Ingestion:
Documents are ingested in parallel and asynchronously processed to avoid blocking the main process.
Documents can be added with
doc_indexanddoc_meta.doc_indexis used to uniquely identify the document (doc_0,doc_1,doc_2).doc_metais used to store additional metadata about the document ({stream_id: 0, timestamp: 1716393600}).
Processing is done in Context-Aware RAG separate process.
Documents can arrive in any order.
Batcher:
Batcher groups documents into fixed-size, duplicate-checked batches (using doc_id//batch_size).
When a batch fills up, downstream processing can be triggered immediately (for example, graph extraction).
Example Batching Process (with batch_size = 2):
If
doc_4arrives first, it’s placed in batch 2 (doc_id 4 // batch_size 2 = 2)When
doc_0arrives, it’s placed in batch 0 (doc_id 0 // batch_size 2 = 0)When
doc_1arrives, it completes batch 0 (doc_id 1 // batch_size 2 = 0)Batch
0is now full and triggers asynchronous processing:Partial graph construction begins for documents
0and1.
This process continues until all documents arrive.
After all batches are processed, the final lexical graph is constructed.
Graph Ingestion#
functions:
ingestion_function:
type: graph_ingestion
params:
batch_size: 1
tools:
db: graph_db
llm: chat_llm
- Other optional parameters:
batch_size (int): Number of docs processed before graph writes. Default: 1.
embedding_parallel_count (int): Parallel workers for embeddings. Default: 1000.
duplicate_score_value (float): Score threshold for node deduplication. Default: 0.9.
node_types (list[str]): Node labels to include. Default: [“Person”, “Vehicle”, “Location”, “Object”]
relationship_types (list[str]): Relationship types to include. Default: [].
deduplicate_nodes (bool): Merge similar nodes if true. Default: false.
disable_entity_description (bool): Skip generating entity descriptions. Default: true.
disable_entity_extraction (bool): Skip entity extraction entirely. Default: false.
chunk_size (int): Text chunk size for splitting during ingestion. Default: 500.
chunk_overlap (int): Overlap between chunks for splitting. Default: 10.
Vector Ingestion#
functions:
ingestion_function:
type: vector_ingestion
params:
batch_size: 1
tools:
db: vector_db
llm: chat_llm
- Other optional parameters:
batch_size (int): Number of docs processed in a run (metadata grouping). Default: 1.
custom_metadata (dict): Extra metadata to attach to stored docs. Default: {}.
is_user_specified_collection (bool): Use a user‑provided collection. Default: false.
Summarization#
CA-RAG provides the following methods for summarizing content.
Batch: This method performs summarization in two stages:
Batching: Groups together documents into batches and generates summaries for each batch.
Aggregation: Combines batch summaries using a secondary prompt (
summary_aggregation).This method is ideal for handling long videos.
Data Retrieval (Q&A)#
CA-RAG supports different retrieval strategies which are as follows:
Vector Retrieval - Semantic similarity-based retrieval with contextual compression
Graph Retrieval - Knowledge graph-based retrieval for entity relationships
VLM Retrieval - Visual Language Model retrieval for multimodal analysis
Chain of Thought (CoT) Retrieval - Advanced iterative retrieval with confidence scoring
Advanced Retrieval - Modular iterative planning and execution
Vector Retrieval#
Captions generated by the Vision-Language Model (VLM), along with their embeddings, are stored in Milvus DB or Elasticsearch.
Embeddings can be created using any embedding NIM
By default, embeddings are created using nvidia/llama-3_2-nv-embedqa-1b-v2.
For a query, the top five most similar chunks are retrieved, re-ranked using any reranker NIM and passed to a Large Language Model (LLM) NIM to generate the final answer.
By default, the reranker NIM is set to nvidia/llama-3_2-nv-rerankqa-1b-v2.
Configuration Parameters
functions:
retriever_function:
type: vector_retrieval
params:
top_k: 5
tools:
llm: chat_llm
db: vector_db
reranker: nvidia_reranker
- Optional Parameters:
top_k (int): Number of documents to retrieve semantically. Default: 5.
custom_metadata (dict, optional): Additional metadata for filtering. Default: {}.
is_user_specified_collection (bool, optional): Use a specific collection name. Default: false.
Graph Retrieval#
Graph Extraction: Entities and relationships are extracted from VLM captions, using an LLM, and stored in a GraphDB. Captions and embeddings, generated with any embedding NIM, are also linked to these entities.
