Sim Evaluation#
What Do I Need for This Module?
Hands-on. You’ll need the teleop-docker and real-robot containers and an NVIDIA GPU for Isaac Lab simulation.
In this session, you’ll run policy evaluation in simulation using the same GR00T-based setup you’ll use later on the real robot.
Learning Objectives#
By the end of this session, you’ll be able to:
Run policy evaluation in simulation using the GR00T server + client (Docker) setup
Compare how policies trained with different data quantities and augmentation behave
Identify common failure modes in simulation
What Policy Are We Going to Evaluate?#
You’ll have the choice of either using policies we trained for you, or training your own. If you use ours, make sure the workspace is set up correctly and the robot is carefully calibrated.
Tip
To use GR00T with LeRobot, follow the official LeRobot GR00T documentation for setup and integration guides. GR00T N1.5 models are natively supported and can be evaluated directly within the LeRobot framework. For GR00T N1.6, integration into LeRobot is still in progress. In the meantime, you’ll need to run training and inference using the official Isaac GR00T repository or provided Docker images for the latest model features.
We used this dataset of 75 sim demonstrations. View it on Hugging Face with the dataset visualizer. This is a sim only dataset, meaning it was trained entirely in simulation, without any real-world data. Our first strategy is to rely solely on simulation and domain randomization.
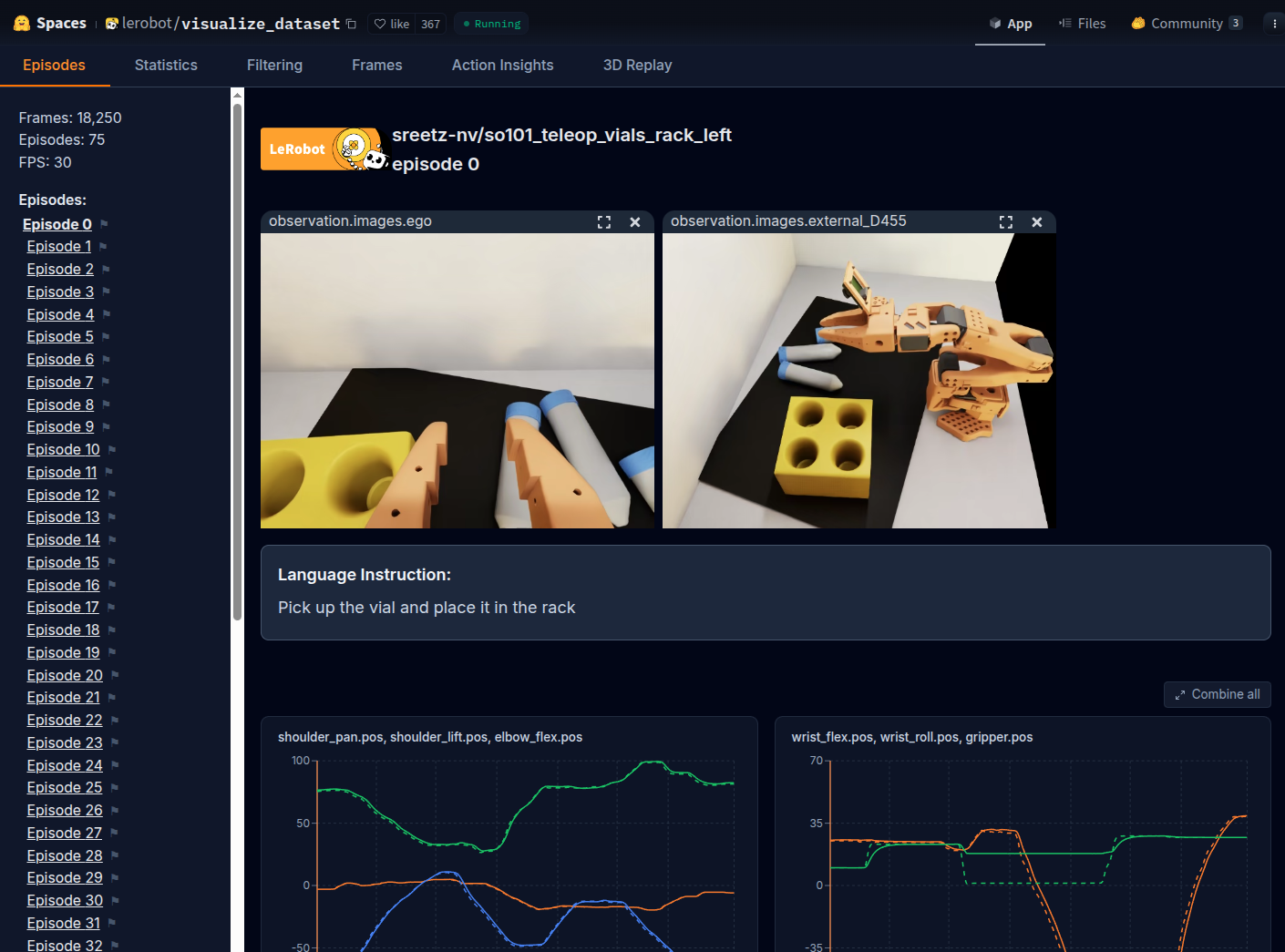
Sample episodes visualized from the sim-only demonstration dataset used for training evaluation policies.#
Running Policy Evaluation in Simulation#
Throughout this course, when we run evaluations there will be two terminals involved:
The host terminal, where we will start the GR00T container and policy server
The client terminal, where we will run the evaluation rollout and actually control the robot
For sim, the client is our simulator. For the real robot, our client is the robot itself.
Terminal 1 (real-robot container) — Start the GR00T policy server#
Open a new terminal window (CTRL+ALT+T).
Run the docker
real-robotcontainer.
xhost +
