Isaac GR00T: Vision-Language-Action Models#
What Do I Need for This Module?
Mostly theory with code examples. No additional hardware is required beyond a computer with the real-robot container built.
In this session, we’ll explore the VLA model called NVIDIA Isaac GR00T, how it works, and see examples of it in action.
Learning Objectives#
By the end of this session, you’ll be able to:
Explain what vision-language-action models are and why they’re powerful
Describe the GR00T architecture and its components
Understand how VLAs differ from traditional robot learning approaches
What Is GR00T?#
NVIDIA Isaac GR00T (Generalist Robot 00 Technology) is a research initiative and development platform for developing general-purpose robot foundation models and data pipelines to accelerate humanoid robotics research and development.
It provides:
Pre-trained visual understanding from large-scale data
Language-conditioned behavior for flexible task specification
Action generation suitable for real-time robot control
In this course, we’ll use GR00T N1.6 models post-trained for the SO-101 robot.
Note
Training time in this course
GR00T post-training requires several hours on GPU hardware. We have pre-trained a set of policies on various datasets that you can use as a start. This lets you focus on understanding the workflow, evaluating results, and iterating on strategies rather than waiting for training jobs to complete.
The commands and scripts shown here are the same ones used to produce those policies, so you can replicate the process on your own hardware after you finish this learning path.
What Is a Vision-Language-Action Model?#
Vision-Language-Action (VLA) models are foundation models that take visual input and language instructions and output low-level or mid-level actions for an embodied agent, such as a robot.
Input: Camera image (1 or more) + "Pick up the red vial and place it in the rack"
Output: Sequence of joint positions/velocities to execute the task
Defining Terminology#
Understanding VLA Training Stages#
VLA models are not trained in a single step. They go through distinct phases, each building on the previous one.
Understanding these stages helps explain how a model progresses from broad world knowledge to task-specific robot behavior, and why each phase matters for sim-to-real transfer.
Pre-training is the first and largest training phase. The model learns general representations from internet-scale data, including images, text, video, and increasingly, robot demonstrations.
No specific robot task is being taught yet. Instead, the model develops broad capabilities such as object recognition, spatial reasoning, and grounding language in visual context. You can think of this as building a world model before the model ever sees your specific robot task.
Post-training is the umbrella term for everything that happens after pre-training to make a general model useful for a specific robot, task, or environment.
This is where a pretrained foundation model is adapted to a specific embodiment and task using demonstrations that map observations and language instructions to robot actions. Post-training is computationally intensive and typically requires several hours on GPU hardware.
Note
This is the stage you run in this course: taking the pretrained GR00T N1.6 foundation model and adapting it to SO-101 data collected in simulation.
Fine-tuning is a specific form of post-training where you continue training on a smaller, targeted dataset to improve performance in a specific setting.
For example, after post-training on simulation data, you might fine-tune on a small set of real-robot demonstrations to reduce the sim-to-real gap. Fine-tuning aims to preserve general capabilities while adapting behavior to new conditions.
Inference is when the trained model runs in real time. It receives camera frames and a language instruction, then outputs joint position commands.
No learning happens during inference because model weights are frozen. Speed matters here. Techniques such as action chunking, where the model predicts multiple timesteps at once, reduce forward passes and produce smoother motion. On modern GPU hardware, this supports real-time closed-loop control.
