ActionRecognitionNet
ActionRecognitionNet takes a sequence of images as network input and predicts the people’s action in those images. TAO Toolkit provides the network backbones in 2D/3D with the following input options: RGB-only input, optical flow (OF) only input, and two-stream joint input (RGB+OF).
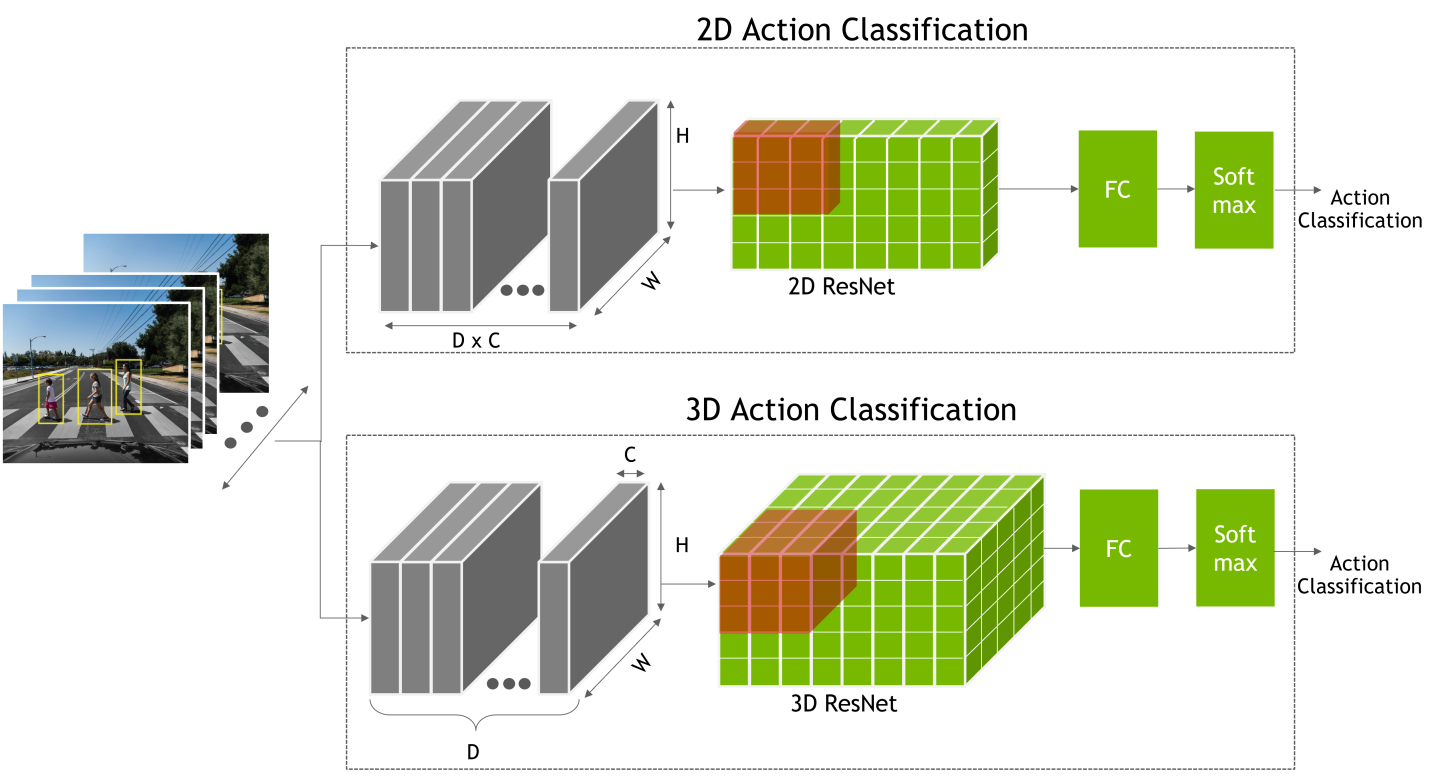
Action Recognition Net Architecture
ActionRecognitionNet requires RGB video frames for the RGB input stream and optical flow vectors for the OF input stream. The x-axis and y-axis of the raw optical flow vectors should be mapped to grayscale images for training. We provide a simple tool to preprocess sample. This tool will convert the video to frames and generate optical flow images based on the NVIDIA Optical Flow (NVOF) SDK.