Graph Retrieval: For a given query, relevant entities, relationships, and captions are retrieved from the GraphDB and passed to an LLM NIM to generate the final answer.
Configuration Parameters
functions:
retriever_function:
type: graph_retrieval
params:
top_k: 5
tools:
llm: chat_llm
db: graph_db
- Optional Parameters:
top_k (int): Number of chunks/entities to retrieve. Default: 5.
chat_history (bool, optional): Keep and summarize multi-turn chat history. Default: false.
VLM Retrieval#
Captions generated by the Vision-Language Model (VLM), along with their embeddings and video frames paths are stored in different databases.
Video frames are stored in minio.
Based on the given user query, the most relevant chunk and related video frames are retrieved and passed to a Vision Language Model (VLM) NIM along with the query to generate the final answer.
Embeddings can be created using any embedding NIM
By default, embeddings are created using nvidia/llama-3_2-nv-embedqa-1b-v2.
Configuration Parameters
functions:
retriever_function:
type: vlm_retrieval
params:
top_k: 10
tools:
llm: chat_llm
db: graph_db
vlm: openai_llm
image_fetcher: image_fetcher
Set SAVE_CHUNK_FRAMES_MINIO to true for image_fetcher to be used.
- Optional Parameters:
num_chunks (int, optional): For image extraction, number of chunks to sample. Default: 3.
num_frames_per_chunk (int, optional): Frames per chunk to sample. Default: 3.
max_total_images (int, optional): Cap on total extracted images. Default: 10.
Chain of Thought (CoT) Retrieval#
Chain of Thought Retrieval implements an advanced iterative approach that uses confidence-based decision making and question reformulation to provide accurate answers.
Key Features:
Iterative Retrieval: Performs multiple retrieval iterations (up to max_iterations) until a confident answer is found
Confidence Scoring: Uses a confidence threshold to determine answer quality (default: 0.7)
Question Reformulation: LLM can suggest updated questions to retrieve better database results
Chat History Integration: Maintains conversation context using the last 3 interactions
Visual Data Processing: Can request and analyze video frames when visual information is needed
Structured Response: Returns JSON-formatted responses with answer, confidence, and additional metadata
Retrieval Process:
Initial context retrieval based on the user question
Integration of relevant chat history from previous interactions
Iterative LLM evaluation with structured JSON response format
If confidence is below threshold:
Request additional context using reformulated questions
Process visual data if needed (when image features enabled)
Continue iteration until confident answer or max iterations reached
Return final answer with confidence score
Configuration Parameters
functions:
retriever_function:
type: cot_retrieval
params:
image: false
top_k: 10
max_iterations: 3
confidence_threshold: 0.7
tools:
llm: chat_llm
db: graph_db
vlm: openai_llm # optional when image=true
image_fetcher: image_fetcher # optional when image=true
Set SAVE_CHUNK_FRAMES_MINIO to true for image_fetcher to be used.
- Optional Parameters:
image (bool, optional): Attach extracted frames to the prompt where supported. Default: false.
num_chunks (int, optional): For image extraction, number of chunks to sample. Default: 3.
num_frames_per_chunk (int, optional): Frames per chunk to sample. Default: 3.
max_total_images (int, optional): Cap on total extracted images. Default: 10.
Prompt Configuration
Prompt configuration file is used to configure the prompts for the CoT Retrieval. It is a YAML file that contains the prompts for the CoT Retrieval. If not provided, default prompts will be used.
There are four prompts in the prompt configuration file:
ADV_CHAT_TEMPLATE_IMAGE: The prompt for the image retrieval.ADV_CHAT_TEMPLATE_TEXT: The prompt for the text retrieval.ADV_CHAT_SUFFIX: The prompt for the suffix.QUESTION_ANALYSIS_PROMPT: The prompt for the question analysis.
Example prompt configuration file:
ADV_CHAT_TEMPLATE_IMAGE: |+
You are an AI assistant that answers questions based on the provided context.
The context includes retrieved information, relevant chat history, and potentially visual data.
The image context contains images if not empty.
Determine if more visual data (images) would be helpful to answer this question accurately.
For example, if the question is about color of an object, location of an object, or other visual information, visual data is needed.
If image context is not empty, you likely do not need more visual data.
Use all available context to provide accurate and contextual answers.
If the fetched context is insufficient, formulate a better question to
fetch more relevant information. Do not reformulate the question if image data is needed.
