Building Complex Pipelines: Stable Diffusion#
Navigate to |
|---|
Watch this explainer video with discusses the pipeline, before proceeding with the example. This example focuses on showcasing two of Triton Inference Server’s features:
Using multiple frameworks in the same inference pipeline. Refer this for more information about supported frameworks.
Using the Python Backend’s Business Logic Scripting API to build complex non linear pipelines.
Using Multiple Backends#
Building a pipeline powered by deep learning models is a collaborative effort which often involves multiple contributors. Contributors often have differing development environment. This can lead to issues whilst building a single pipeline with work from different contributors. Triton users can solve this challenge with the use of the Python or a C++ backend along with the Business Logic Scripting API (BLS) API to trigger model execution.
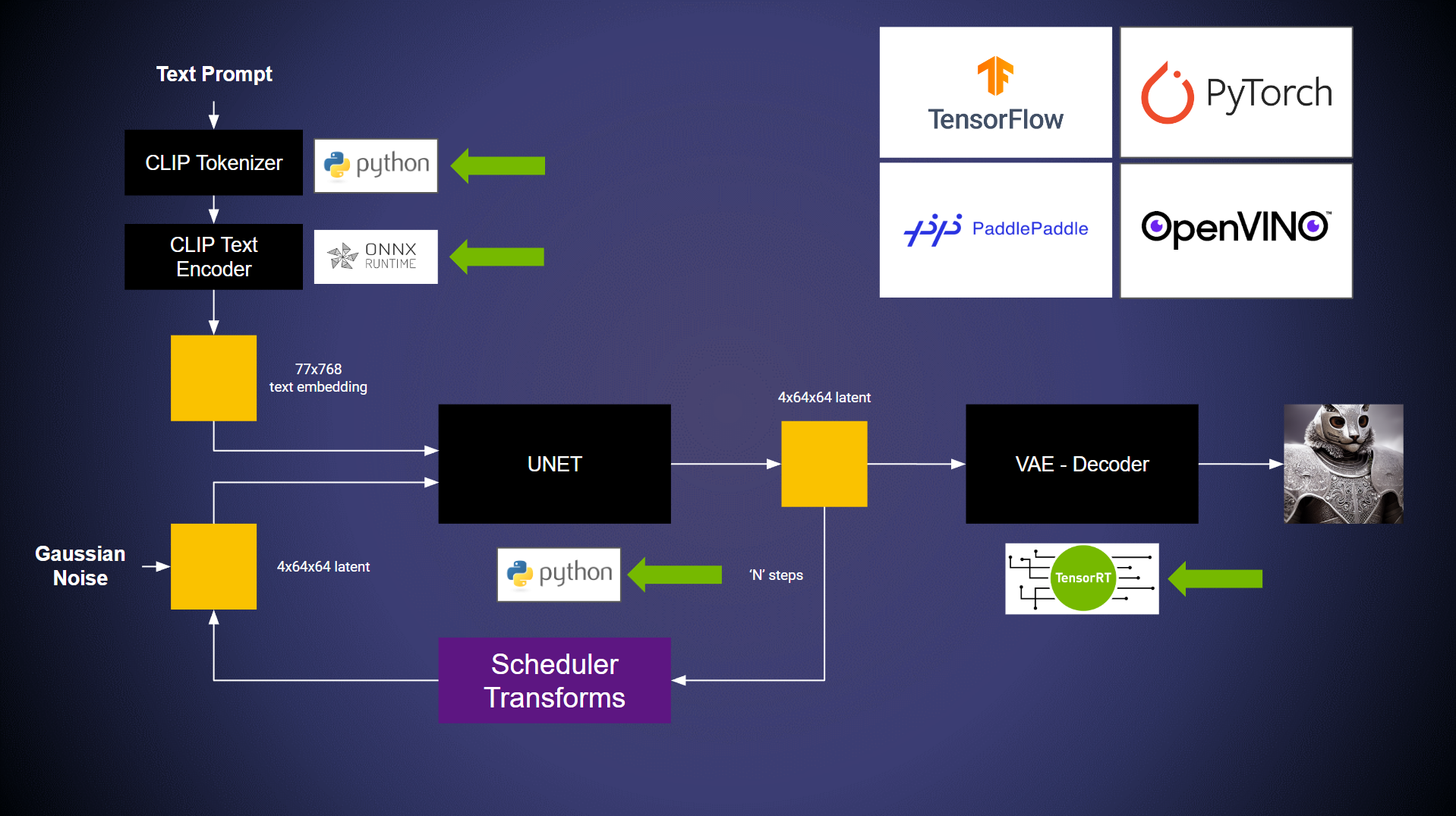
In this example, the models are being run on:
ONNX Backend
TensorRT Backend
Python Backend
Both the models deployed on a framework backend can be triggered using the following API:
encoding_request = pb_utils.InferenceRequest(
model_name="text_encoder",
requested_output_names=["last_hidden_state"],
inputs=[input_ids_1],
)
response = encoding_request.exec()
text_embeddings = pb_utils.get_output_tensor_by_name(response, "last_hidden_state")
Refer to model.py in the pipeline model for a complete example.
Stable Diffusion Example#
Before starting, clone this repository and navigate to the root folder. Use three different terminals for an easier user experience.
Step 1: Prepare the Server Environment#
First, run the Triton Inference Server Container.
# Replace yy.mm with year and month of release. Eg. 22.08
docker run --gpus=all -it --shm-size=256m --rm -p8000:8000 -p8001:8001 -p8002:8002 -v ${PWD}:/workspace/ -v ${PWD}/model_repository:/models nvcr.io/nvidia/tritonserver:yy.mm-py3 bash
Next, install all the dependencies required by the models running in the python backend and login with your huggingface token(Account on HuggingFace is required).
# PyTorch & Transformers Lib
pip install torch torchvision torchaudio
pip install transformers ftfy scipy accelerate
pip install diffusers==0.9.0
pip install transformers[onnxruntime]
huggingface-cli login
Step 2: Exporting and converting the models#
Use the NGC PyTorch container, to export and convert the models.
docker run -it --gpus all -p 8888:8888 -v ${PWD}:/mount nvcr.io/nvidia/pytorch:yy.mm-py3
pip install transformers ftfy scipy
pip install transformers[onnxruntime]
pip install diffusers==0.9.0
huggingface-cli login
cd /mount
python export.py
# Accelerating VAE with TensorRT
trtexec --onnx=vae.onnx --saveEngine=vae.plan --minShapes=latent_sample:1x4x64x64 --optShapes=latent_sample:4x4x64x64 --maxShapes=latent_sample:8x4x64x64 --fp16
# Place the models in the model repository
mkdir model_repository/vae/1
mkdir model_repository/text_encoder/1
mv vae.plan model_repository/vae/1/model.plan
mv encoder.onnx model_repository/text_encoder/1/model.onnx
Step 3: Launch the Server#
From the server container, launch the Triton Inference Server.
tritonserver --model-repository=/models
Step 4: Run the client#
Use the client container and run the client.
docker run -it --net=host -v ${PWD}:/workspace/ nvcr.io/nvidia/tritonserver:yy.mm-py3-sdk bash
# Client with no GUI
python3 client.py
# Client with GUI
pip install gradio packaging
python3 gui/client.py --triton_url="localhost:8001"
Note: First Inference query may take more time than successive queries