cuMAC#
Aerial cuMAC provides a library of CUDA-accelerated MAC scheduling algorithms for the 5G/6G RAN. The algorithms can be integrated into the Layer-2 (L2) stack of the RAN system to offload computationally intensive MAC scheduling functions from the host CPU to the GPU. cuMAC is designed to enhance the spectral efficiency of 5G/6G RAN and alleviate compute bottlenecks inherent in conventional CPU-based MAC schedulers. It serves as an open-source reference implementation for accelerating 5G/6G MAC scheduling on NVIDIA GPUs.
The Core Problem: The Compute Bottleneck in MAC Scheduling#
The MAC scheduler is a critical component of the L2 stack in the 5G/6G RAN. It is responsible for allocating time-frequency radio resources to the user equipment (UEs) within each cell, and its performance directly impacts the spectral efficiency and overall user experience of the RAN system.
Real-time constraints in L2 stack - In general, MAC scheduling involves solving complex optimization problems to efficiently utilize the available radio resources under strict real-time constraints - typically on the order of milliseconds or even sub-milliseconds for 5G/6G services, e.g., URLLC, eMBB, and mMTC. This imposes heavy computational demands on the L2 stack.
The CPU bottleneck - However, conventional MAC schedulers running on CPUs are limited by the small number of cores available per cell for real-time decision making. As a result, CPU-only implementations often encounter severe compute bottlenecks, hindering the adoption of many high-performance yet computationally intensive scheduling algorithms within the latency bounds required by the L2 stack.
The future is more complex - Future AI-native RANs, which use AI/ML techniques for tasks such as resource allocation and interference management and require real-time inference of neural network models, will impose even greater computational challenges on traditional CPU-only architectures.
The Solution: CUDA-Accelerated MAC Scheduling#
To address these challenges, NVIDIA has developed cuMAC, a library of CUDA-accelerated MAC scheduling algorithms designed to offload compute-intensive scheduling functions from the L2 stack host to the GPU.
Why CUDA/GPU? - cuMAC leverages the massive parallel processing capabilities of CUDA to accelerate scheduling algorithms, which inherently exhibit high degrees of parallelism in their computational steps. This enables the deployment of advanced, compute-intensive scheduling algorithms in the RAN, delivering scalable and high-performance MAC scheduling within the strict latency constraints of the L2 stack.
What we provide - cuMAC provides a reference design/implementation demonstrating how to:
Offload complex L2 MAC scheduler algorithms from the CPU to the GPU.
Implement advanced, compute-intensive scheduling algorithms in CUDA.
Achieve the real-time performance requirements for the L2 stack.
Integrate with common RAN L2 stacks (with a reference framework).
Key insights - We view the MAC scheduler as a high-throughput, parallelizable data pipeline rather than a collection of sequential tasks executed solely by CPU cores. In addition, the modular implementation of cuMAC algorithms allows seamless integration with common RAN L2 stacks and facilitates the evolution of MAC scheduler design for next-generation RANs.
Key Features#
Reference scheduling algorithms - Includes clean, well-documented CUDA implementations of:
Proportional-fairness (PF)-based UE selection algorithms.
PF-based UE/logical channel sorting per QoS type.
PF-based PRB allocation algorithms.
ILLA + OLLA based link adaptation.
Link adaptation based on deep reinforcement learning (DRL).
MU-MIMO user grouping/pairing for 64T64R.
DL beamforming weights computation (zero-forcing).
Real-time performance - The CUDA implementations of cuMAC algorithms are designed to meet the real-time performance requirements for the L2 stack.
Interfacing between L2 stack and GPU - cuMAC-CP serves as the real-time interface for offloading MAC scheduling functions to the GPU.
Joint scheduling across multiple cells - The CUDA implementations are designed for the joint scheduling across multiple cells within a coordinated cell group.
Modular design - Built as a library of modular scheduling algorithms that can be integrated into existing L2 stacks, simulators, or custom testbeds to offload individual MAC scheduling functions to the GPU.
Benchmarking suite - Includes tools to profile, test, and compare the performance of CUDA algorithm implementations against CPU-based equivalents.
Extensible framework - Provides a C++/CUDA framework and API for researchers and engineers to implement and test their own novel MAC scheduling algorithms on the GPU.