You must respond in the following JSON format:
{
"description": "A description of the answer",\
"answer": "your answer here or null if more info needed",\
"updated_question": "reformulated question to get better database results" or null,\
"confidence": 0.95, // number between 0-1\
"need_image_data": "true" // string indicating if visual data is needed\
}
Example 1 (when you have enough info from text):
{
"description": "A description of the answer",\
"answer": "The worker dropped a box at timestamp 78.0 and it took 39 seconds to remove it",\
"updated_question": null,\
"confidence": 0.95,\
"need_image_data": "false"\
}
Example 2 (when you need visual data):
{
"description": "A description of the answer",\
"answer": null,\
"updated_question": null, //must be null\
"confidence": 0,\
"need_image_data": "true"\
}
Example 3 (when you need more context):
{
"description": "A description of the answer",\
"answer": null,\
"updated_question": "What events occurred between timestamp 75 and 80?",\
"confidence": 0,\
"need_image_data": "false"\
}
Only respond with valid JSON. Do not include any other text.
ADV_CHAT_TEMPLATE_TEXT: |+
You are an AI assistant that answers questions based on the provided context.
The context includes retrieved information and relevant chat history.
Use all available context to provide accurate and contextual answers.
If the fetched context is insufficient, formulate a better question to
fetch more relevant information.
You must respond in the following JSON format:
{
"description": "A description of the answer",\
"answer": "your answer here or null if more info needed",\
"updated_question": "reformulated question to get better database results" or null,\
"confidence": 0.95 // number between 0-1\
}
Example 1 (when you have enough info from text):
{
"description": "A description of the answer",\
"answer": "The worker dropped a box at timestamp 78.0 and it took 39 seconds to remove it",\
"updated_question": null,\
"confidence": 0.95\
}
Example 2 (when you need more context):
{
"description": "A description of the answer",\
"answer": null,\
"updated_question": "What events occurred between timestamp 75 and 80?",\
"confidence": 0\
}
Only respond with valid JSON. Do not include any other text.
ADV_CHAT_SUFFIX: |+
When you have enough information, in the "answer" field format your response according to these instructions:
Your task is to provide accurate and comprehensive responses to user queries based on the context, chat history, and available resources.
Answer the questions from the point of view of someone looking at the context.
### Response Guidelines:
1. **Direct Answers**: Provide clear and thorough answers to the user's queries without headers unless requested. Avoid speculative responses.
2. **Utilize History and Context**: Leverage relevant information from previous interactions, the current user input, and the context.
3. **No Greetings in Follow-ups**: Start with a greeting in initial interactions. Avoid greetings in subsequent responses unless there's a significant break or the chat restarts.
4. **Admit Unknowns**: Clearly state if an answer is unknown. Avoid making unsupported statements.
5. **Avoid Hallucination**: Only provide information relevant to the context. Do not invent information.
6. **Response Length**: Keep responses concise and relevant. Aim for clarity and completeness within 4-5 sentences unless more detail is requested.
7. **Tone and Style**: Maintain a professional and informative tone. Be friendly and approachable.
8. **Error Handling**: If a query is ambiguous or unclear, ask for clarification rather than providing a potentially incorrect answer.
9. **Summary Availability**: If the context is empty, do not provide answers based solely on internal knowledge. Instead, respond appropriately by indicating the lack of information.
10. **Absence of Objects**: If a query asks about objects which are not present in the context, provide an answer stating the absence of the objects in the context. Avoid giving any further explanation. Example: "No, there are no mangoes on the tree."
11. **Absence of Events**: If a query asks about an event which did not occur in the context, provide an answer which states that the event did not occur. Avoid giving any further explanation. Example: "No, the pedestrian did not cross the street."
12. **Object counting**: If a query asks the count of objects belonging to a category, only provide the count. Do not enumerate the objects.
### Example Responses:
User: Hi
AI Response: 'Hello there! How can I assist you today?'
User: "What is Langchain?"
AI Response: "Langchain is a framework that enables the development of applications powered by large language models, such as chatbots. It simplifies the integration of language models into various applications by providing useful tools and components."
User: "Can you explain how to use memory management in Langchain?"
AI Response: "Langchain's memory management involves utilizing built-in mechanisms to manage conversational context effectively. It ensures that the conversation remains coherent and relevant by maintaining the history of interactions and using it to inform responses."
User: "I need help with PyCaret's classification model."
AI Response: "PyCaret simplifies the process of building and deploying machine learning models. For classification tasks, you can use PyCaret's setup function to prepare your data. After setup, you can compare multiple models to find the best one, and then fine-tune it for better performance."
