GCP Dataproc#
Google Cloud Dataproc is Google Cloud’s fully managed Apache Spark and Hadoop service. The quick start guide will go through:
We provide some RAPIDS tools to analyze the clusters and the applications running on Google Cloud Dataproc including:
The Prerequisites of the RAPIDS tools including:
gcloud CLI is installed: https://cloud.google.com/sdk/docs/install
python 3.8-3.11
pip install spark-rapids-user-tools
Create a Dataproc Cluster Accelerated by GPUs#
You can use Cloud Shell to execute shell commands that will create a Dataproc cluster. Cloud Shell contains command line tools for interacting with Google Cloud Platform, including gcloud and gsutil. Alternatively, you can install GCloud SDK on your machine. From the Cloud Shell, users will need to enable services within your project. Enable the Compute and Dataproc APIs to access Dataproc, and enable the Storage API as you’ll need a Google Cloud Storage bucket to house your data. This may take several minutes.
1gcloud services enable compute.googleapis.com
2gcloud services enable dataproc.googleapis.com
3gcloud services enable storage-api.googleapis.com
After the command line environment is set up, log in to your GCP account. You can now create a Dataproc cluster. Dataproc supports multiple different GPU types depending on your use case. Generally, T4 s a good option for use with the RAPIDS Accelerator for Spark. We also support MIG on the Ampere architecture GPUs like the A100. Using MIG you can request an A100 and split it up into multiple different compute instances, and it runs like you have multiple separate GPUs.
The example configurations below will allow users to run any of the notebook demos on GCP. Adjust the sizes and number of GPU based on your needs.
The script below will initialize with the following:
GPU Driver and RAPIDS Accelerator for Apache Spark through initialization actions ( note it takes up to 1 week for the latest init script to be merged into the GCP Dataproc public GCS bucket)
To make changes to example configuration, make a copy of
spark-rapids.shand add the RAPIDS Accelerator related parameters according to tuning guide and modify the--initialization-actionsparameter to point to the updated version.Configuration for GPU scheduling and isolation
Local SSDs are recommended for Spark scratch space to improve IO
Component gateway enabled for accessing Web UIs hosted on the cluster
Note
Dataproc 2.1 enables Secure Boot by default, causing issues with cluster creation on all operating systems due to GPU drivers that aren’t properly signed. Proper GPU driver signing isn’t currently supported on all operating systems and will cause cluster creation failures occur on all Dataproc 2.1 clusters that use the RAPIDS Accelerator initialization script.
Add --no-shielded-secure-boot to gcloud cluster creation commands allow the cluster to boot correctly with unsigned GPU drivers.
For more information:
Create a Dataproc Cluster Using T4s#
One 16-core master node and 5 32-core worker nodes
Two NVIDIA T4 for each worker node
1 export REGION=[Your Preferred GCP Region]
2 export GCS_BUCKET=[Your GCS Bucket]
3 export CLUSTER_NAME=[Your Cluster Name]
4 # Number of GPUs to attach to each worker node in the cluster
5 export NUM_GPUS=2
6 # Number of Spark worker nodes in the cluster
7 export NUM_WORKERS=5
8
9gcloud dataproc clusters create $CLUSTER_NAME \
10 --region=$REGION \
11 --image-version=2.1-ubuntu20 \
12 --master-machine-type=n1-standard-16 \
13 --num-workers=$NUM_WORKERS \
14 --worker-accelerator=type=nvidia-tesla-t4,count=$NUM_GPUS \
15 --worker-machine-type=n1-highmem-32 \
16 --num-worker-local-ssds=4 \
17 --initialization-actions=gs://goog-dataproc-initialization-actions-${REGION}/spark-rapids/spark-rapids.sh \
18 --no-shielded-secure-boot \
19 --optional-components=JUPYTER,ZEPPELIN \
20 --metadata=rapids-runtime=SPARK \
21 --bucket=$GCS_BUCKET \
22 --enable-component-gateway \
23 --subnet=default
This takes around 10-15 minutes to complete. You can navigate to the Dataproc clusters tab in the Google Cloud Console to see the progress.
To reduce initialization time to 4-5 minutes, create a custom Dataproc image using this guide.
Build a Custom Dataproc Image to Reduce Cluster Init Time#
Building a custom Dataproc image that already has NVIDIA drivers, the CUDA toolkit, and the RAPIDS Accelerator for Apache Spark preinstalled and preconfigured will reduce cluster initialization time to 3-4 minutes. The custom image can also be used in air gap environments. In this example, we adapt these instructions from GCP to create a RAPIDS Accelerator custom Dataproc image.