The data should be organized in the following structure:
/Dataset
/class_a
/video_1
/rgb
000000.png
000001.png
...
N.png
/u
000000.jpg
000001.jpg
...
N-1.jpg
/v
000000.jpg
000001.jpg
...
N-1.jpg
The root directory of dataset contains multiple sub-directories for different classes. Each class directory has sub-folders for different videos, and each of these subfolders contain rgb, u and v folders that respectively hold RGB frames, optical flow x-axis grayscale images, and optical flow y-axis grayscale images. The u and v folders can be empty if you want to train an RGB-only model. A simple script is provided to generate RGB frames only.
The spec file for ActionRecognitionNet includes model_config,
train_config, and dataset_config parameters. Here is an example spec for
training a 3D RGB-only model with a resnet18 backbone on a dataset that contains 5 classes:
“walk”, “sits”, “squat”, “fall”, “bend”:
model_config:
model_type: rgb
backbone: resnet18
rgb_seq_length: 3
input_type: 3d
sample_rate: 1
dropout_ratio: 0.0
train_config:
optim:
lr: 0.01
momentum: 0.9
weight_decay: 0.0001
lr_scheduler: MultiStep
lr_steps: [5, 15, 25]
lr_decay: 0.1
epochs: 30
checkpoint_interval: 1
dataset_config:
train_dataset_dir: /data/train
val_dataset_dir: /data/test
label_map:
walk: 0
sits: 1
squat: 2
fall: 3
bend: 4
output_shape:
- 224
- 224
batch_size: 32
workers: 8
clips_per_video: 15
augmentation_config:
train_crop_type: no_crop
horizontal_flip_prob: 0.5
rgb_input_mean: [0.5]
rgb_input_std: [0.5]
val_center_crop: False
Parameter |
Data Type |
Default |
Description |
|
dict config |
– |
The configuration of the model architecture |
|
dict config |
– |
The configuration of the training process |
|
dict config |
– |
The configuration for the dataset |
model_config
The model_config parameter provides options to change the ActionRecognitionNet architecture.
model_config:
model_type: rgb
backbone: resnet18
rgb_seq_length: 3
input_type: 3d
sample_rate: 1
dropout_ratio: 0.0
Parameter |
Datatype |
Default |
Description |
Supported Values |
|
string |
joint |
The type of model, which can be rgb for the RGB-only model, of for the OF-only model, or joint for the RGB+OF model |
rgb/of/joint |
|
string |
resnet18 |
The backbone of the model. Currently supported backbones are ResNet18/34/50/101 |
resnet18/34/50/101 |
|
string |
2d |
The type of input for the model. It can be 2d or 3d. |
2d/3d |
|
unsigned int |
3 |
The number of RGB frames for single inference |
>0 |
|
string |
None |
The absolute path to pretrained weights for the RGB model |
|
|
unsigned int |
0 |
The number of classes for the pretrained RGB model. Use 0 to specify the same number of classes as the current training. |
>=0 |
|
unsigned int |
10 |
The number of optical flow frames for single inference |
>0 |
|
string |
None |
The absolute path to pretrained weights for the OF model |
|
|
unsigned int |
0 |
The number of classes for the pretrained RGB model. Use 0 to specify the same number of classes as the current training. |
>=0 |
|
string |
None |
The absolute path to pretrained weights for the joint model |
|
|
unsigned int |
64 |
The number of hidden units for the joint model |
>0 |
|
unsigned int |
1 |
The sample rate to pick consecutive frames. For example, if the sample_rate is 2, the frame will be picked every 2 frames. |
>0 |
|
float |
0.5 |
The probability to drop out hidden units | 0.0 ~ 1.0 |
train_config
The train_config parameter defines the hyperparameters of the training process.
train_config:
optim:
lr: 0.01
momentum: 0.9
weight_decay: 0.0001
lr_scheduler: MultiStep
lr_steps: [5, 15, 25]
lr_decay: 0.1
epochs: 30
checkpoint_interval: 1
Parameter |
Datatype |
Default |
Description |
Supported Values |
|
dict config |
The config for SGD optimizer, including the learning rate, learning scheduler, and weight decay |
>0 |
|
|
unsigned int |
10 |
The total number of epochs to run the experiment |
>0 |
|
unsigned int |
5 |
The interval at which the checkpoints are saved |
>0 |
|
float |
0.0 |
The amount to clip the gradient by the L2 norm. 0.0 means don’t clip |
>=0 |
optim
The optim parameter defines the config for the SGD optimizer in training, including the
learning rate, learning scheduler, and weight decay.