Architecture Overview#
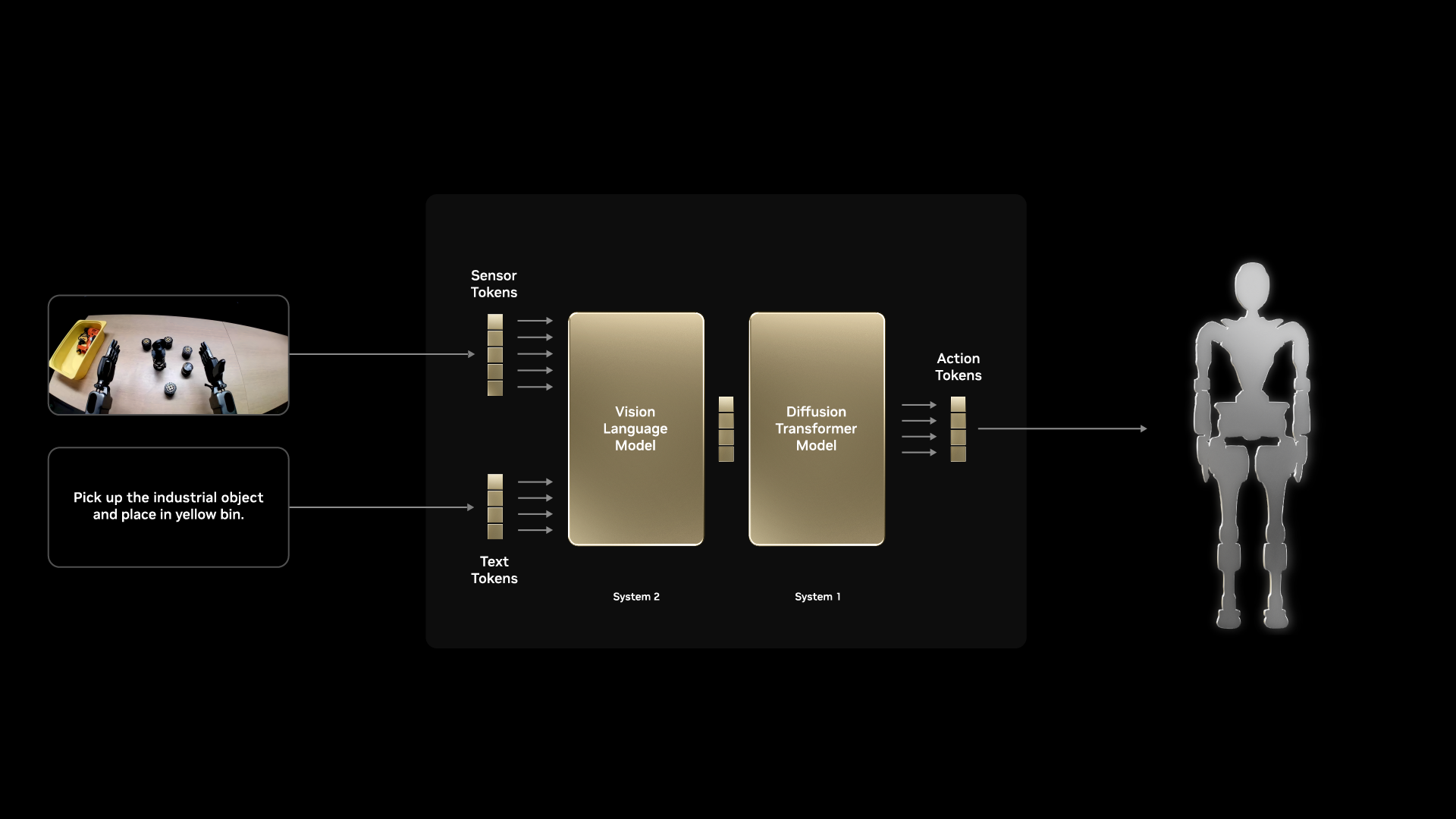
Key Components#
Vision Encoder: Processes camera images into rich feature representations
Pre-trained on large image datasets (ImageNet, etc.)
Understands objects, spatial relationships, affordances
Language Encoder: Processes task instructions
Maps natural language to task embeddings
Enables zero-shot generalization to new task descriptions
Cross-Modal Fusion: Combines vision and language
Attention mechanisms to relate visual features to language
Grounds language concepts in visual observations
Action Decoder: Generates robot actions
Conditioned on fused visual-language features
Outputs appropriate action representation (joint positions, velocities, etc.)
Action Space and Control#
Action Representations#
GR00T supports several action representations:
Joint Position Actions
Direct control over robot configuration
Requires learning full arm coordination
End-Effector Actions
Inverse kinematics computes joint commands
Abstracts away arm configuration
Action Chunking
Predict multiple future actions at once
Smoother execution, temporal consistency
In this course, we use joint position actions with action chunking.
Action Horizon Parameter#
The action_horizon parameter controls how many future actions the model predicts at once. This is a critical hyperparameter that affects both training and deployment.
What it controls:
Training: The model learns to predict
action_horizontimesteps into the futureInference: The model outputs a chunk of
action_horizonactions per forward pass
Trade-offs:
Horizon |
Pros |
Cons |
|---|---|---|
Short (4-8) |
More reactive, corrects quickly |
Choppy motion, frequent replanning |
Medium (16) |
Balanced smoothness and reactivity |
Good default for most tasks |
Long (32+) |
Very smooth trajectories |
Slow to correct errors, may overshoot |
Tip
Start with the default action_horizon=16. Only adjust if you observe specific issues: reduce if the robot overshoots targets, increase if motion is too jerky.
Hands-On: Run GR00T Post-Training Yourself#
You can follow either path:
Use the fine-tuned models we provide in this course. In this case, skip this module.