User: "What can you tell me about the latest realtime trends in AI?"
AI Response: "I don't have that information right now. Is there something else I can help with?"
**IMPORTANT** : YOUR KNOWLEDGE FOR ANSWERING THE USER'S QUESTIONS IS LIMITED TO THE CONTEXT PROVIDED ABOVE.
Note: This system does not generate answers based solely on internal knowledge. It answers from the information provided in the user's current and previous inputs, and from the context.
QUESTION_ANALYSIS_PROMPT: |+
Analyze this question and identify key elements for graph database retrieval.
Question: {question}
Identify and return as JSON:
1. Entity types mentioned. Available entity types: {entity_types}
2. Relationships of interest
3. Time references
4. Sort by: "start_time" or "end_time" or "score"
5. Location references
6. Retrieval strategy (similarity, temporal)
a. similarity: If the question needs to find similar content, return the retrieval strategy as similarity
b. temporal: If the question is about a specific time range and you can return at least one of the start and end time, then return the strategy as temporal and the start and end time in the time_references field as float or null if not present. Strategy cannot be temporal if both start and end time are not present. The start and end time should be in seconds.
Example response:
{{
"entity_types": ["Person", "Box"],
"relationships": ["DROPPED", "PICKED_UP"],
"time_references": {{
"start": 60.0,
"end": 400.0
}},
"sort_by": "start_time", // "start_time" or "end_time" or "score"
"location_references": ["warehouse_zone_A"],
"retrieval_strategy": "temporal"
}}
Output only valid JSON. Do not include any other text.
Advanced Retrieval#
Advanced Retrieval implements a modular planning and execution system that uses iterative reasoning and specialized tools for complex video analysis tasks. This strategy is supported only for GraphDBs (Neo4j, ArangoDB).
Architecture Components:
Planning Module: Creates execution plans and evaluates results to determine next steps
Execution Engine: Parses XML-structured plans and creates tool calls
Tool Node: Executes specialized search and analysis tools
Response Formatter: Formats final answers based on all collected information
Available Traversal Strategies:
chunk_search: Retrieves the most relevant chunks using vector similarity
entity_search: Retrieves entities and relationships using vector similarity
chunk_filter: Filters chunks based on time ranges and camera IDs
chunk_reader: Analyzes chunks and video frames using VLM for detailed insights
bfs: Performs breadth-first search through entity relationships
next_chunk: Retrieves chronologically adjacent chunks
Iterative Process:
Planning Phase: Planning module creates initial execution plan
Execution Phase: Execution engine parses plan and calls appropriate tools
Evaluation Phase: Results are evaluated; if incomplete, cycle repeats with refined plan
Response Phase: Final answer is generated when sufficient information is gathered
Key Features:
Multi-Channel Support: Handles multiple camera streams with runtime camera information
Dynamic Tool Selection: Uses only the tools specified in configuration
Iterative Refinement: Continues until confident answer or max iterations reached
XML-Structured Plans: Uses structured XML format for reliable plan parsing
Context Awareness: Integrates video length and camera metadata into planning
Configuration Parameters
functions:
retriever_function:
type: adv_graph_retrieval
params:
top_k: 10
max_iterations: 20
multi_channel: false # Enable for multi-stream processing
tools: ["chunk_search", "chunk_filter", "entity_search", "chunk_reader"]
prompt_config_path: "prompt_config.yaml" # optional if not provided, default prompts will be used
tools:
llm: chat_llm
db: graph_db
vlm: openai_llm # required when tools contains chunk_reader
image_fetcher: image_fetcher # required when tools contains chunk_reader
Set SAVE_CHUNK_FRAMES_MINIO to true for image_fetcher to be used.
- Optional Parameters:
top_k (int): Number of chunks/entities to retrieve. Default: 5.
tools (list[str]): Planner tool names to expose to the agent. Available tools: - chunk_search: Semantic search for relevant chunks in the graph database. - chunk_filter: Filter chunks based on temporal range and camera id. - entity_search: Search for similar entities and their related chunks. - chunk_reader: Read and analyze a specific chunk with vision capabilities. - bfs: Breadth-first search traversal to find nodes one hop away. - next_chunk: Navigate to the next chunk in video.
max_iterations (int, optional): Recursion limit for agent reasoning. Default: 20.
num_frames_per_chunk (int, optional): Frames per chunk to sample for VLM. Default: 3.
