Reference Workflow#
Tokkio comes with a reference workflow of a LLM-RAG Agent that covers a broad use case that serves as a starting point for various user-specific applications. This reference workflow can then be further customized as described in the Customization Options. More details regarding the workflow are below.
Tokkio LLM-RAG#
The Tokkio LLM-RAG sample application is designed to facilitate live interactions with the digital humans using popular Large Language Model (LLM) or Retrieval-Augmented Generation (RAG) solutions.
You may connect Tokkio with LLMs and RAGs from common platforms such as NVIDIA NIM, OpenAI, and NVIDIA Generative AI Examples foundational RAG. Users may also connect compatible third-party LLMs or RAGs.
Note
A compatible LLM is required for successful integration with the Tokkio reference workflow. The compatibility factors include streaming. Also, some of the reasoning models may not be compatible with Tokkio reference workflow due to extra fields in the response structure.
Minimum GPU Requirements#
T4 |
L4 |
A10 |
|
|---|---|---|---|
1 stream |
2x |
2x |
2x |
3 streams |
4x |
4x |
4x |
6 streams |
4x |
4x |
Artifacts#
Source code: NVIDIA/ACE
Application specs: NVIDIA/ACE
Helm chart variations: Note that the helm chart variations with and without UI are available for 1, 3, and 6 streams. The ones without UI require a separate/local deployment of the Tokkio UI outside the Tokkio deployment.
1 stream with UI: https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ace/helm-charts/tokkio-1stream-with-ui/files?version=5.0.0-GA
1 stream without UI: https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ace/helm-charts/tokkio-1stream-no-ui/files?version=5.0.0-GA
3 stream with UI: https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ace/helm-charts/tokkio-3stream-with-ui/files?version=5.0.0-GA
3 stream without UI: https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ace/helm-charts/tokkio-3stream-no-ui/files?version=5.0.0-GA
6 stream with UI: https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ace/helm-charts/tokkio-6stream-with-ui/files?version=5.0.0-GA
6 stream without UI: https://catalog.ngc.nvidia.com/orgs/nvidia/teams/ace/helm-charts/tokkio-6stream-no-ui/files?version=5.0.0-GA
The following table describes the important files within LLM RAG Agent source code.
File name |
Description |
|---|---|
bot.py |
This is the main file dictates the frame processors and their parameters used for the Tokkio llm rag agent pipeline. |
custom_view_processor.py |
The CustomViewProcessor is a specialized processor that handles the visualization of data from RAG (Retrieval Augmented Generation) citations in the UI. |
otel.py |
This file sets up OpenTelemetry (OTEL) tracing for the application. |
serializer.py |
This file implements a WebSocket serializer (TokkioUIWebSocketSerializer) that handles the conversion between Python objects and JSON messages for real-time communication between the server and client. |
config.py |
This file defines the configuration structure for the application using Pydantic models. |
LLM RAG Agent Pipeline#
The Tokkio LLM-RAG agent pipeline consists of the components from the ACE Controller NVIDIA-pipecat library. For more details regarding the ACE Controller, please refer to ACE Controller Microservice. Note that in the diagram below, the pipeline is shown cascaded across multiple lines for visibility.