Run your own post-training workflow using the steps below. You can also use your own hardware - we recommend the Brev Launchable route because it sets up the environment for you.
Note
Make sure to update to match your repo IDs throughout this section. Example ones are provided in commands.
Launch a GR00T Launchable instance. Brev is a pay-by-the-hour way to access GPU compute in the cloud.

Alternatively you can also train locally, in which case you’ll want to checkout the GR00T 1.6 repo and setup the virtual environment per the
README.Set environment variables to identify the Hugging Face dataset, define the conversion output location, and derive the local dataset path used by later commands.
export HF_DATASET_REPO_ID="sreetz-nv/so101_teleop_vials_rack_left"
export CONVERSION_ROOT="sreetz-nv_so101_teleop_vials_rack_left_conv"
export DATASET_DIR="${CONVERSION_ROOT}/${HF_DATASET_REPO_ID}"
Replace HF_DATASET_REPO_ID and derived names with your own dataset naming.
Convert the LeRobot dataset from v3 format to v2 format under the conversion root.
uv run --project scripts/lerobot_conversion python scripts/lerobot_conversion/convert_v3_to_v2.py \
--repo-id "${HF_DATASET_REPO_ID}" \
--root "${CONVERSION_ROOT}"
Copy the SO-100 modality metadata to the converted dataset metadata directory so GR00T can interpret the dataset structure.
cp examples/SO100/modality.json "${DATASET_DIR}/meta/"
Activate the GR00T virtual environment.
source "/home/ubuntu/Isaac-GR00T/.venv/bin/activate"
Set fine-tuning configuration variables to select the GPU, define the embodiment tag, name the run, and set the training output directory.
export NUM_GPUS=1
export CUDA_VISIBLE_DEVICES=0
export EMBODIMENT_TAG="NEW_EMBODIMENT"
export RUN_NAME="so101_teleop_vials_rack_left"
export OUTPUT_DIR="/ephemeral/${RUN_NAME}"
Run fine-tuning.
python gr00t/experiment/launch_finetune.py \
--base_model_path nvidia/GR00T-N1.6-3B \
--dataset_path "${DATASET_DIR}" \
--modality_config_path examples/SO100/so100_config.py \
--embodiment_tag "${EMBODIMENT_TAG}" \
--num_gpus "${NUM_GPUS}" \
--output_dir "${OUTPUT_DIR}" \
--save_steps 5000 \
--save_total_limit 5 \
--max_steps 20000 \
--warmup_ratio 0.05 \
--weight_decay 1e-5 \
--learning_rate 1e-4 \
--global_batch_size 64 \
--color_jitter_params brightness 0.3 contrast 0.4 saturation 0.5 hue 0.08 \
--dataloader_num_workers 4
Authenticate with Hugging Face.
hf auth login
Create the Hugging Face model repository.
export HF_MODEL_REPO="grootn17-finetune_sreetz-so101_teleop_vials_rack_left"
hf repo create "${HF_MODEL_REPO}" --repo-type model --exist-ok
Upload model artifacts to Hugging Face.
# Upload full training output directory
hf upload "${HF_MODEL_REPO}" "${OUTPUT_DIR}" . --repo-type model
# Or upload only the final checkpoint to a specific repository
hf upload sreetz-nv/grootn16-finetune_sreetz-so101_teleop_vials_rack_left \
"${OUTPUT_DIR}/checkpoint-20000" \
. \
--repo-type model
If you used Brev, and you’re sure your files are uploaded, you can stop or delete the instance to save credits.
Practical Considerations#
Data Requirements#
VLA training typically requires:
50-200 demonstrations per task for basic competence
Language annotations describing each demonstration
Diverse conditions to enable generalization
Tip
Quality matters more than quantity. 50 high-quality, diverse demonstrations often outperform 500 redundant ones.
Compute Requirements#
GR00T training benefits from:
GPU memory: 24GB+ for full model training
Training time: 2-8 hours depending on dataset size
Inference: Real-time on modern GPUs (RTX 3080+)
Key Takeaways#
VLA models combine vision, language, and action in a unified architecture
GR00T provides pre-trained components for accelerated learning
Language conditioning enables flexible task specification
Action chunking provides smooth, temporally consistent control
Pre-trained vision encoders enable visual generalization
Resources#
NVIDIA Isaac GR00T GitHub — Source code, model weights, and documentation
What’s Next?#
Now that you understand VLAs conceptually, run policy evaluation in simulation. In the next session, Sim Evaluation, you’ll compare policies in sim using open-loop and closed-loop evaluation.