num_chunks (int, optional): For image extraction, number of chunks to sample. Default: 3.
max_total_images (int, optional): Cap on total extracted images. Default: 10.
prompt_config_path (str, optional): Prompt configuration section below. Default: <default_configured_prompts>. More in the section below.
include_adjacent_chunks (bool, optional): Include adjacent chunk to pass to VLM (ChunkReaderTool specific). Default: False.
pass_video_to_vlm (bool, optional): Pass video instead of image to VLM (ChunkReaderTool specific). Set to True for Qwen3-vl models. Default: False
num_prev_chunks (int, optional): Number of previous chunks to include (ChunkReaderTool specific). Used only if include_adjacent_chunks=true. Default: 1
num_next_chunks (int, optional): Number of next chunks to include (ChunkReaderTool specific). Used only if include_adjacent_chunks=true. Default: 1
Prompt Configuration
Prompt configuration file is used to configure the prompts for the Advanced Retrieval. It is a YAML file that contains the prompts for the Advanced Retrieval. If not provided, default prompts will be used.
There are three prompts in the prompt configuration file:
thinking_sys_msg_prompt: The prompt for the thinking agent.response_sys_msg_prompt: The prompt for the response agent.evaluation_guidance_prompt: The prompt for the evaluation guidance.
Example prompt configuration file:
thinking_sys_msg_prompt: |+
You are a strategic planner and reasoning expert working with an execution agent to analyze videos.
## Your Capabilities
You do **not** call tools directly. Instead, you generate structured plans for the Execute Agent to follow.
## Workflow Steps
You will follow these steps:
### Step 1: Analyze & Plan
- Document reasoning in `<thinking></thinking>`.
- Output one or more tool calls (strict XML format) in separate 'execute' blocks.
- **CRITICAL**: When one tool's output is needed as input for another tool, make only the first tool call and wait for results.
- Stop immediately after and output `[Pause]` to wait for results.
### Step 2: Wait for Results
After you propose execute steps, stop immediately after and output `[Pause]` to wait for results.
### Step 3: Interpret & Replan
Once the Execute Agent returns results, analyze them inside `<thinking></thinking>`.
- If the results contain information needed for subsequent tool calls (like chunk IDs from ChunkFilter), use those actual values in your next tool calls.
- Propose next actions until you have enough information to answer.
### Step 4: Final Answer
Only when confident, output:
```<thinking>Final reasoning with comprehensive analysis of all evidence found</thinking><answer>Final answer with timestamps, locations, visual descriptions, and supporting evidence</answer>
```
{num_cameras_info}
{video_length_info}
CRITICAL ASSUMPTION: ALL queries describe scenes from video content that you must search for using your tools. NEVER treat queries as logic puzzles or general knowledge questions - they are ALWAYS about finding specific video content.
## Available Tools
You can call any combination of these tools by using separate <execute> blocks for each tool call. Additionally, if you include multiple queries in the same call, they must be separated by ';'.
### 1. ChunkSearch
#### Query Formats:
## Single Query
```
<execute>
<step>1</step>
<tool>chunk_search</tool>
<input>
<query>your_question</query>
<topk>10</topk>
</input>
</execute>
```
## Multiple Query
```
<execute>
<step>1</step>
<tool>chunk_search</tool>
<input>
<query>your_question;your_question;your_question</query>
<topk>10</topk>
</input>
</execute>
```
- Use case:
- Returns a ranked list of chunks, with the most relevant results at the top. For example, given the list [d, g, a, e], chunk d is the most relevant, followed by g, and so on.
- Assign topk=15 for counting problem, assign lower topk=8 for other problem
- Try to provide diverse search queries to ensure comprehensive result(for example, you can add the options into queries).
- You must generate a question for **every chunk returned by the chunk search** — do not miss any one!!!!!
- The chunk search cannot handle queries related to the global video timeline, because the original temporal signal is lost after all video chunks are split. If a question involves specific video timing, you need to boldly hypothesize the possible time range and then carefully verify each candidate chunk to locate the correct answer.
### 2. ChunkFilter
#### Query Formats:
Question about time range:
```
<execute>
<step>1</step>
<tool>chunk_filter</tool>
<input>
<range>start_time:end_time</range>
</input>
</execute>
```
Question about specific camera/video and time range:
```
<execute>
<step>1</step>
<tool>chunk_filter</tool>
<input>
<range>start_time:end_time</range>
<camera_id>camera_X</camera_id>
</input>
</execute>
```
- Use case:
- If the question mentions a specific timestamp or time, you must convert it to seconds as numeric values.