Google provides the generate_custom_image.py script that:
Launches a temporary Compute Engine VM instance with the specified Dataproc base image.
Then runs the customization script and/or update configurations.
After the customization script finishes, it shuts down the VM instance and creates a Dataproc custom image from the disk of the VM instance.
The temporary VM is deleted after the custom image is created.
The custom image is saved and can be used to create Dataproc clusters.
The following example clones the Dataproc custom-images repository, downloads the
spark-rapids.sh script locally, and then creates a custom Dataproc image with RAPIDS Accelerator resources using the downloaded scripts. The spark-rapids.sh script is passed as the customization script and installs the RAPIDS Accelerator for Apache Spark, NVIDIA drivers, and other dependencies. Custom image generation may take 20-25 minutes to complete.
1git clone https://github.com/GoogleCloudDataproc/custom-images
2cd custom-images
3wget https://raw.githubusercontent.com/GoogleCloudDataproc/initialization-actions/master/spark-rapids/spark-rapids.sh
4
5export ZONE=[Your Preferred GCP Zone]
6export GCS_BUCKET=[Your GCS Bucket]
7export CUSTOMIZATION_SCRIPT=./spark-rapids.sh
8export IMAGE_NAME=sample-20-ubuntu20-gpu-t4
9export DATAPROC_VERSION=2.1-ubuntu20
10export GPU_NAME=nvidia-tesla-t4
11export GPU_COUNT=1
12
13python generate_custom_image.py \
14 --image-name $IMAGE_NAME \
15 --dataproc-version $DATAPROC_VERSION \
16 --customization-script $CUSTOMIZATION_SCRIPT \
17 --no-smoke-test \
18 --zone $ZONE \
19 --gcs-bucket $GCS_BUCKET \
20 --machine-type n1-standard-4 \
21 --accelerator type=$GPU_NAME,count=$GPU_COUNT \
22 --disk-size 200 \
23 --subnet default
Refer here for details on generate_custom_image.py script configuration and here for dataproc version information.
The custom sample-21-ubuntu20-gpu-t4 image is now ready and can be viewed in the GCP console under Compute Engine > Storage > Images.
Let’s launch a cluster using the sample-21-ubuntu20-gpu-t4 custom image:
1export REGION=[Your Preferred GCP Region]
2export GCS_BUCKET=[Your GCS Bucket]
3export CLUSTER_NAME=[Your Cluster Name]
4export IMAGE_NAME=sample-21-ubuntu20-gpu-t4
5export NUM_GPUS=1
6export NUM_WORKERS=2
7
8gcloud dataproc clusters create $CLUSTER_NAME \
9 --region=$REGION \
10 --image=$IMAGE_NAME \
11 --master-machine-type=n1-standard-4 \
12 --num-workers=$NUM_WORKERS \
13 --worker-accelerator=type=nvidia-tesla-t4,count=$NUM_GPUS \
14 --worker-machine-type=n1-standard-4 \
15 --num-worker-local-ssds=1 \
16 --optional-components=JUPYTER,ZEPPELIN \
17 --metadata=rapids-runtime=SPARK \
18 --bucket=$GCS_BUCKET \
19 --enable-component-gateway \
20 --subnet=default
There are no initialization actions that need to be configured because NVIDIA drivers and RAPIDS Accelerator resources are already installed in the custom image. The new cluster should be up and running within 3-4 minutes!
Create a Dataproc Cluster using MIG with A100s#
One 16-core master node and five 12-core worker nodes
One NVIDIA A100 for each worker node, split into two MIG instances using instance profile 3g.20gb.