docker run -it --rm --name real-robot --network host --privileged --gpus all \
-e DISPLAY \
-v /dev:/dev \
-v /run/udev:/run/udev:ro \
-v $HOME/.Xauthority:/root/.Xauthority \
-v /tmp/.X11-unix:/tmp/.X11-unix \
-v ~/.cache/huggingface/lerobot/calibration:/root/.cache/huggingface/lerobot/calibration \
-v ~/models:/workspace/models \
-v ~/Sim-to-Real-SO-101-Workshop/docker/env:/root/env \
-v ~/Sim-to-Real-SO-101-Workshop/docker/real/scripts:/Isaac-GR00T/gr00t/eval/real_robot/SO100 \
real-robot \
/bin/bash
Inside this container, run the following to set which model to evaluate.
export MODEL=aravindhs-NV/grootn16-finetune_sreetz-so101_teleop_vials_rack_left/checkpoint-10000
Run the policy server with that model.
python Isaac-GR00T/gr00t/eval/run_gr00t_server.py \
--model-path /workspace/models/$MODEL
When you see
Server is ready and listening on tcp://0.0.0.0:5555the policy server is ready to accept connections.
Terminal 2 (teleop-docker container) — Evaluation rollout#
If you still have the
teleop-dockercontainer’s terminal open from the last module, you can skip this step. If not, expand the dropdown and run the command.
Start the Isaac Sim container used for sim teleop and sim evaluation:
xhost +
docker run --name teleop -it --privileged --gpus all -e "ACCEPT_EULA=Y" --rm --network=host \
-e "PRIVACY_CONSENT=Y" \
-e DISPLAY \
-v /dev:/dev \
-v /run/udev:/run/udev:ro \
-v $HOME/.Xauthority:/root/.Xauthority \
-v ~/docker/isaac-sim/cache/kit:/isaac-sim/kit/cache:rw \
-v ~/docker/isaac-sim/cache/ov:/root/.cache/ov:rw \
-v ~/docker/isaac-sim/cache/pip:/root/.cache/pip:rw \
-v ~/docker/isaac-sim/cache/glcache:/root/.cache/nvidia/GLCache:rw \
-v ~/docker/isaac-sim/cache/computecache:/root/.nv/ComputeCache:rw \
-v ~/docker/isaac-sim/logs:/root/.nvidia-omniverse/logs:rw \
-v ~/docker/isaac-sim/data:/root/.local/share/ov/data:rw \
-v ~/docker/isaac-sim/documents:/root/Documents:rw \
-v ~/.cache/huggingface/lerobot/calibration:/root/.cache/huggingface/lerobot/calibration \
-v ~/Sim-to-Real-SO-101-Workshop/docker/env:/root/env \
-v ~/Sim-to-Real-SO-101-Workshop:/workspace/Sim-to-Real-SO-101-Workshop \
teleop-docker:latest
This command will begin moving the robot in simulation, using an environment with less lighting variation to start.