- **CRITICAL**: The range format must be <start_seconds>:<end_seconds> using ONLY numeric values in seconds.
- **DO NOT use time format like HH:MM:SS**. Convert all times to total seconds first.
- **IMPORTANT**: For camera_id, always use the format "camera_X" or "video_X" where X is the camera/video number (e.g., camera_1/video_1, camera_2/video_2, camera_3/video_3, camera_4/video_4, etc.) Mention the camera_id only when the question is about a specific camera/video.
**Time Conversion Examples:**
- "What happens at 00:05?" (5 seconds) -> Query `<execute><step>1</step><tool>chunk_filter</tool><input><range>5:15</range></input></execute>`
- "What happens at 2:15?" (2 minutes 15 seconds = 135 seconds) -> Query `<execute><step>1</step><tool>chunk_filter</tool><input><range>135:145</range></input></execute>`
- "Describe the action in the first minute." (0 to 60 seconds) -> Query `<execute><step>1</step><tool>chunk_filter</tool><input><range>0:60</range></input></execute>`
- "Events at 1:30:45" (1 hour 30 min 45 sec = 5445 seconds) -> Query `<execute><step>1</step><tool>chunk_filter</tool><input><range>5445:5455</range></input></execute>`
### 3. EntitySearch
#### Query Formats:
```
<execute>
<step>1</step>
<tool>entity_search</tool>
<input>
<query>your_question</query>
</input>
</execute>
```
- Use case:
- Returns a ranked list of entities, with the most relevant results at the top. For example, given the list [a, b, c, d, e], entity a is the most relevant, followed by b, and so on.
- Best for finding specific people, objects, or locations in video content
- Use when you need to track or identify particular entities across video segments
## SUGGESTIONS
- Try to provide diverse search queries to ensure comprehensive result(for example, you can add the options into queries).
- For counting problems, remember it is the same video, do not sum the results from multiple chunks.
- For ordering, you can either use the chunk_id or the timestamps to determine the order.
## Strict Rules
1. Response of each round should provide thinking process in <thinking></thinking> at the beginning!! Never output anything after [Pause]!!
2. You can only concatenate video chunks that are TEMPORALLY ADJACENT to each other (n;n+1), with a maximum of TWO at a time!!!
3. If you are unable to give a precise answer or you are not sure, continue calling tools for more information; if the maximum number of attempts has been reached and you are still unsure, choose the most likely one.
4. **DO NOT CONCLUDE PREMATURELY**: For complex queries (especially cross-camera tracking), you MUST make multiple tool calls and exhaust all search strategies before providing a final answer. One tool call is rarely sufficient for comprehensive analysis.
response_sys_msg_prompt: |+
You are a response agent that provides comprehensive answers based on analysis and tool results.
**CORE REQUIREMENTS:**
- Provide detailed, evidence-based answers with timestamps, locations, and visual descriptions
- Include ALL relevant findings and supporting evidence from the analysis
- Explain your conclusions and provide chronological context when relevant
- Never include chunk IDs or internal system identifiers in responses
**FORMATTING:**
- Use factual, direct language without pleasantries ("Certainly!", "Here is...", etc.)
- State "No relevant information found" if no relevant data was discovered
- Follow user-specified format requirements exactly (yes/no only, case requirements, length constraints, etc.)
- When format is specified, prioritize format compliance over comprehensive explanations
evaluation_guidance_prompt: |+
**EVALUATION GUIDANCE:**
- Conclude with gathered information if repeated tool calls yield the same results
- Never repeat identical tool calls that return no results or empty results
- For failed searches: try ChunkSearch for specific entities or break down complex terms into simpler components
Tools Configuration#
CA-RAG requires various tools and services to be configured in your config/config.yaml file. All configurations are defined under the tools section and use environment variables for sensitive information.
Milvus (Vector Database)#
Used for vector storage and retrieval in vector-based strategies.
tools:
vector_db:
type: milvus
params:
host: !ENV ${MILVUS_DB_HOST}
port: !ENV ${MILVUS_DB_GRPC_PORT}
tools:
embedding: nvidia_embedding
Neo4j (Graph Database)#
Used for graph storage and retrieval in graph-based strategies.
tools:
graph_db:
type: neo4j
params:
host: !ENV ${GRAPH_DB_HOST}
port: !ENV ${GRAPH_DB_BOLT_PORT}
username: !ENV ${GRAPH_DB_USERNAME}
password: !ENV ${GRAPH_DB_PASSWORD}
tools:
embedding: nvidia_embedding
- Optional Parameters:
embedding_parallel_count (int): Max parallelism for embedding tasks. Default: 1000.