optim:
lr: 0.01
momentum: 0.9
weight_decay: 0.0001
lr_scheduler: MultiStep
lr_steps: [5, 15, 25]
lr_decay: 0.1
Parameter |
Datatype |
Default |
Description |
Supported Values |
|---|---|---|---|---|
|
float |
5e-4 |
The initial learning rate for the training |
>0.0 |
|
float |
0.9 |
The momentum for the SGD optimizer |
>0.0 |
|
float |
5e-4 |
The weight decay coefficeint |
>0.0 |
|
|
string |
MultiStep |
The learning scheduler. Two schedulers are provided: |
MultiStep/AutoReduce |
|
float |
0.1 |
The decreasing factor for learning rate scheduler |
>0.0 |
|
int list |
[15, 25] |
The steps to decrease the learning rate for the |
int list |
|
string |
val_loss |
The monitor value for the |
val_loss/train_loss |
|
unsigned int |
1 |
The number of epochs with no improvement, after which learning rate will be reduced |
>0 |
|
float |
1e-4 |
The minimum learning rate in the training |
>0.0 |
dataset_config
The dataset_config parameter defines the dataset source, training batch size, and
augmentation.
dataset_config:
train_dataset_dir: /data/train
val_dataset_dir: /data/test
label_map:
walk: 0
sits: 1
squa: 2
fall: 3
bend: 4
output_shape:
- 224
- 224
batch_size: 32
workers: 8
clips_per_video: 15
augmentation_config:
train_crop_type: no_crop
horizontal_flip_prob: 0.5
rgb_input_mean: [0.5]
rgb_input_std: [0.5]
val_center_crop: False
Parameter |
Datatype |
Default |
Description |
Supported Values |
|
string |
The path to the train dataset |
||
|
string |
The path to the validation dataset |
||
|
dict |
A dict that maps the class names to indices |
||
|
list |
[224, 224] |
The output shape after augmentation |
unsigned int list with size=2 |
|
unsigned int |
32 |
The batch size for training and validation |
>0 |
|
unsigned int |
8 |
The number of parallel workers processing data |
>0 |
|
unsigned int |
1 |
The number of clips sampled from a video in an epoch |
>0 |
|
dict config |
The parameters to define the augmentation method |
For a 3D model, the input layout is NCDHW, where N is the batch size, C
is the input channel, D is the depth or sequence length, H is the image height,
and W is the image width.
For a 2D model, the input layout is N[CxD]HW.
augmentation_config
The augmentation_config parameter contains hyperparameters for augmentation.
augmentation_config:
train_crop_type: no_crop
horizontal_flip_prob: 0.5
rgb_input_mean: [0.5]
rgb_input_std: [0.5]
val_center_crop: False
Parameter |
Datatype |
Default |
Description |
Supported Values |
|
|
string |
random_crop |
The crop type when training: |
random_crop |
|
float list |
[1.0] |
The scales to generate the crop pattern in |
float list / >0.0 |
|
float list |
[0.485, 0.456, 0.406] |
The input mean for RGB frames: (input - mean) / std |
float list / size=1 or 3 |
|
float list |
[0.229, 0.224, 0.225] |
The input std for RGB frames: (input - mean) / std |
float list / size=1 or 3 |
|
float list |
[0.5] |
The input mean for OF frames: (input - mean) / std |
float list / size=1 or 3 |
|
float list |
[0.5] |
The input std for OF frames: (input - mean) / std |
float list / size=1 or 3 |
|
bool |
False |
Specifies whether to center crop the images in validation. |
|
|
|
unsigned int |
256 |
Specifies whether to resize the images, with |
>0 |
Use the following command to run ActionRecognitionNet training:
tao action_recognition train -e <experiment_spec_file>
-r <results_dir>
-k <key>
[gpu_ids=<gpu id list>]
[resume_training_checkpoint_path=<absolute path to \*.tlt checkpoint>]
Required Arguments
-e, --experiment_spec_file: The path to the experiment spec file-r, --results_dir: The path to a folder where the experiment outputs should be written-k, --key: The user-specific encoding key to save or load a.tltmodel.