lerobot_eval \
--task Lerobot-So101-Teleop-Vials-To-Rack-Eval \
--rename_map '{"external_D455": "front", "ego": "wrist"}' \
--action_horizon 16 \
--lang_instruction "Pick up the vial and place it in the yellow rack" \
--rerun
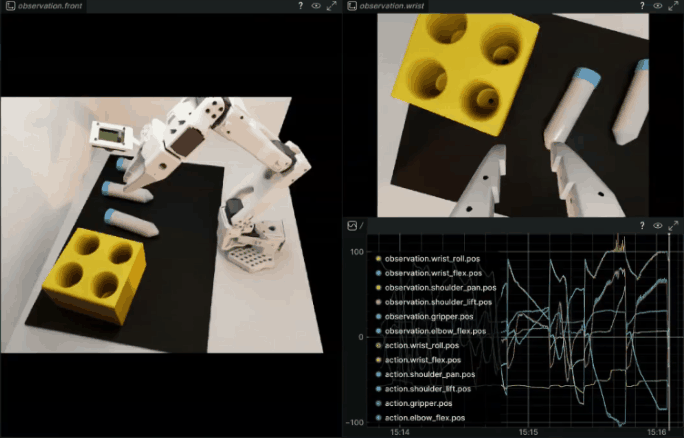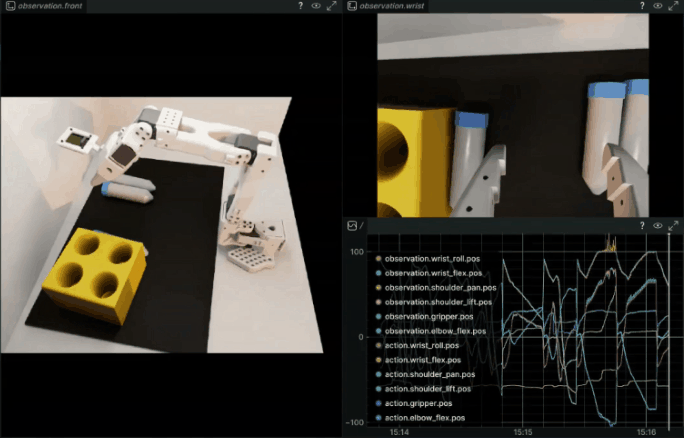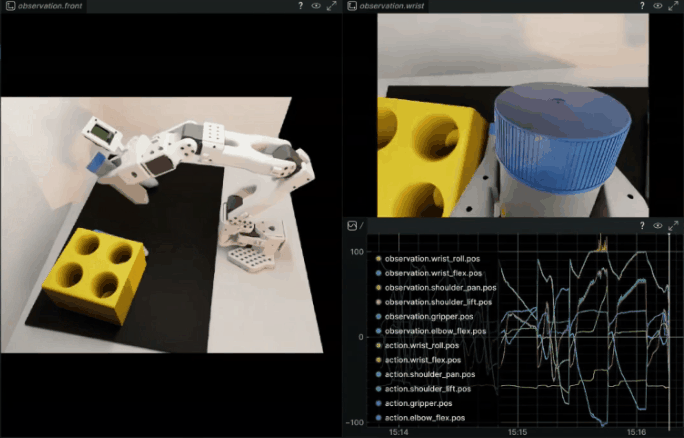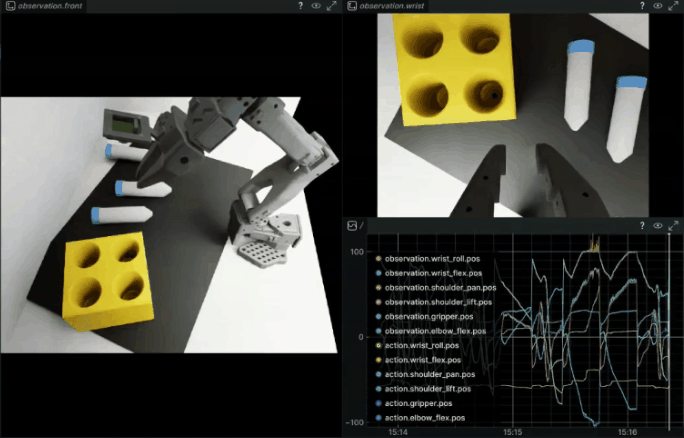
This will launch both Isaac Sim, and Rerun.