1 export REGION=[Your Preferred GCP Region]
2 export ZONE=[Your Preferred GCP Zone]
3 export GCS_BUCKET=[Your GCS Bucket]
4 export CLUSTER_NAME=[Your Cluster Name]
5 # Number of GPUs to attach to each worker node in the cluster
6 export NUM_GPUS=1
7 # Number of Spark worker nodes in the cluster
8 export NUM_WORKERS=4
9
10gcloud dataproc clusters create $CLUSTER_NAME \
11 --region=$REGION \
12 --zone=$ZONE \
13 --image-version=2.1-ubuntu20 \
14 --master-machine-type=n1-standard-16 \
15 --num-workers=$NUM_WORKERS \
16 --worker-accelerator=type=nvidia-tesla-a100,count=$NUM_GPUS \
17 --worker-machine-type=a2-highgpu-1g \
18 --num-worker-local-ssds=4 \
19 --initialization-actions=gs://goog-dataproc-initialization-actions-${REGION}/spark-rapids/spark-rapids.sh \
20 --metadata=startup-script-url=gs://goog-dataproc-initialization-actions-${REGION}/spark-rapids/mig.sh \
21 --optional-components=JUPYTER,ZEPPELIN \
22 --metadata=rapids-runtime=SPARK \
23 --bucket=$GCS_BUCKET \
24 --enable-component-gateway \
25 --subnet=default
To change the MIG instance profile you can specify either the profile id or profile name via the metadata parameter MIG_CGI. Below is an example of using a profile name and a profile id.
--metadata=^:^MIG_CGI='3g.20gb,9'
This may take around 10-15 minutes to complete. You can navigate to the Dataproc clusters tab in the Google Cloud Console to see the progress.
To reduce initialization time to 4-5 minutes, create a custom Dataproc image using this guide.
Cluster Creation Troubleshooting#
If you encounter an error related to GPUs not being available because of your account quotas, go to this page for updating your quotas: Quotas and limits.
If you encounter an error related to GPUs not available in the specific region or zone, you will need to update the REGION or ZONE parameter in the cluster creation command.
Run Python or Scala Spark Notebook on a Dataproc Cluster Accelerated by GPUs#
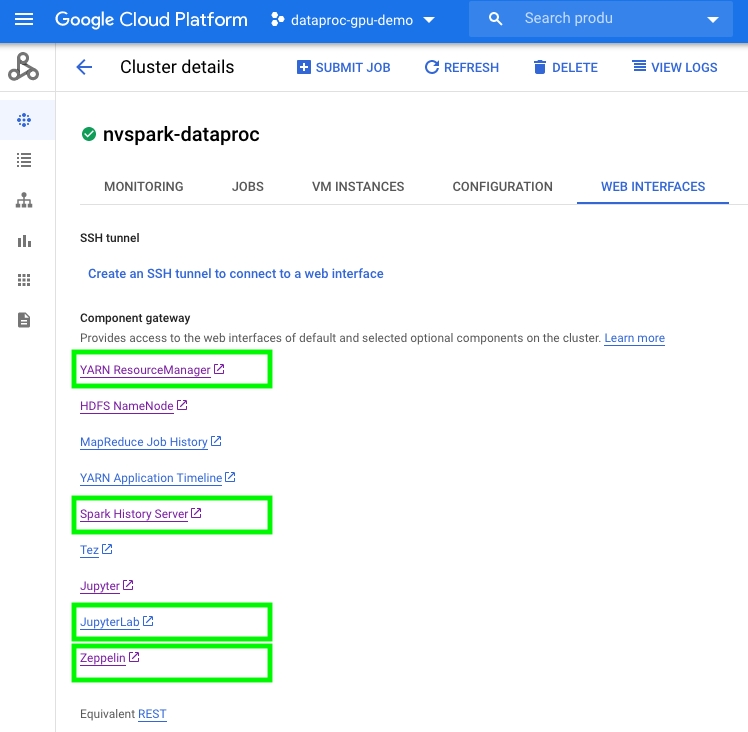
To use notebooks with a Dataproc cluster, click on the cluster name under the Dataproc cluster tab and navigate to the
Web Interfacestab. UnderWeb Interfaces, click on the JupyterLab or Jupyter link.Download the sample
Mortgage ETL on GPU Jupyter Notebookand upload it to Jupyter.
To get example data for the sample notebook, refer to these instructions. Download the desired data, decompress it, and upload the csv files to a GCS bucket.
The sample notebook will transcode the CSV files into Parquet files before running an ETL query that prepares the dataset for training. The ETL query splits the data, saving 20% of the data in a separate GCS location training for evaluation. Using the default notebook configuration the first stage should take ~110 seconds (1/3 of CPU execution time with same config) and the second stage takes ~170 seconds (1/7 of CPU execution time with same config). The notebook depends on the RAPIDS Accelerator for Apache Spark, which is pre-downloaded and pre-configured by the GCP Dataproc RAPIDS Accelerator init script.