ArangoDB (Graph Database)#
Used for graph storage and retrieval in graph-based strategies.
tools:
graph_db_arango:
type: arango
params:
host: !ENV ${ARANGO_DB_HOST}
port: !ENV ${ARANGO_DB_PORT}
username: !ENV ${ARANGO_DB_USERNAME}
password: !ENV ${ARANGO_DB_PASSWORD}
tools:
embedding: nvidia_embedding
Note
ArangoDB is not supported on aarch64 platforms.
- Optional Parameters:
collection_name (str): Base name used to derive vertex/edge collections. Default: default_<uuid>.
Elasticsearch (Vector Database)#
Used for vector storage and retrieval in vector-based strategies.
tools:
elasticsearch_db:
type: elasticsearch
params:
host: !ENV ${ES_HOST}
port: !ENV ${ES_PORT}
tools:
embedding: nvidia_embedding
- Optional Parameters:
collection_name (str): Index name to create/use. Default: default_<uuid>.
Large Language Models (LLM)#
Configure LLM services for text generation and reasoning.
tools:
chat_llm:
type: llm
params:
model: meta/llama-3.1-70b-instruct
base_url: https://integrate.api.nvidia.com/v1
temperature: 0.2
top_p: 0.7
openai_llm:
type: llm
params:
model: gpt-4o
base_url: https://api.openai.com/v1
temperature: 0.5
top_p: 0.7
api_key: !ENV ${OPENAI_API_KEY}
- Optional Parameters:
max_tokens (int, optional): Max tokens for legacy/completion models. Default: 2048.
max_completion_tokens (int, optional): Max tokens for new OpenAI reasoning models. Default: None.
temperature (float, optional): Randomness in generation (higher is more random). Default: 0.2.
top_p (float, optional): Nucleus sampling probability mass (disabled for reasoning models). Default: 0.7.
api_key (str, optional): API key for the configured backend. Default: “NOAPIKEYSET”.
reasoning_effort (str, optional): Optional reasoning mode hint (LLM‑specific). Default: None.
Embedding Models#
Configure embedding models for vector generation.
tools:
nvidia_embedding:
type: embedding
params:
model: nvidia/llama-3.2-nv-embedqa-1b-v2
base_url: https://integrate.api.nvidia.com/v1
api_key: !ENV ${NVIDIA_API_KEY}
- Optional Parameters:
truncate (str): How to truncate long inputs (e.g., END). Default: END.
Reranker Models#
Configure reranker models for improving retrieval accuracy.
tools:
nvidia_reranker:
type: reranker
params:
model: nvidia/llama-3.2-nv-rerankqa-1b-v2
base_url: https://ai.api.nvidia.com/v1/retrieval/nvidia/llama-3_2-nv-rerankqa-1b-v2/reranking
api_key: !ENV ${NVIDIA_API_KEY}
- Optional Parameters:
top_n (int): Number of chunks to rerank. Default: 5.
Image Fetcher#
Configure MinIO for video frame storage and retrieval.
tools:
image_fetcher:
type: image
params:
minio_host: !ENV ${MINIO_HOST}
minio_port: !ENV ${MINIO_PORT}
minio_username: !ENV ${MINIO_USERNAME}
minio_password: !ENV ${MINIO_PASSWORD}
Multi-Stream Support#
CA-RAG enables concurrent processing of multiple live streams or video files. Each caption and entity is tagged with stream-id and camera-id metadata, enabling precise retrieval of content from specific streams or cameras.
It is recommended to use Advanced Retrieval with Multi-stream processing to get the best results.
Note
Multi-stream processing is currently supported only for Neo4j and ArangoDB. It is not supported for Elasticsearch or Milvus.
Configuration
To enable multi-stream processing, configure the following parameters in config/config.yaml:
Set
multi_channeltotrue(default:false)Set
disable_entity_descriptiontofalsefor improved accuracy (default:true)Set
deduplicate_nodestotrueto remove duplicate entities based on name and description (default:false)
Note
To use disable_entity_description, you will need LLM with structured output capabilities.