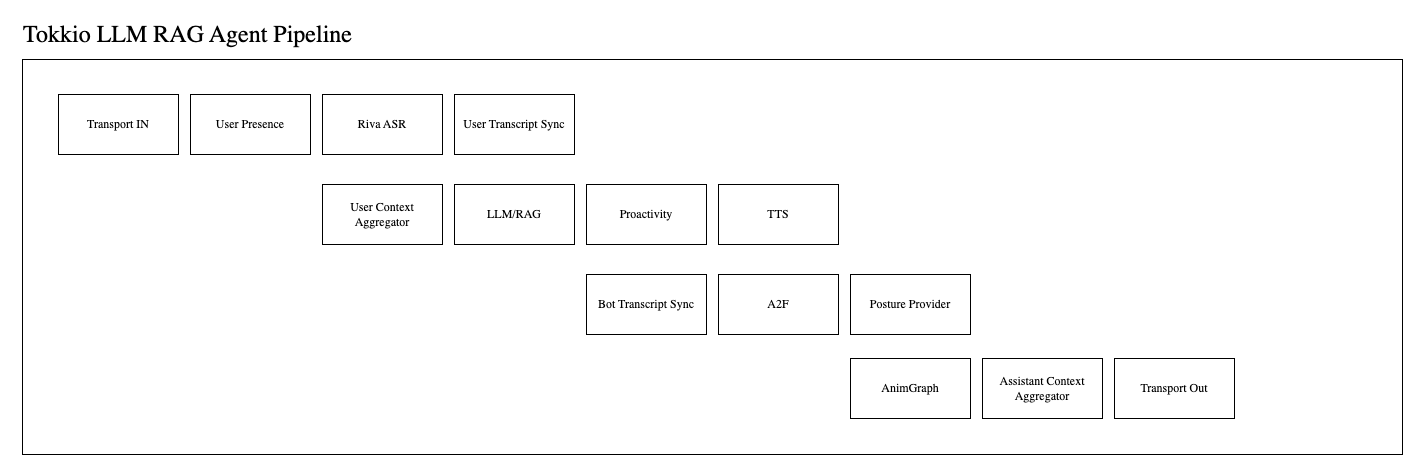
The pipeline is designed to facilitate live interactions with the digital humans using popular Large Language Model (LLM) or Retrieval-Augmented Generation (RAG) solutions. The pipeline consists of the following components:
Transport IN : The LLM RAG Agent uses the ACETransport. The input transport for the ACETransport has support for RTSP and WebSocket connections.
User Presence: The user presence processor is responsible for greeting the user on detecting user presence. Before detecting user presence, the conversation pipeline (forwarding queries to RAG/LLM) is not active. A farewell message is also sent to the user when user absence is detected.
User Transcript Sync: This processor is used to synchronize user transcripts in the UI
User Context Aggregator: This processor aggregates the user specific context.
LLM/RAG processor: Depending on the chosen configuration (RAG or LLM), this processor is responsible for forwarding user queries to RAG/LLM and processing the response.
Proactivity processor: This processor encourages the user to communicate if there is a long pause in the conversation.
Text-to-speech processor: This processor is responsible for converting the text response from LLM/RAG to speech.
Bot Transcript Sync: Used to synchronize the bot transcripts in the UI.
Facial Gesture Provider: Provides facial gestures to the bot based on pre-configured speaking states.
A2F: This is used for processing audio data and sending it to Audio2Face-3D microservice deployed with Tokkio.
Posture Provider: Handles bot postures based on the current state of the conversation. E.g.: Talking/Listening/Attentive.
AnimGraph: This processor implements an animation graph microservice deployed with Tokkio for managing avatar animations.
Assistant Context Aggregator: This processor aggregates the bot (assistant) specific context.
Transport Out: This is the output transport for the ACETransport. It has support for WebSocket connections for audio and frames output.
Note that the pipeline here is configurable to add or remove processors as needed by the application. The entire agent pipeline resides with the ACE Controller microservice within the Tokkio application. The diagram is shown below for reference.