Optional Arguments
gpu_ids: The GPU indices list for training. If you set more than one GPU ID in it, multi-GPU training will be triggered automatically.resume_training_checkpoint_path: The path to a checkpoint to continue training
Here’s an example of using the ActionRecognitionNet training command:
tao action_recognition train -e $DEFAULT_SPEC -r $RESULTS_DIR -k $YOUR_KEY
The evaluation metric of ActionRecognitionNet is recognition accuracy. Two modes of video sampling
strategies are provided for evaluation on a video: center and conv.
The center evaluation inference is performed on the middle part of frames in a video clip.
For example, if the model requires 32 frames as input and a video clip has 128 frames, then
the frames from index 48 to index 79 will be used to perform inference.
The conv evaluation inference is performed on a number of segments out of a video clip. For
example, a video clip is divided uniformly into 10 parts; the center of each segments is treated as
a starting point from which 32 consecutive frames are chosen to form an inference segment. In this
manner, an inference segment is generated for every part the video was divided into. And the final
label of the video is determined by the average score of those 10 segments.
Use the following command to run ActionRecognitionNet evaluation:
tao action_recognition evaluate -e <experiment_spec_file>
-k <key>
model=<model to be evaluated>
[gpu_id=<gpu index>]
[batch_size=<batch size>]
[test_dataset_dir=<path to test dataset>]
[video_eval_mode=<evaluation mode for the video>]
[video_num_segments=<number of segments for :code:`conv` mode>]
Required Arguments
-e, --experiment_spec_file: THe xperiment spec file to set up the evaluation experiment. This should be the same as a training spec file.-k, --key:The encoding key for the.tltmodel.model: The.tltmodel.
Optional Arguments
gpu_id: The GPU index used to run the evaluation. You can specify the GPU index used to run evaluation when the machine has multiple GPUs installed. Note that evaluation can only run on a single GPU.batch_size: The batch size to perform inference in evaluation. The default value is 1.test_dataset_dir: The path to the test dataset. If not set, the validation dateset in theexperiment_specwill be used.video_eval_mode: The evaluation mode for the video:center: Evaluation inference is performed on the middle part of frames in the video clip. This is the default mode.conv: Evaluation inference is performed on a number of segments out of a video clip. The final prediction is averaged among all the segments.
video_num_segments: The number of segments sampled in a video clip forconvevaluation mode. The default value is 10.
Here’s an example of using the ActionRecognitionNet evaluation command:
tao action_recognition evaluate -e $DEFAULT_SPEC -k $YOUR_KEY model=$TRAINED_TLT_MODEL
Use the following command to run inference on ActionRecognitionNet with the .tlt model.
tao action_recognition inference -e <experiment_spec>
-k <key>
model=<inference model>
inference_dataset_dir=<path to dataset to be inferenced>
[gpu_id=<gpu index>]
[batch_size=<batch size>]
[video_inf_mode=<inference >]
[video_num_segments]
The output will be formatted as [video_sample_path] [labels list of inference segments in this video].
Required Arguments
-e, --experiment_spec: The experiment spec file to set up inference. This can be the same as the training spec.-k, --key:The encoding key for the.tltmodel.model: The.tltmodel to perform inference with.inference_dataset_dir: The path to the dataset to perform inference with. It should be a class-level directory, as described in the Preparing the Dataset section.
Optional Arguments
gpu_id: The GPU index used to run the inference. You can specify the GPU index used to run inference when the machine has multiple GPUs installed. Note that inference can only run on a single GPU.batch_size: The batch size to perform inference in evaluation. The default value is 1.video_inf_mode: The inference mode for the video:center: Inference is performed on the middle part of frames in the video clip. This is the default mode.conv: Inference is performed on a number of segments in a video clip. All the segment preidctions will be kept in a label list.
video_num_segments: The number of segments sampled in a video clip for theconvinference mode.
Here’s an example ActionRecognitionNet inference command:
tao action_recognition inference -e $DEFAULT_SPEC -k $KEY
model=$SAVED_TRT_ENGINE
inference_dataset_dir=$PATH_TO_INF_DATASET
The expected output for the fall class would be as follows:
/path/to/fall/video_1 [fall]
/path/to/fall/video_2 [fall]
...