Once the data is prepared, we use the Mortgage XGBoost4j Scala Notebook in Dataproc’s Jupyter notebook to execute the training job on GPUs. Scala based XGBoost examples use DMLC XGBoost. For a PySpark based XGBoost example, refer to RAPIDS Accelerator-examples that makes sure the required libraries are installed.
The training time should be around 680 seconds (1/7 of CPU execution time with same config). This is shown under cell:
1// Start training
2println("\n------ Training ------")
3val (xgbClassificationModel, _) = benchmark("train") {
4xgbClassifier.fit(trainSet)
5}
Submit Spark jobs to a Dataproc Cluster Accelerated by GPUs#
Similar to spark-submit for on-prem clusters, Dataproc supports submitting Spark applications to Dataproc clusters. The previous mortgage examples are also available as a Spark application.
Follow these instructions to Build the xgboost-example jars. Upload the sample_xgboost_apps-${VERSION}-SNAPSHOT-jar-with-dependencies.jar to a GCS bucket by dragging and dropping the jar file from your local machine into the GCS web console or by running:
gsutil cp aggregator/target/sample_xgboost_apps-${VERSION}-SNAPSHOT-jar-with-dependencies.jar gs://${GCS_BUCKET}/scala/
Submit the Spark XGBoost application to dataproc using the following command:
1export REGION=[Your Preferred GCP Region]
2export GCS_BUCKET=[Your GCS Bucket]
3export CLUSTER_NAME=[Your Cluster Name]
4export VERSION=[Your jar version]
5export SPARK_NUM_EXECUTORS=20
6export SPARK_EXECUTOR_MEMORY=20G
7export SPARK_EXECUTOR_MEMORYOVERHEAD=16G
8export SPARK_NUM_CORES_PER_EXECUTOR=7
9export DATA_PATH=gs://${GCS_BUCKET}/mortgage_full
10
11gcloud dataproc jobs submit spark \
12 --cluster=$CLUSTER_NAME \
13 --region=$REGION \
14 --class=com.nvidia.spark.examples.mortgage.Main \
15 --jars=gs://${GCS_BUCKET}/scala/sample_xgboost_apps-${VERSION}-SNAPSHOT-jar-with-dependencies.jar \
16 --properties=spark.executor.cores=${SPARK_NUM_CORES_PER_EXECUTOR},spark.task.cpus=${SPARK_NUM_CORES_PER_EXECUTOR},spark.executor.memory=${SPARK_EXECUTOR_MEMORY},spark.executor.memoryOverhead=${SPARK_EXECUTOR_MEMORYOVERHEAD},spark.executor.resource.gpu.amount=1,spark.task.resource.gpu.amount=1,spark.rapids.sql.batchSizeBytes=512M,spark.rapids.sql.reader.batchSizeBytes=768M,spark.rapids.sql.variableFloatAgg.enabled=true,spark.rapids.memory.gpu.pooling.enabled=false,spark.dynamicAllocation.enabled=false \
17 -- \
18 -dataPath=train::${DATA_PATH}/train \
19 -dataPath=trans::${DATA_PATH}/eval \
20 -format=parquet \
21 -numWorkers=${SPARK_NUM_EXECUTORS} \
22 -treeMethod=gpu_hist \
23 -numRound=100 \
24 -maxDepth=8
Diagnosing a GPU Cluster#
The diagnostic tool can be run to check a GPU cluster with RAPIDS Accelerator for Apache Spark is healthy and ready for Spark jobs, such as checking the version of installed NVIDIA driver, cuda-toolkit, RAPIDS Accelerator and running Spark test jobs etc. This tool also can be used by the front line support team for basic diagnostic and troubleshooting before escalating to NVIDIA RAPIDS Accelerator for Apache Spark engineering team.
Usage: spark_rapids_user_tools dataproc diagnostic --cluster <cluster-name>
Help (to see all options available): spark_rapids_user_tools dataproc diagnostic -- --help
Example output:
1*** Running diagnostic function "nv_driver" ***
2Warning: Permanently added 'compute.9009746126288801979' (ECDSA) to the list of known hosts.
3Fri Oct 14 05:17:55 2022
4+---------------------------------------------------------------------------------------+
5| NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 |
6|-----------------------------------------+----------------------+----------------------+
7| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
8| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
9| | | MIG M. |
10|=========================================+======================+======================|
11| 0 NVIDIA L4 On | 00000000:00:03.0 Off | 0 |
12| N/A 37C P8 11W / 72W | 4MiB / 23034MiB | 0% Default |
13| | | N/A |
14+-----------------------------------------+----------------------+----------------------+
15
16+---------------------------------------------------------------------------------------+
17| Processes: |
18| GPU GI CI PID Type Process name GPU Memory |
19| ID ID Usage |
20|=======================================================================================|
21| No running processes found |
22+---------------------------------------------------------------------------------------+
23GCC version: gcc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
24Connection to 34.68.242.247 closed.
