NVIDIA Triton Inference Server#
Triton Inference Server is an open source inference serving software that streamlines AI inferencing. Triton Inference Server enables teams to deploy any AI model from multiple deep learning and machine learning frameworks, including TensorRT, PyTorch, ONNX, OpenVINO, Python, RAPIDS FIL, and more. Triton supports inference across cloud, data center, edge and embedded devices on NVIDIA GPUs, x86 and ARM CPU, or AWS Inferentia. Triton Inference Server delivers optimized performance for many query types, including real time, batched, ensembles and audio/video streaming. Triton inference Server is part of NVIDIA AI Enterprise, a software platform that accelerates the data science pipeline and streamlines the development and deployment of production AI.
Triton Architecture#
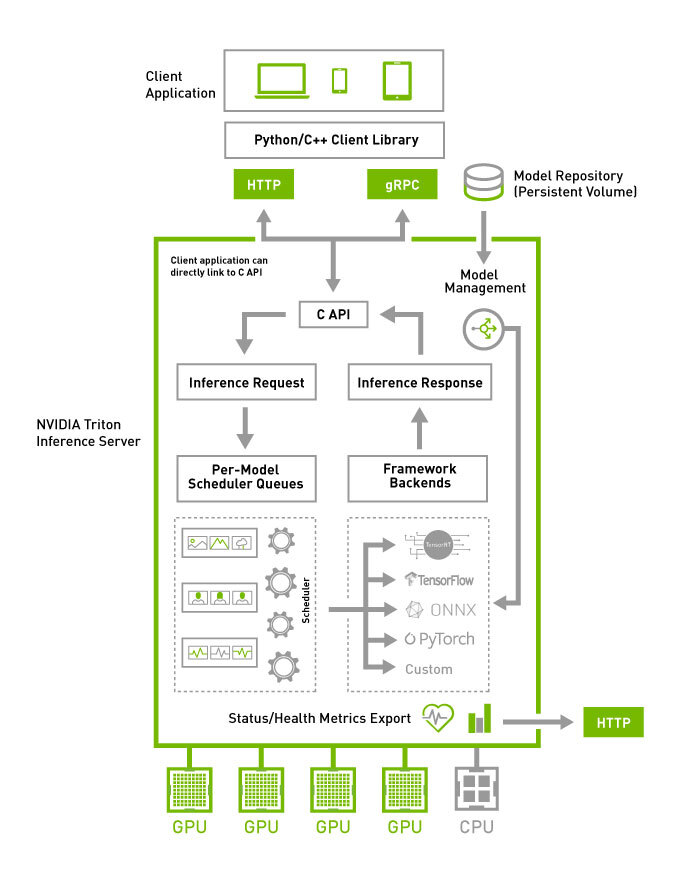
The following figure shows the Triton Inference Server high-level architecture. The model repository is a file-system based repository of the models that Triton will make available for inferencing. Inference requests arrive at the server via either HTTP/REST or GRPC or by the C API and are then routed to the appropriate per-model scheduler. Triton implements multiple scheduling and batching algorithms that can be configured on a model-by-model basis. Each model’s scheduler optionally performs batching of inference requests and then passes the requests to the backend corresponding to the model type. The backend performs inferencing using the inputs provided in the batched requests to produce the requested outputs. The outputs are then returned.
Triton supports a backend C API that allows Triton to be extended with new functionality such as custom pre- and post-processing operations or even a new deep-learning framework.
The models being served by Triton can be queried and controlled by a dedicated model management API that is available by HTTP/REST or GRPC protocol, or by the C API.
Readiness and liveness health endpoints and utilization, throughput and latency metrics ease the integration of Triton into deployment framework such as Kubernetes.
Triton major features#
Major features include:
Sequence batching and implicit state management for stateful models
Provides Backend API that allows adding custom backends and pre/post processing operations
Model pipelines using Ensembling or Business Logic Scripting (BLS)
HTTP/REST and GRPC inference protocols based on the community developed KServe protocol
A C API and Java API allow Triton to link directly into your application for edge and other in-process use cases
Metrics indicating GPU utilization, server throughput, server latency, and more
Join the Triton and TensorRT community and stay current on the latest product updates, bug fixes, content, best practices, and more. Need enterprise support? NVIDIA global support is available for Triton Inference Server with the NVIDIA AI Enterprise software suite.
See the Latest Release Notes for updates on the newest features and bug fixes.