

Custom CUDA Kernel Sample
There are 2 examples for custom CUDA kernel ingestion in the Holoscan SDK. These examples demonstrate usage of InferenceProcessorOp to ingest a custom CUDA kernel for processing.
- custom_cuda_kernel_1d_sample: Example shows ingestion of a single 1D custom CUDA kernel.
- custom_cuda_kernel_multi_sample: example shows ingestion of multiple custom CUDA kernels. Specifically a 1D and a 2D kernel are ingested through a single instance of the operator via parameter set.
In these examples we’ll cover:
- How to use parameter set with InferenceProcessorOp operator to ingest a custom CUDA kernel.
- Rules for writing custom CUDA kernel in the parameter set.
The example source code and run instructions can be found in the examples directory on GitHub, or under /opt/nvidia/holoscan/examples in the NGC container and the Debian package, alongside their executables.
Operators and Workflow
Here is the diagram of the operators and workflow used in both the examples.
-
custom_cuda_kernel_1d_sample: In the diagram below, the workflow input comes from video_replayer operator followed by format conversion via the format_converter operator. The inference processor operator then ingests and applies custom CUDA kernels and the result is then sent to the Holoviz operator for display.
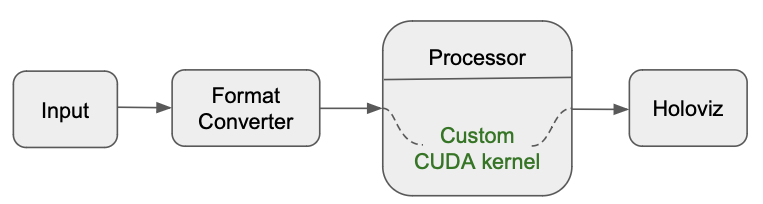
-
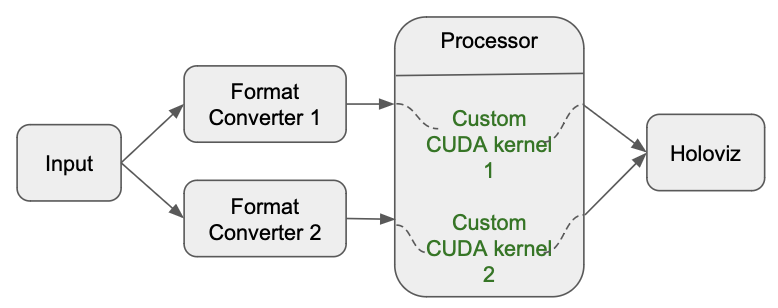
custom_cuda_kernel_multi_sample: This sample has multiple custom CUDA kernels ingested into the workflow. In the diagram below, input in the workflow comes through the video_replayer operator. There are two instances of the format_converter operator that convert the format of the input data for the two custom CUDA kernels. The inference processor operator then ingests both the tensors from format converter operators, and applies custom CUDA kernels as per the specifications in the workflow. The result is then sent to the Holoviz operator for display.
Video Stream Replayer Operator
The built-in video stream replayer operator can be used to replay a video stream that has been encoded as GXF entities. You can use the convert_video_to_gxf_entities.py script (installed in /opt/nvidia/holoscan/bin or available on GitHub) to encode a video file as GXF entities for use by this operator.
This operator processes the encoded file sequentially and supports realtime, faster than realtime, or slower than realtime playback of prerecorded data. The input data can optionally be repeated to loop forever or only for a specified count. For more details, see holoscan::ops::VideoStreamReplayerOp.
We will use the replayer to read GXF entities from disk and send the frames downstream to the Holoviz operator.
Format Converter Operator
The built-in format converter operator converts the size and datatype of the incoming tensor.
Processor Operator
Inference Processor operator (InferenceProcessorOp) is designed using APIs from Holoscan Inference Component. The operator performs data processing operations specifically for inference examples in Holoscan SDK. The Inference Processor operator is updated to ingest custom CUDA kernels written by the user. The user must follow the conventions described below when designing and using custom CUDA kernels:
-
Custom Cuda Kernel name must be: custom_cuda_kernel-identifier. E.g. A custom CUDA kernel with identifier as 1 must be named as custom_cuda_kernel-1. The identifier must be unique for all the custom kernels and is used in defining the kernels further in the parameter set.
-
Named custom CUDA kernel is invoked in the parameter set as shown below. Custom CUDA operation is mapped to the input tensor input_tensor via process_operations map in the parameter set.
-
Custom CUDA kernel is defined using custom_kernels map in the parameter set.
- Custom CUDA kernel is defined with key cuda_kernel-identifier. In the example above, CUDA kernel with identifier 1 is defined using the key cuda_kernel-1 in the cuda_kernels parameter.
- Custom CUDA kernel name must follow the following convention: customKernelIdentifier. For e.g in the example in the parameter set above, function name is customKernel1 with identifier 1.