25*** Check "nv_driver": PASS ***
26*** Running diagnostic function "nv_driver" ***
27Warning: Permanently added 'compute.6788823627063447738' (ECDSA) to the list of known hosts.
28Fri Oct 14 05:18:02 2022
29+---------------------------------------------------------------------------------------+
30| NVIDIA-SMI 535.104.05 Driver Version: 535.104.05 CUDA Version: 12.2 |
31|-----------------------------------------+----------------------+----------------------+
32| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
33| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
34| | | MIG M. |
35|=========================================+======================+======================|
36| 0 NVIDIA L4 On | 00000000:00:03.0 Off | 0 |
37| N/A 37C P8 11W / 72W | 4MiB / 23034MiB | 0% Default |
38| | | N/A |
39+-----------------------------------------+----------------------+----------------------+
40
41+---------------------------------------------------------------------------------------+
42| Processes: |
43| GPU GI CI PID Type Process name GPU Memory |
44| ID ID Usage |
45|=======================================================================================|
46| No running processes found |
47+---------------------------------------------------------------------------------------+
48GCC version: gcc (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0
49Connection to 34.123.223.104 closed.
50*** Check "nv_driver": PASS ***
51*** Running diagnostic function "cuda_version" ***
52Connection to 34.68.242.247 closed.
53found cuda major version: 11
54*** Check "cuda_version": PASS ***
55*** Running diagnostic function "cuda_version" ***
56Connection to 34.123.223.104 closed.
57found cuda major version: 11
58*** Check "cuda_version": PASS ***
59...
60********************************************************************************
61Overall check result: PASS
Please note that the diagnostic tool supports the following:
Dataproc 2.0 with image of Debian 10 (Rocky8 support is coming soon)
GPU clusters that must have 1 worker node at least. Single node cluster (1 master, 0 workers) isn’t supported
Bootstrap GPU Cluster with Optimized Settings#
The bootstrap tool will apply optimized settings for the RAPIDS Accelerator on Apache Spark on a GPU cluster for Dataproc. The tool will fetch the characteristics of the cluster – including number of workers, worker cores, worker memory, and GPU accelerator type and count. It will use the cluster properties to then determine the optimal settings for running GPU-accelerated Spark applications.
Usage: spark_rapids_user_tools dataproc bootstrap --cluster <cluster-name>
Help (to see all options available): spark_rapids_user_tools dataproc bootstrap -- --help
Example output:
1##### BEGIN : RAPIDS bootstrap settings for gpu-cluster
2spark.executor.cores=16
3spark.executor.memory=32768m
4spark.executor.memoryOverhead=7372m
5spark.rapids.sql.concurrentGpuTasks=2
6spark.rapids.memory.pinnedPool.size=4096m
7spark.sql.files.maxPartitionBytes=512m
8spark.task.resource.gpu.amount=0.0625
9##### END : RAPIDS bootstrap settings for gpu-cluster
A detailed description for bootstrap settings with usage information is available in the RAPIDS Accelerator for Apache Spark Configuration and Spark Configuration page.
Qualify CPU Workloads for GPU Acceleration#
The qualification tool is launched on a Dataproc cluster that has applications that have already run. The tool will output the applications recommended for acceleration along with estimated speed-up and cost saving metrics. Additionally, it will provide information on how to launch a GPU-accelerated cluster to take advantage of the speed-up and cost savings.