Architecture#
The architecture for offloading MAC scheduler functions to the GPU is illustrated in the following figure:
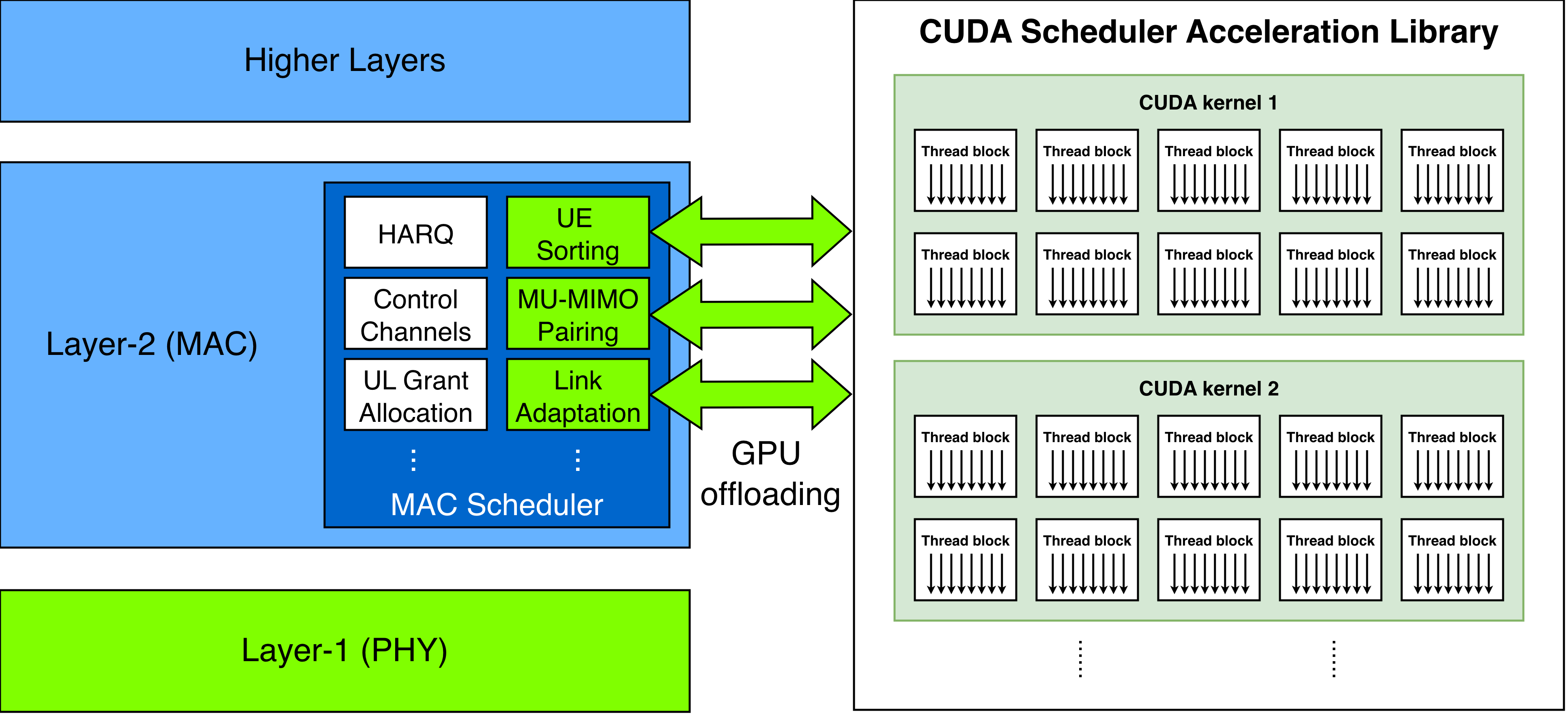
GPU offloading for MAC scheduler functions
The L2 stack host, which contains the MAC scheduler, operates on the CPU.
Compute-intensive MAC scheduling functions are offloaded to the GPU for accelerated processing and improved spectral efficiency.
The cuMAC architecture including the GPU offloading APIs, cuMAC-CP interface, and the CUDA-based MAC scheduling algorithm library is illustrated in the following figure:
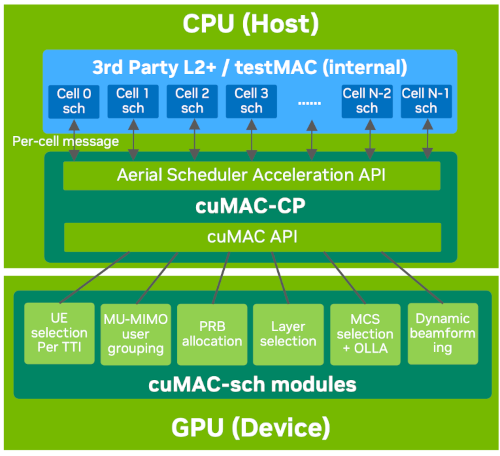
cuMAC architecture
Aerial Scheduler Acceleration API - A set of APIs provided by cuMAC-CP to interface with the L2 stack host for offloading MAC scheduling functions to the GPU.
cuMAC-CP — The control-plane process that interfaces between the L2 stack host and the MAC scheduling functions running on the GPU.
cuMAC-Sch API - A set of APIs called by cuMAC-CP to launch the CUDA-based MAC scheduling algorithms on the GPU.
cuMAC Algorithm CUDA Library - The library of CUDA implementations with C++ wrappers of the MAC scheduling algorithms.
Installing cuMAC within the cuBB container#
cuMAC is built together with other cuBB components under the cuBB container. Refer to the Installation Guide to complete the installation or upgrade process.