Note
The --rerun flag is optional.
It adds Rerun into the loop for debugging, so you can see joint actions and the camera feeds while the policy is running. This lets you confirm the camera views are reasonable and the assignments are correct.
(Alternatively) You can run the evaluation headlessly, meaning there is no Isaac Sim UI or Rerun visualization:
lerobot_eval \
--task Lerobot-So101-Teleop-Vials-To-Rack-Eval \
--rename_map '{"external_D455": "front", "ego": "wrist"}' \
--action_horizon 16 \
--lang_instruction "Pick up the vial and place it in the yellow rack" \
--headless
Watching the Evaluation#
Watch the terminal for evaluation of the model’s performance. The scene resets either after a timeout, or when the vial starts to enter the rack slots.
Depending on how much the vials roll around, and how dark the lighting is, expect the evaluation success rate to be between 50-70%.
Remember this dataset has a fairly low number of demonstrations (75 pick and place demos), so the policy may not be able to generalize as much as we’d ultimately need.
Example output:
Rollout (ep 7, success: 66.7%): 33%|█████████████████████▉ | 131/400 [00:06<00:15][GRASP] Vial grasped in env(s): [0]
Rollout (ep 7, success: 66.7%): 70%|██████████████████████████████████████████████▉ | 280/400 [00:14<00:06][RACK] vial_1 placed in rack in env(s): [0]
Rollout (ep 7, success: 66.7%): 70%|███████████████████████████████████████████████▏ | 282/400 [00:14<00:06]
Rollout (ep 8, success: 71.4%): 34%|
Testing Against More Lighting Variation#
We’ve preconfigured another environment with more lighting randomization. This is an example of how you can use simulation to stress test a policy against different conditions, by changing just a bit of code.
You can use that evaluation environment by running this command instead:
lerobot_eval \
--task Lerobot-So101-Teleop-Vials-To-Rack-DR-Eval \
--rename_map '{"external_D455": "front", "ego": "wrist"}' \
--action_horizon 16 \
--lang_instruction "Pick up the vial and place it in the yellow rack"
Cleanup#
When you’re done trying model evaluations:
In the teleop-docker container, press CTRL+C to stop Isaac Lab.
In the same terminal, type
exitand press Enter to exit theteleop-dockercontainer.In the real-robot container, press CTRL+C to stop the policy server. You can leave this terminal open.
Tip
If you want to see which containers are running, you can run docker ps to list all containers.
Common Failure Modes#
When observing evaluation runs, notice the failure modes. Remember that this policy was trained from a limited amount of data, only 75 demonstrations (~1 hour of teleoperation time for a seasoned operator).
Key Takeaways#
Policies trained on few demonstrations aren’t able to generalize
Domain randomization is essential for robust policies
More diverse training data beats more identical training data
These sim-only policies provide a baseline for comparison when you run on the real robot
What’s Next?#
Confirm your physical setup still matches Building the Workspace, then continue with Real Evaluation to run the same policy on the physical SO-101 and observe the sim-to-real gap.