Usage: spark_rapids_user_tools dataproc qualification --cluster <cluster-name>
Help (to see all options available): spark_rapids_user_tools dataproc qualification --help
Example output:
1+----+------------+--------------------------------+----------------------+-----------------+-----------------+---------------+-----------------+
2| | App Name | App ID | Recommendation | Estimated GPU | Estimated GPU | App | Estimated GPU |
3| | | | | Speedup | Duration(s) | Duration(s) | Savings(%) |
4|----+------------+--------------------------------+----------------------+-----------------+-----------------+---------------+-----------------|
5| 0 | query24 | application_1664888311321_0011 | Strongly Recommended | 3.49 | 257.18 | 897.68 | 59.70 |
6| 1 | query78 | application_1664888311321_0009 | Strongly Recommended | 3.35 | 113.89 | 382.35 | 58.10 |
7| 2 | query23 | application_1664888311321_0010 | Strongly Recommended | 3.08 | 325.77 | 1004.28 | 54.37 |
8| 3 | query64 | application_1664888311321_0008 | Strongly Recommended | 2.91 | 150.81 | 440.30 | 51.82 |
9| 4 | query50 | application_1664888311321_0003 | Recommended | 2.47 | 101.54 | 250.95 | 43.08 |
10| 5 | query16 | application_1664888311321_0005 | Recommended | 2.36 | 106.33 | 251.95 | 40.63 |
11| 6 | query38 | application_1664888311321_0004 | Recommended | 2.29 | 67.37 | 154.33 | 38.59 |
12| 7 | query87 | application_1664888311321_0006 | Recommended | 2.25 | 75.67 | 170.69 | 37.64 |
13| 8 | query51 | application_1664888311321_0002 | Recommended | 1.53 | 53.94 | 82.63 | 8.18 |
14+----+------------+--------------------------------+----------------------+-----------------+-----------------+---------------+-----------------+
To launch a GPU-accelerated cluster with RAPIDS Accelerator for Apache Spark, add the following to your cluster creation script:
1 --initialization-actions=gs://goog-dataproc-initialization-actions-${REGION}/spark-rapids/spark-rapids.sh \
2 --worker-accelerator type=nvidia-tesla-t4,count=2 \
3 --metadata gpu-driver-provider="NVIDIA" \
4 --metadata rapids-runtime=SPARK \
5 --cuda-version=11.5
Please refer Qualification Tool guide for running qualification tool on more environment.
Tune Applications on GPU Cluster#
Once Spark applications have been run on the GPU cluster, the profiling tool can be run to analyze the event logs of the applications to determine if more optimal settings should be configured. The tool will output a per-application set of config settings to be adjusted for enhanced performance.
Usage: spark_rapids_user_tools dataproc profiling --cluster <cluster-name>
Help (to see all options available): spark_rapids_user_tools dataproc profiling -- --help
Example output:
1+--------------------------------+--------------------------------------------------+--------------------------------------------------------------------------------------------------+
2| App ID | Recommendations | Comments |
3+================================+==================================================+==================================================================================================+
4| application_1664894105643_0011 | --conf spark.executor.cores=16 | - 'spark.task.resource.gpu.amount' wasn't set. |
5| | --conf spark.executor.memory=32768m | - 'spark.rapids.sql.concurrentGpuTasks' wasn't set. |
6| | --conf spark.executor.memoryOverhead=7372m | - 'spark.rapids.memory.pinnedPool.size' wasn't set. |
7| | --conf spark.rapids.memory.pinnedPool.size=4096m | - 'spark.executor.memoryOverhead' wasn't set. |
8| | --conf spark.rapids.sql.concurrentGpuTasks=2 | - 'spark.sql.files.maxPartitionBytes' wasn't set. |
9| | --conf spark.sql.files.maxPartitionBytes=1571m | - 'spark.sql.shuffle.partitions' wasn't set. |
10| | --conf spark.sql.shuffle.partitions=200 | |
11| | --conf spark.task.resource.gpu.amount=0.0625 | |
12+--------------------------------+--------------------------------------------------+--------------------------------------------------------------------------------------------------+
13| application_1664894105643_0002 | --conf spark.executor.cores=16 | - 'spark.task.resource.gpu.amount' wasn't set. |
14| | --conf spark.executor.memory=32768m | - 'spark.rapids.sql.concurrentGpuTasks' wasn't set. |
15| | --conf spark.executor.memoryOverhead=7372m | - 'spark.rapids.memory.pinnedPool.size' wasn't set. |
16| | --conf spark.rapids.memory.pinnedPool.size=4096m | - 'spark.executor.memoryOverhead' wasn't set. |
17| | --conf spark.rapids.sql.concurrentGpuTasks=2 | - 'spark.sql.files.maxPartitionBytes' wasn't set. |
18| | --conf spark.sql.files.maxPartitionBytes=3844m | - 'spark.sql.shuffle.partitions' wasn't set. |
19| | --conf spark.sql.shuffle.partitions=200 | |
20| | --conf spark.task.resource.gpu.amount=0.0625 | |
21+--------------------------------+--------------------------------------------------+--------------------------------------------------------------------------------------------------+