Architecture#
Tokkio implements a distributed, event-driven architecture composed of multiple parallel processing pipelines. The system utilizes a message bus for inter-service communication, with stream lifecycle events (client connect/disconnect) triggering pipeline execution. Scaling is achieved by using NVIDIA SDR (Stream Distribution and Routing) to distribute the load across multiple GPUs. This is covered in more detail in the Scaling & Dynamic Routing section.
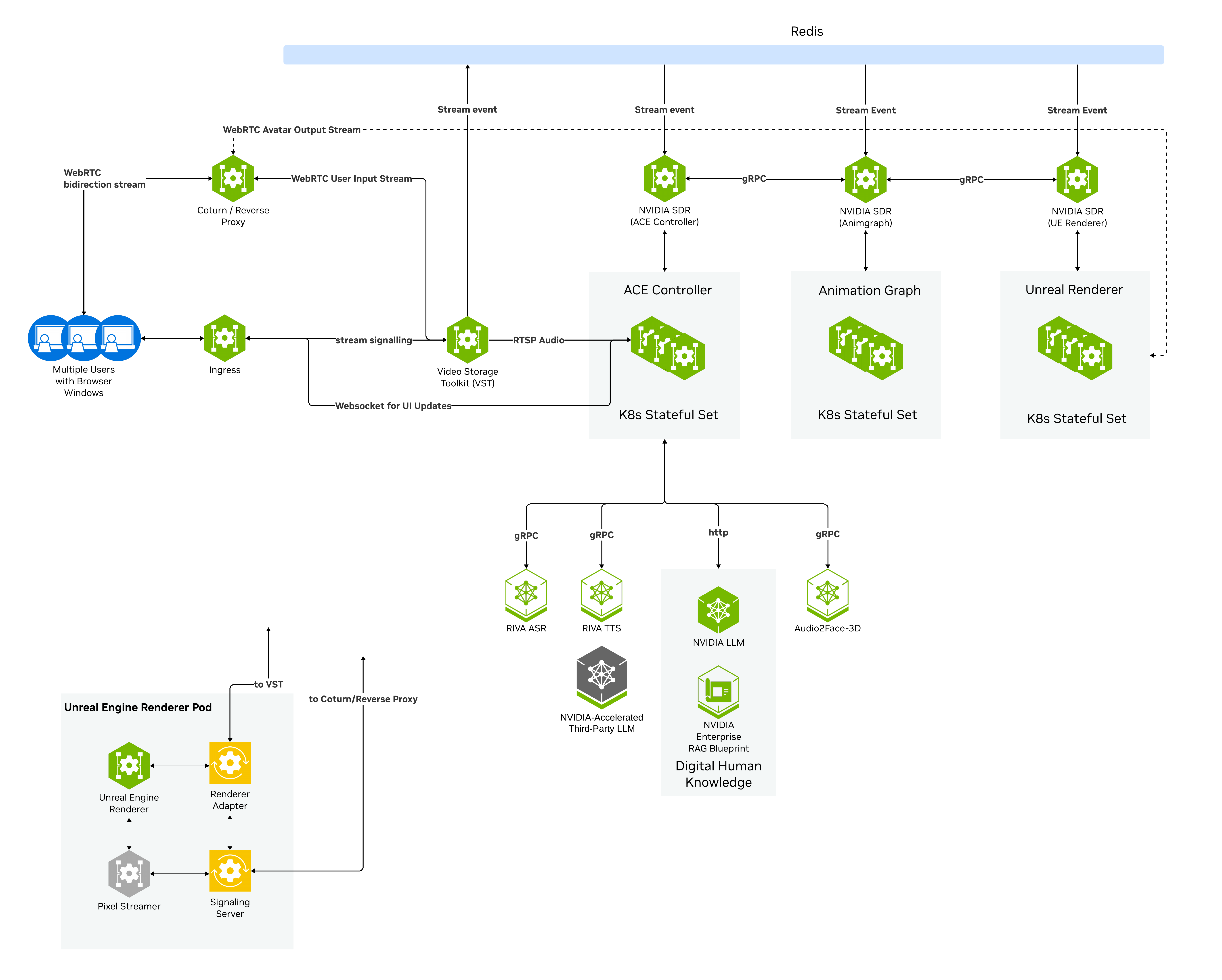
Workflow#
The following sequence of operations describes the high-level workflow of the system when a user opens the Tokkio web app and starts a conversation with the avatar:
The Tokkio Web UI establishes a WebRTC connection through the coturn server with VST. It uses a WebSocket connection for WebRTC signaling.
VST sends a Redis message indicating that a new client has connected and a new input stream is available for processing. It also creates a unique streamID.
SDR receives this Redis message and routes the stream to an available pod for the ACE Controller, Animation Graph, and Unreal Renderer microservices.
The renderer begins streaming the avatar video to the web UI.
On the input side, the ACE Controller connects to VST to receive the audio stream and starts processing the live audio.
The ACE Controller processes the audio, connects to the digital human knowledge base, and generates a response. It calls into the TTS services to generate a streaming audio response.
The streaming audio response is sent to the Audio2Face-3D service, which generates the 3D avatar facial animation.
The ACE Controller sends this animation data and the audio response to the Animation Graph microservice together with additional gesture triggers.
The Animation Graph microservice generates the final animation and sends it to the renderer along with the audio response.
The renderer applies the animation to the 3D avatar, renders the video, and streams the result to the web UI.
Additionally, the web UI maintains a WebSocket connection to the ACE Controller, which allows for sending additional information to the web UI, including transcripts, tables, and images to be displayed alongside the avatar.
Let’s look at some of the pipeline components in more detail:
Streaming Pipeline
ACE Controller Pipeline
Animation Pipeline
Streaming Pipeline#
The streaming pipeline manages bidirectional audio/video communication between the web UI and the backend system:
Protocol: WebRTC for media transmission
Signaling: WebSocket-based connection establishment
Components:
Video Storage Toolkit (VST) for media handling
TURN server for NAT traversal
Multimodal web UI, which enables audio and video communication along with the capability to display tables and images alongside the avatar
Epic’s Pixel Streaming technology of the Unreal Engine, used to stream the avatar video to the web UI
ACE Controller Pipeline#
The ACE Controller is based on Pipecat, an open-source Python orchestrator designed for digital human pipelines. This pipeline orchestrates real-time avatar interactions through the following stages:
Input Speech & Context Processing
Uses Riva ASR for speech recognition and transcribes the audio into text
Integration with External Knowledge Bases
NVIDIA NIM
OpenAI APIs
RAG (Retrieval-Augmented Generation) systems
Response Generation with Speech Synthesis and Transcript Synchronization
Uses Eleven Labs TTS for speech synthesis and transcribes the text into audio
Avatar Control
Facial expression management
Gesture coordination
Posture control
Multimodal Output
Connects to the web UI via WebSocket to send transcripts, tables, and images
Animation Pipeline#
The animation pipeline handles avatar rendering and animation through three core components:
The pipeline processes input signals to generate synchronized avatar animations and visual output.