Use the following command to export ActionRecognitionNet to .etlt format for deployment:
tao action_recognition export -k <key>
-e <experiment_spec>
model=<tlt checkpoint to be exported>
[gpu_id=<gpu index>]
[output_file=<path to exported file>]
Required Arguments
-e, --experiment_spec: The experiment spec file to set up export. This can be the same as the training spec.-k, --key:The encoding key for the.tltmodel.model: The.tltmodel to be exported.
Optional Arguments
gpu_id: The GPU index used to run the export. We can specify the GPU index used to run export when the machine has multiple GPUs installed. Note that export can only run on a single GPUoutput_file: The path to save the exported model to. The default path is in the same directory of\*.tltmodel.
Here’s an example of using the ActionRecognitionNet export command:
tao action_recognition export -e $DEFAULT_SPEC -k $YOUR_KEY model=$TLT_TRAINED_MODEL
The deep learning and computer vision models that you trained can be deployed on edge devices,
such as a Jetson Xavier, Jetson Nano, or Tesla, or in the cloud with NVIDIA GPUs. The exported
\*.etlt model can be used in a stand-alone TensorRT inference sample or in DeepStream.
DeepStream SDK is a streaming analytic toolkit to accelerate building AI-based video analytic applications. TAO Toolkit is integrated with DeepStream SDK, so models trained with TAO Toolkit will work out of the box with Deepstream.
Deploying the ActionRecognitionNet in the DeepStream sample
Once you get the .etlt ActionRecognitionNet model, you can deploy it into the DeepStream
3d-action-recognition sample app. Refer to the sample applications documentation for detailed
steps to run action recogintion in DeepStream.
Running ActionRecognitionNet Inference on the Stand-Alone Sample
A stand-alone TensorRT inference sample is also provided. It consumes the TensorRT engine and supports running with 2D/3D input on images. The sample can be found on Github.
To use this sample, you need to generate the TensorRT engine out of a \*.etlt model using
tao-converter.
Using
tao-converter
The tao-converter is a tool that is provided with the TAO Toolkit to facilitate the
deployment of TAO Toolkit trained models on TensorRT and/or Deepstream. For deployment platforms
with an x86 based CPU and discrete GPUs, the tao-converter is distributed within the TAO
Docker. Therefore, we suggest using the Docker to generate the engine. However, you will need to
adhere to the same minor version of TensorRT that is distributed with the Docker. The TAO Docker
includes TensorRT version 8.0. To use the engine with a different minor version of TensorRT, copy
the converter from /opt/nvidia/tools/tao-converter to the target machine and follow the
instructions for x86 to run it and generate a TensorRT engine.
For the aarch64 platform, the tao-converter is available to download from Dev Zone.
Here is a sample command to generate the ActionRecognitionNet engine through tao-converter:
#convert 2D RGB model with input sequence length is 32 and input size is 224x224:
tao-converter <2d_rgb_etlt_model> -k <key_to_etlt_model> -p input_rgb,1x96x224x224,4x96x224x224,16x96x224x224 -e <path_to_generated_trt_engine> -t fp16
#convert 3D RGB model with input sequence length is 32 and input size is 224x224:
tao-converter <3d_rgb_etlt_model> -k <key_to_etlt_model> -p input_rgb,1x3x32x224x224,4x3x32x224x224,16x3x32x224x224 -e <path_to_generated_trt_engine> -t fp16
This command will generate an optimized TensorRT engine with dynamic batch size (1~16).
Usage of inference sample
Once you get the tensorrt engine, you can deploy the engine in the stand-alone sample. Use the following command to run inference:
python ar_trt_inference.py --input_images_folder <path to input images folder> \
--trt_engine <path to tensorrt engine> \
[--center_crop] \
[--input_2d]
Required Arguments
--input_images_folder: The path to input images folder. It should be avideo_<n>level directory as described in the Preparing the Dataset section.--trt_engine: The path to the TensorRT engine.
Optional Arguments
--center_crop: Resizes the input images with a short side to 256 and center crops to a 224x224 area. If this flag is not set, the input images will be directly resized to 224x224.--input_2d: Set this flag if the engine is generated from a 2D model.
The script will do inference on the images in the folder through a 32-len sliding window with stride 1, which means the inference will be done on sequences as follows:
[frame_0, frame_1, frame_2, ..., frame_31]
[frame_1, frame_2, frame_3, ..., frame_32]
....