Optimizing the Training Pipeline
All Deep Neural Network tasks supported by TAO Toolkit provide a train command
to enable the users to train models. Training can be done on one or more GPUs. The
NVIDIA TAO Toolkit provides a simple command line interface to train a
deep-learning model for classification, object detection, and instance segmentation. To speed
up the training process, the train command supports multi-GPU training. You can
invoke a multi-GPU training session using the --gpus N option, where N
is the number of GPUs you want to use. N must be less than the number of GPUs
available in the given node for training.
Currently, only single-node multi-GPU training is supported.
The following optimizations are also included with the train command:
Quantization Aware Training (QAT)
Automatic Mixed Precision (AMP)
TAO Toolkit supports Quantization-Aware-Training (QAT) for its object detection networks namely, DetectNet_v2, SSD, DSSD, YOLOv3, YOLOv4, YOLOv4-tiny, RetinaNet and FasterRCNN. Quantization Aware Training emulates the inference time quantization when training a model that may then be used by downstream inference platforms to generate actual quantized models. The error from quantizating weights and tensors to INT8 is modeled during training, allowing the model to adapt and mitigate the error. During QAT, the model constructed in the training graph is modified to:
Replace existing nodes with nodes that support fake quantization of its weights.
Convert existing activations to ReLU-6 (except the output nodes).
Add Quantize and De-Quantize(QDQ) nodes to compute the dynamic ranges of the intermediate tensors.
The dynamic ranges computed during training are serialized to a cache file at
export, which may then be parsed by TensorRT to create an optimized inference engine.
To enable QAT during training, simply set the enable_qat parameter to be true in the
training_config field of the corresponding spec file of each of the supported networks.
The benefit of QAT training is usually a better accuracy when doing INT8 inference with TensorRT
compared with traditional calibration based INT8 TensorRT inference.
The number of scales present in the cache file is less than that generated by the Post Training Quantization technique using TensorRT. This is because the QDQ nodes are added only after operations that are fused by TensorRT (in GPU) eg: operation sequences such as Conv2d -> Bias -> Relu or Conv2d -> Bias -> BatchNormalization -> Activation, whereas during PTQ, the scales are applied to all the intermediate tensors in the model. Also, the final output regression nodes are not quantized in the current training graphs. So these layers currently run in fp32.
When deploying a model with platforms that have DLA, please note that currently using
Quantization cache files generated by peeling the scales from the model is not
supported, since DLA requires a scale factor for all layers. Inorder to use a QAT
trained model with DLA, we recommend using the post training quantization at export.
The Post Training Quantization method takes the current QAT trained model and generates
scale factors for all intermediate tensors in the model since the DLA doesn’t fuse
operations as done by the GPU. More information about this can be found in the
Exporting the Model sections of each app.
The recommended workflow for training a Quantization Aware model is depicted in the diagram below.
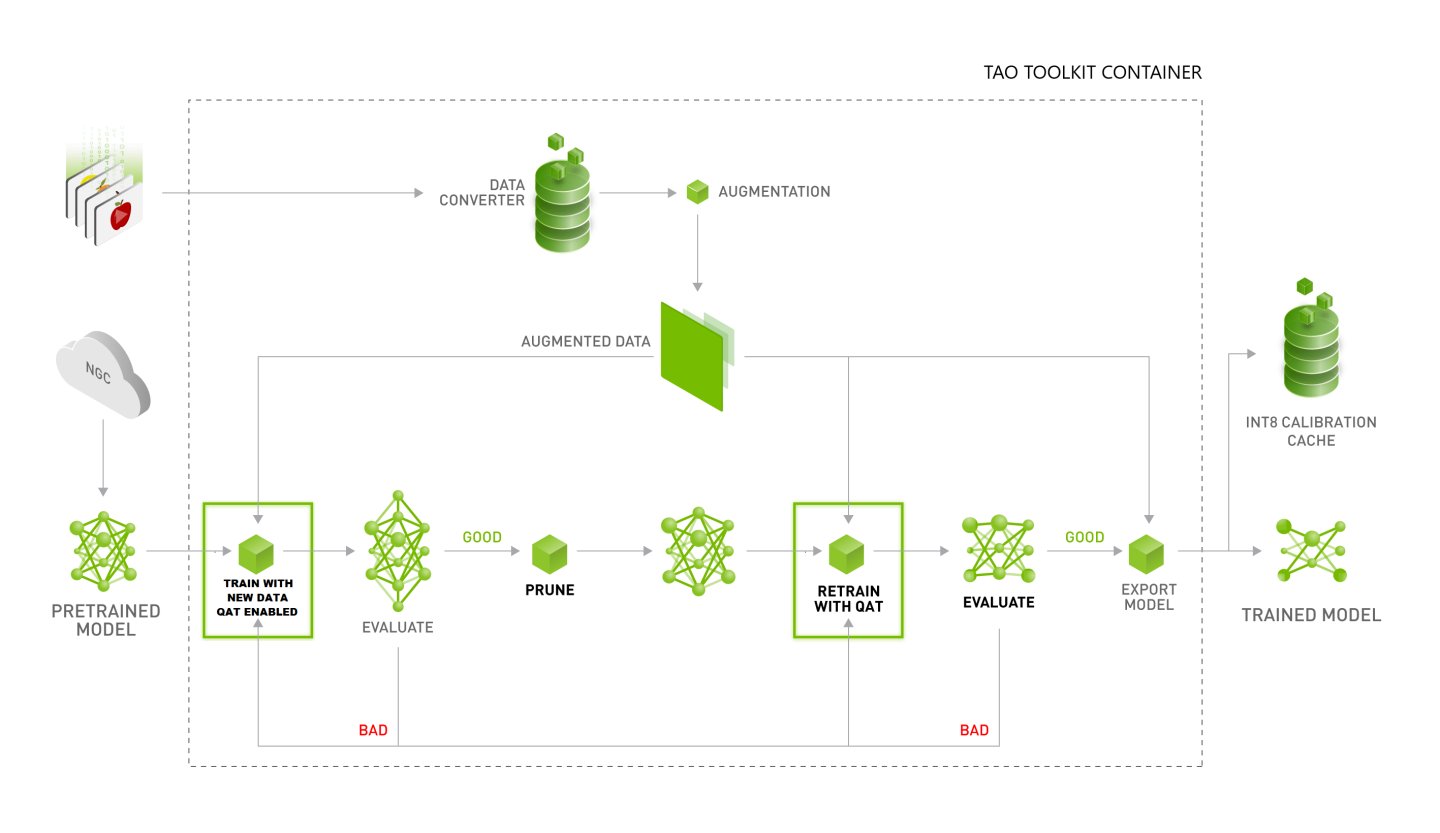
TAO Toolkit now supports Automatic-Mixed-Precision(AMP) training. DNN training has traditionally relied on training using the IEEE-single precision format for its tensors. With mixed precision training however, one may use a mixture for FP16 and FP32 operations in the training graph to help speed up training while not compromising accuracy. There are several benefits to using AMP:
Speed up math-intensive operations, such as linear and convolution layers.
Speed up memory-limited operations by accessing half the bytes compared to single-precision
Reduce memory requirements for training models, enabling larger models or larger minibatches.
In TAO Toolkit, enabling AMP is as simple as setting the --use_amp flag at the command line
when running the train command. This will help speed up the training by using FP16 tensor
cores. Note that AMP is only supported on GPUs with Volta or above architecture.