- Function name must be preceded: by
extern "C"and the__global__keyword as shown in the example above. - Multi dimensional custom CUDA kernels are supported, though function arguments support is limited to the following:
- 1D: (const voidinput, void output, int size)
- 2D: (const voidinput, void output, int width, int height)
- 3D: (const voidinput, void output, int width, int height, int depth)
- Custom CUDA kernel can be ingested via a filepath or a string. If the custom CUDA kernel is ingested via a filepath, the operator will read the kernel from the file. If the custom CUDA kernel is ingested via a string in the parameter set, the operator will use the kernel from the string. Filepath must end with .cu extension. All specifications for the kernel must be present in the file.
- Output data type for custom CUDA kernel with identifier 1 is defined as out_dtype-1.
- Options: kFloat32, kFloat16, kUInt8, kInt8, kInt32, kInt64
- Output dimensions for custom CUDA kernel with identifier 1 is defined with key output_dimensions-1.
- This parameter is used to specify the dimensions of the output tensor for the custom CUDA kernel. For example: “320,320,1”
- This parameter is optional and if not specified, the operator will assume the output dimensions to be the same as the input dimensions.
- In case of multiple custom CUDA kernels, the output dimensions of a particular kernel is the input dimensions for the next kernel. The user must ensure that the output dimensions of a kernel are compatible with the input dimensions of the next kernel and the respective kernel implementation takes care of the dimensions.
- In case of multiple custom CUDA kernels, if a dynamic output dimension is required for any kernel, it must be specified for each kernel. If any kernel does not specify the output dimensions, it will be assumed that the output dimensions are the same as the input dimensions for all of the kernels. The user cannot use this feature selectively in chaining of multiple custom CUDA kernels.
- Threads per block for custom CUDA kernel with identifier 1 is defined with key thread_per_block-1. By default, custom CUDA kernel is 1D and if this parameter is not specified, the operator will assume it to be a 1D kernel with 256 threads.
- threads_per_block-identifier parameter in the cuda_kernels map is used in identifying the dimension of the kernel. For a 2D kernel, this parameter must be present with 2 values of threads per block (in x and y dimension) separated by a comma (,). For e.g. thread_per_block-identifier: “16,16”. Similarly for a 3D kernel, thread_per_block-identifier: “8,8,8”.
- Custom CUDA kernel is defined with key cuda_kernel-identifier. In the example above, CUDA kernel with identifier 1 is defined using the key cuda_kernel-1 in the cuda_kernels parameter.
-
Multi Custom CUDA kernel support: User can create one of more custom CUDA kernel in the same instance of the InferenceProcessorOp and can define it in the same parameter set.
- In the example above, two custom CUDA kernels are defined. cuda_kernel-1 is 1D and custom_kernel-2 is a 2D kernel, they both are used in the same parameter set.
-
Templated kernels are not supported in this release.
-
Custom CUDA kernel can be ingested via a filepath or a string. If the custom CUDA kernel is ingested via a filepath, the operator will read the kernel from the file. If the custom CUDA kernel is ingested via a string in the parameter set, the operator will use the kernel from the string. Filepath must end with .cu extension. All specifications for the kernel must be present in the file.
-
Multiple custom CUDA kernels chaining is supported. For a particular input tensor, multiple custom CUDA kernels can be defined in the parameter set. Custom CUDA kernels are executed in the order of their definition in the parameter set. For e.g. custom_cuda_kernel-1 and custom_cuda_kernel-2 are two custom CUDA kernels defined in the parameter set. The output of custom_cuda_kernel-1 is used as input for custom_cuda_kernel-2. Custom CUDA kernels are separated by a colon (:) as shown below.
-
CUDA Graphs support: is enabled for execution of custom CUDA kernels. In use cases with multiple custom CUDA kernels chained together, usage of CUDA Graphs may optimize the execution. By default, CUDA Graphs are disabled. It can be enabled by setting use_cuda_graphs as true in the parameter set as shown below. If CUDA Graphs are enabled, it will be applied for all custom CUDA kernel executions and for all the tensors using custom CUDA kernels for processing.
Holoviz Operator
The built-in Holoviz operator provides the functionality to composite realtime streams of frames with multiple different other layers like segmentation mask layers, geometry layers and GUI layers. We will use Holoviz to display frames that have been sent by the replayer operator and processor operator to its “receivers” port which can receive any number of inputs.
Running the Application
Running the application should bring up holoviz display for each of the example as shown below.
-
custom_cuda_kernel_1d_sample: This example shows the input frame and grayscale of the input frame side by side. Grayscale conversion is executed by the custom CUDA kernel.

-
custom_cuda_kernel_multi_sample: This example shows the input frame and grayscale of the input frame, followed by edge detection in the frame. Grayscale conversion is executed by a 1D CUDA kernel, edge detection is performed by a customized 2D CUDA kernel.
