Overview#
The cuDF for Apache Spark leverages GPUs to accelerate processing via the RAPIDS libraries.
As data workloads continued to grow to support traditional analytics as well as large-scale ML pipelines, traditional CPU-based processing can no longer keep up without compromising either speed or cost. The growing adoption of AI in analytics has created the need for a new framework to process data quickly and cost-efficiently with GPUs.
The cuDF for Apache Spark combines the power of the RAPIDS cuDF library and the scale of the Spark distributed computing framework. The cuDF for Apache Spark library also has a built-in accelerated shuffle based on UCX that can be configured to leverage GPU-to-GPU communication and RDMA capabilities.
Performance & Cost Benefits#
cuDF for Apache Spark reaps the benefit of GPU performance while saving infrastructure costs. Perf-cost ETL for FannieMae Mortgage Dataset (~200GB) as shown in our demo. Costs based on Cloud T4 GPU instance market price.
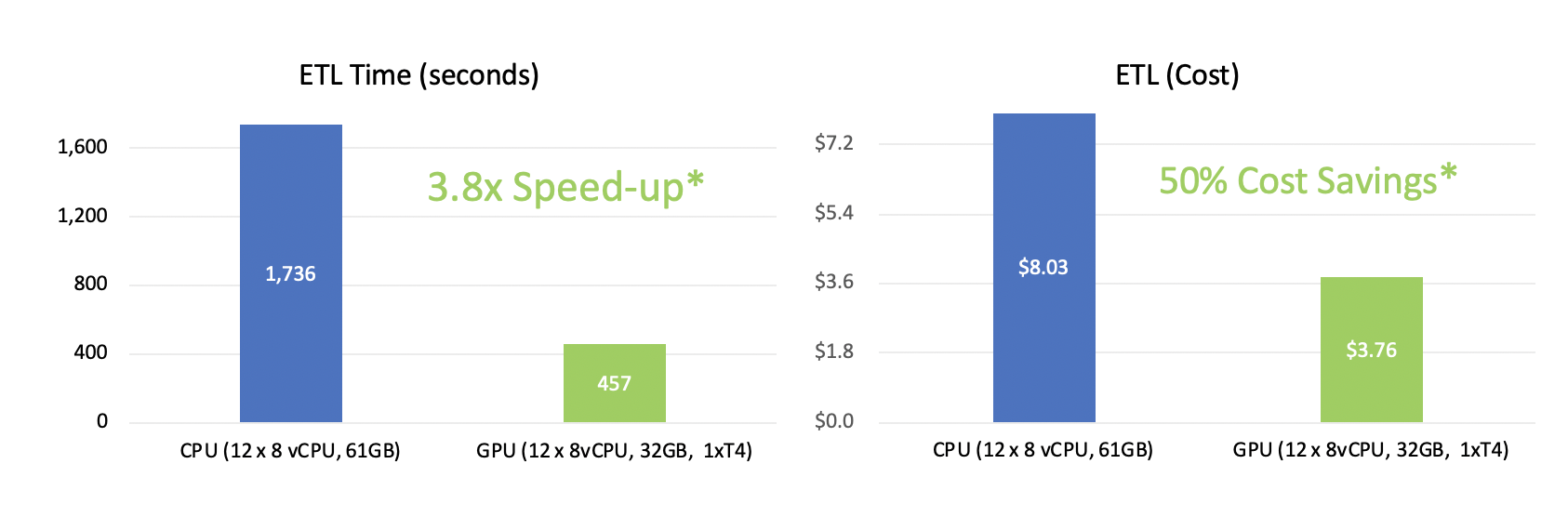
Please refer to cudf-spark-examples repo for details of this example job.
TPC-DS is a decision support benchmark often used to evaluate performance of OLAP Databases and Big Data systems. This is a benchmark result of a user-specified subset of the TPC-DS queries on a relatively smaller scale (10 GB) but you can start directly from a browser in colab.
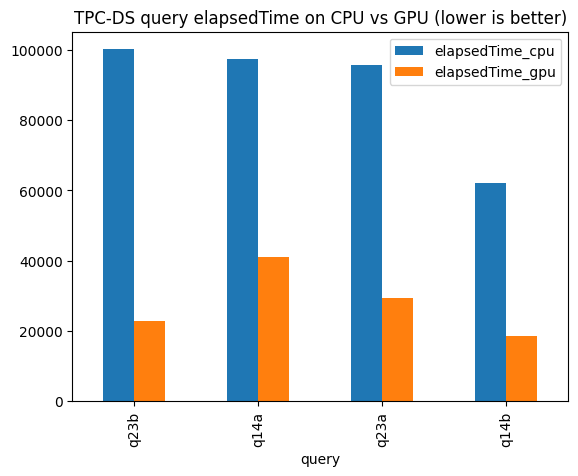
Please refer to cudf-spark-examples repo for details of this example job.
Ease of Use#
Run your existing Apache Spark applications with no code change. Launch Spark with the cuDF for Apache Spark plugin jar and enable a configuration setting:
spark.conf.set('spark.rapids.sql.enabled','true')
The following is an example of a physical plan with operators running on the GPU:
1== Physical Plan ==
2GpuColumnarToRow false
3+- GpuProject [cast(c_customer_sk#0 as string) AS c_customer_sk#40]
4 +- GpuFileGpuScan parquet [c_customer_sk#0] Batched: true, DataFilters: [], Format: Parquet, Location: InMemoryFileIndex[file:/tmp/customer], PartitionFilters: [], PushedFilters: [], ReadSchema: struct<c_customer_sk:int>
Learn more on how to get started.
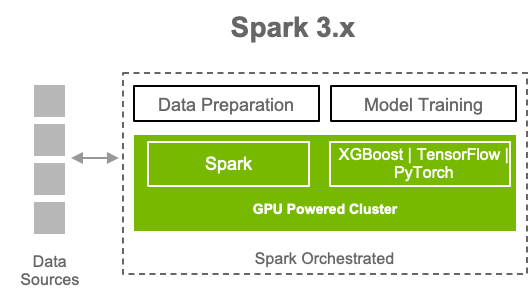
A Unified AI framework for ETL + ML/DL#
A single pipeline, from ingest to data preparation to model training spark3cluster