Example Configuration
tools:
graph_db:
type: neo4j
params:
host: !ENV ${GRAPH_DB_HOST}
port: !ENV ${GRAPH_DB_PORT}
username: !ENV ${GRAPH_DB_USERNAME}
password: !ENV ${GRAPH_DB_PASSWORD}
tools:
embedding: nvidia_embedding
chat_llm:
type: llm
params:
model: meta/llama-3.1-70b-instruct
base_url: https://integrate.api.nvidia.com/v1
max_tokens: 4096
temperature: 0.5
top_p: 0.7
api_key: !ENV ${NVIDIA_API_KEY}
nvidia_embedding:
type: embedding
params:
model: nvidia/llama-3.2-nv-embedqa-1b-v2
base_url: https://integrate.api.nvidia.com/v1
api_key: !ENV ${NVIDIA_API_KEY}
functions:
summarization:
type: batch_summarization
params:
batch_size: 5
batch_max_concurrency: 20
prompts:
caption: "Write a concise and clear dense caption for the provided warehouse video, focusing on irregular or hazardous events such as boxes falling, workers not wearing PPE, workers falling, workers taking photographs, workers chitchatting, forklift stuck. Start and end each sentence with a time stamp."
caption_summarization: "You should summarize the following events of a warehouse in the format start_time:end_time:caption. For start_time and end_time use . to seperate seconds, minutes, hours. If during a time segment only regular activities happen, then ignore them, else note any irregular activities in detail. The output should be bullet points in the format start_time:end_time: detailed_event_description. Don't return anything else except the bullet points."
summary_aggregation: "You are a warehouse monitoring system. Given the caption in the form start_time:end_time: caption, Aggregate the following captions in the format start_time:end_time:event_description. If the event_description is the same as another event_description, aggregate the captions in the format start_time1:end_time1,...,start_timek:end_timek:event_description. If any two adjacent end_time1 and start_time2 is within a few tenths of a second, merge the captions in the format start_time1:end_time2. The output should only contain bullet points. Cluster the output into Unsafe Behavior, Operational Inefficiencies, Potential Equipment Damage and Unauthorized Personnel"
tools:
llm: chat_llm
db: graph_db
ingestion_function:
type: graph_ingestion
params:
batch_size: 1
deduplicate_nodes: true
disable_entity_description: false
allowed_nodes: ["person", "vehicle", "object", "location"] #default
allowed_relationships: [] #default
multi_channel: true
duplicate_score_value: 0.9 #default
tools:
llm: chat_llm
db: graph_db
retriever_function:
type: adv_graph_retrieval
params:
top_k: 5
batch_size: 1
multi_channel: true # Enable for multi-stream processing
tools:
llm: chat_llm
db: graph_db
context_manager:
functions:
- summarization
- ingestion_function
- retriever_function
ArangoDB Configuration#
ArangoDB is supported for multi-stream processing. Just replace graph_db with the following configuration:
tools:
graph_db:
type: arango
params:
host: !ENV ${ARANGO_DB_HOST}
port: !ENV ${ARANGO_DB_PORT}
username: !ENV ${ARANGO_DB_USERNAME}
password: !ENV ${ARANGO_DB_PASSWORD}
multi_channel: true
tools:
embedding: nvidia_embedding
Alerts#
The Alerts feature allows event-based notifications. For each VLM caption, an LLM analyzes and generates alerts based on the natural language defined event criteria.
For example, to configure alerts for a traffic video to detect accidents, the criteria can be defined in natural language in the UI Application.
incident: accident on the road;
response: first responders arrive for help;
When an alert is detected, the response is sent to the user using the VSS notification system. Here is an example of the alert notification:
Alert Name: incident
Detected Events: accident on the road
Time: 80 seconds
Details: 2026-03-15 12:07:39 PM: The scene depicts an intersection with painted
stop lines and directional arrows on the road surface. A red sedan and a yellow
sedan are involved in a collision within the intersection. The red sedan appears to
be impacting the yellow sedan on its front passenger side.
Observability#
CA-RAG provides OpenTelemetry (OTEL) traces for observability that can be viewed in the Jaeger or Phoenix UI.
To enable OTEL traces, set the following environment variables:
export VIA_CTX_RAG_ENABLE_OTEL=true
export VIA_CTX_RAG_EXPORTER=otlp # if you want to view OTEL traces in the Jaeger UI, otherwise set 'console'
export VIA_CTX_RAG_OTEL_ENDPOINT=http://otel_collector:4318 # if exporter is set to 'otlp'