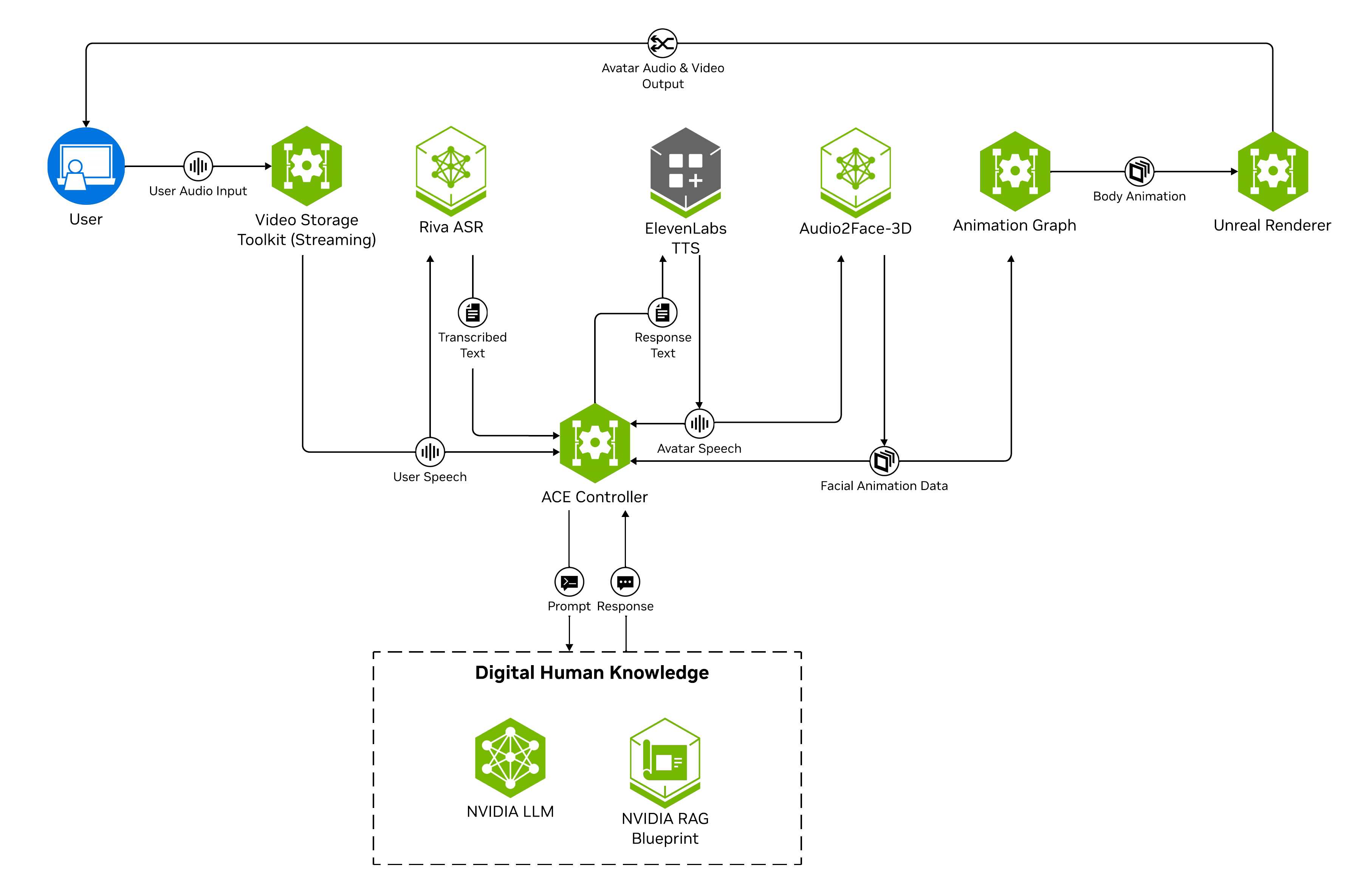
The default version of Tokkio LLM-RAG, deployed in the quick start guide, leverages a NIM LLM to generate user responses. One can switch to using a compatible RAG for response generation. Please refer to Digital Human Agent Customization for more information regarding the customization.
The application extends default support for any external RAG server that adheres to the schema from NVIDIA RAG Blueprint Schema.
The RAG from NVIDIA Generation AI examples refers to a RAG server that uses NVIDIA hosted embeddings + reranking + llm endpoints to respond to a user with enhanced context from the ingested documents.
Please refer to NVIDIA RAG Blueprint and follow the deployment instructions to deploy the RAG server and ingest the relevant documents.
Please refer to RAG Server for more information regarding the recommended RAG server settings.
Customization#
The LLM RAG Agent default pipeline serves as a reference implementation. It can be customized in a number of ways. The section Digital Human Agent Customization provides a non-exhaustive list of various customizations that can be achieved.
Custom Avatar Creation#
Please refer to the Unreal Renderer Microservice Introduction section for an introduction regarding the use of Unreal Engine for Tokkio and the custom avatar creation steps.